Машинное обучение применяется на всём цикле заказа автомобиля в Яндекс.Такси, и число компонентов сервиса, работающих благодаря ML, постоянно растёт. Чтобы строить их единообразно, нам потребовался обособленный процесс. Руководитель службы машинного обучения и анализа данных Роман Халкечев рассказал про препроцессинг данных, применение моделей в продакшене, сервис их прототипирования и сопутствующие инструменты.
— На мой взгляд, какие-то новые вещи намного проще воспринимаются, когда их рассказывают на каком-нибудь простом примере. Поэтому, чтобы доклад не был сухим, я решил рассказать про одну из задач, которые мы решаем. На её примере я покажу, почему мы действуем именно так. Давайте сформулируем проблему. Есть пользователи Такси, которым нужно добраться из точки А в точку Б, и есть водители, которые готовы за определенную сумму доставлять этих пользователей из точки А в точку Б. У пользователя есть несколько состояний, в которых он находится. Он вызывает такси, выбирает точку А, точку Б, тариф и так далее, производит посадку в такси, едет, и наконец, производит высадку. Cегодня я бы хотел поговорить про посадку в автомобиль и проблемы, которые могут при этом возникать.
Как правило, эти проблемы связаны с тем, что человеку нужно выбрать место, куда такси должно приехать. И здесь бывает ряд трудностей. Эти трудности связаны с четырьмя вещами, которые я перечислил на слайде. В первую очередь, локация может быть незнакома пользователю. В качестве примера можно представить себя, приехавшего в какой-нибудь большой торговый центр, в котором вы не так часто бываете. Вы хотите уехать и не очень представляете, куда вообще здесь можно вызвать такси, куда машина может заехать, а куда не может — например, из-за шлагбаума. Бывают проблемы с тем, что в каких-то местах много людей, много машин и вам трудно найти свою машину. Есть места, где люди обычно садятся в автомобиль, там сесть проще. И вы можете не знать, находясь в каком-нибудь новом месте, необязательно в торговом центре, где именно провести посадку. Сложности могут быть связаны с тем, что водитель не может подъехать туда, куда вы вызвали такси: ему запрещен проезд, там какой-нибудь большой выезд из ТЦ, напротив которого нельзя останавливаться, и т. д. С другой стороны, проблемы могут быть и у вас как у пользователя. Водитель приехал, все хорошо, но вам неудобно садиться, потому что все перекопали. Вы просите водителя подъехать куда-то еще. Бывают и другие причины.
Самым наглядным примером, квинтэссенцией всех перечисленных может служить аэропорт, в котором выполняется примерно всё. Даже если вы вылетаете из Шереметьево очень часто, все равно это незнакомая для вас локация, потому что там часто многое меняется. Там много людей, много машин, есть удобные места для посадки, есть неудобные, но про это, как правило, никто из нас не помнит.
Решение читается из названия слайда. Давайте будем рекомендовать пользователю некоторые места, в которых, на наш взгляд, производить посадку удобно. Мысль кажется очевидной, но тут сразу много нюансов. Для начала, «удобно» — субъективное понятие. Кажется, что перед тем, как решать задачу, нужно сформулировать некоторые критерии того, что задача будет решена правильно. Мы для себя сформулировали три основных. Первый критерий — как в любой задаче рекомендаций: наверное, рекомендации хороши, если ими пользуются. Если мы будем показывать такие точки, из которых пользователь действительно будет уезжать — наверное, это хорошие точки. Но это, разумеется, еще не всё, потому что можно научиться что-нибудь рекомендовать, показывать, сподвигнуть пользователя этим воспользоваться, но какого-то ощутимого профита не получить (не получим ни мы как система, ни пользователь, ни водитель). Поэтому очень важно смотреть на другие метрики. Мы выбрали две.
Если мы подскажем такое место посадки, к которому водителю будет легко подъехать, то время подачи автомобиля должно снизиться. С другой стороны, если в этом месте пользователю будет легче найти автомобиль, легче произвести посадку, то должно уменьшиться время ожидания водителем пользователя. Это некоторая наша гипотеза, которую мы принимаем на веру, и это некоторые метрики, на которые мы смотрим, когда делаем эти рекомендации. Но разумеется, это не единственные метрики, на которые можно смотреть. Их можно придумать еще с десяток. Я думаю, каждый из вас может придумать свою сотню таких метрик.
