Audio AI: выделяем вокал из музыки с помощью свёрточных нейросетей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-02-22 01:51
алгоритмы машинного обучения, реализация нейронной сети, алгоритмы распознавания речи
Отказ от ответственности: вся интеллектуальная собственность, проекты и методы, описанные в этой статье, раскрыты в патентах US10014002B2 и US9842609B2.
Вот бы вернуться в 1965 год, постучать в парадную дверь студии «Эбби-Роуд» с пропуском, зайти внутрь — и услышать настоящие голоса Леннона и Маккартни… Что ж, давайте попробуем. Входные данные: MP3 среднего качества песни «Битлз» We Can Work it Out. Верхняя дорожка — входной микс, нижняя дорожка — изолированный вокал, который выделила наша нейросеть.
Я занимался обработкой сигналов и изображений ещё до того, как распространился лозунг «глубокое обучение решает всё», поэтому могу представить вам решение в качестве путешествия feature engineering и показать, почему для этой конкретной проблемы нейросеть оказывается лучшим подходом. Зачем? Очень часто я вижу, как люди пишут что-то вроде такого:
«С глубоким обучением больше не нужно беспокоиться о выборе признаков; оно сделает это за вас»
или ещё хуже…
«Разница между машинным обучением и глубоким обучением [погодите… глубокое обучение это по-прежнему машинное обучение!] в том, что в ML вы сами извлекаете признаки, а в глубоком обучении это происходит автоматически внутри сети».
Вероятно, такие обобщения исходят из того факта, что DNN могут быть очень эффективны при изучении хороших скрытых пространств. Но так обобщать нельзя. Меня очень расстраивает, когда недавние выпускники и практики поддаются вышеуказанным заблуждениям и принимают подход «глубокое-обучение-решает-всё». Мол, достаточно набросать кучу необработанных данных (пусть даже после небольшой предварительной обработки) — и всё заработает как надо. В реальном мире нужно заботиться о таких вещах, как производительность, выполнение в реальном времени и т. д. Из-за таких заблуждений вы очень надолго застрянете в режиме экспериментов…
Feature Engineering остаётся очень важной дисциплиной при проектировании искусственных нейронных сетей. Как и в любой другой технике ML, в большинстве случаев именно она отличает эффективные решения уровня продакшна от неудачных или неэффективных экспериментов. Глубокое понимание ваших данных и их природы по-прежнему очень много значит…
От А до Я
Хорошо, я закончил проповедь. Теперь разберёмся, зачем мы здесь собрались! Как и с любой проблемой по обработке данных, сначала посмотрим, как они выглядят. Взглянем на следующий фрагмент вокала из оригинальной студийной записи.
Не слишком интересно, верно? Ну, это потому что мы визуализируем сигнал во времени. Здесь мы видим только изменения амплитуды с течением времени. Но можно извлечь всякие другие штуки, такие как амплитудные огибающие (envelope), среднеквадратичные значения (RMS), скорость изменения с положительных значений амплитуды на отрицательные (zero-crossing rate) и т. д., но эти признаки слишком примитивны и недостаточно отличительны, чтобы помочь в нашей проблеме. Если мы хотим извлечь вокал из аудиосигнала, для начала нужно каким-то образом определить структуру человеческой речи. К счастью, на помощь приходит оконное преобразование Фурье (STFT).
Хотя я люблю обработку речи и определённо люблю играться с моделированием входного фильтра, кепстром, сачтотами, LPC, MFCC и так далее, пропустим всю эту ерунду и сосредоточимся на основных элементах, связанных с нашей проблемой, чтобы статья была понятна как можно большему числу людей, а не только специалистам по обработке сигналов.
Итак, что же говорит нам структура человеческой речи?
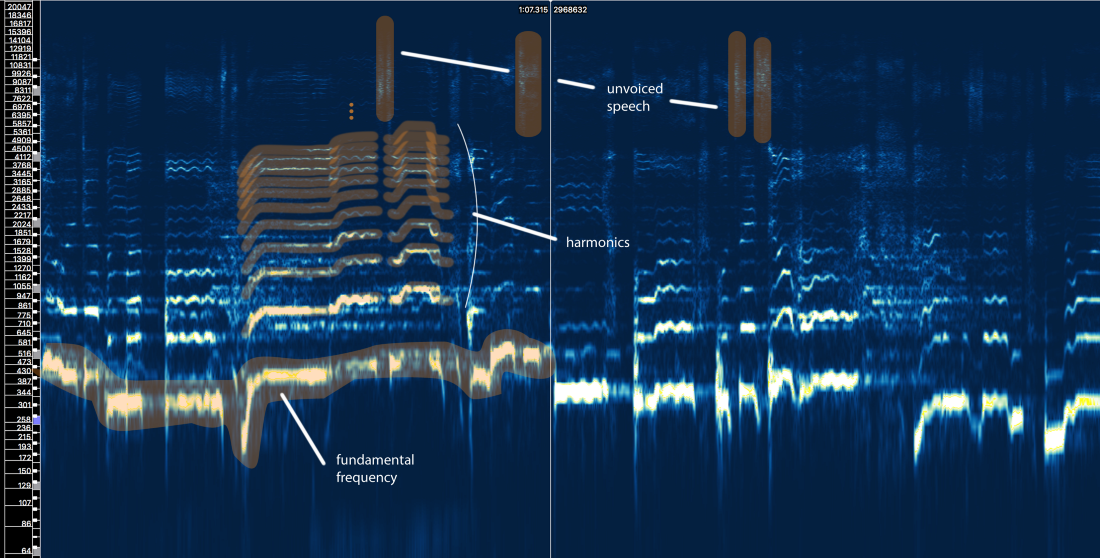
- Фундаментальная частота (f0), которая определяется частотой вибрации наших голосовых связок. В этом случае Ариана поёт в диапазоне 300-500 Гц.
