Почти у всех рекомендательных систем есть трудности с новым или редким контентом — поскольку с ним взаимодействовала лишь незначительная часть пользователей. В своём докладе на встрече «Яндекс изнутри» Даниил Бурлаков поделился набором трюков, которые используются в рекомендациях Музыки, и подробно разобрал популярную модель Singular Value Decomposition (SVD).
Плюс у нас есть такие исполнители, которые называются композиторами и обычно проставляются правообладателями просто веером. Только у одного Моцарта было «записано» более миллиона композиций.
— Всем привет! Меня зовут Даниил Бурлаков, я руковожу командой рекомендаций в Медиасервисах. Сегодня хочу рассказать про некоторые проблемы, которые мы решаем, когда занимаемся рекомендациями в Музыке.
У нас замечательная команда, которая делает рекомендации не только для Яндекс.Музыки, но и всех Медиасервисов: это Кинопоиск, Афиша. Решаем множество более технических задач, чем рекомендации. Сегодня я хочу рассказать про центральный продукт Яндекс.Музыки, наш самый главный и любимый продукт — умные плейлисты, которые, наверное, многие из вас знают и слушают. Кратко пробегусь по тому, что это за плейлисты и каким контентом мы их наполняем. Плейлист дня задумывался как набор треков, который будет строиться для вас каждый день так, чтобы вы их могли скачать и послушать даже там, где нет интернета. Но он вам будет замечательно подходить, будет с вами, и он должен обновляться каждый день и содержать что-то новенькое. То, что вам подходит. Дежавю — более интересный плейлист. Он обновляется раз в неделю, и там будут треки, которые вы никогда не слушали, и исполнители, которых вы практически не знаете или вообще не знаете. Премьера — подборка новинок ваших исполнителей, которые вам могут понравиться. Второй продукт — Яндекс.Радио. В 2015 году оно запустилось, мы его продолжаем развивать. Идея в том, чтобы предоставить возможность пользователю получить персонализованный поток аудиомузыки, ничего не делая. Фактически нажал одну кнопку и получил прекрасный поток, который никогда не закончится и будет радовать вас долгие часы. Он, в отличие от плейлистов, уже может быть тегированным. Вы можете, например, включить радио по жанрам — рок или фоновую музыку, если вы не хотите отвлекаться во время работы. Или полностью персонализированный аудиопоток — то, что мы называем радио «На вашей волне». С какими проблемами мы сталкиваемся, когда делаем эти рекомендации? Мы сталкиваемся с двумя основными проблемами, довольно типичными для большей части рекомендательных систем. Это холодные пользователи, которые только что пришли на наш сервис и про которых мы еще ничего не знаем, и холодный контент. К нему относятся не только треки, которые появились недавно, но и огромное множество редких треков. В каталоге Яндекс.Музыки более 50 млн треков, многие из них еще не слушал ни один пользователь. Поэтому возникает проблема: даже если трек вышел достаточно давно, к сожалению, мы можем ничего не знать об этом треке и не иметь никакой статистики. Обе проблемы особенно усугубились и стали для нас особенно важными, поскольку Яндекс.Музыка стала международным сервисом и начала выходить во много стран. При выходе в каждую страну локальный контент этой страны становится, в первую очередь, очень важен. Понятное дело, что когда вы входите в новую страну, игнорировать местную музыку довольно неприятно. Ее необходимо рекомендовать, рекомендовать уместно и понимать устройство этой внутренней музыки. Фактически в России никто не слушает израильскую музыку, и статистики, даже если у нас есть этот контент, по ней крайне мало. Давайте пройдемся по этим проблемам. Начнем с проблемы холодных пользователей. Как ее можно решать? Первое самое простое решение — не рекомендовать ничего холодным пользователям. Действительно, решение очень простое, можно просто спросить о явных предпочтениях. Это многочисленные визарды, которые можно предоставлять пользователю. перед тем, как пользователь получит свой первый плейлист дня, мы просим пользователя пройти такой визард, указав свои предпочтения, набор жанров и исполнителей, которые бы ему понравились. В результате этого первый же плейлист пользователя становится достаточно осмысленным, подходит пользователю, и скорее всего, с первого же плейлиста пользователь в него влюбится. К сожалению, такой подход можно сделать не всегда. Второй наш продукт, Яндекс.