Как изучать Data Science в 2019: ответы на частые вопросы
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-02-20 02:52

Мысль о том, чтобы изучать Data Science, не даёт вам покоя? Возможно, не зря. В этой статье мы ответили на ряд популярных вопросов новичков.
В последнее время Data Science набирает популярность в IT-мире, и игнорировать эту технологию просто не получается. Так каково это ? изучать Data Science в 2019 году?
Сейчас большая часть аналитики происходит в Excel ? таблицы, диаграммы, рутина. Но появляется все больше статей о том, что искусственный интеллект заменит таких специалистов. Это так? И при чем здесь Data Science?
Не совсем, но об этом чуть позже. Data Science развивается и начинает оперировать все большими объемами информации, которые позволяют создавать много полезных штук.
Когда смотришь на карты путей развития вроде этой, кажется, что и создаются они не для людей, а для роботов.
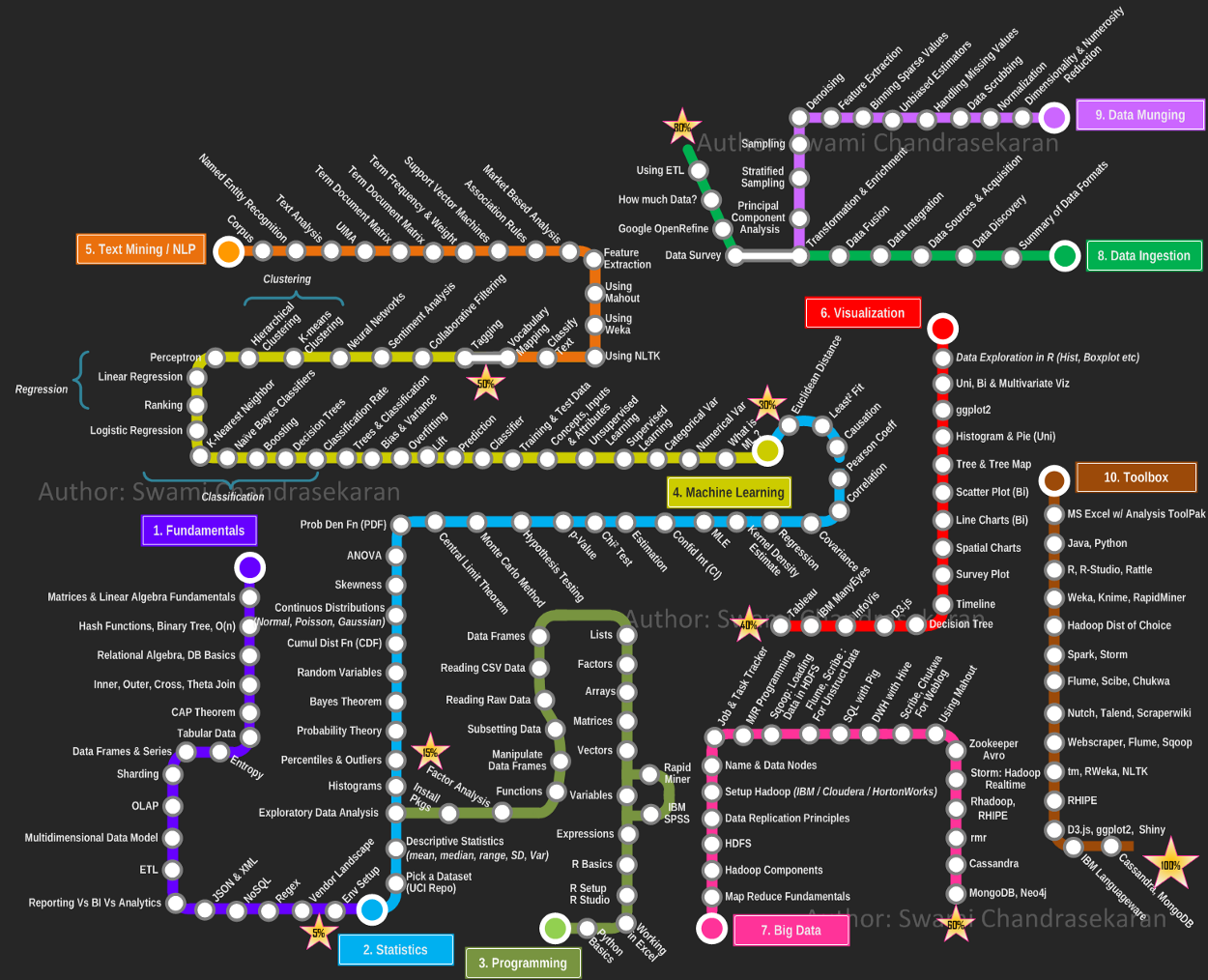
Отставить панику. К примеру, эта карта появилась ещё в 2013 году, ведь здесь нет даже TensorFlow. Data Science с тех времен стала намного более фрагментированной. Лучше выбрать другой подход.