Вот еще некоторые примеры. Это может быть доля отмен до поездки. По идее, она должна снизиться, если пользователю будет легче произвести посадку. Условно, это звонки, когда пользователь звонит водителю, пытаясь его найти, или, наоборот, водитель звонит пользователь до того, как поездка началась. Это обращение в поддержку, и еще с десяток других.
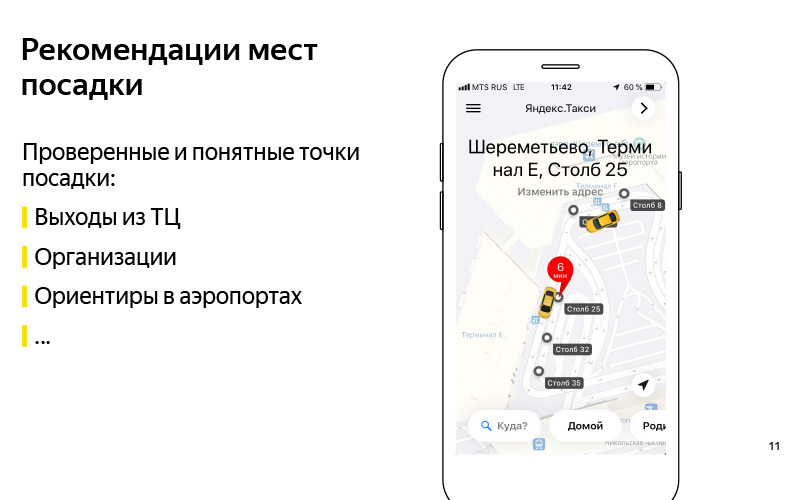
Мы сформулировали проблему. Мы примерно поняли критерий того, что мы эту проблему умеем решать. Давайте теперь подумаем про то, как можно решить эту проблему. Первое, что приходит на ум: а давайте какие-нибудь такие проверенные и понятные точки посадки будем рекомендовать. Здесь на слайде изображен пример торгового центра «Европейский». И мы знаем точно, что к выходам из этого торгового центра можно подъехать, и это некоторый ориентир, благодаря которому пользователь может найти водителя. Это могут быть какие-нибудь организации. Есть пример с «Азбукой вкуса» в каком-нибудь торговом центре. По-моему, это «Ереван Плаза». Это тоже некоторый ориентир для пользователя и водителя, про который мы знаем, что туда подъехать можно.
Это могут быть ориентиры в аэропортах, о которых я говорил. Условно, есть такие столбы в Шереметьево с номерами. К ним удобно вызывать такси и садиться в машину. Хорошее решение, но у него есть минус, что оно не очень масштабируемое. У нас много стран, сотни городов, еще огромное число разных торговых центров, аэропортов, сложных развязок, незнакомых мест, для которых вручную эти точки сделать довольно сложно, и держать их в актуальном состоянии еще сложнее. Именно здесь нам на помощь приходит то, что громко называют «искусственным интеллектом». Я предпочитаю называть это анализом данных или машинным обучением. Для машинного обучения нужны какие-то данные, и эти данные у нас на самом деле есть. Еще один способ решить проблему автоматически — использовать эти данные. Высокоуровнево идея заключается в том, что у нас есть данные про GPS, логи приложения, и есть граф дорог. И мы можем понять, где пользователи на самом деле садятся в машину. Не те точки, в которые они вызывают машину, а там, где они производят посадку. И на основе этого сделать что-нибудь в таком духе.
Это уже автоматически полученные точки для бизнес-центра «Аврора», в котором сейчас сидит наша команда Яндекс.Такси. Я высокоуровнево рассказал про нашу задачу. Теперь давайте подробнее поговорим про то, из каких этапов состоит решение этой задачи. Понятное дело, что есть этап подготовки данных.