Радио, задумывался как продукт, который не требует усилий от пользователя. Он хочет просто прийти и включить музыку, ничего не делая. Более того, Яндекс.Радио встраивается во многие другие системы, такие как Яндекс.Драйв, где просто заставить пользователя, сидячи в машине, прокликивать какой-то визард, если он туда впервые сел, довольно странно и неудобно. Поэтому мы пошли другим путем. Мы начинаем с рекомендаций, скажем так, для среднего пользователя, чтобы большая часть пользователей уже с первых треков получила максимум удовольствия, и им музыка понравилась. И обеспечиваем очень быструю персонализацию. В отличие от плейлиста, который вы получили и он весь день с вами, все ваши 60 треков. И если мы, например, не угадали с тем, что ваш любимый жанр — это популярная музыка (что будет неплохой догадкой для начала), то все 60 треков будут не про вас, и это будет печально, и скорее всего, завтра вы и не вернетесь. Однако если в радио мы поставим вам первый трек популярной музыки, а вы скажете, что вы его не хотите слушать, то мы мгновенно персонализируем для вас следующий трек и предложим что-то другое, например, рок или другой жанр. Собственно, фактически эти два решения закрывают проблему холодных пользователей в той или иной степени. Как можно было бы по аналогии решить проблему с контентом? Решение номер один, как и про пользователей — не рекомендовать холодный контент. Но здесь, в отличие от пользователей, контент сам себя не наберет и не нагреет. Тем самым получается проблема, что если мы сами не наберем статистики про него, то новинка исполнителя, которая только что вышла, не поставится, и пользователи, которые не увидели новинки своего исполнителя, наверняка будут расстроены.
Аналогичная ситуация с международным контентом. Мы вышли в новую страну, и не рекомендовать его, фактически проигнорировать этот контент, очевидно, нам не подходит. Второе решение, если будем действовать полностью по аналогии, рекомендовать его как-то в среднем. Простейшая аналогия — подсовывать либо всем подряд пользователям этот контент, либо рекомендовать его как популярную музыку. С вариантом рекомендовать в среднем вообще не очень понятно, что такое средняя музыка. Это от силы можно назвать популярной музыкой, но вряд ли можно сказать, что вся музыка похожа друг на друга настолько, чтобы она была похожей на популярную музыку. Поэтому если промежду популярной музыки вам встретится композиция Бетховена, большая часть людей вряд ли будет счастлива ее получить. Поэтому это решение нам тоже не подходит. Что же еще есть про треки? Вместе с самим треком от правообладателя к нам приходит множество метаданных, таких как жанр трека, исполнитель, альбом и год выпуска. Давайте пробежимся. Как можно было бы их использовать? Например, жанр. Жанр — это неплохая информация, которая позволяет нам более-менее угадывать. Например, проблему с Бетховеном или шансоном, который мог бы случайно появиться у кого-нибудь в радио, это решает: мы знаем жанр трека, и вряд ли подсунем тем, кому он не подойдет. Но к сожалению, построить хорошую рекомендацию он не позволяет, потому что понятие самого жанра довольно субъективно, и не позволяет построить на базе него сколько-нибудь хорошие рекомендации. Естественно, внутри жанров есть много поджанров, и именно так и присылают нам правообладатели. Вторая проблема в том, что обычный человек может назвать обычно десяток жанров, тогда как правообладатели присылают нам многие тысячи жанров, и это достаточно большая проблема, чтобы их как-то сгруппировать, найти между ними похожие и так далее. К сожалению, эта проблема не всегда решается. Затем, очевидно, есть проблемы с тем, что, к сожалению, правообладатели часто путаются и совершают ошибки. И у нас регулярные проблемы и репорты о том, что в радио рок мы собираем треки, которые популярны, и правообладатель поставил на них жанр рок. По аналогии мы собираем джаз и другие радиостанции. И у нас регулярно случаются репорты пользователей, которые просят поправить, потому что на эти радиостанции залетел трек с ошибкой. Хочу вам предложить угадать жанр трека.
