Демистифицируем свёрточные нейросети
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-03-13 07:27

В прошлом десятилетии мы наблюдали удивительный и беспрецедентный прогресс в сфере компьютерного зрения. Сегодня компьютеры умеют распознавать объекты на изображениях и кадрах видео с точностью до 98 %, уже опережая человека с его 97 %. Именно функции человеческого мозга вдохновляли разработчиков при создании и совершенствовании методик распознавания.
Когда-то неврологи проводили эксперименты на кошках и выяснили, что одни и те же части изображения активируют одни и те же части кошачьего мозга. То есть когда кошка смотрит на круг, в её мозге активируется зона «альфа», а когда смотрит на квадрат, активируется зона «бета». Исследователи пришли к выводу, что в мозге животных есть области нейронов, реагирующие на конкретные характеристики изображения. Иными словами, животные воспринимают окружающую среду через многослойную нейронную архитектуру мозга. И каждая сцена, каждый образ проходит через своеобразный блок выделения признаков, и только потом передаётся в более глубокие структуры мозга.
Вдохновлённые этим, математики разработали систему, в которой эмулируются группы нейронов, срабатывающие на разные свойства изображения и взаимодействующие друг с другом для формирования общей картины.
Извлечение свойств
Идею группы активируемых нейронов, которым подаются конкретные входные данные, превратили в математическое выражение многомерной матрицы, играющей роль определителя какого-нибудь набора свойств — его называют фильтром или ядром (kernel). Каждый такой фильтр ищет в изображении какую-то особенность. Например, может быть фильтр для определения границ. Найденные свойства затем передаются другому набору фильтров, которые умеют определять более высокоуровневые свойства изображения, например, глаза, нос и т. д.
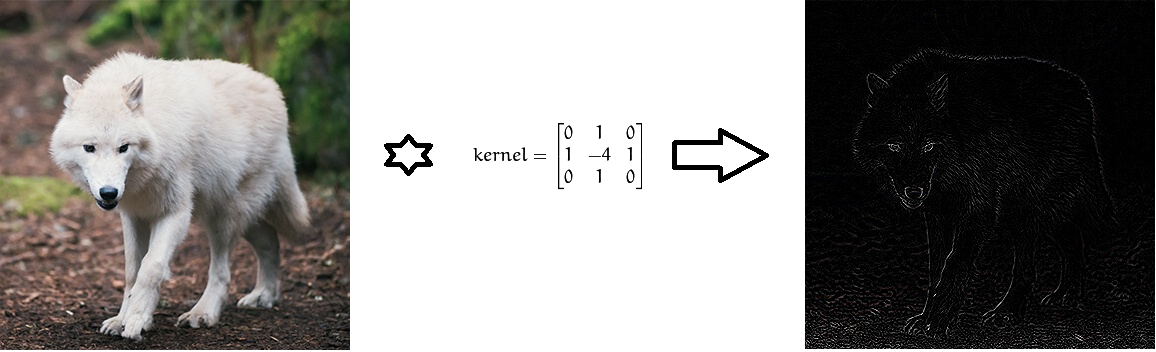
С точки зрения математики, между входным изображением, представленным в виде матрицы интенсивности пикселей, и фильтром мы выполняем операцию свёртки, в результате получая так называемую карту свойств (карту признаков, feature map). Эта карта будет служить входными данными для следующего слоя фильтров.
Почему свёртка?
Свёртка — это процесс, в ходе которого сеть пытается разметить входной сигнал, сравнивая с узнанной ранее информацией. Если входной сигнал выглядит как предыдущие изображения кошек, уже известные сети, то референсный сигнал «кошка» будет свёрнут — смешан — со входным сигналом. Получившийся в результате сигнал передаётся на следующий слой. В данном случае под входным сигналом подразумевается трёхмерное представление картинки в виде интенсивностей RGB-пикселей, а референсный сигнал «кошка» выучен ядром для распознавания кошек.