Какие данные у нас есть? Во-первых, у нас есть GPS-данные наших пользователей и GPS-данные наших водителей. Когда они пользуются нашим приложением, мы знаем приблизительное местоположение пользователей. Понятно, что у GPS большая погрешность, в районе 13-15 метров, но тем не менее, что-то есть. Во-вторых, у нас есть информация, которая содержится в логах приложения, про то, когда водитель перешел из статуса «Ожидаю пользователя» в статус «Везу пользователя». Можно предположить, что примерно в это время водитель дождался пользователя, пользователь сел в машину, и они поехали. Примерно в этом месте была произведена посадка. И у нас есть дорожный граф. Дорожный граф — это не только набор ребер, улиц, но и дополнительная метаинформация: шлагбаумы, информация про парковки, и т. д. На основе этих данных уже можно получить какие-то автоматические точки. Это были исходные данные. А на выходе мы хотим две вещи. Это какие-то так называемые кандидаты в точки посадки. Каким образом они получаются? Жалко, что не получилось показать видео. Происходит приблизительно следующее. У нас есть много точек GPS, в которых мы знаем, что водитель перешел из статуса «Ожидаю пассажира» в статус «Поехали». Мы их можем, условно, притянуть к графу, то есть спроецировать на граф дорог, потому что, как правило, машина начинает движение от какой-то дороги. На этом графе какую-то кластеризацию этих точек выполнить. И получить большое число кандидатов — это места, в которых какие-то пользователи садились в автомобиль, и им это было нормально, удобно. Не куда они вызывали, а где они в итоге сели.
После этого, когда у нас есть очень много кандидатов и у нас есть некоторый пользователь в онлайне, мы знаем его местоположение, вот он открыл приложение и хочет вызвать такси, то мы можем из большого числа кандидатов выбрать самые лучшие пять, и показать их. Самые лучшие пять определяет некоторая модель машинного обучения, которая учится ранжировать всех кандидатов по вероятности того, что пользователь прямо сейчас в это время с учетом его местоположения и с учетом его истории поездок удобнее всего уехать. И приблизительно так мы можем эти точки автоматически генерировать. Причем, если в какой-то момент где-то, условно, перекопают, то есть станет вызывать такси неудобно, или где-нибудь поставят знак, запрещающий остановку, и водители и пользователи действительно перестанут производить посадку в этом месте, то в какой-то момент алгоритм это поймет, и данные обновятся.
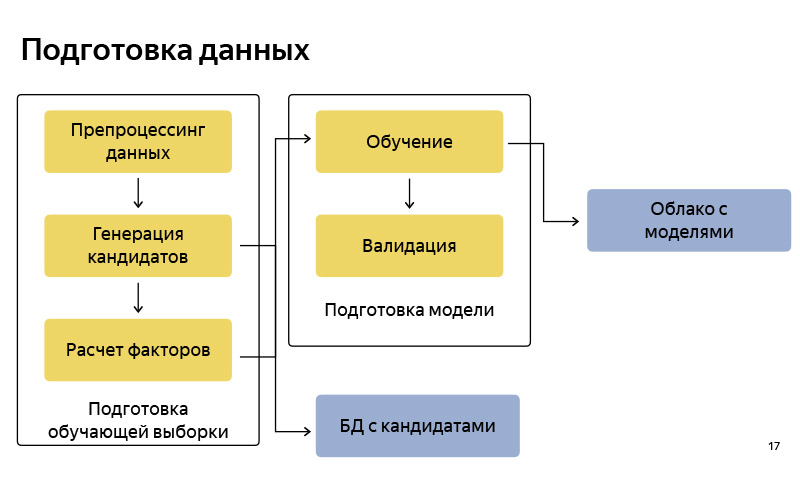
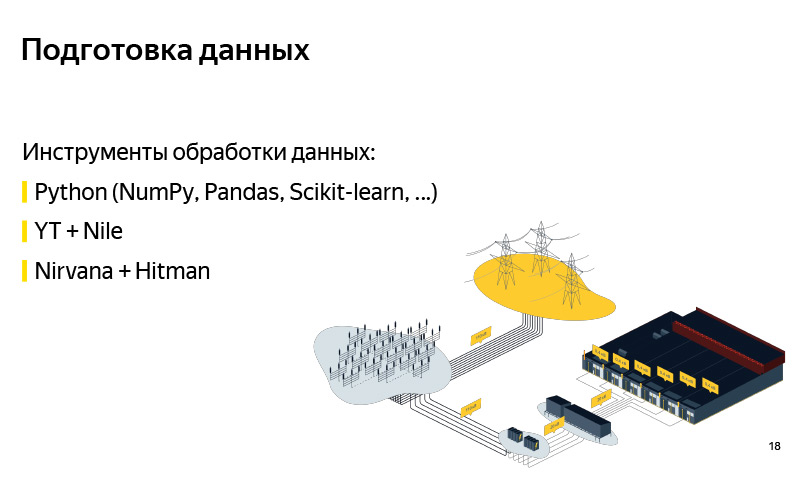
