Как нейронные сети графике помогали
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-02-23 06:06
Евгений Туманов работает Deep Learning инженером в компании NVIDIA. По итогам его выступления на конференции HighLoad++ мы подготовили рассказ о применении Machine Learning и Deep Learning в графике. Машинное обучение не заканчивается на NLP, Computer Vision, рекомендательных системах и задачах поиска. Даже если вы не очень знакомы с этим направлением, то сможете применить наработки из статьи в своей области или индустрии.
Supervised DL/ML in graphics, или обучение с учителем в графике
Разберем две группы задач. Для начала кратко их обозначим.
Real-World or render engine:
- Создание правдоподобных анимаций: локомоция, лицевая анимация.
- Постобработка отрендеренных изображений: supersampling, anti-aliasing.
- Slowmotion: интерполяция кадров.
- Генерация материалов.
Вторую группу задач сейчас условно назовем "Heavy algorithm". К ней мы относим такие задачи, как рендеринг сложных объектов, например, облаков, и физические симуляции: воды, дыма.
Наша цель — понять, в чем принципиальное различие между этими двумя группами. Рассмотрим задачи подробнее.
Создание правдоподобных анимаций: локомоция, лицевая анимация
В последние несколько лет появляется много статей, где исследователи предлагают новые пути к генерации красивой анимации. Использовать труд художников — дорого, и заменить их алгоритмом, было бы всем очень выгодно. Года назад в NVIDIA мы работали над проектом, в котором занимались лицевой анимацией персонажей в играх: синхронизацией лица героя с аудиодорожкой речи. Мы пытались «оживить» лицо, чтобы каждая точка на нем двигалась, и прежде всего губы, потому что это самый сложный момент в анимации. Вручную художнику это делать дорого и долго. Какие варианты решить эту задачу и сделать для нее dataset?
Первый вариант — определить гласные звуки: на гласные рот открывается, на согласные — закрывается. Это простой алгоритм, но слишком простой. В играх мы хотим больше качества. Второй вариант — посадить людей читать разные тексты и записывать их лица, а потом сопоставить буквы, которые они произносят, с мимикой. Это хорошая идея, и мы так и сделали в совместном с Remedy Entertainment проекте. Единственное отличие — в игре мы показываем не видео, а 3D модель из точек. Чтобы собрать dataset, нужно понять, как двигаются конкретные точки на лице. Мы брали актеров, просили читать тексты с разными интонациями, снимали на очень хорошие камеры с разных углов, после чего восстанавливали 3D модель лиц на каждом кадре, и по звуку прогнозировали положение точек на лице.
Постобработка отрендеренных изображений: supersampling, anti-aliasing
Рассмотрим кейс из конкретной игры: у нас есть движок, который генерирует изображения в разных разрешениях. Мы хотим рендерить изображение в разрешении 1000?500 пикселей, а игроку показывать 2000?1000 — так будет симпатичнее. Как собрать dataset для этой задачи?
Сначала отрендерить картинку в большом разрешении, потом понизить качество, и дальше попытаться обучить систему переводить картинку с малого разрешения в большое.
Slowmotion: интерполяция кадров
У нас есть видео, и мы хотим сетью дописывать фреймы посередине — интерполировать кадры. Идея очевидна — снимать реальное видео с большим количеством кадров, убирать промежуточные и пытаться прогнозировать сетью то, что убрали.
Генерация материалов
На генерации материалов мы не будем сильно останавливаться. Ее суть в том, что мы снимаем, например, кусок дерева под несколькими углами освещения, и интерполируем вид под другими углами.
Мы рассмотрели первую группу задач. Вторая — принципиально иная. Про рендеринг сложных объектов, например, облаков, мы будем говорить позже, а сейчас разберемся с физическими симуляциями.
Физические симуляции воды и дыма
Представим бассейн, в котором находятся движущиеся твердые объекты. Мы хотим предсказывать движение частиц жидкости. В бассейне есть частицы в момент времени t, и в момент t + ?t мы хотим получить их положение. Для каждой частицы вызовем нейронную сеть и получим ответ, где он будет на следующем кадре.
Чтобы решить задачу используем уравнение Навье-Стокса, которое описывает движение жидкости. Для правдоподобной, физически корректной симуляции воды, нам придется решить уравнение или приближение к нему. Это можно сделать вычислительным способом, которых за последние 50 лет придумано много: алгоритм SPH, FLIP или Position Based Fluid.