- Ряд гармоник выше f0, которые следуют аналогичной форме или шаблону. Эти гармоники появляются на частотах, кратных f0.
- Невокализированная речь, которая включает согласные, такие как ‘t’, ‘p’, ‘k’, ‘s’ (которые не производятся вибрацией голосовых связок), дыхание и т. д. Всё это проявляется в виде коротких всплесков в высокочастотной области.
Первая попытка с применением правил
Давайте на секунду забудем, что называется машинным обучением. Можно ли разработать метод извлечения вокала на основе наших знаний о сигнале? Позвольте попробовать…
Наивная изоляция вокала V1.0:
- Определить участки с вокалом. В исходном сигнале много всего. Мы хотим сосредоточиться на тех участках, которые действительно содержат вокальное содержание, и игнорировать всё остальное.
- Различить вокализированную и невокализированную речь. Как мы видели, они сильно отличаются. Вероятно, их нужно обрабатывать по-разному.
- Оценить изменение фундаментальной частоты во времени.
- На основании вывода 3 применить какую-то маску для захвата гармоник.
- Сделать что-нибудь с фрагментами невокализированной речи…

Что произойдёт, если вокал обработан реверберацией, задержками и другими эффектами? Давайте взглянем на последний припев Арианы Гранде из этой песни.
Гипотеза: использовать нейросеть как передаточную функцию, которая транслирует миксы в вокалы
Глядя на достижения свёрточных нейросетей в обработке фотографий, почему бы не применить здесь такой же подход?
В конце концов, можно же представить звуковой сигнал «как изображение», используя кратковременное преобразование Фурье, верно? Хотя эти звуковые картинки не соответствуют статистическому распределению естественных изображений, у них всё равно есть пространственные закономерности (во времени и частотном пространстве), на которых можно обучать сеть.

Проведение такого эксперимента было бы дорогостоящим мероприятием, поскольку трудно получить или сгенерировать необходимые учебные данные. Но в прикладных исследованиях я всегда стараюсь применять такой подход: сначала выявить более простую проблему, которая подтверждает те же принципы, но не требует много работы. Это позволяет оценить гипотезу, быстрее выполнять итерации и с минимальными потерями исправить модель, если она не работает как надо.
Подразумеваемым условием является то, что нейросеть должна понимать структуру человеческой речи. Более простая проблема может быть такой: сможет ли нейросеть определить наличие речи на произвольном фрагменте звукозаписи. Мы говорим о надёжном детекторе голосовой активности (VAD), реализованном в виде бинарного классификатора.
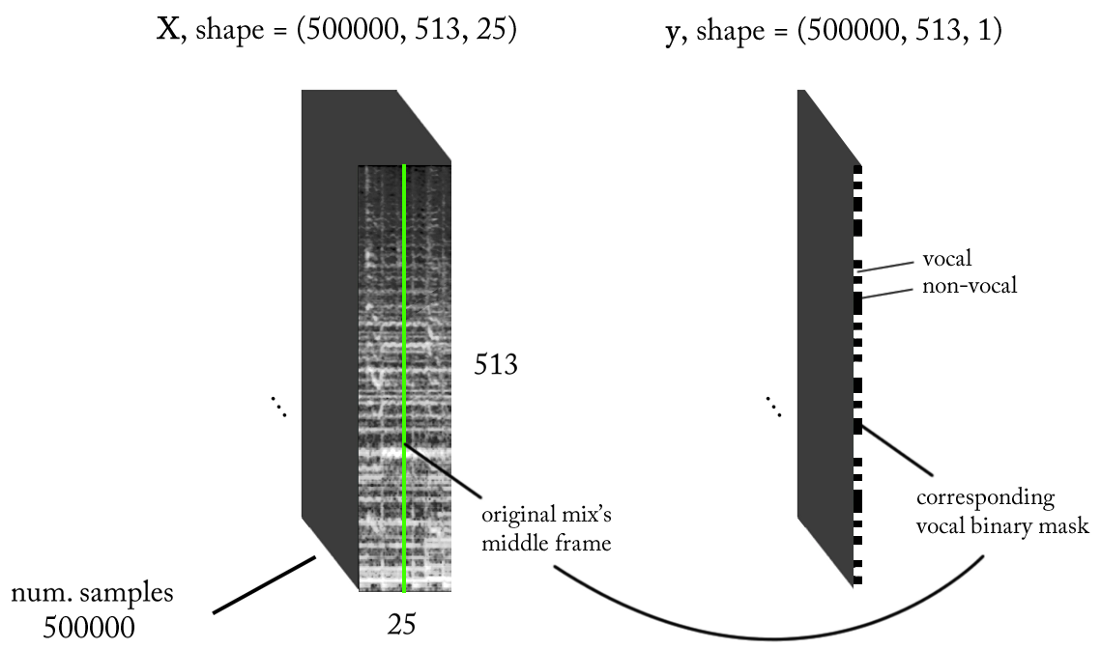
Проектируем пространство признаков
Мы знаем, что звуковые сигналы, такие как музыка и человеческая речь, основаны на временных зависимостях. Проще говоря, ничто не происходит изолированно в данный момент времени. Если я хочу знать, есть ли голос на конкретном фрагменте звукозаписи, то нужно смотреть на соседние регионы. Такой временной контекст даёт хорошую информацию о том, что происходит в интересующей области. В то же время желательно выполнять классификацию с очень малыми временными приращениями, чтобы распознавать человеческий голос с максимально возможным разрешением по времени.

