Data Science за 3 месяца: эффективный учебный план
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-04-25 02:08
Data Science за 3 месяца? В своем ли мы уме? Вполне. Расскажем, как стать аналитиком данных за 12 недель по курсам Microsoft и др.
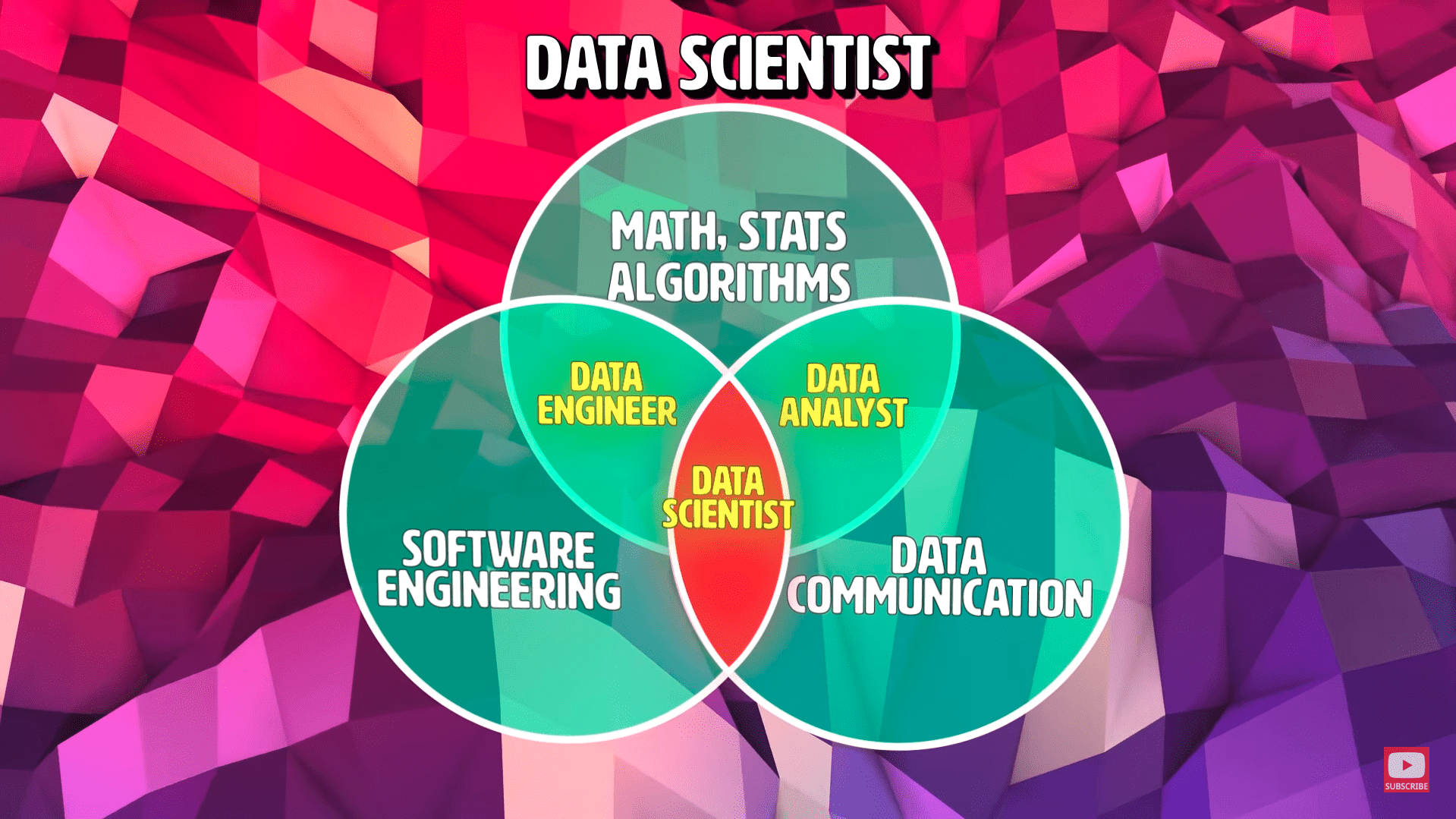
Специалист по анализу данных – одна из самых востребованных специальностей в 2018 году. Маловероятно, что тренд изменится в ближайшие годы. Коммерческие организации тайно или явно собирают все больше клиентских данных, чтобы повысить собственную прибыль. Наука о данных принимает вызовы времени, предлагая новые алгоритмические решения. Однако нехватка специалистов ощущается.
Предлагаемый план самообразования основан на минимальных требованиях, предъявляемых в вакансиях для аналитиков данных. Мы расскажем, как развиться от новичка до специалиста в Data Science за 3 месяца.
По результатам прохождения плана вы вряд ли поступите на службу в компанию, чья деятельность целиком основана на анализе данных. Но при должном усердии сможете зарекомендовать себя в фирму поменьше и начать карьеру аналитика данных. Очевидно, что предлагаемый курс Data Science за 3 месяца – это лишь один из вариантов. Вы можете варьировать продолжительность по своему усмотрению.
Небольшой объем курса позволит понять, интересно ли вам это. В плане используются только общедоступные курсы и свободные образовательные платформы, так что вы не потратите ничего, кроме собственного времени. Деятельность разработчика, так или иначе, связана с операциями над данными, поэтому потраченное время точно не пропадет даром.
Первый месяц в предлагаемом учебном плане посвящен анализу данных, второй – алгоритмам машинного обучения, третий – современным технологиям науки о данных, используемым в реальных проектах – как Spark и Hadoop. Чтобы изучить эти столпы Data Science за 3 месяца, план требует ускоренного обучения. Каждую неделю нужно уделять для занятий минимум 10 часов. Но не делайте это за один раз, гораздо эффективнее заниматься каждый день по 2-3 часа.
Многие лекторы говорят довольно медленно, так как в процессе говорения думают о наилучшем преподнесении речи. Не бойтесь ускорять видео и проматывать понятные моменты. Ускоренное обучение позволяет тратить меньше времени на прокрастинацию. Ведите текстовые записи, заносите в конспект новые идеи, чтобы вернуться к ним при обсуждении свежего материала. Чтобы закрепить полученные знания, в конце недели делайте один небольшой проект с применением освоенной технологии.
Специалистам по анализу данных обычно нет необходимости изучать все особенности используемого ими языка. Для курса Data Science за 3 месяца гораздо правильнее положиться на практику. В этом смысле идеально подходит Python. Понимание основных концепций не займет много времени. Плюс Python настолько популярен, что при возникновении любых трудностей ответ находится за считанные секунды.
Как же изучить самое необходимое, не отвлекаясь на пока ненужные аспекты? К счастью, Microsoft разработал специальный курс Introduction to Python for Data Science.