Отличие первой группы задач от второй
В первой группе учителем для алгоритма выступает что-то свыше: запись из реальной жизни, как в случае с лицами, либо что-то из движка, например, рендер картинок. Во второй группе задач мы используем метод вычислительной математики. Из этого тематического разделения, вырастает идея.
Главная идея
У нас есть вычислительно сложная задача, которая долго, упорно и тяжело решается классическим вычислительным университетским методом. Чтобы ее решить и ускориться, возможно, даже немного потеряв в качестве, нам нужно:
- найти в задаче самое времязатратное место, где дольше всего работает код;
- посмотреть, что выдает эта строчка;
- попытаться спрогнозировать результат строчки с помощью нейронной сети или любого другого алгоритма машинного обучения.
Это общая методология и главная мысль — рецепт, как найти применение для машинного обучения. Чем вы должны заниматься, чтобы эта идея была полезна? Точного ответа нет — используйте креативность, посмотрите на свою работу и найдете. Я занимаюсь графикой, и не так хорошо знаком с другими областями, но могу представить, что в академической среде — в физике, химии, робототехнике, — точно можно найти применение. Если вы решаете сложное физическое уравнение у себя на производстве, то, возможно, тоже сможете найти применение для этой идеи. Для наглядности идеи рассмотрим конкретный кейс.
Задача рендеринга облаков
Этим проектом мы занимались в NVIDIA полгода назад: задача в том, чтобы нарисовать физически корректное облако, которое представлено как плотность капелек жидкости в пространстве.
Облако — физически сложный объект, взвесь капелек жидкости, который нельзя смоделировать, как твердый предмет.
На облако не получится наложить текстуру и отрендерить, потому что капельки воды сложно геометрически расположены в 3d пространстве и сами по себе сложны: они практически не поглощают цвет, а отражают его, причем, анизотропно — во все стороны по-разному.
Если взглянуть на каплю воды, на которую светит солнце, а векторы из глаза и солнца на каплю параллельны, то будет наблюдаться большой пик интенсивности света. Этим объясняется физический феномен, который все видели: в солнечную погоду одна из границ облака очень яркая, практически белая. Мы смотрим на границу облака, и вектор взгляда и вектор от этой границы к солнцу практически параллельны.

Классическое решение
Чтобы решить проблему, требуется решить вот такое сложное уравнение.

За второй способ «распространения света вдоль направления» отвечает интегральный терм уравнения. Его физический смысл следующий.
Рассмотрим отрезок внутри облака на луче — от точки входа до точки выхода. Интегрирование ведется как раз по этому отрезку, и для каждой точки на нем мы считаем, так называемый, Indirect light energy L(x, ?) — смысл интеграла I1 — опосредованное освещение в точке. Оно появляется за счет того, что капли по-разному переотражают солнечный свет. Соответственно, в точку приходит огромное количество опосредованных лучей от окружающих капелек. I1 — это интеграл по сфере, которая окружает точку на луче. В классическом алгоритме его считают с помощью метода Монте-Карло.
Классический алгоритм.
- Рендерим картинку из пикселей, и выпускаем луч, который идет из центра камеры в пиксель и затем дальше.
- Пересекаем луч с облаком, находим точку входа и выхода.
- Считаем последний терм уравнения: пересечь, соединить с солнцем.
- Начинаем importance sampling
Как считать Монте-Карло оценку I1 мы разбирать не будем, потому что это сложно и не так важно. Достаточно сказать, что это самая долгая и сложная часть во всем алгоритме.
Подключаем нейронные сети
Из главной идеи и описания классического алгоритма следует рецепт, как применить нейронные сети к этой задаче. Самое тяжелое — посчитать Монте-Карло оценку. Она дает число, которое означает опосредованное освещение в точке, и это именно то, что мы хотим предсказывать.