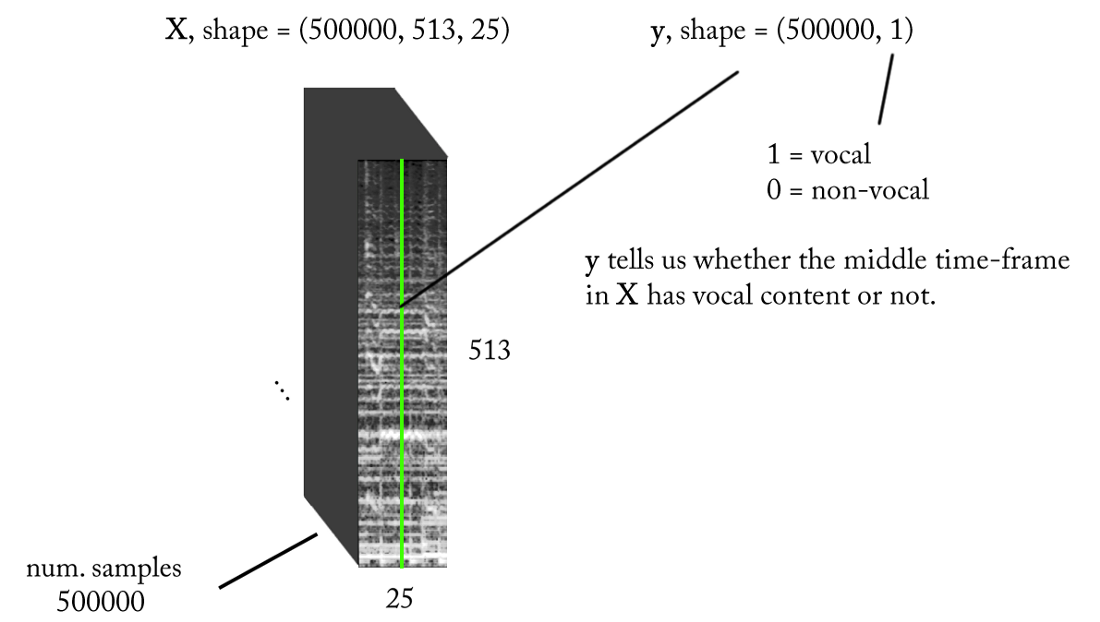
- Частота дискретизации (fs): 22050 Гц (мы понижаем дискретизацию с 44100 до 22050)
- Дизайн STFT: размер окна = 1024, hop size = 256, интерполяция мел-шкалы для взвешивающего фильтра с учётом восприятия. Поскольку наши входные данные настоящие, можно работать с половиной STFT (объяснение выходит за рамки этой статьи...), сохраняя компонент DC (необязательное требование), что даёт нам 513 частотных бункеров.
- Целевое разрешение классификации: один кадр STFT (~11,6 мс = 256 / 22050)
- Целевой временной контекст: ~300 миллисекунд = 25 кадров STFT.
- Целевое количество обучающих примеров: 500 тыс.
