Какие deep learning фреймворки использует VK и почему
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-03-22 19:45
разработка по, алгоритмы машинного обучения, реализация нейронной сети
На прошедшем в Казани 14 марта VK Tech Talks первым выступил Даниил Гаврилов с докладом на тему deep learning фреймворков и их применению.
Есть два основных фреймворка, которые сейчас используются во «ВКонтакте», и они в некоторой степени представляют собой два основных способа решить задачу: написать функцию и взять к ней производную, чтобы получить модель.
Первый из них: TensorFlow — библиотека, которая была представлена Google ещё в 2014 году. При помощи TensorFlow описывается граф вычислений, который мы компилируем где-то на бекэнде TensorFlow'а:

Вот простейший пример:

По-началу может показаться, что здесь происходят достаточно очевидные вещи, но на самом деле на фоне происходят вещи достаточно нетривиальные, потому что в этой части описывается граф, а не выполняется какой-либо код, высчитывающий что-либо.
Также, имея этот граф, можно легко посчитать производные к тем или иным параметрам.
Плюсы и минусы статичных графов вычислений:

Второй фреймворк, который активно используется — PyTorch. Он появился на год позже, чем TensorFlow. Фреймворк решает нашу задачу достаточно альтернативным способом.

В динамичной манере этот код вместе с выполнением программы строит граф. Построив этот граф во время прогона кода мы снова можем взять производную, как это было в TensorFlow.
Если мы попытаемся написать какую-нибудь достаточно простую функцию, как в первом примере, то она будет выглядеть примерно так:

При этом, поскольку граф строится при помощи методов самого языка, мы можем заметить, что случаи, который были в TensorFlow проблемными, теперь решаются достаточно просто.
Плюсы и минусы динамических графов вычислений:

Что выходит в сравнении?
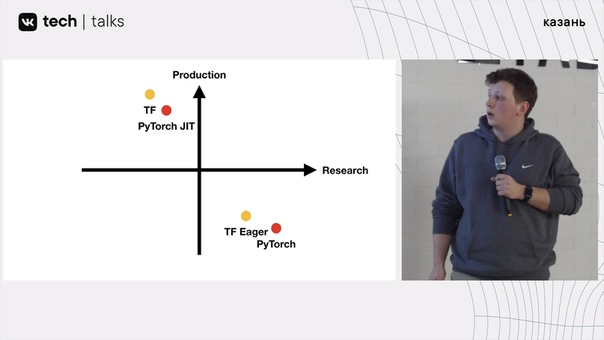
Возьмём и построим небольшой график на плоскости с осями: research по x и production по y. TensorFlow будет находиться во второй четверти координатной оси, а PyTorch в четвёртой четверти.

Что изменилось к 2019 году?
Во-первых, разработчики TensorFlow понимают, что тот инструментарий, который они предоставляют для того, чтобы решать ту или иную задачу, плох для ресёрча и, в частности, хочется иметь динамичное выполнение графов.

Теперь TensorFlow Eager находится рядом с PyTorch.

Torch в свою очередь представляет компиляцию своих моделей. Если мы возьмем код на Python и с помощью специальных декораторов напишем его в, так называемый, Torchscript, который представляет собой сабмодуль Python, который на самом деле представляет собой статичный граф. И мы при помощи метода самого Python'а используем статичный граф, который в последствии можем импортировать в произвольном месте.

Теперь же PyTorch JIT находится рядом с TensorFlow:
В действительности можно заметить, что обе эти библиотеки пришли примерно к одному и тому же, потому что, если мы с Вами напишем модуль на Torch'e:

После этого пишем то же самое на TensorFlow 2.0, то мы получим примерно такую же картину:
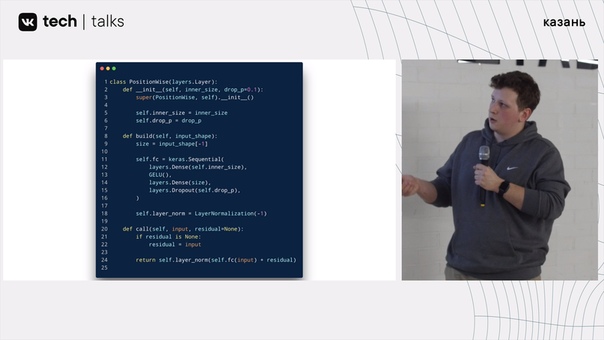
Однако, не смотря на то, что TensorFlow в 2019 году начал выглядеть, как PyTorch, происходит небольшая проблема, что внутри он все равно остаётся TensorFlow.

Снова посмотрим на график. Заметим, что все эти библиотеки находятся во второй или четвёртой плоскостях, но на деле хочется в первую плоскость, в котором будет удобно делать research и удобно выкатывать в production.

Как нам попасть в правый верхний угол? Какие критерии должны быть в фреймворка, чтобы туда попасть?

На самом то деле, проблема не в статичных графах, а в DSL:

Можем заметить, что PyTorch в свою очередь эти статичные графы строит с помощью методов языков и самого языка, оборачивая его в Torchscript.

И вот, мы приходим к тому, что для того, чтобы попасть в тот самый правый верхний угол нам нужно встроит фреймворк непосредственно в язык:

Многие значит, что такое Swift, и многие думают, что это язык просто для iOS разработки, но это не совсем так, потому что, появившись ещё в 2014 году, он непрерывно развивался, и с тех пор на нём, если очень хочется, можно даже написать бекэнд. Это кажется очень странной затеей, но факт остаётся фактом.

Так, например выглядит то, что можно сейчас найти про Swift на TensorFlow:

Может возникнуть вопрос: зачем вообще тащить этот Swift в разработку? Google добавила возможность импортировать Python и произвольные библиотеки в Swift.

Самое главное, что Swift for TensorFlow очень активно развивается и сейчас уже есть реальные примеры того, что с ним можно сделать, и есть не просто сам Swift, который перестраивается для того, чтобы работать с TensorFlow'ом, также есть различные модели и модуль для глубокого обучения, которые написаны на Swift'e.

Вот и всё!
Посмотреть полную версию доклада можно в трансляции мероприятия:

и современных технологиях
Автор: Сергей Котов Корректор: Арсений Метелев
Телеграм: t.me/ainewsline
Источник: m.vk.com