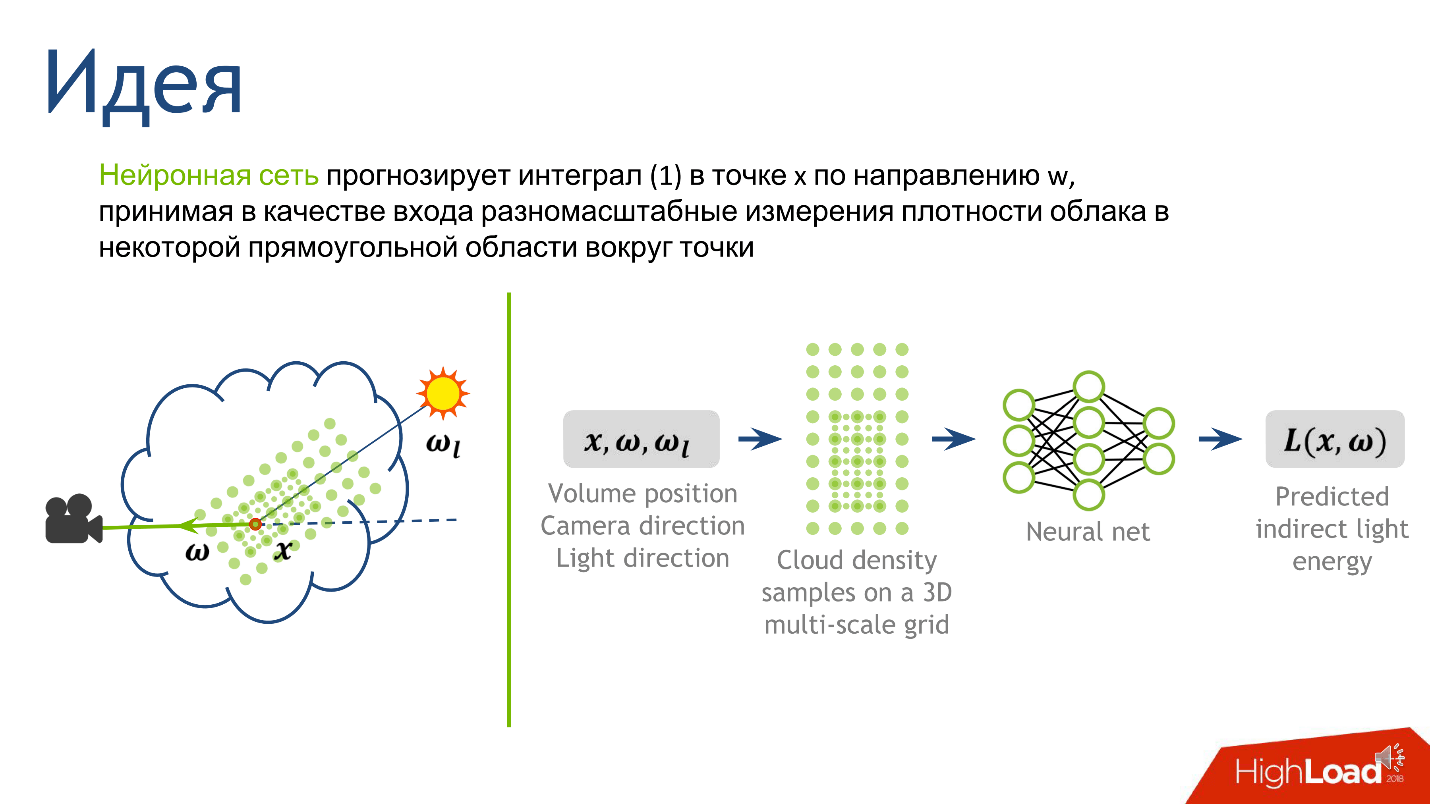
- Зафиксируем достаточно маленькую константу. Пусть это будет длина свободного пробега в облаке.
- Рисуем вокруг точки на нашем отрезке объемную прямоугольную сетку фиксированного размера, допустим, 5*5*9. В центре этого кубика будет наша точка. Шаг сетки — маленькая зафиксированная константа. В узлах сетки будем измерять плотность облака.
- Увеличим константу в 2 раза, нарисуем сетку побольше, и проделаем то же самое — измерим плотность в узлах сетки.
- Повторяем предыдущий шаг несколько раз. Мы это делали 10 раз, и после процедуры получили 10 сеток — 10 тензоров, в каждом из которых хранится плотность облака, и каждый из тензоров охватывает все большую и большую окрестность вокруг точки.
Такой подход нам дает максимально подробное описание маленькой области — чем ближе к точке, тем подробнее описание. Определились с выходом и входом сети, осталось понять, как её обучать.