- Предполагая, что мы используем скользящее окно с шагом в 1 таймфрейм STFT для генерации учебных данных, нужно около 1,6 часов размеченного звука для генерации 500 тыс. образцов данных
С вышеуказанными требованиями вход и выход нашего бинарного классификатора выглядят следующим образом:
Модель
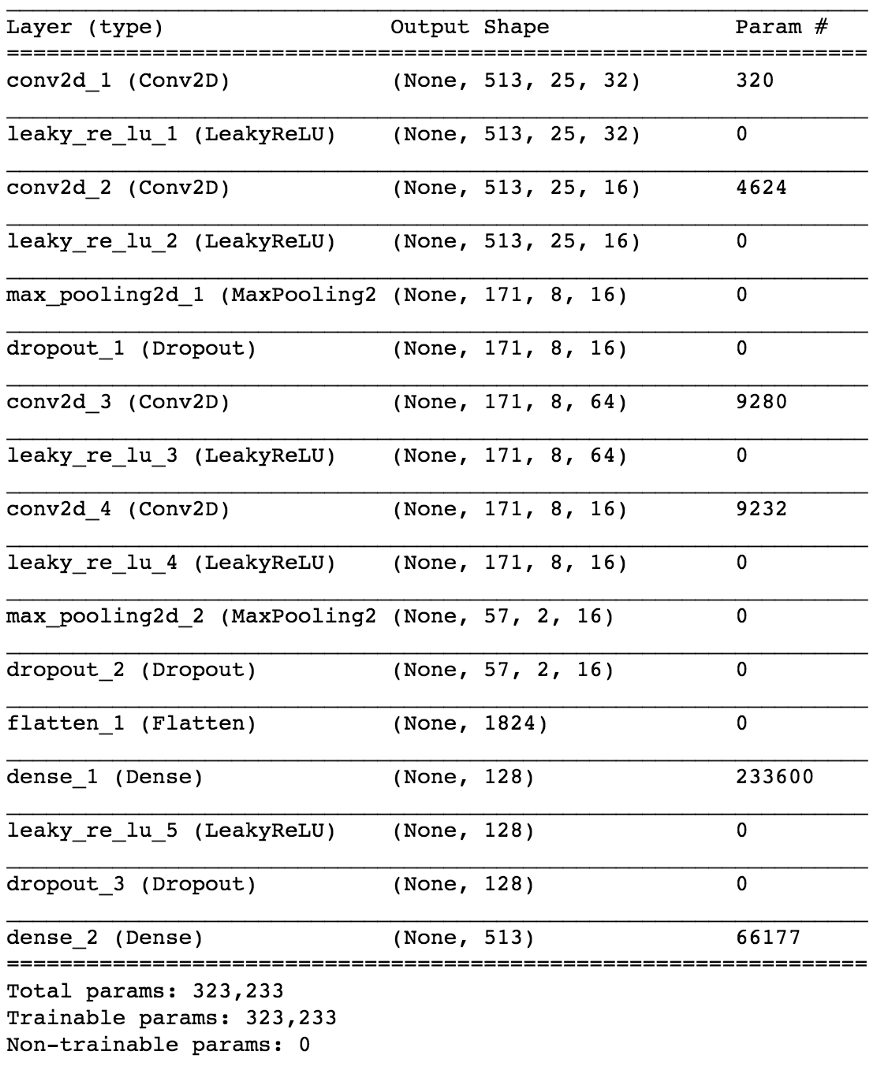
С помощью Keras построим небольшую модель нейросети для проверки нашей гипотезы.
import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D from keras.optimizers import SGD from keras.layers.advanced_activations import LeakyReLU model = Sequential() model.add(Conv2D(16, (3,3), padding='same', input_shape=(513, 25, 