Курс как раз учит самому важному из Python, а также применению наиболее популярных сторонних библиотек: NumPy (работа с массивами чисел), Matplotlib (визуализация данных) и Pandas (обработка датасетов). В качестве дополнения вы можете посмотреть видео из соответствующего YouTube списка Сираджа Равала, предложившего этот план и набор курсов.
Вторая неделя плана посвящена основам теории вероятностей и математической статистики при помощи Khan Academy. Усилиями мощной команды этот ресурс прогрессирует с каждым годом и уже давно превратился из сборника образовательных видео в мощную платформу с наглядной визуализацией данных и тестами в интерактивной игровой форме.
Курс включает все необходимые базовые понятия из указанных дисциплин.
Чтобы правильно использовать данные для анализа, важно уметь их подготавливать, «чистить» и правильным образом визуализировать. Это не так уж просто. Облегчить задачу поможет курс Georgia Tech на edX.

Кроме вышеперечисленного, в этом курсе вы узнаете, как пользоваться блокнотами Jupyter – одним из наиболее популярных средств представления результатов работы аналитиков данных.
Если вы интересуетесь Data Science, то наверняка слышали о Kaggle. Это не только сайт, на котором аналитики выигрывают денежные призы в конкурсах по машинному обучению, но и гостеприимное сообщество. На Kaggle имеются подборки курсов, которые помогут вам быстрее влиться в Data Science комьюнити.
Ничто не учит лучше специфике работы, чем конкретизированная практика. На четвертой неделе выберите один из несложных проектов Kaggle, который заинтересует вас сильнее прочих. Ничего страшного, если вы не сможете предложить лучшее решение. Зато поймете на деле, чем фактически занимаются аналитики данных.
Создайте репозиторий своего решения на GitHub. Не пренебрегайте документацией и помните, что профиль GitHub может служить вашим резюме (здесь мы объяснили, что это такое, простыми словами).
Наступила пора познакомиться с базовыми алгоритмами и основными идеями машинного обучения. Соответствующему курсу на edX нужно уделить, по крайней мере, две недели: первую – всем трем разделам по алгоритмам, а вторую – теории и практике машинного обучения.

Одним из главных и популярных типов алгоритмов машинного обучения являются нейронные сети. Самым цитируемым пособием по применению нейронных сетей в сфере искусственного интеллекта является регулярно дополняемая книга по глубокому обучению Иэна Гудфеллоу и соавторов.
В конце второго месяца выполните проект Kaggle, учитывая полученные фундаментальные знания в области машинного обучения и Deep Learning. Терминология на форуме Kaggle станет вам уже гораздо более понятной.
Пока мы говорили только об анализе данных, но практически ничего об их хранении и обращении к ним. Курс по реляционным базам данных на Udacity дает краткое, но вполне достаточное для начала работы представление о базах данных, подобных SQL.

Другой короткий курс по NoSQL от Microsoft позволит ознакомиться с отличиями, связанными с нереляционными базами данных.

Объемы данных, которыми оперируют аналитики в коммерческих организациях, не позволяют работать с ними, сохранив на персональном компьютере. Эта проблема возникла давно и потребовала нового стиля обработки больших данных. Наиболее популярными инструментами в этом плане стали Hadoop и MapReduce, которым посвящен соответствующий курс Cloudera.

Новым популярным инструментом стал Spark, который для удобства вы можете рассматривать как расширение Hadoop. Чтобы ознакомиться с инструментом, изучите эту презентацию.
Одной из частых проблем аналитиков данных является их слишком «инженерная» погруженность в задачу, неумение представить информацию. Аналитики данных не всегда корректно могут донести заказчику, что им необходимо знать относительно данных, и что они могут дать в ответ. Избавиться от подобных проблем поможет соответствующий курс Microsoft Analytics Storytelling for Impact.

Аналогично первым двум месяцам, в конце третьего мы предлагаем реализовать вам проект Kaggle с большими данными. Возьмите тот, который максимально интересен вам по самой концепции, чтобы было приятно писать о нем в своем резюме. Приложите максимум усилий и используйте все полученные за три месяца знания.
После прохождения курса, как говорилось вначале, вы можете попробоваться на одну из вакансий, которой будете соответствовать по требованиям. Не ограничивайте себя российскими биржами труда. Не пренебрегайте стажировками и продолжайте свое обучение – выделите для себя, какие инструменты из интересующих вакансий встречаются чаще прочих.
Кстати, ведь даже задачу поиска вакансии в области Data Science можно оптимизировать при помощи Data Science. Дерзайте!
Телеграм: t.me/ainewsline
Источник: proglib.io