Приблизительно так выглядит блок-схема того, как мы готовим данные. Соответственно, она довольно стандартная, как в любом пайплайне машинного обучения. Есть подготовка данных, есть генерация кандидатов по алгоритму, упрощенную версию я рассказал. Мы этих кандидатов сохраняем в некоторую базу данных. После этого мы готовим некоторый пул для обучения (обучающая выборка), в которой есть, условно, пользователь, время, метаинформация, набор кандидатов, и известно, из которой точки пользователь в итоге уехал. На этом мы обучаем модель классификации. И затем по предсказаниям вероятности ранжируем кандидатов. Когда модель готова, мы загружаем ее в некоторое облако, где она хорошо хранится. Какие инструменты мы используем при подготовке данных? В основном вся подготовка данных у нас написана на Python, на Python stack: это стандартные NumPy, Pandas, Scikit-learn и т. д. Данных у нас очень много. У нас миллионы поездок в месяц. Очень много данных про GPS, про треки водителей, логи приложений, поэтому их нам нужно обрабатывать все-таки на кластере. Для этого мы используем MapReduce нашей внутрияндексовской версии, который называется YT, и к нему есть библиотека, написанная на Python, которая позволяет какие-то маперы и редьюсеры запускать, и делать какие-то вычисления на большом кластере. Наконец, когда пайплайн готов, нам нужно его автоматизировать, чтобы была актуальность данных, и для этого мы используем такую вещь как Nirvana и Hitman. Это тоже внутрияндексовские разработки. Nirvana — это фреймворк по управлению вычислениями на кластере. На самом деле, она умеет примерно любую программу запускать, быть отказоустойчивой, быть cross DC (00:14:53). И в случае, если что-то падает, она умеет это перезапускать, создавать запуски по наступлению каких-нибудь событий. и т. д.
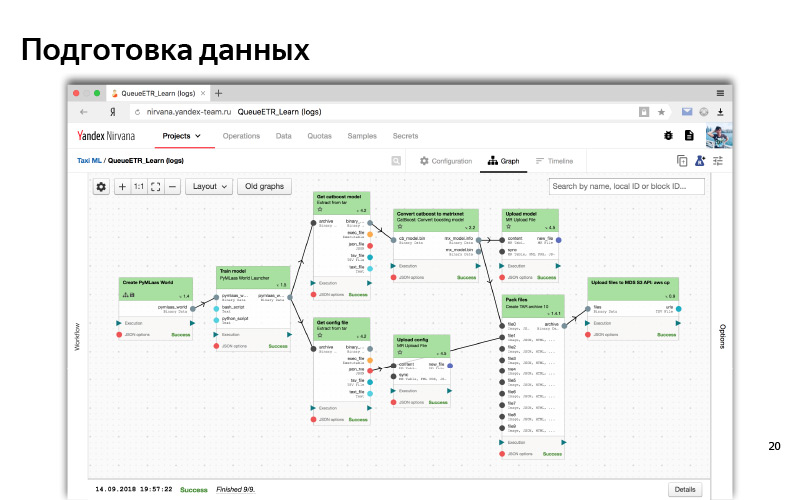
Приблизительно так выглядит веб-интерфейс нашего кластера MapReduce. Здесь видно, что у нас очень много машинок, таких нод, на которых выполняются вычисления. А так в веб-интерфейсе выглядит типичный процесс какого-то препроцессинга данных и обучения моделей. Это такой граф зависимостей. Зависимости бывают как по данным, когда одна часть (один кубик) ждет данные другого кубика; так и логическая зависимость (сперва приготовили все данные, затем запустили обучение). Это некоторая автоматизированная система. Для всего этого мы, как правило, используем Python. Задачу сформулировали, критерии успеха сформулировали, научились как-то решать ее в офлайне, сделали даже какую-то модель, и по каким-то офлайн-метрикам она вроде работает — предсказывает действительно те точки, из которых пользователь уезжает, и находит те точки, которые, казалось бы, должны снижать время ожидания и подачи автомобиля.