1))) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(64)) model.add(LeakyReLU()) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss=keras.losses.binary_crossentropy, optimizer=sgd, metrics=['accuracy'])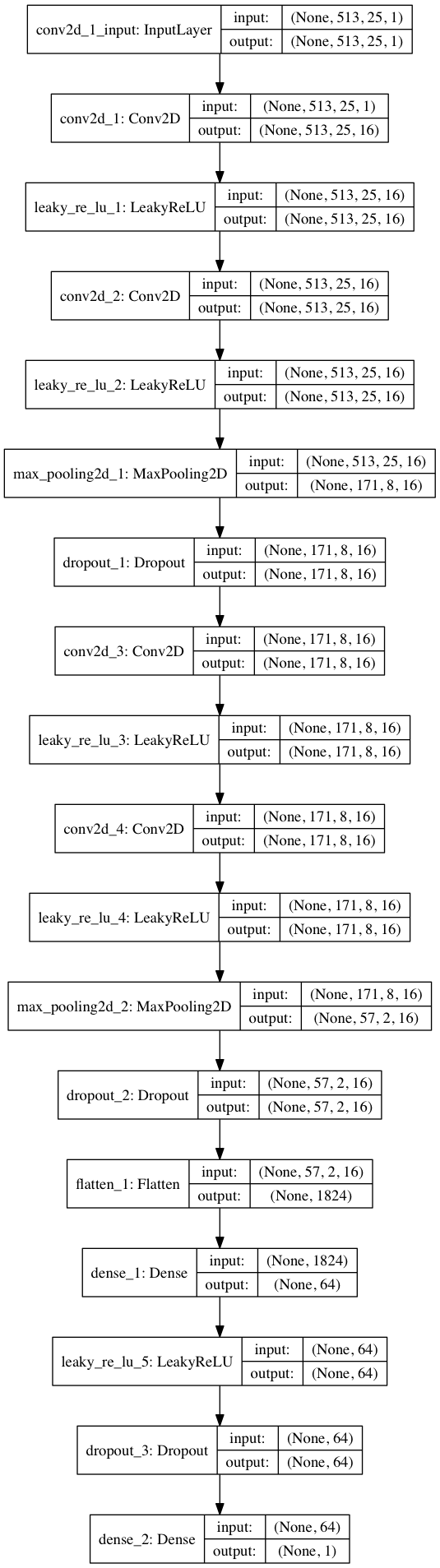
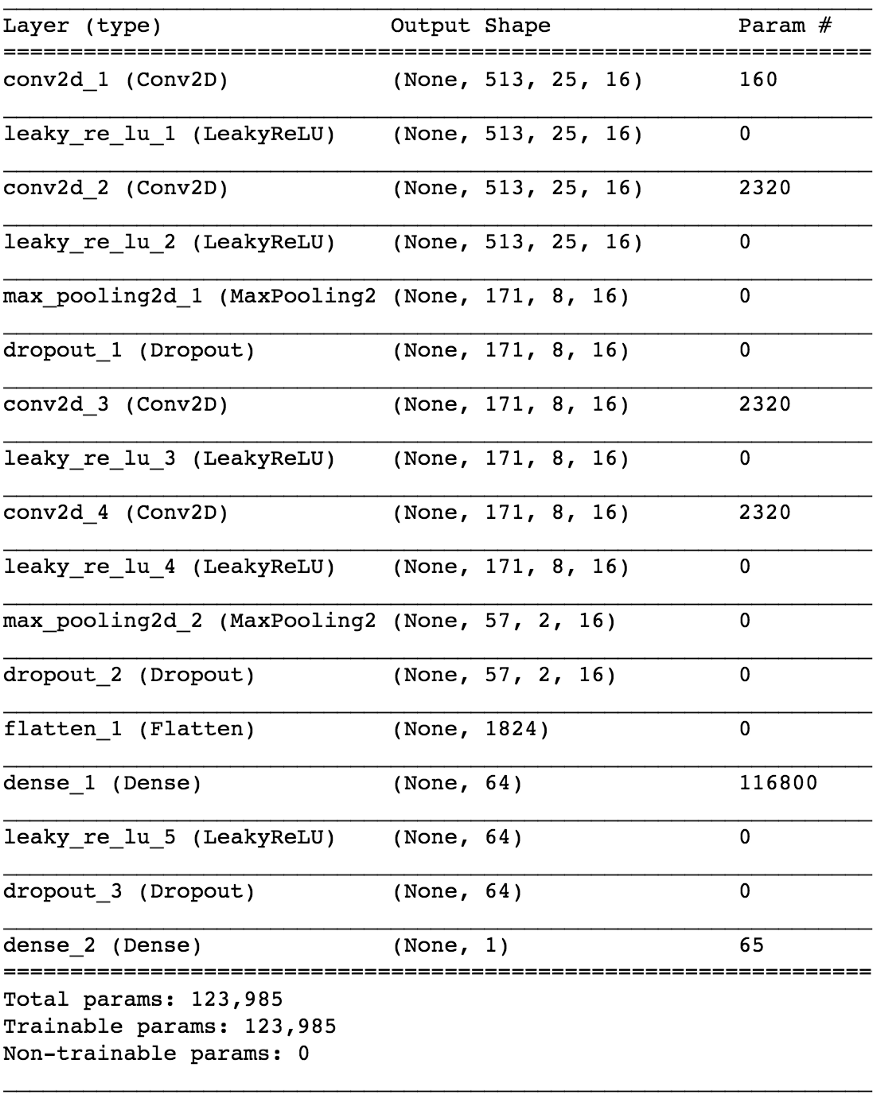
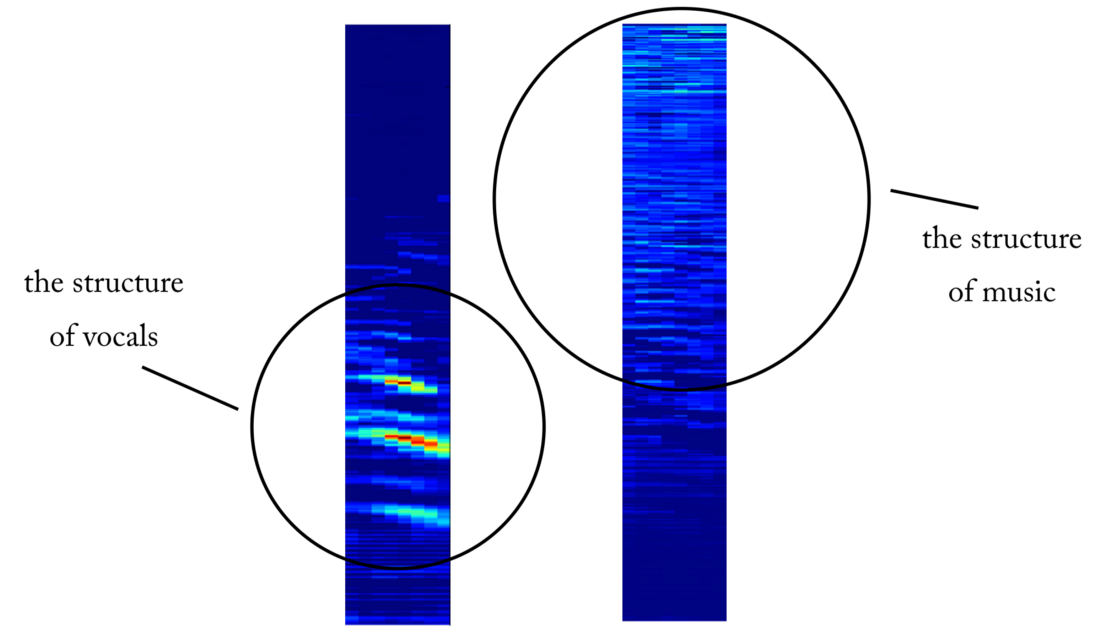
От детектора голоса к разъединению сигнала
Решив более простую задачу классификации, как нам перейти к реальному выделению вокала из музыки? Ну, глядя на первый наивный метод, мы всё равно хотим как-то получить амплитудную спектрограмму для вокала. Теперь это становится задачей регрессии. Что мы хотим сделать, так это по конкретному таймфрейму из STFT исходного сигнала, то есть микса (с достаточным временным контекстом) рассчитать соответствующий амплитудный спектр для вокала в этом таймфрейме.