Послушайте трек
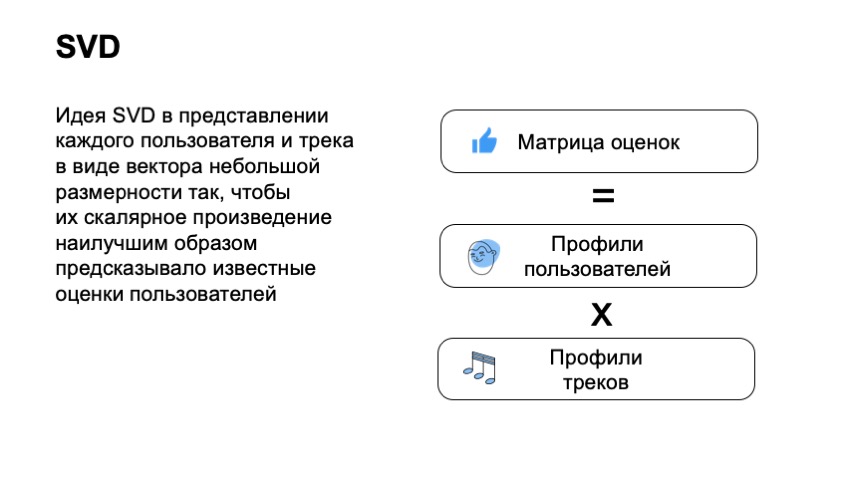
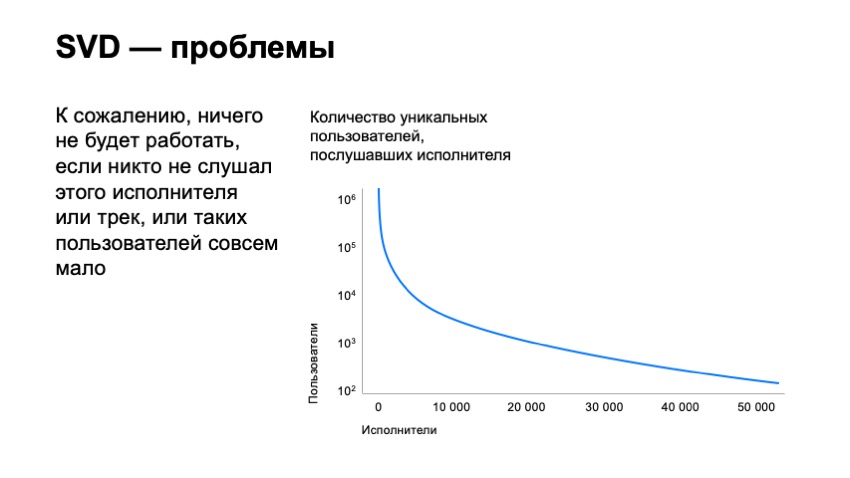
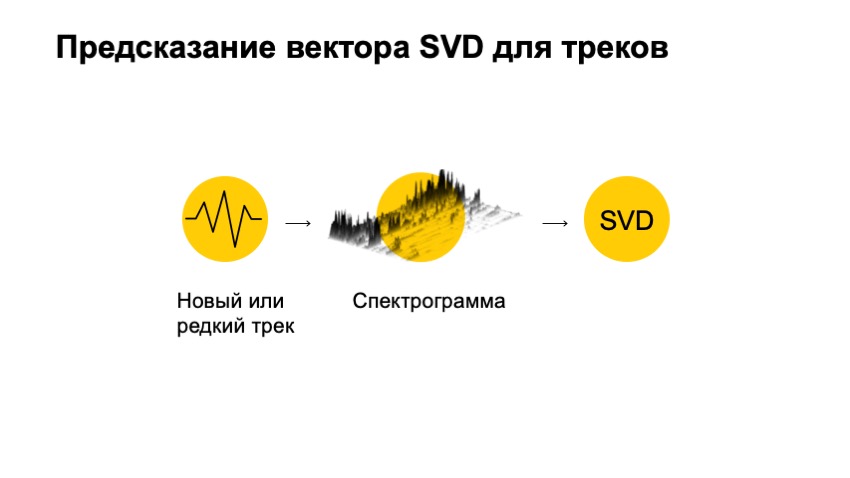
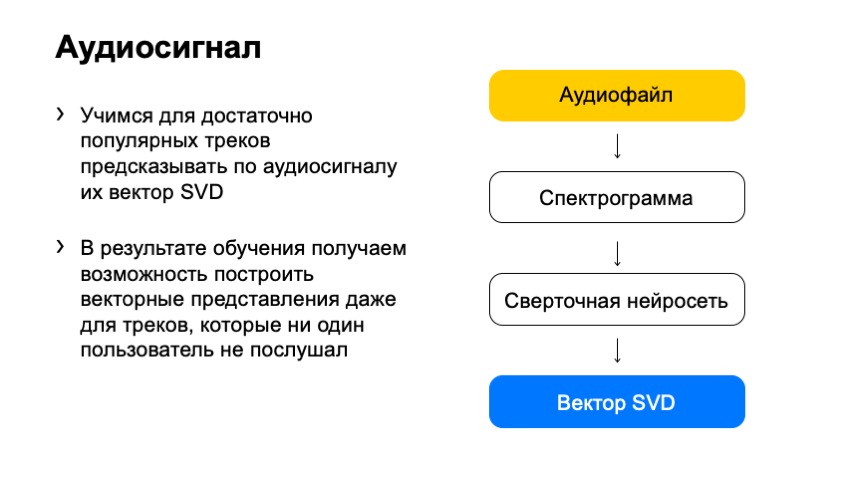
Это не саундтрек. Это металл. И у нас возникает большая проблема, когда нам присылают такую разметку. Предлагаю перейти к следующей части и поговорить про исполнителей трека. Я уже сказал, что есть проблема, что выходит новинка у исполнителя, новый трек или альбом, и ее надо рекомендовать. В частности информация про исполнителя всегда нас будет спасать. Мы знаем, что пользователь слушал этого исполнителя, и можем уместно ему его порекомендовать. Так мы и делаем. Однако тут тоже есть свои сложности. Например, если про самого исполнителя мы ничего не знали или пользователь его не слушал, то информация о том, что у этого трека такой-то исполнитель, не говорит нам ничего. Аналогично с редкими треками. Был редкий трек у редкого исполнителя, мы узнали, что теперь этот редкий трек принадлежит ему. К сожалению, опять не очень много информации, которая позволит его как-то рекомендовать другим людям, не знакомым с его творчеством. Вторая проблема — каверы и ремиксы. Опять здесь вмешиваются подлые правообладатели и часто совершают ошибки. В частности, когда у нас есть оригинальный трек и его кавер, правообладатели часто не утруждаются тем, чтобы назвать эти треки по-разному, подписать, что один из них ремикс или даже просто проставить у них разных исполнителей, когда это так. Хочу предложить вам два трека, чтобы понять, насколько разное звучание бывают у треков, которые называются абсолютно одинаково. Тем самым получаем два трека, которые можно назвать похожими, у них относительно похожий ритм, относительно похожий текст, но они разные. А для нас это один и тот же трек, потому что у него название, исполнитель и все остальное совершенно одинаковые. Плюс у нас есть такие подлые исполнители, которые называются композиторами и обычно проставляются правообладателями просто веером. Только у одного Моцарта было «записано» более миллиона композиций. Понятно, что для любителей классической музыки подобное будет невозможно. Если пользователь сказал, что ему нравится Моцарт, то дальше у нас есть миллионы треков, различные переисполнения стандартных классических мелодий. В итоге мы практически не можем ничего с этим сделать. Хочу дальше рассказать, как можно было бы решить эту проблему, но для начала давайте ослабим наши требования. Мы хотели рекомендовать треки, которые никто не слушал, а теперь давайте подумаем, как