Нейросеть обучили распознавать гнев в речи за 1,2 секунды благодаря transfer learning
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-02-11 20:30

Нейронная сеть разработчиков Affectiva распознает гнев и разочарование в речи за 1,2 секунды, независимо от языка говорящего. Точность работы алгоритма на разных датасетах составила от 65% до 81%. Модель можно применять в диалоговых интерфейсах, создании социальных роботов и других задачах, где требуется распознавание эмоций человека по аудио.
Сверточные нейронные сети требуют больших наборов данных для обучения, а в случае с распознаванием эмоций таких датасетов нет, отмечают разработчики в статье. Поэтому они использовали сеть SoundNet для классификации аудио по видеозаписям и подход transfer learning. Это сработало лучше, чем обучение с нуля.
Обучение
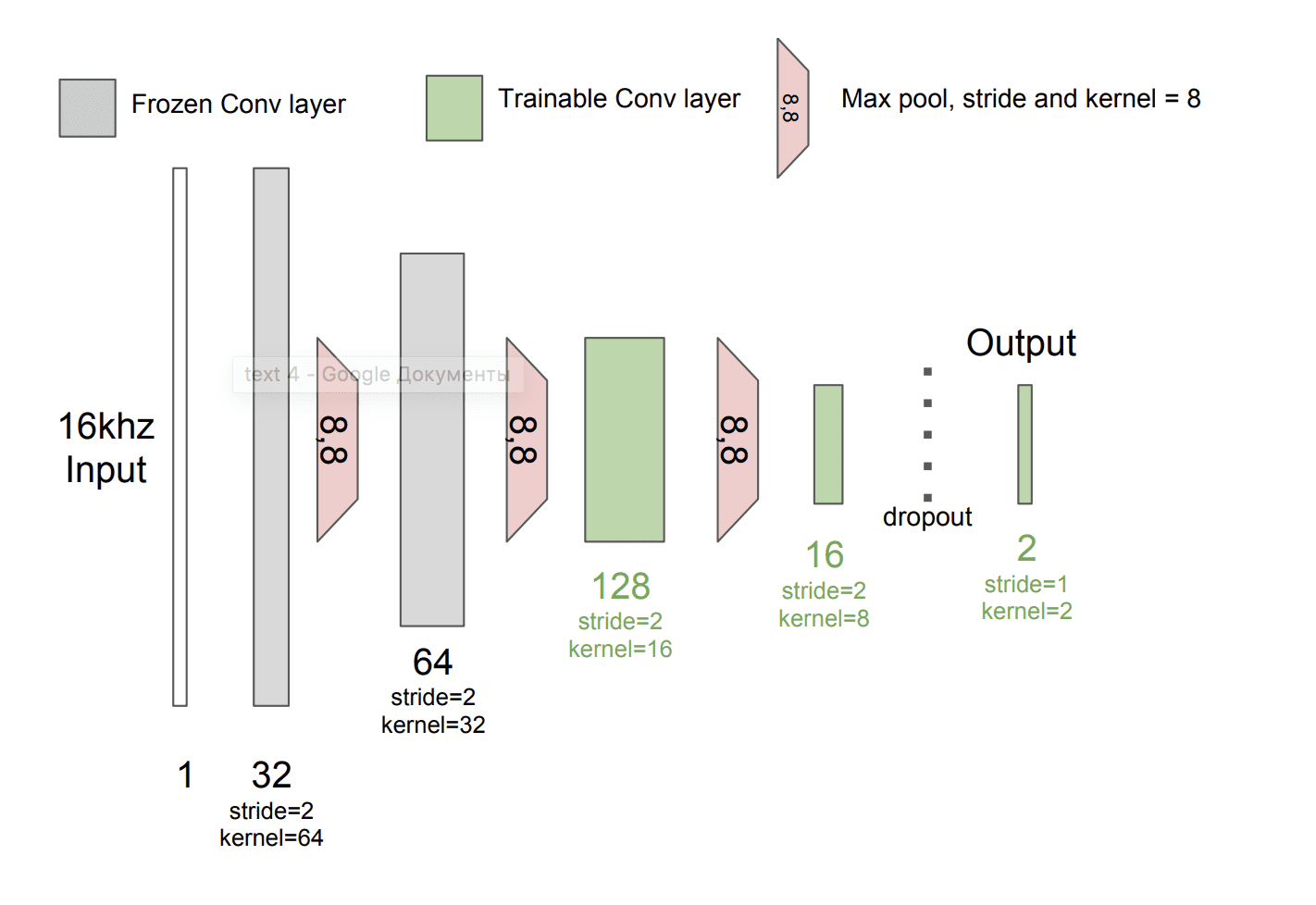
Модель разработана на базе сверточной нейронной сети (CNN), которая принимает на вход необработанный звук человеческой речи. Разработчики использовали сеть SoundNet, которая была предварительно обучена на большом количестве видео. Набор состоял из двух миллионов видео с ground truth, размеченных визуальными классификаторами.
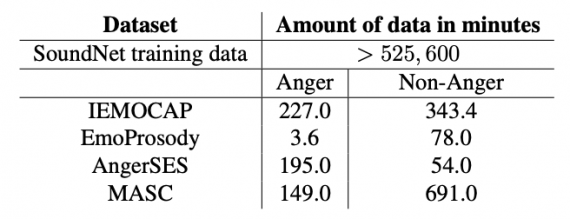
После этого команда до-обучила модель, используя набор данных IEMOCAP, который содержит 12 часов аннотированных аудиовизуальных данных с эмоциями, включая видео, аудио и текстовые транскрипции.
Результаты
Эффективность работы модели, обученной на англоязычных аудио и видео, проверили на датасете с записями эмоциональной речи на китайском языке (Mandarin Affective Speech Corpus, MASC). Производительность работы ухудшилась незначительно.
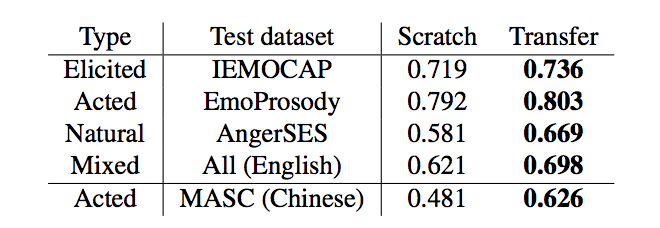
По мнению исследователей, результат показывает, что можно эффективно применять transfer learning в задачах распознавания эмоций на аудиозаписях. Использование модели, предварительно обученной на большом наборе размеченных данных, может улучшить точность классификации.
Небольшие датасеты, которые содержат только аудио с эмоциями доступны не всем из-за высокой стоимости. В то время как открытый датасет, используемый для обучения SoundNet, и набор Google AudioSet содержат более 15 000 часов размеченных аудиоданных.
В этой работе исследователи сфокусировались на распознавании гнева и разочарования. В дальнейшем они планируют работать над распознаванием других эмоций и аффективных состояний.
Телеграм: t.me/ainewsline
Источник: neurohive.io