"Мешок трюков для классификации изображений с сверточными нейронными сетями": обсуждение статьи
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-04-10 03:40

О серии:
Это сообщение в блоге, отмечающее начало серии (надеюсь), будет пошаговым руководством идей, разделенных в сумке трюков для классификации изображений с помощью сверточных нейронных сетей бумаги и несколько мыслей мной.
В статье обсуждается несколько трюков и проводится анализ их индивидуального, а также объединенного вклада в обучение некоторых из последних моделей CNN.
Контекст:
В то время как мы продолжаем замечать толчок в современной точности для моделей классификации изображений и даже несмотря на то, что сети глубокого обучения превзошли точность человеческого уровня в задаче классификации изображений, эти прорывы были не только из-за архитектур или просто потому, что модели нейронных сетей продолжают становиться " глубже”
Многие из улучшений были вызваны маленькими "трюками", которые обычно остаются неопубликованными или не особо выделяются.
Цель авторов-поделиться этими трюками вместе с обширными экспериментами, основанными на каждом из “трюков”.
Эти трюки имеют две цели:
- Включение лучшей точности:
настройки для моделей NN позволяют повысить точность. - Включение более быстрой тренировки.
Например: использование тензорных ядер на новых RTX-картах с использованием FP16 compute.
Трюки
Авторы обсуждают несколько трюков, давайте пройдемся по ним:
- Скорость обучения линейному масштабированию:
при обучении нейронной сети мы загружаем изображения в графический процессор пакетами, насколько позволяет память. Они рисуются случайным образом в SGD и имеют некоторую дисперсию к ним.
По мере увеличения размера пакета разброс изображений между пакетами уменьшается, что позволяет использовать более агрессивные настройки скорости обучения.
Скорость обучения устанавливается по формуле: 0.1 x (Batch_size) / 256 - Разминка скорости обучения:
когда мы тренируем нейронную сеть, мы устанавливаем скорость обучения, которая определяет, как “быстро” модель учится или как агрессивно мы наказываем предсказания из нее.
Когда мы начинаем тренировать нашу нейронную сеть, мы можем ожидать, что веса будут иметь больше случайности. Если мы установим агрессивную скорость обучения, это может привести к расхождению сети.
Чтобы исправить это, используется разминка скорости обучения, которая позволяет установить скорость обучения на более низкие значения изначально, а затем увеличить.
Делается это следующим образом: вначале скорость обучения имеет значение ~0, а затем возрастает для “начальных серий” согласно формуле:
текущая эпоха* (скорость обучения)/(Num_of_Initial_Epochs)
кол-во первоначальных эпох: это hyperparameter, номер, который мы выбираем, чтобы держать, пока модель не “подогревают”
обучения курс: наша конечная скорость обучения, которые мы устанавливаем для НН. - Zero Y:
ResNets составлены множественных остаточных блоков. Они могут быть обозначены для простоты как X + BL block(x)
, за ними обычно следуют слои пакетной нормализации, которые в дальнейшем масштабируются как Y*(x)+bias. (Y и bias “выучены” по мере того как мы тренируем сеть)
статья предлагает инициализировать для слоев в конце блоков ResNet, Y должен быть инициализирован к 0. Это уменьшает количество обучаемых параметров изначально. - Отсутствие спада смещения:
регуляризация вообще приложена к всем learnable параметрам однако, это часто водит к overfitting.
Авторы предлагают применять регуляризацию только к сверточным и полносвязным слоям, смещения и параметры пакетной нормы не упорядочены. - Mixed Precision Training:
Mixed Precision training позволяет нам использовать Тензорные ядра последних GPU(S), которые намного быстрее, и, таким образом, позволяют нам использовать быстрые операции FP16 и FP32 training для вычисления весов или градиентов, чтобы позволить “небезопасным” операциям быть выполненными с полной точностью.
Для получения более подробной информации о смешанной точности обучения, я бы предложил прочитать эту запись. - Модельные настройки:
в статье сравниваются некоторые настройки, сделанные в архитектурах ResNet.
Они включают в себя настройку шагов внутри слоя свертки, вдохновленную последними архитектурами. Я пропущу детали этой части, так как они требуют немного подробного знания шагов и извилин.
В общем, аргумент настраивает существующие архитектуры также обеспечивает повышение точности. - Косинус скорость обучения:
по мере обучения нашей модели, мы можем ожидать, что он будет лучше с эпохами (предполагая, что все работает хорошо), как наши значения потерь уменьшаются, мы приближаемся к “минимумам”. На этом этапе мы хотели бы снизить скорость обучения.