можно рекомендовать просто треки, которые были бы редкими. Здесь на помощь нам приходит коллаборативная фильтрация. Как это устроено и что мы получаем в итоге? Чтобы начать, мы должны составить матричку оценок пользователей, где по строчкам будут пользователи, по столбцам будут треки, на пересечении столбца и строки будет стоять его оценка. Понятно, что на большей части матрицы мы не знаем фидбек пользователей, пользователи не могли послушать весь наш каталог даже близко. С этой матрицей мы хотим пользователю и треку поставить в соответствие маленькие, достаточно короткие вектора, чтобы скалярное произведение вектора пользователя и вектора айтема хорошо предсказывало оценку пользователя. Тем самым мы получаем, что для каждого айтема и для каждого юзера мы должны найти два вектора так, чтобы итоговое их произведение предсказывало наилучшим образом нашу оценку. Например, если в данном случае мы бы сказали, что пользователю трек понравился — это 1, если не понравился — 0. И в данном случае мы можем фактически применить стандартную технику, SVD-разложение, и получить оптимальные векторы для пользователей и для треков. Что это нам дает? это нам дает следующий большой плюс. Для большей части подходов мы не можем сказать, что два трека похожи, если их никто не послушал вместе. Обычно значительная часть подходов базируется на том, что у нас есть какие-то пользователи, которые повзаимодействовали с айтемом А и Б, и мы видим, что они похожи в результате этого. Коллаборативная фильтрация в виде SVD позволяет нам это сделать даже если ни один пользователь не послушал два трека вместе. Они позволяют это оценить довольно хорошо. Это первый плюс. Что это нам дает? Имея вектор трека, мы можем его рекомендовать значительно более широкому кругу людей, и рекомендовать значительно менее популярные треки. И самый главный плюс, мы еще получаем векторное представление треков, с которым очень удобно работать, с которым можно быстро искать похожие треки. Однако это не решает всех наших проблем. мы лишь немного отодвинули планку количества треков, которые мы можем рекомендовать. Если мы построим график количества пользователей, которые слушали исполнителей, отсортируем исполнителей фактически по их популярности, мы увидим, что топовых исполнителей на нашем сервисе слушают миллионы пользователи. Если мы посмотрим уже на 10-тысячную позицию этих артистов, там будут всего тысячи пользователей. Если мы посмотрим даже на 50-тысячного артиста, там будет всего сотня пользователей. Понятно, у его