Что насчёт обучающего набора данных? (вы можете спросить меня в этот момент)
Вот чёрт… зачем же так. Я собирался рассмотреть это в конце статьи, чтобы не отвлекаться от темы!
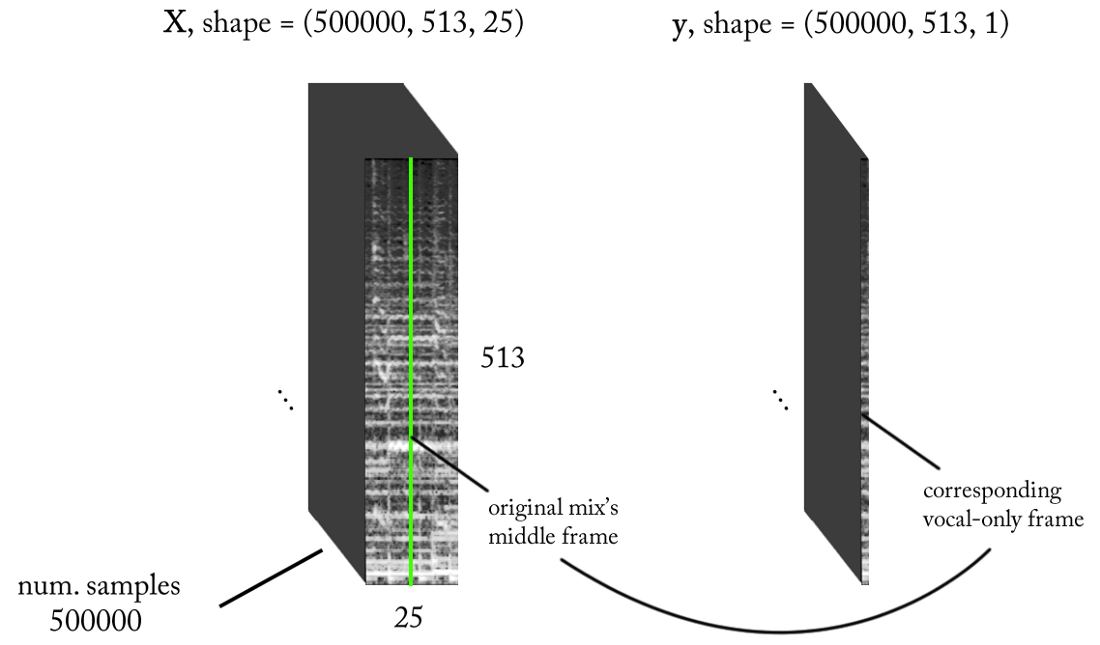
Хотя такое представление ввода/вывода имеет смысл, после обучения нашей модели несколько раз, с различными параметрами и нормализациями данных, результатов нет. Кажется, мы просим слишком многого…
Мы перешли от бинарного классификатора к регрессии на 513-мерном векторе. Хотя сеть в некоторой степени изучает задачу, но в восстановленном вокале всё равно есть очевидные артефакты и помехи от других источников. Даже после добавления дополнительных слоёв и увеличения количества параметров модели результаты не сильно меняются. И тогда встаёт вопрос: как обманом «упростить» для сети задачу, и при этом достичь желаемых результатов?