Есть мнение, что эта область подразумевает наличие серьёзной базы, освоить которую самостоятельно будет непросто. Действительно ли большинство специалистов по данным имеют университетские дипломы?
Конечно, нет. Ко всему, что вы видите в интернете, стоит относиться со скептицизмом. Большинство статей о том, как изучать Data Science, скорее, являются руководством по бизнес-аналитике. А основная часть материала, изучаемого в университетах, просто устарела. Чтобы не отставать, лучше заниматься самому. Об этом, кажется, уже было сказано много раз, но почему тогда возникают вопросы «как освоить технологию X»?
Что стоит освоить в первую очередь? Linux? А может, Scala, Python или R?
Про Scala можете пока забыть. R неплох в математическом моделировании, но это все. С Python вы получите более развернутый функционал и возможность оперировать такими вещами, как обработка данных и настройка веб-сервисов.
Более того, это простой язык, с помощью которого можно автоматизировать множество задач. И вам не придется изучать его вдоль и поперек ? Data Science является чем-то большим, нежели скрипты и машинное обучение.
Это все инструменты. Можно использовать Python, а если вам нужно лишь построить пару диаграмм, то используйте Tableau.
Разве с покупкой лицензии какого-то сервиса человек становится профессионалом? Кажется, Data Science состоит не только из кружков и столбиков, иначе все можно было бы сделать и в Excel.
Да, на самом деле, это просто маркетинг. Визуализация данных ? интересная часть Data Science, но она не включает в себя трудоемкие этапы работы: очистку, обработку, загрузку.
Для начала вам нужно изучить несколько библиотек для управления Data Frame. Например, Pandas. И matplotlib, но уже для создания диаграмм.
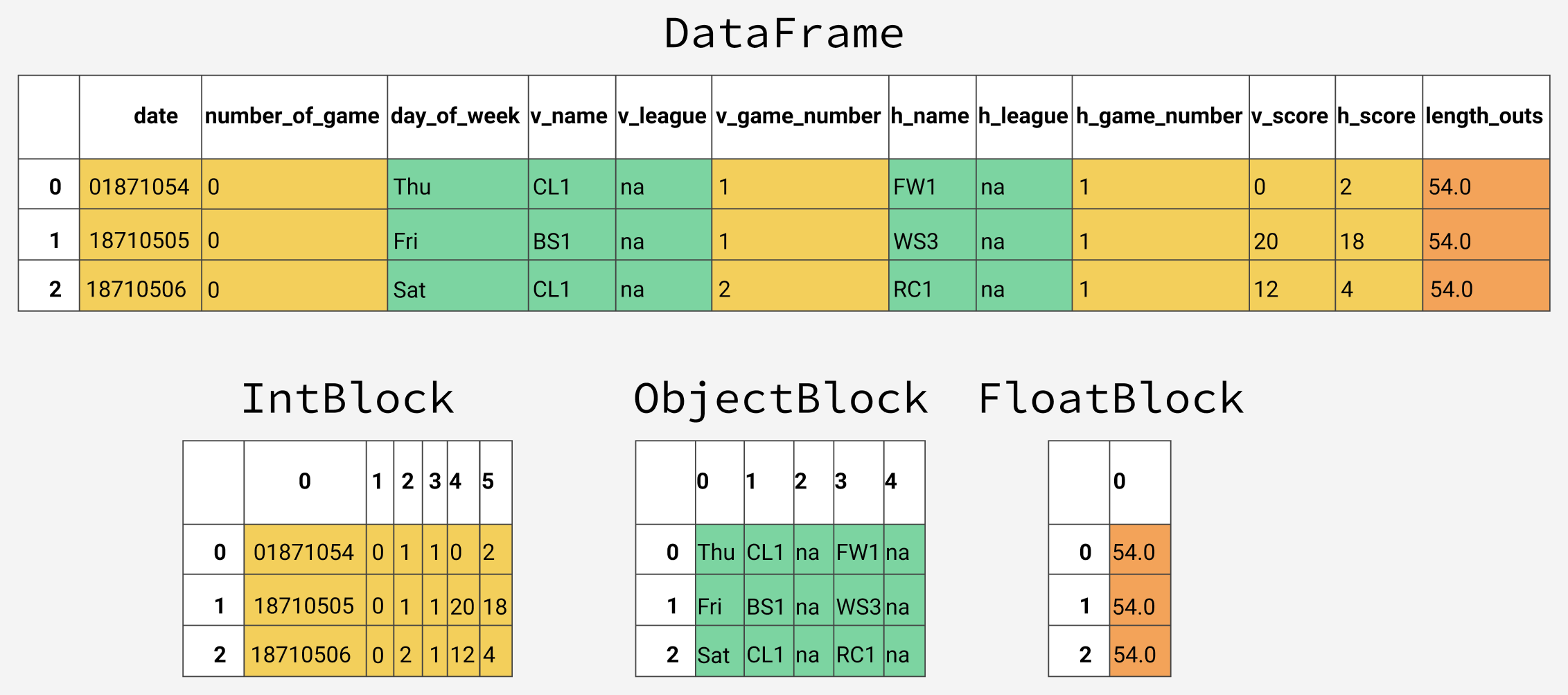
Это функционал для манипулирования данными в табличной структуре. В чём отличия Python от Excel? В среде Python вы можете заниматься этими делами в Jupyter ? каждый шаг будет визуализирован, появится полное видение процесса.