Вместо использования ступенчатого спада, когда скорость обучения распадается в " шагах” при фиксированных номерах пакета, в статье предлагается использовать косинусную запланированную скорость обучения следующим образом:
скорость обучения (Cosine_Decayed) = первоначально установленная скорость обучения * 0.5 * (1 + cos (Current_Batch * (Pi)) / Total_Num_Batches)) - Сглаживание надписей:
это предполагает настройку конечных слоев и распределение вероятностей для предсказаний,чтобы позволить сети лучше обобщать. Я пропустил детали того, как это реализуется. - Дистилляция знаний:
этот подход "перегоняет" знания из другой предварительно подготовленной модели "учитель" в нашу текущую студенческую сеть.
Это делается путем добавления потери дистилляции, которая наказывает нашу студенческую сеть на основе того, насколько ее прогнозы не соответствуют “модели учителя”.
Результаты:
В статье показано наиболее перспективное в ImageNet использование модели ResNet 50, которая показывает наибольшее улучшение.
Существует обширное исследование того, насколько полезен или “вреден” каждый из этих отдельных трюков по отношению к задаче.
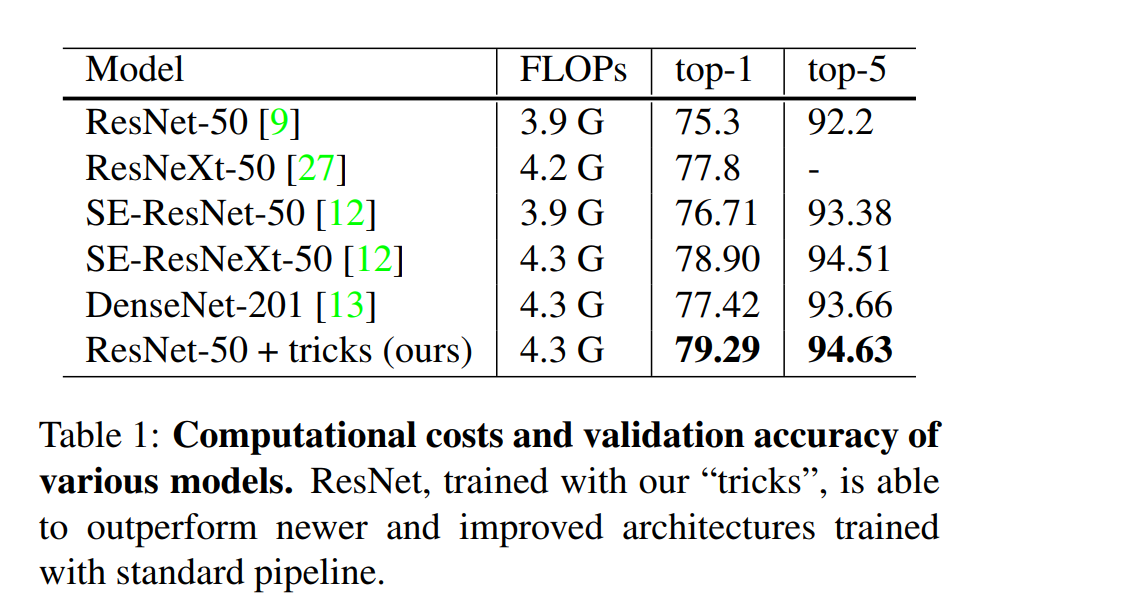
Наконец, проводится сравнение использования трансферного обучения на двух задачах:
- Обнаружение объектов в наборе данных VOC Pascal:
- Семантическая Сегментация
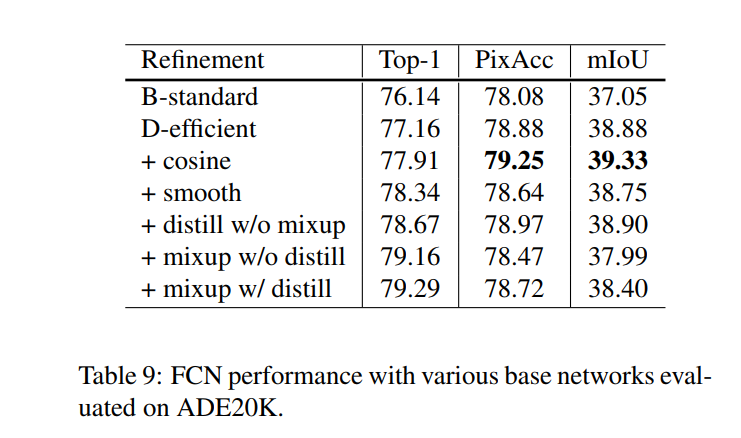
Заключение и личные мысли:
Это один из первых документов, чтобы охватить маленькие трюки, которые обычно не в центре внимания или не придается столько значения в документах.
Статья глубоко погружается во все идеи, показывая обширные сравнения.
В качестве небольшого упражнения, я считаю, что это должен быть хороший эксперимент, чтобы попробовать несколько из этих трюков на личную целевую задачу и документировать улучшения.
Я также хотел бы подробнее прочитать о таких трюках в будущих статьях или иметь подробный раздел, посвященный таким подходам.
Телеграм: t.me/ainewsline
Источник: hackernoon.com