Классификация текста на примере фильтрования спама в VK
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-03-24 14:31
свёрточные нейронные сети, работа головного мозга, компьютерная лингвистика
14 марта в Казани на VK Tech Talks выступил с речью о классификации текста, приведя в пример фильтрацию спама в VK с применением алгоритмов нейронных сетей.
В первую очередь речь заходит о необходимости быстрой, но при этом качественной классификации текста в VK, и ярким примером служит спам на просторах социальной сети.
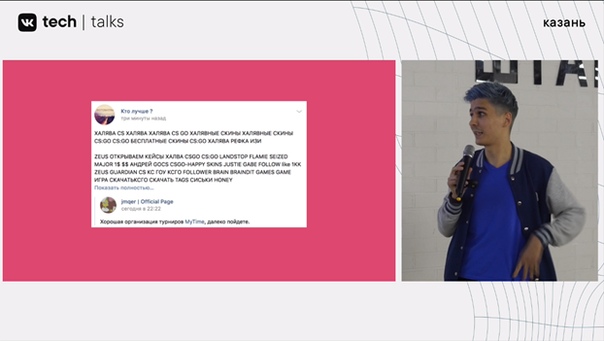
Избавиться от подобных случаев можно, но для начала стоит понять, что из себя представляет так называемый «плохой» текст. И именно тут термин текстовой классификации приходится как нельзя кстати.

Понятно, что в 2019 году без нейросетей с такими задачи справиться будет не слишком просто, да и вопрос удобства тут тоже играет роль. В пример приводится deep learning NLP и начало карьеры с bi-LSTM в 2015 году, где выполнение задачи, которая делалась бы сугубо вручную, было куда более удобным, хоть и не слишком быстрым методом.

«Вот, пример, двунаправленная LSTM. Здесь мы “прогоняем” последовательность в одну сторону, пытаясь определить очевидный кликбейт, потом делаем то же самое, но наоборот, берём последнее скрытое состояние из первого прогона, последнее скрытое состояние из второго прогона, объединяем и, соответственно, решаем эту задачу. Это, в целом, эффективно, но супер-медленно. И это необходимо ускорить».

Вскользь упоминается, что bi-LSTM чуть позже использовался в сочетании с Theano, но это не оказалось достаточно быстрым.
Эволюция нейронных сетей в сфере классификации текстовых задач.
Последовал переход на «свёртки» (свёрточная нейронная сеть, она же CNN, она же convolutional neural network) вместе с Tensor Flow. Сочетание TF + CNN дало куда более эффективные результаты по сравнению с первыми шагами в использовании нейронных сетей для алгоритмов классификации сетей.

Но помимо необходимости работать быстрее возникает нужда, мало того, чтобы сохранить качество работы, так ещё и улучшить его, распознавать текст лучше. Возникает проблема «шумных» пользовательских данных.
Один из пользователей, студент Стэндфорского университета (Alex R. Kuefler), решил интегрировать inception блоки прямо в текст. Это позволяет работать с кусочками текста разной длины и для фильтрации «шумного» текста нет необходимости преодолеть порог с опечатками, нарочитыми исправлениями, отсутствием пробелов. Встроенные inception блоки позволяют это делать прямо на ходу.

Как всё это выглядит на реальном примере:

Слитный текст автоматически, без какого-либо обучения и ручного размещения, разбивается на связанную фразу, с ориентиром на суффиксы в разных словах. И это очень удобно. Но, опять же, эффективность снизила пресловутую скорость, к которой так все стремились, хоть и незначительно.
Attention & Self-Attention/Intra-Attention

Речь заходит о несовершенстве механизма, когда данные новой последовательности генерируются из последнего скрытого слоя. Механизм Attention предлагает в автоматическом режиме обращаться к предыдущим данным скрытых состояний, совершенствуя результат своеобразным способом самопроверки.

Но этот способ работает при условии, что используется incoder. Но в нашем случае нет никакого incoder-decoder’а. Поэтому стоит прибегнуть к использованию Self-Attention (он же Intra-Attention). Ключевое отличие от предыдущего способа — возможность пересечь все скрытые состояния для получения более точного итогового результата.
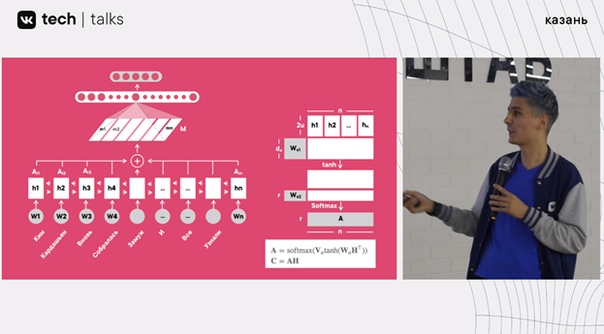

И, опять же, всё это — эффективно, но недостаточно быстро. И снова необходимо как-то ускорить процесс. Следует переход на PyTorch+DAN (deep averaging network), гибрид которых показывает практически пятикратную разницу, приведённую на скриншоте выше.
Подведя итоги, можно сказать, что ничего прорывного и инновационного изобретено не было, но, сравнивая текущее состояние работы алгоритмов классификации текста в VK и работу подобных систем в 2015 году, можно заметить, что как минимум виден глобальный скачок вперёд, благодаря которому сейчас самые слабые фильтры в тех же пабликах работают мгновенно и без необходимости заполнять суффиксно-приставочную базу (и это лишь один из примеров!) одного и того же слова.
Полная версия доклада:
и современных технологиях
Телеграм: t.me/ainewsline
Источник: m.vk.com