Jupyter и другие подобные утилиты намного более автоматизированы и оптимизированы, что позволяет легко отслеживать каждый пройденный этап.
Нам нужны данные. Один из вариантов их получения ? банальная загрузка нескольких статей из Википедии на жесткий диск. Сделать это можно с помощью Beautiful Soup, например.
Читая про Data Science складывается впечатление, что значительная часть работы заключается в обработке таблиц, а не просмотре веб-страниц. Как же SQL?
Ну, с неструктурированными текстовыми данными мы можем сделать очень много полезных вещей, например, анализ настроений в социальных сетях или обработку лексикона. Переживать не стоит. NoSQL отлично справляется с хранением данных такого типа.
Буквально ? не только SQL. Он поддерживает структуры данных за пределами реляционных таблиц. Однако, базы данных NoSQL обычно не используют SQL, а являются языком запросов. Но пока, можно об этом не думать.
Анализ этих данных может служить хорошей отправной точкой для создания многих проектов. Например, чат-ботов.
Не стоит ожидать, что у вас сразу получится сделать что-то наподобие Microsoft Tay или прогнозировать продажи. Подобные эксперименты лучше отложить на потом.
Для новичка чат-боты и неструктурированные данные не должны быть приоритетными задачами. Но стоит помнить, что крупные корпорации сейчас занимаются именно этим, а значит, когда наберётесь опыта, обязательно уделите им внимание.
Практика. Но мы будем двигаться дальше ? таблицы, анализ, множества. Больше похоже на статистический анализ. Начать лучше с чего-то базового, вроде линейной регрессии.
Использование скриптов даст вам намного большую гибкость. Во много раз легче использовать Python, нежели создавать адски длинные формулы, ведь так? Тем более, у вас под рукой всегда будет библиотека scikit-learn, которая облегчает жизнь специалистам по данным.
По общепринятому мнению, линейная алгебра является основой многих наук о данных. Большинство процессов, используемых в этой сфере, базируются на умножении и сложении матриц. Также существуют и другие важные понятия. Например, детерминанты и собственные векторы. К слову, чуть ли не единственный ресурс, где можно найти интуитивное объяснение линейной алгебры, ? канал 3Blue1Brown.
Не стоит бояться. Прямой контакт с математическими вычислениями почти исключен. Такие библиотеки, как TensorFlow, Keras и scikit-learn, сделают все сами.
Линейная регрессия является инструментом для машинного обучения. Нейронные сети, опорные векторы, логистическая регрессия ? все они выполняют некоторую форму подбора кривой, подгоняют ее к точкам. Естественно, в разном контексте. Одни из них достаточно просты для интерпретации, другие же запутаны по определению.

Нейронные сети на самом деле являются просто многослойными регрессиями с некоторыми нелинейными функциями. Может показаться, что это просто, но только в случае, если есть 2-3 переменные. Самое интересное начинается тогда, когда их становится в сотни раз больше.
Именно. Каждый пиксель прикрепляется к переменной. Таким образом, чем больше этих самых переменных, тем больше данных нужно обработать. Это одна из многих причин, почему машинное обучение может быть настолько запутанным.
Помимо Data Science, существует также и Operations Research. На самом деле, между ними есть очень много общего. И именно Operations Research принесло множество алгоритмов оптимизации, которые теперь используют при машинном обучении и устранении проблем ИИ.
Ну, определенно не алгоритмы машинного обучения. Древовидный поиск, метаэвристика, линейное программирование и прочие методологии исследования операций использовались в течение большого промежутка времени, и все еще выполняют такие задачи лучше, чем алгоритмы машинного обучения.
Да. На самом деле Data Science является невероятно неопределенной дисциплиной, использующей множество других отраслей. Может быть, в скором времени нейросети и роботы смогут оперировать более сложными данными, чем те, с которыми сейчас работает Data Science: автоматическая аналитика, разработка бизнес-планов, составление многоуровневого расписания. Но сначала до этого нужно дожить.
Источник: Каково изучать Data Science в 2019 году на Towards Data Science
Телеграм: t.me/ainewsline
Источник: proglib.io