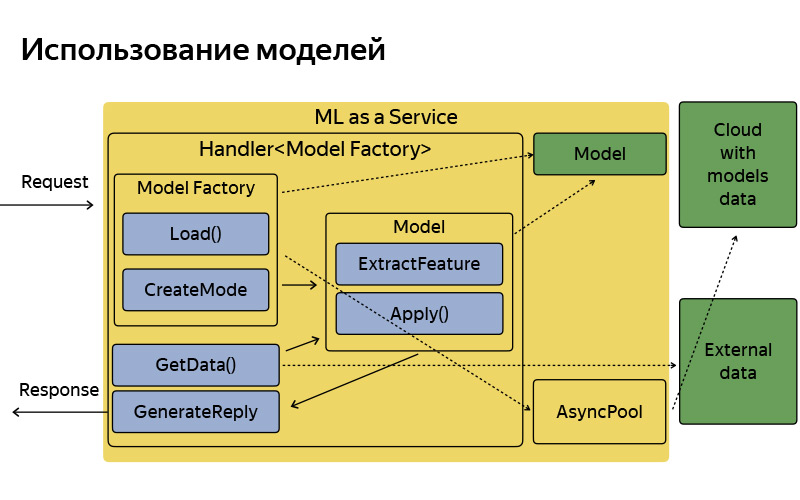
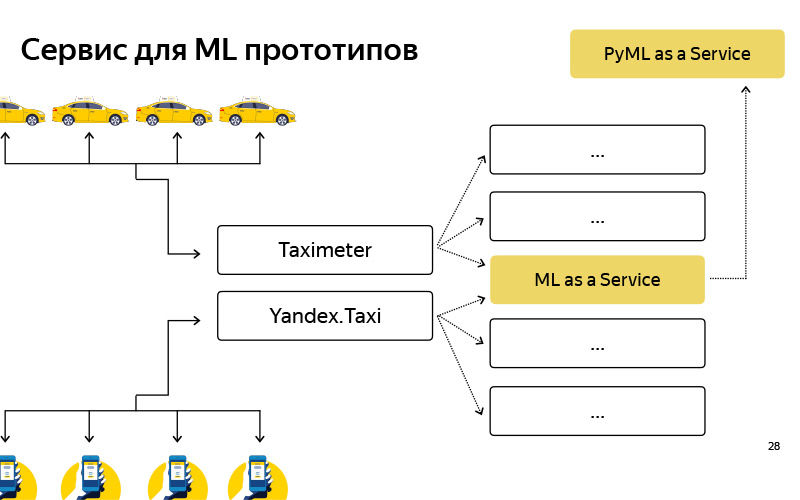
Давайте попробуем эти модели, эти данные использовать. Для этого нужно представить, что из себя представляет сервис Яндекс.Такси. Очень поверхностная схема выглядит так. Есть пользователи, у них есть приложение, а есть водители, у них тоже есть приложение, называется «Таксометр». Эти приложения как-то общаются с бэкэндом, а бэкэнд представляет из себя набор микросервисов, которые между собой общаются — про это рассказывал Илья. Один из микросервисов — наш сервис, наша команда его делает, он называется ML as a Service, MLaaS. Всё, что про него нужно знать, — MLaaS написан на С++, на базе так называемого Fastcgi Daemon. Это опенсорсная библиотека, которая представляет из себя, грубо говоря, фреймворк для написания веб-сервера, который умеет get- и post-запросы, все стандартно. Она когда-то в Яндексе написана, выложена в open source. У нас используется допиленная версия. Что умеет этот сервис? Он умеет работать с моделями: применять их, хранить у себя и иногда обновлять, ходить в это замечательное облако, где модели регулярно обновляются, сохраняются, и скачивать их. Каждой функциональности, например, этим точкам посадки — внутри мы называем их pickup points, — или, например, подсказкам точек Б, про которые Илья говорил и всё время ломал в предыдущем докладе, каждой такой функциональностью, где есть какое-то машинное обучение, соответствует handler, который хранит в себе логику получения запроса, генерации факторов машинного обучения, и применения моделей, и генерации ответа. Разумеется, этот сервис не изолирован, умееть ходить в какие-то дополнительные источники данных, базы данных, какие-то другие микросервисы.