Обучаем
Сгенерируем 100 разных облаков с разной топологией. Будем просто их рендерить, применяя классический алгоритм, записывать, что алгоритм получает в той самой строчке, где он осуществляет интегрирование методом Монте-Карло, и записывать свойства, которые при этом соответствуют точке. Так мы получим dataset, на котором можно обучаться.

Что обучать, или архитектура сети
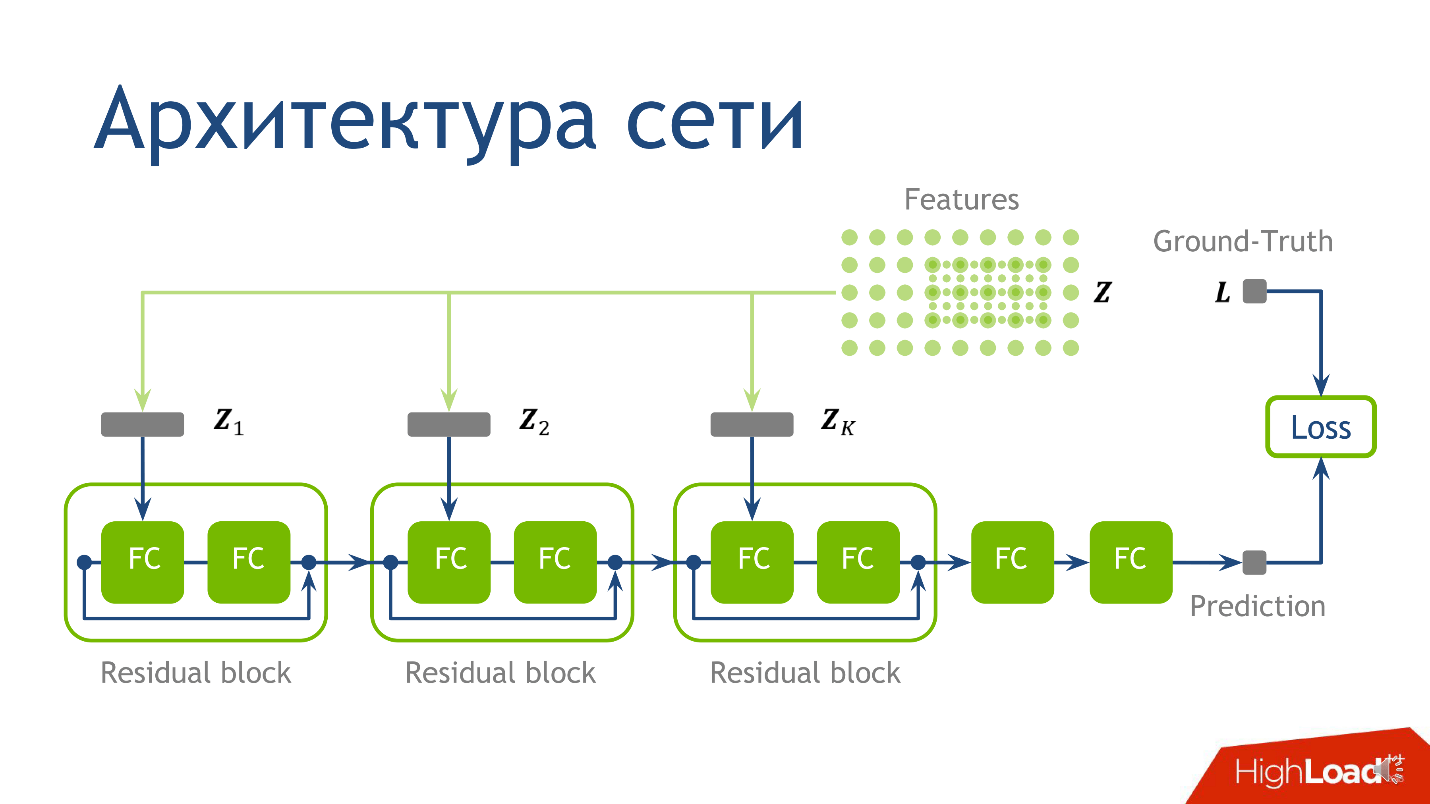
Архитектура сети для этой задачи — не самый ключевой момент, и если вы ничего не поймете — не переживайте — это не самое важное, что я хотел донести. Мы использовали следующую архитектуру: для каждой точки 10 тензоров, каждый из которых посчитан на все более масштабной сетке. Каждый из этих тензоров попадает в соответствующий блок.
