Семь мифов в области исследований машинного обучения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-03-20 09:15
Миф 1: TensorFlow – это библиотека для работы с тензорами
На самом деле, это библиотека для работы с матрицами, и эта разница весьма существенна.
В работе Computing Higher Order Derivatives of Matrix and Tensor Expressions. Laue et al. NeurIPS 2018 авторы демонстрируют, что их библиотека автоматического дифференцирования, основанная на реальном тензорном исчислении, имеет гораздо более компактные деревья выражений. Дело в том, что тензорное исчисление использует индексные обозначения, что позволяет одинаково работать с прямым и обратным режимом. Матричное счисление прячет индексы для удобства обозначения, из-за чего деревья выражений автоматического дифференцирования часто становятся слишком сложными. Рассмотрим перемножение матриц C=AB. У нас есть для прямого режима и для обратного. Чтобы правильно выполнить перемножение, нужно точно соблюдать порядок и использования переносов. Для человека, занимающегося МО, с точки зрения записи это выглядит запутанно, а с точки зрения вычислений это лишняя нагрузка для программы.
Другой пример, менее тривиальный: c=det(A). У нас есть для прямого режима и для обратного. В данном случае очевидно невозможно использовать дерево выражений для обеих режимов, учитывая, что они состоят из разных операторов.
В целом, то, как TensorFlow и другие библиотеки (к примеру, Mathematica, Maple, Sage, SimPy, ADOL-C, TAPENADE, TensorFlow, Theano, PyTorch, HIPS autograd) реализовали автоматическое дифференцирование, приводит к тому, что для прямого и обратного режима строятся разные и неэффективные деревья выражений. Тензорное счисление обходит эти проблемы, благодаря коммутативности перемножения из-за индексной записи. Подробности того, как это работает, см. в научной работе.
Авторы проверяли свой метод, выполняя автоматическое дифференцирование обратного режима, также известное, как обратное распространение, на трёх различных задачах, и измеряли время, потребовавшееся для вычисления гессианов.

На CPU их метод оказался на два порядка быстрее таких популярных библиотек, как TensorFlow, Theano, PyTorch, и HIPS autograd.
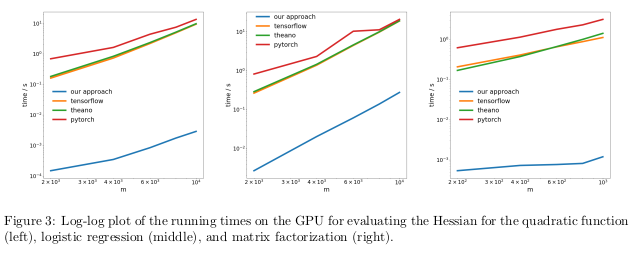
Вычисление производных для функций второго или более высокого порядка при помощи текущих библиотек глубокого обучения слишком дорого с вычислительной точки зрения. Сюда входят вычисления общих тензоров четвёртого порядка типа гессианов (к примеру, в MAML и ньютоновской оптимизации второго порядка). К счастью, квадратичные формулы встречаются в глубоком обучении нечасто. Однако они часто встречаются в «классическом» машинном обучении – SVM, метод наименьших квадратов, LASSO, гауссовские процессы, и т.п.
Миф 2: Базы данных изображений отражают реальные фотографии, встречающиеся в природе
Многим нравится думать, что нейросети научились распознавать объекты лучше людей. Это не так. Они могут опережать людей на базах избранных изображений, например, ImageNet, но в случае распознавания объектов с реальных фотографий из обычной жизни они определённо не смогут обогнать обычного взрослого человека. Всё потому, что выборка изображений в текущих наборах данных не совпадает с выборкой всех возможных изображений естественным образом встречающихся в реальности.
В довольно старой работе Unbiased Look at Dataset Bias. Torralba and Efros. CVPR 2011., авторы предложили исследовать искажения, связанные с набором изображений в двенадцати популярных базах, выяснив, можно ли обучить классификатор определять набор данных, из которого было взято данное изображение.