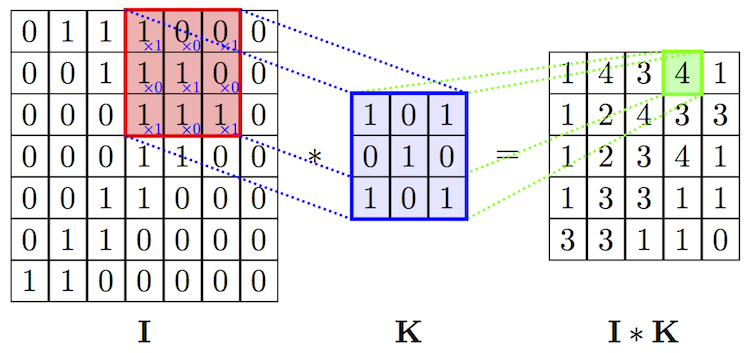
У операции свёртки есть прекрасное свойство — инвариантность относительно переноса (translation invariant). Это означает, что каждый свёрточный фильтр отражает определённый набор свойств, например, глаза, уши и т. д., и алгоритм свёрточной нейросети учится определять, какой набор свойств соответствует референсу, скажем, кошки. Интенсивность выходного сигнала зависит не от местоположения свойств, а от их наличия. Следовательно, кошка может быть изображена в разных позах, но алгоритм всё равно сможет её распознать.
Пулинг (Pooling)
Проследив принцип работы биологического мозга, учёные смогли разработать математический аппарат для извлечения свойств. Но оценив общее количество слоёв и свойств, которые нужно проанализировать для отслеживания сложных геометрических форм, учёные поняли, что для хранения всех данных компьютерам не хватит памяти. Более того, количество необходимых вычислительных ресурсов растёт экспоненциально вместе с ростом количества свойств. Для решения этой проблемы была разработана методика пулинга (pooling). Её идея очень проста: если некая область содержит ярко выраженные свойства, то мы можем отказаться от поиска других свойств в этой области.

Операция пулинга позволяет не только экономить память и вычислительную мощность, но и помогает очистить изображения от шума.
Полностью связанный слой
Ладно, а для чего может пригодиться нейросеть, если она умеет только определять наборы свойств изображения? Нам нужно как-то научить её классифицировать изображения по категориям. И в этом нам поможет традиционный подход к формированию нейросетей. В частности, карты свойств, полученные на предыдущих слоях, можно собрать в слой, полностью связанный со всеми метками, которые мы приготовили для категоризирования. Этот последний слой будет присваивать вероятности соответствия каждому классу. И опираясь на эти финальные вероятности, мы сможем отнести изображение к какой-то категории.
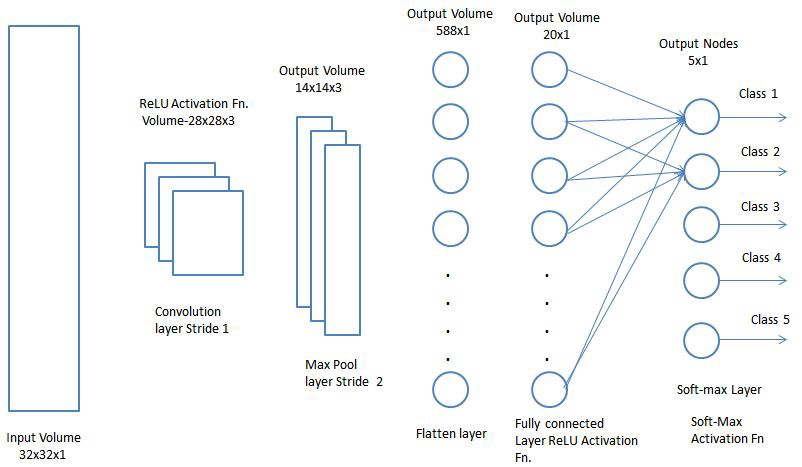
Финальная архитектура
Теперь осталось только объединить все изученные сетью концепции в единый фреймворк — свёрточную нейросеть (Convolution Neural Network, CNN). CNN состоит из серии свёрточных слоёв, которые могут быть объединены со слоями пулинга, чтобы сгенерировать карту свойств, передаваемую в полностью связанные слои для определения вероятностей соответствия каким-либо классам. Возвращая назад получаемые ошибки, мы сможем обучать эту нейросеть вплоть до получения точных результатов.
Теперь, когда мы поняли функциональные перспективы CNN, давайте внимательнее рассмотрим аспекты использования CNN.
