Книга «Прикладной анализ текстовых данных на Python»
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-03-20 09:15

О чем рассказывается в этой книге
В этой книге рассказывается о применении методов машинного обучения для анализа текста с использованием только что перечисленных библиотек на Python. Прикладной характер книги предполагает, что мы сосредоточим свое внимание не на академической лингвистике или статистических моделях, а на эффективном развертывании моделей, обученных на тексте внутри приложения.
Предлагаемая нами модель анализа текста напрямую связана с процессом машинного обучения — поиска модели, состоящей из признаков, алгоритма и гиперпараметров, которая давала бы лучшие результаты на обучающих данных, с целью оценки неизвестных данных. Этот процесс начинается с создания обучающего набора данных, который в сфере анализа текстов называют корпусом. Затем мы исследуем методы извлечения признаков и предварительной обработки для представления текста в виде числовых данных, понятных методам машинного обучения. Далее, познакомившись с некоторыми основами, мы перейдем к исследованию приемов классификации и кластеризации текста, рассказ о которых завершает первые главы книги.
В последующих главах основное внимание уделяется расширению моделей более богатыми наборами признаков и созданию приложений анализа текстов. Сначала мы посмотрим, как можно представить и внедрить контекст в виде признаков, затем перейдем к визуальной интерпретации для управления процессом выбора модели. Потом мы посмотрим, как анализировать сложные отношения, извлекаемые из текста с применением приемов анализа графов. После этого обратим свой взгляд в сторону диалоговых агентов и углубим наше понимание синтаксического и семантического анализа текста. В заключение книги будет представлено практическое обсуждение приемов масштабирования анализа текста в многопроцессорных системах с применением Spark, и, наконец, мы рассмотрим следующий этап анализа текста: глубокое обучение.
Кому адресована эта книга
Эта книга адресована программистам на Python, интересующимся применением методов обработки естественного языка и машинного обучения в своих программных продуктах. Мы не предполагаем наличия у наших читателей специальных академических или математических знаний и вместо этого основное внимание уделяем инструментам и приемам, а не пространным объяснениям. В первую очередь в этой книге обсуждается анализ текстов на английском языке, поэтому читателям пригодится хотя бы базовое знание грамматических сущностей, таких как существительные, глаголы, наречия и прилагательные, и того, как они связаны между собой. Читатели, не имеющие опыта в машинном обучении и лингвистике, но обладающие навыками программирования на Python, не будут чувствовать себя потерянными при изучении понятий, которые мы представим.
Отрывок. Извлечение графов из текста
Извлечение графа из текста — сложная задача. Ее решение обычно зависит от предметной области, и, вообще говоря, поиск структурированных элементов в неструктурированных или полуструктурированных данных определяется контекстно-зависимыми аналитическими вопросами.
Мы предлагаем разбить эту задачу на более мелкие шаги, организовав простой процесс анализа графов, как показано на рис. 9.3.
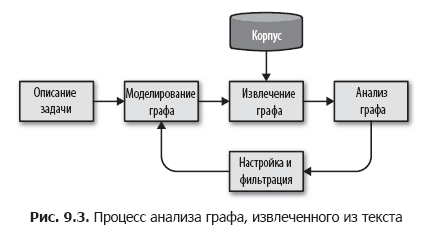
Создание социального графа
Рассмотрим наш корпус новостных статей и задачу моделирования связей между разными сущностями в тексте. Если рассматривать вопрос различий в охвате между разными информационными агентствами, можно построить граф из элементов, представляющих названия публикаций, имена авторов и источники информации. А если целью является объединение упоминаний одной сущности во множестве статей, в дополнение к демографическим деталям наши сети могут зафиксировать форму обращения (уважительную и другие). Интересующие нас сущности могут находиться в структуре самих документов или содержаться непосредственно в тексте.
Допустим, наша цель — выяснить людей, места и все что угодно, связанные друг с другом в наших документах. Иными словами, нам нужно построить социальную сеть, выполнив серию преобразований, как показано на рис. 9.4. Начнем конструирование графа с применения класса EntityExtractor, созданного в главе 7. Затем добавим преобразователи, один из которых отыскивает пары связанных сущностей, а второй преобразует эти пары в граф.