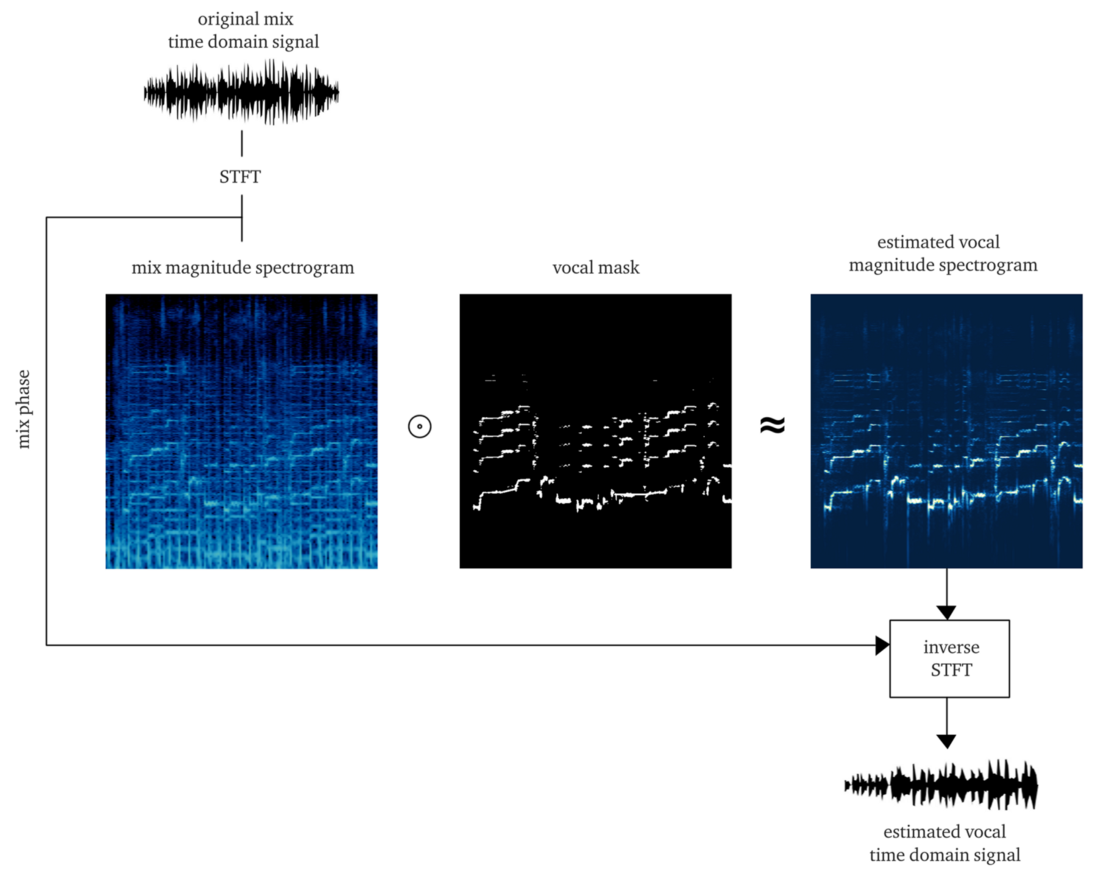
Что если вместо оценки амплитуды STFT вокала обучать сеть получению бинарной маски, которая при применении к STFT микса даёт нам упрощённую, но перцептивно-приемлемую амплитудную спектрограмму вокала?
Экспериментируя с различными эвристиками, мы придумали очень простой (и, безусловно, неортодоксальный с точки зрения обработки сигналов...) способ извлечения вокала из миксов с использованием бинарных масок. Не вдаваясь в подробности, суть в следующем. Представим выход как бинарное изображение, где значение ‘1’ указывает на преобладающее присутствие вокального контента на заданной частоте и таймфрейме, а значение ‘0’ указывает на преобладающее присутствие музыки в данном месте. Можем назвать это бинаризацией восприятия, просто чтобы придумать какое-то название. Визуально это выглядит довольно некрасиво, если честно, но результаты удивительно хороши.
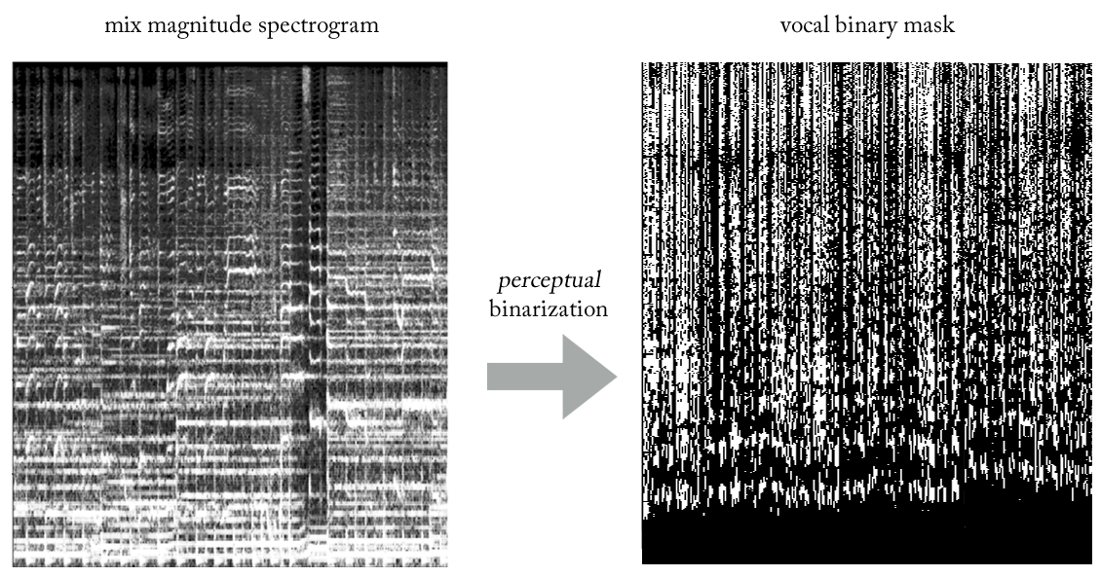

Как восстановить сигнал временной области?
По сути, как в наивном методе. В данном случае на каждый проход мы прогнозируем один таймфрейм бинарной маски вокала. Опять же, реализуя простое скользящее окно с шагом одного таймфрейма, продолжаем оценивать и объединять последовательные таймфреймы, которые в конечном итоге составляют всю вокальную бинарную маску.