треков будут всего десятки пользователей, которые его прослушали, что фактически не дает возможности их рекомендовать, поскольку вектор SVD для таких треков будет крайне неустойчив и не подойдет. Как мы можем пытаться это решить? Что мы хотим? Мы хотим взять какой-то редкий, новый трек, о котором ничего не знаем, например, редкий трек из Израиля, и хотим получить для него какое-то векторное представление, которое было бы очень похоже на наш вектор SVD, с которым очень удобно работать и делать рекомендации. Единственное, что мы не рассмотрели, это само аудио этого трека. Благодаря аудио мы могли бы рекомендовать треки. Как бы нам, используя аудио трека, получить вектор SVD. первым делом мы хотим сделать маленькое преобразование. Что такое, по сути, аудио? Можно представить себе график напряжения. В любом случае, это одномерный набор цифр, с которым работать довольно неудобно, он очень большой и длинный, представляет собой малый смысл сам по себе. Но мы можем проверить у него спектр, совершить над ним преобразования Фурье, очень кратко, это посмотреть, насколько он похож на конкретный вид синусоиды. Насколько он похож на какую-то из синусоид. И посмотреть, как много синусоиды в этом графике, и сделать так же для каждой из частот. Если мы так сделаем для всего трека в целом, конечно, мы получим какую-то информацию, но очень маленькую, она очень мало будет говорить, потому что, например, для музыки очень важны переходы между частями трека, тогда как в спектре мы их будем иметь в косвенном виде на изменении очень больших частот, которые должны относиться к секундам, к минутам, и это довольно неудобно и плохо представимо в виде спектра. Поэтому мы идем дальше и режем трек на маленькие кусочки. В каждом кусочке делаем такое преобразование. В результате получаем такую картинку, я ее нарисовал в трехмерном виде, чтобы было виднее, что на плоскости по времени мы развернули частоты, а по высоте — энергия, которая в этот момент времени была в этой частоте. И получили так называемую спектрограмму. Как бы нам, используя эту спектрограмму, получить вектор SVD? Ответ в наше время довольно банальный: давайте возьмем нейронную сеть и обучим ее предсказывать вектор SVD. Так мы и сделали. Что мы выбрали в качестве обучения? Те треки SVD, вектор которых мы точно знаем. Мы специально отобрали популярные треки, фидбек которых был достаточно большим, чтобы вектор SVD уже был совсем нешумным, и мы могли его четко вычислить. И — обучили нейронную сеть предсказывать эти вектора. Что мы в итоге