Приблизительно так он устроен, у него довольно простая архитектура. Я не хотел на этом слайде подробно останавливаться, просто хотел сказать, что, условно, архитектура очень простая. Прилетает запрос, есть некоторая фабрика моделей, которая эти модели иногда скачивает из облака. В памяти они хранятся в единственном экземпляре. На каждый запрос создается довольно легковесный объект-модель, которая извлекает фичи, применяется и генерирует ответ. Но что мы имеем к текущему моменту? Я вам уже рассказал, что у нас есть подготовка данных, обучение, разные исследования, эксперименты, и всё это написано на Python Stack, а есть некоторый продакшен, который написан на C++, просто потому что у нас большие требования по эффективности и производительности. Когда живешь в такой экосистеме, возникают две проблемы. В первую очередь, это проблема экспериментов. Например, data scientist'у, который работает у нас в команде, пришла идея. Если запустить какой-нибудь алгоритм кластеризации или классификации чуть с другими параметрами, то можно добиться лучшего качества. Он попробовал проверить свою гипотезу в офлайне, встроился в наш Python-процесс, посчитал, и действительно получается. И теперь он хочет AB-эксперимент, то есть части пользователей показать новый алгоритм и измерить некоторые метрики уже в онлайне: падает ли действительно время подачи, ожидания, растёт ли использование. Для этого ему приходится, условно, пять версий своего алгоритма, в которые он верит, которые в офлайне дают хорошее качество: реализовывать на C++ и проводить AB-эксперимент. И после этого AB-эксперимента, возможно, все пять пойдут в утиль, то есть качество от них в онлайне окажется хуже, чем было в офлайне, то есть хуже, чем в продакшене. То есть процесс экспериментирования занимает большое время из-за того, что, условно, два разных языка, две разных технологии.
Это для существующих фич. А еще есть новые. Когда-то эти pickup points тоже были идеями, которые хотелось быстро проверить. Не тратить на это два месяца разработки — желательно получить что-то за три недели. Создать такой прототип довольно трудоемко. Сперва на Python написать извлечение фич, просто потому что это удобно — move fast, что называется. На Python можно собрать любой прототип, есть много библиотек для анализа данных. Ты поэкспериментировал в своем ноутбуке, а теперь хочешь проверить на пользователях. И сделать прототип получалось довольно тяжело. Мы пришли к тому, что нам нужен какой-то дополнительный сервис, чтобы такие прототипы собирать довольно быстро — условно, за неделю или даже за день, — а также проводить AB-эксперименты.
Мы создали такой сервис, назвали его PyMLaaS. Что он из себя представляет? На самом деле, это полный аналог MLaaS, про который я до этого говорил, но написанный на Python на базе Flask, nginx и Gunicorn. Архитектура довольно простая, такая же, как у MLaaS, но есть возможность в неё быстро впилить какой-нибудь прототип из своих офлайн-экспериментов. Помимо этого мы устроили такое проксирование на уровне nginx, чтобы, условно, у нас была возможность часть нагрузки из MLaaS переправлять в PyMLaaS и тем самым экспериментировать. То есть мы какие-то параметры подвигали и хотим проверить, как это влияет на пользователей. Мы 5% нагрузки пустили на PyMLaaS, и смотрим, что получается в эксперименте. Наконец, удобно создавать прототипы. Создал прототип какой-нибудь новой фичи, впилил его в PyMLaaS и сразу же можешь проверить ее в продакшене. Он нам так понравился, что возникла идея — а почему бы его всё время не использовать? Потому что, условно, есть фичи, которые требуют большой нагрузки, 1000 RPS, большие требования по памяти. Хочется иметь довольно гибкую параллельность. Но для каких-то фич, для каких-то продуктов или сервисов, в которых нет таких больших требований по нагрузке, производительности, RPS и так далее, мы этот сервис вполне успешно используем.
Подведем итоги. Прямо сейчас у нас получилась работающая схема создания продуктов, которые используют машинное обучение. Вначале появляется идея. Мы стараемся быть модными ребятами и проверяем эту идею на данных. Смотрим и готовим данные, ставим какие-то эксперименты, возможно, обучаем модели, смотрим на офлайн-метрики, на какую-то аналитику. Затем мы это реализовываем в виде какого-то хэндлера в PyMLaaS, запускаем AB-эксперимент, пускаем часть нагрузки на этот сервис. Если фича летит, мы ее переносим в MLaaS, и она живет себе, работает и приносит счастье пользователям и водителям. Возвращаясь к задаче про pickup points — гипотеза оказалась верной. Польза от таких точек и рекомендаций удобных мест посадки вполне ощутима. Время подачи автомобиля упало, время ожидания также упало. Сейчас примерно 30% всех поездок осуществляются из точки, которую мы рекомендуем. Большое спасибо за внимание.