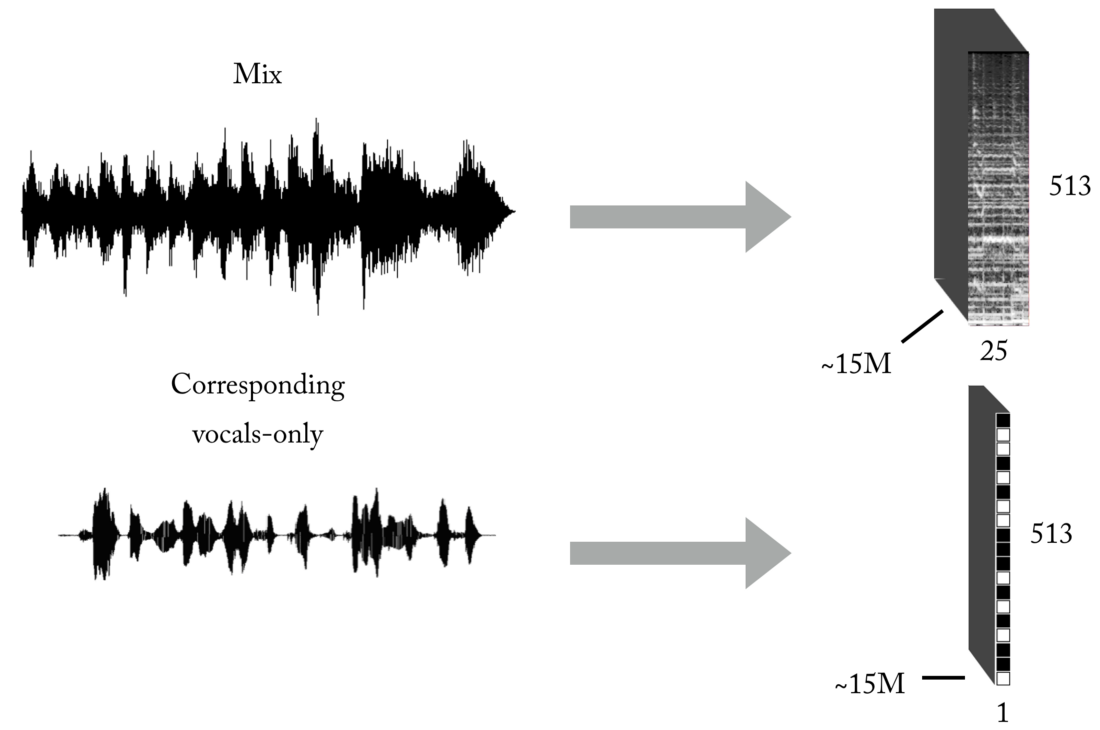
Создание обучающего набора
Как вы знаете, одна из главных проблем при обучении с учителем (оставьте эти игрушечные примеры с готовыми датасетами) — правильные данные (по количеству и качеству) для конкретной проблемы, которую вы пытаетесь решить. Исходя из описанных представлений ввода и вывода, для обучения нашей модели сначала понадобится значительное количество миксов и соответствующих им, идеально выровненных и нормализованных вокальных треков. Такой набор можно создать несколькими способами, и мы использовали комбинацию стратегий, начиная от ручного создания пар [микс <-> вокал] на основе нескольких а капелл, найденных в интернете, до поиска музыкального материала рок-групп и скрапинга Youtube. Просто чтобы дать вам представление, насколько это трудоёмкий и болезненный процесс, частью проекта стала разработка такого инструмента для автоматического создания пар [микс <-> вокал]:

Архитектура конвейера
Как вы наверное знаете, создать модель ML для конкретной задачи — только полдела. В реальном мире нужно продумать архитектуру программного обеспечения, особенно если нужна работа в реальном времени или близком к нему.
В этой конкретной реализации реконструкция во временную область может происходить сразу после прогнозирования полной бинарной маски вокала (автономный режим) или, что более интересно, в многопоточном режиме, где мы получаем и обрабатываем данные, восстанавливаем вокал и воспроизводим звук — всё мелкими сегментами, близко к потоковой передаче и даже практически в режиме реального времени, обрабатывая музыку, которая записывается на лету с минимальной задержкой. Вообще, это отдельная тема, и я оставлю её для другой статьи, посвящённой ML-конвейерам в реальном времени…
Наверное, я сказал достаточно, так почему бы не послушать парочку примеров!?
Daft Punk—Get Lucky (студийная запись)
Adele—Set Fire to the Rain (живая запись!)
Да, и «ещё кое-что»…
Если система работает для вокала, почему бы не применить её к другим инструментам...?
Статья и так довольно большая, но учитывая проделанную работу, вы заслуживаете услышать последнее демо. С точно такой же логикой, как при извлечении вокала, мы можем попытаться разделить стереомузыку на составляющие (барабаны, басы, вокал, другие), сделав некоторые изменения в нашей модели и, конечно, имея соответствующий набор обучения :).
Телеграм: t.me/ainewsline
Источник: habr.com