получили? Сеть, которая может взять уже любой трек и предсказать его вектор SVD. Получили очень простое решение, которое очень хорошо работает. Хочу показать пример пары треков, которые мы вытянули. Один из этих треков достаточно популярный, и его вектор SVD можно было бы узнать довольно точно, а второй очень малопопулярный. Хочу предложить угадать, какой из этих треков менее популярен, а какой более популярен. Первый трек:
Второй трек:
Ответ
Первый трек более популярный. Если посмотреть на количество слушателей, которые знали об этом треке и смогли его сами найти, без помощи рекомендаций, то первый трек смогли найти более 1000 пользователей, а второй — всего 10. И то того, как мы применили нашу технологию, мы не могли бы даже попробовать порекомендовать этот трек, потому что не за что было зацепиться для рекомендаций. Мы могли бы предложить его разве что этим 10 пользователям.
Когда мы применили это в продакшене, то получили множество замечательных отзывов. Один из плейлистов, «Дежавю», куда мы должны встраивать треки, которые пользователь не слушал, организовывать для пользователя дискавери, значительно улучшился после того, как мы смогли применить эту технологию. Разумеется, мы применили это при выходе в новые страны и тоже получили множество положительных отзывов. В них отмечалось то, что плейлисты умеют хорошо персонализироваться. Кроме того, редакторов в Израиле довольно сильно удивило, что русский сервис в Израиле рекомендует не русских исполнителей в больших количествах, а местную музыку и международную. О цифрах, которых нам удалось добиться. Главное, мы хотели добиться количества новинок для пользователей в аудиопотоке, чтобы он стал разнообразнее. За счет этого у нас получилось удвоить количество новинок, которые мы ставим пользователям. Казалось бы, удвоить несложно: берете и ставите больше новых треков. Однако у нас не только удвоилось количество новинок. Еще мы не просадили метрики пользователей. За время эксперимента пользователи были с нами на 1,5% чаще. И они не только приходили к нам чаще, но и каждый день слушали дольше. А этого сложно добиться, потому что многие пользователи слушают музыку во время каких-то занятий, например, пока работают или едут на работу. Добиться, чтобы пользователь в день нас начал слушать дольше, довольно сложно. И последнее: мы стали меньше ошибаться. Когда пользователи нас слушают, у них есть возможность сказать, что мы ошиблись, дизлайкнув трек. Количество таких ошибок у нас очень сильно сократилось. Спасибо за внимание.