- Сначала в первый обычный fully connected слой.
- После выхода из первого fully connected слоя — во второй fully connected слой, у которого нет активации.
Fully connected слой без активации — это просто перемножение на матрицу. К результату перемножения на матрицу добавляем выход с предыдущего residual-блока, и только потом применяем активацию.
Результаты
Первое наблюдение — мы получили то, что хотели: вызов нейронной сети, по сравнению с оценкой методом Монте-Карло, работает быстрее, что уже хорошо.
Но есть еще одно наблюдение по результатам обучения — это сходимость по количеству сэмплов. О чем идет речь?

- Выпускаем на каждый пиксель несколько антиалиасинговых лучей.
- На внутренней части луча из камеры, в облаке, на отрезке рассчитываем n сэмплов точек, в которых хотим проводить Монте-Карло оценку, либо для них вызывать сеть.
Еще есть сэмплы, которые соответствуют соединению с источниками света. Они появляются, когда мы соединяем точку с источником света, например, с солнцем. Это сделать легко, потому что солнце — это лучи падающие на землю параллельно друг другу. Например, небо, как источник света, гораздо сложнее, потому что представляется в виде бесконечно удаленной сферы, у которой есть функция цвета по направлению. Если вектор смотрит прямо вертикально в небо, то цвет — синий. Чем ниже — тем светлее. Внизу сферы обычно нейтральный цвет, имитирующий землю: зеленый, коричневый.
Когда мы соединяем точку с небом, чтобы понять, сколько в нее приходит света, всегда выпускаем несколько лучей, чтобы получить ответ, сходящийся к правде. Лучей выпускаем больше, чем один, чтобы получить оценку получше. Поэтому на весь pipeline рендеринга нужно столько сэмплов.
Когда мы обучили нейронную сеть, то заметили, что она выучивает гораздо более усредненное решение. Если зафиксировать количество сэмплов, то видно, что классический алгоритм сходится к левому ряду колонки картинок, а сеть выучивается к правому. Это не значит, что оригинальный метод плох — мы просто быстрее сходимся. Когда мы увеличим количество сэмплов, оригинальный метод будет все ближе и ближе к тому, что мы получаем.
Главный наш результат, который мы хотели получить — это повышение скорости рендеринга. Для конкретного облака в конкретном разрешении с параметрами сэмплов мы видим, что картинки, полученные за счет сети и классического метода практически идентичны, но правую картинку мы получаем в 800 раз быстрее.

Реализация
Есть Open Source программа для 3D моделирования — Blender, в которой реализован классический алгоритм. Мы сами не писали алгоритм, а использовали эту программу: проводили обучение в Blender, записывая за алгоритмом все, что нам нужно. Продакшен тоже делали в программе: обучили сеть в TensorFlow, перенесли ее в C++ с помощью TensorRT, и уже TensorRT-сеть интегрировали в Blender, потому что его код открыт.
Так как мы все делали для Blender, в нашем решении есть все фишки программы: можем рендерить какие угодно сцены и много облаков. Облака в нашем решении задаем созданием кубика, внутри которого определяем функцию плотности специфическим, для 3D-программ, способом. Мы провели оптимизацию этого процесса — кэшируем плотность. Если пользователь хочет одно и то же облако нарисовать в куче разных сетапов сцены: при разном освещении, с разными объектами на сцене, то ему не нужно постоянно пересчитывать плотность облака. Что получилось, можете посмотреть на видео. Напоследок повторю еще раз главную идею, которую хотел донести: если в своей работе вы долго и усердно что-то считаете каким-то специфическим вычислительным алгоритмом, и вас это не устраивает — найдите в коде самое тяжелое место, замените его на нейронную сеть, и, возможно, вам это поможет.
Нейронные сети и искусственный интеллект — одна из новых тем, которые будем обсуждать на Saint HighLoad++ 2019 в апреле. Мы уже получили несколько заявок по этой теме, и если у вас есть классный опыт, не обязательно по нейросетям, — подавайте заявку на доклад до 1 марта. Будем рады видеть вас среди наших спикеров.
Чтобы быть в курсе, как формируется программа и какие доклады приняты, подписывайтесь на рассылку. В ней только публикуем тематические подборки докладов, дайджесты по статьям и новые видео.
Телеграм: t.me/ainewsline
Источник: habr.com