Свёрточные нейросети

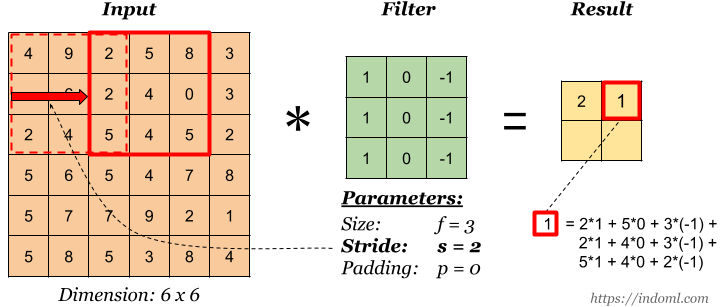
Свёрточный слой — основной строительный блок CNN. Каждый такой слой включает в себя набор независимых фильтров, каждый из которых ищет в поступившем изображении свой набор свойств.
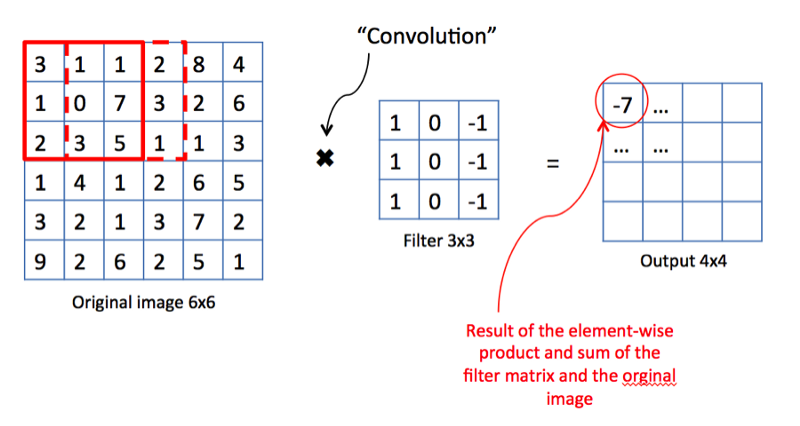
С точки зрения математики мы берём фильтр фиксированного размера, накладываем на изображение и вычисляем скалярное произведение фильтра и кусочка входного изображения. Результаты произведения помещаются в финальную карту свойств. Затем мы сдвигаем фильтр вправо и повторяем операцию, также добавляя результат вычисления в карту свойств. После свёртки всего изображения с помощью фильтра мы получаем карту свойств, которая представляет собой набор явных признаков и подаётся в качестве входных данных на следующий слой.
Страйды
Страйд — это величина смещения фильтра. На приведённой выше иллюстрации мы сдвигаем фильтр с коэффициентом 1. Но иногда нужно увеличить размер смещения. Например, если соседние пиксели сильно коррелируют друг с другом (особенно на нижних слоях), то имеет смысл уменьшить размер выходных данных с помощью соответствующего страйда. Но если страйд сделать слишком большим, то будет теряться много информации, так что будьте внимательны.
Паддинг
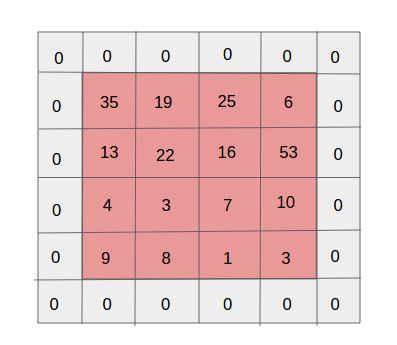
Одним из побочных эффектов страйдинга является последовательное уменьшение карты свойств по мере выполнения всё новых и новых свёрток. Это может быть нежелательно, поскольку «уменьшение» означает потерю информации. Чтобы стало понятнее, обратите внимание на количество применений фильтра к ячейке в средней части и в углу. Получается, что безо всяких причин информация в средней части оказывается важнее, чем по краям. И чтобы извлечь полезную информацию из более ранних слоёв, можно окружить матрицу слоями из нулей.
Совместное использование параметров
Зачем нужны свёрточные сети, если у нас уже есть хорошие нейросети глубокого обучения? Примечательно, что если воспользоваться для классификации изображений сетями глубокого обучения, количество параметров на каждом слое будет в тысячу раз больше, чем у свёрточной нейросети.

Телеграм: t.me/ainewsline
Источник: habr.com