Так какова же ценность имеющихся наборов данных для обучения алгоритмов, предназначенных для реального мира? Получающийся ответ можно описать, как «лучше, чем ничего, но не сильно».
Миф 3: Исследователи МО не используют проверочные наборы для испытаний
В учебнике по машинному обучению нас учат делить набор данных на обучающий, оценочный и проверочный. Эффективность модели, обученной на обучающем наборе, и оцененной на оценочном помогает человеку, занимающемуся МО, подстраивать модель для максимизации эффективности при её реальном использовании. К проверочному набору не нужно прикасаться, пока человек не закончит подстройку, чтобы обеспечить непредвзятую оценку реальной эффективности работы модели в реальном мире. Если человек жульничает, используя проверочный набор на этапах обучения или оценки, модель рискует стать слишком сильно приспособленной для определённого набора данных.
В гиперконкурентном мире исследований МО новые алгоритмы и модели часто оценивают по эффективности их работы с проверочными данными. Поэтому для исследователей нет смысла писать или публиковать работы, где описываются методы, плохо работающие с проверочными наборами данных. А это, по сути, означает, что сообщество МО в целом использует проверочный набор для оценки.
Каковы последствия этого жульничества?


Миф 4: В обучении нейросети используются все входные данные
Принято считать, что данные – это новая нефть, и что чем больше у нас данных, тем лучше мы сможем обучить модели для глубокого обучения, которые сейчас неэффективны по образцам [sample-inefficient] и перепараметризированы [overparametrized]. В работе An Empirical Study of Example Forgetting During Deep Neural Network Learning. Toneva et al. ICLR 2019 авторы демонстрируют значительную избыточность в нескольких распространённых наборах небольших изображений. Удивительно, но 30% данных из CIFAR-10 можно просто убрать, не изменив точность проверки на значительную величину.
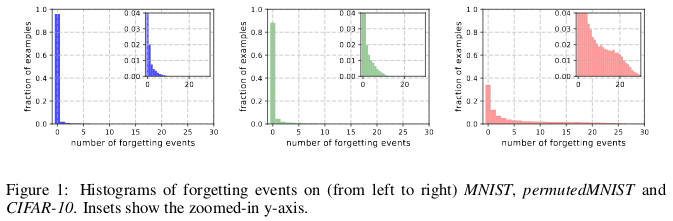
Забывание случается, когда нейросеть неправильно классифицирует изображение в момент времени t+1, в то время как в момент времени t ей удалось правильно классифицировать изображение. Течение времени измеряется обновлениями SGD. Чтобы отслеживать забывания, авторы запускали свою нейросеть на небольшом наборе данных после каждого обновления SGD, а не на всех примерах, имеющихся в базе. Примеры, не подверженные забыванию, называются незабываемыми примерами.
Они обнаружили, что 91.7% MNIST, 75.3% permutedMNIST, 31.3% CIFAR-10 и 7.62% CIFAR-100 составляют незабываемые примеры. Интуитивно это понятно, поскольку увеличение разнообразия и сложности набора данных должно заставлять нейросеть забывать больше примеров.