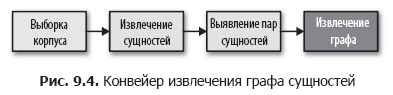
Наш следующий шаг — создание класса EntityPairs, который получает документы в виде списков сущностей (созданных классом EntityExtractor из главы 7). Этот класс должен действовать как преобразователь в конвейере Pipeline из Scikit-Learn, а значит, наследовать классы BaseEstimator и TransformerMixin, как рассказывалось в главе 4. Предполагается, что сущности в одном документе безусловно связаны друг с другом, поэтому добавим метод pairs, использующий функцию itertools.permutations для создания всех возможных пар сущностей в одном документе. Наш метод transform будет вызывать pairs для каждого документа в корпусе:
import itertools from sklearn.base import BaseEstimator, TransformerMixin class EntityPairs(BaseEstimator, TransformerMixin): def __init__(self): super(EntityPairs, self).__init__() def pairs(self, document): return list(itertools.permutations(set(document), 2)) def fit(self, documents, labels = None): return self def transform(self, documents): return [self.pairs(document) for document in documents]Теперь можно последовательно извлечь сущности из документов и составить пары. Но мы пока не можем отличить пары сущностей, встречающихся часто, от пар, встречающихся только один раз. Мы должны как-то закодировать вес связи между сущностями в каждой паре, чем мы и займемся в следующем разделе.
Графы свойств
Математическая модель графа определяет только наборы узлов и ребер и может быть представлена в виде матрицы смежности (adjacency matrix), которой можно пользоваться в самых разных вычислениях. Но она не поддерживает механизм моделирования силы или типов связей. Появляются ли две сущности только в одном документе или во многих? Встречаются ли они вместе в статьях определенного жанра? Для поддержки подобных рассуждений нам нужен некий способ, позволяющий сохранить значимые свойства в узлах и ребрах графа.
Модель графа свойств позволяет встроить в граф больше информации, тем самым расширяя наши возможности. В графе свойств узлами являются объекты с входящими и исходящими ребрами и, как правило, содержащие поле type, напоминая таблицу в реляционной базе данных. Ребра — это объекты, определяющие начальную и конечную точки; эти объекты обычно содержат поле label, идентифицирующее тип связи, и поле weight, определяющее силу связи. Применяя графы для анализа текста, в роли узлов мы часто используем существительные, а в роли ребер — глаголы. После перехода к этапу моделирования это позволит нам описать типы узлов, метки связей и предполагаемую структуру графа.
Об авторах
Бенджамин Бенгфорт (Benjamin Bengfort) — специалист в области data science, живущий в Вашингтоне, внутри кольцевой автострады, но полностью игнорирующий политику (обычное дело для округа Колумбия) и предпочитающий заниматься технологиями. В настоящее время работает над докторской диссертацией в Университете штата Мериленд, где изучает машинное обучение и распределенные вычисления. В его лаборатории есть роботы (хотя это не является его любимой областью), и к его большому огорчению, помощники постоянно вооружают этих роботов ножами и инструментами, вероятно, с целью победить в кулинарном конкурсе. Наблюдая, как робот пытается нарезать помидор, Бенджамин предпочитает сам хозяйничать на кухне, где готовит французские и гавайские блюда, а также шашлыки и барбекю всех видов. Профессиональный программист по образованию, исследователь данных по призванию, Бенджамин часто пишет статьи, освещающие широкий круг вопросов — от обработки естественного языка до исследования данных на Python и применения Hadoop и Spark в аналитике.
Д-р Ребекка Билбро (Dr. Rebecca Bilbro) — специалист в области data science, программист на Python, учитель, лектор и автор статей; живет в Вашингтоне (округ Колумбия). Специализируется на визуальной оценке результатов машинного обучения: от анализа признаков до выбора моделей и настройки гиперпараметров. Проводит исследования в области обработки естественного языка, построения семантических сетей, разрешения сущностей и обработки информации с большим количеством измерений. Как активный участник сообщества пользователей и разработчиков открытого программного обеспечения, Ребекка с удовольствием сотрудничает с другими разработчиками над такими проектами, как Yellowbrick (пакет на языке Python, целью которого является прогнозное моделирование на манер черного ящика). В свободное время часто катается на велосипедах с семьей или практикуется в игре на укулеле. Получила докторскую степень в Университете штата Иллинойс, в Урбана-Шампейн, где занималась исследованием практических приемов коммуникации и визуализации в технике.
» Более подробно с книгой можно ознакомиться на сайте издательства » Оглавление » Отрывок Для Хаброжителей скидка 20% по купону — Python
По факту оплаты бумажной версии книги на e-mail высылается электронная версия книги.
P.S.: 7% от стоимости книги пойдет на перевод новых компьютерных книг, список сданных в типографию книг здесь.
Телеграм: t.me/ainewsline
Источник: habr.com