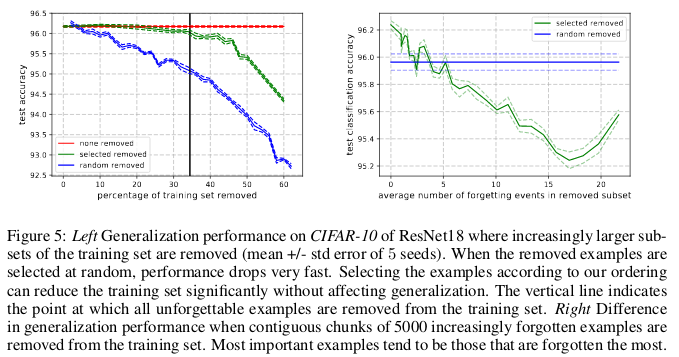
Если мы сможем определить, какие из данных являются незабываемыми, до начала обучения, то мы можем сэкономить место, удалив их, и время, не используя их при обучении нейросети.
Миф 5: Для обучения очень глубоких остаточных сетей требуется пакетная нормализация
Долгое время считалось, что «обучение глубокой нейросети для прямой оптимизации только для контролируемой цели (к примеру, логарифмической вероятности правильной классификации) при помощи градиентного спуска, начиная со случайных параметров, работает плохо».
Появившаяся с тех пор куча хитроумных методов случайной инициализации, функций активации, техник оптимизации и других инноваций, таких, как остаточные связи, облегчил обучение глубоких нейросетей методом градиентного спуска.
Но реальный прорыв случился после ввода пакетной нормализации (и других последовательных техник нормализации), ограничивающей размер активаций для каждого слоя сети, чтобы устранить проблему исчезающих и взрывных градиентов.
В недавней работе Fixup Initialization: Residual Learning Without Normalization. Zhang et al. ICLR 2019 было показано, что возможно обучить сеть с 10 000 слоёв используя чистый SGD, не применяя никакой нормализации.



Миф 6: Сети с вниманием лучше свёрточных
В сообществе исследователей МО набирает популярность идея, что механизмы «внимания» превосходят по возможностям свёрточные нейросети. В работе Vaswani и коллег отмечено, что «вычислительные затраты на отделяемые свёртки равны комбинации слоя с самовниманием [self-attention layer] и точечного перематывающего слоя [point-wise feed-forward layer]». Даже передовые генеративно-состязательные сети показывают преимущество самовнимания перед стандартными свёртками при моделировании дальнодействующих зависимостей. Авторы работы Pay Less Attention with Lightweight and Dynamic Convolutions. Wu et al. ICLR 2019 ставят под сомнение параметрическую эффективность и действенность самовнимания при моделировании дальнодействующих зависимостей, и предлагают новые варианты свёрток, частично вдохновлённых самовниманием, более эффективные с точки зрения параметров.
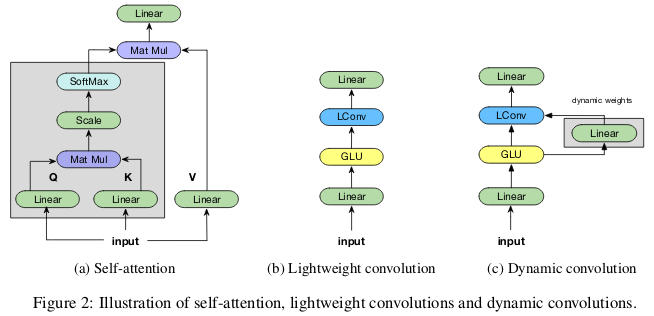

Миф 7: Карты значимости – надёжный способ интерпретации нейросетей
Хотя существует мнение о том, что нейросети – это чёрные ящики, было сделано огромное множество попыток их интерпретации. Наиболее популярными из них служат карты значимости, или другие сходные методы, назначающие оценки важности особенностям или обучающим примерам.
Соблазнительно иметь возможность заключить, что данное изображение было определённым образом классифицировано из-за определённых частей изображения, значимых для нейросети. Для вычисления карт значимости существует несколько способов, которые часто используют активацию нейросетей на заданном изображении и градиенты, проходящие через сеть.
В работе Interpretation of Neural Networks is Fragile. Ghorbani et al. AAAI 2019 авторы показывают, что могут ввести неуловимое изменение в картинку, которое, тем не менее, исказит её карту значимости.


В связи со всё большим распространением глубокого обучения в таких критически важных областях применения, как обработка медицинских изображений, важно осторожно подходить к вопросу интерпретации решений, сделанных нейросетями. К примеру, хотя было бы здорово, если бы свёрточная нейросеть могла опознать пятно на МРТ-снимке как злокачественную опухоль, этим результатам не стоит доверять, если они основаны на ненадёжных методах интерпретации.
Телеграм: t.me/ainewsline
Источник: habr.com