Вместо классического программирования уже завтра явится… что?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-01-02 14:14
Обучение императивному программированию напоминает сизифов труд: тупишь часами над пятью строчками кода, не в силах их скомбинировать в правильный результат, в мозгах сплошной "агонь". Почему так? Поэтому что абстракции, предлагаемые мэйстримовскими языками, это сплошной навоз и палки, конечно из них лепить что-то работающее тяжело и ньюбу, и профессионалу.
Какие абстракции для начала нужны? Логика Хоара например, которая позволяет сразу писать математически корректный, доказанный код.
Какие абстракции формируются в голове у человека, изучившего императивное программирование мэйнстримовским способом, и затем утащившего эти кривые навыки в продакшен?
Мутабельность (направленные графы с размеченными вершинами) да полиморфизм (произвольно вложенные друг в друга функции с побочными эффектами). По сути, миллионы людей на Земле регулярно изобретают и потом всю жизнь практикуют вот такую нехитрую математическую теорию :-) Основная её характеристика -- способность несколькими простыми операциями создать крайне запутанные структуры. Пример с самозапутывающимися проводками наушников очень наглядный.
Сильную для своего времени концепцию реляционных систем, где все эти запутанности прозрачно развязываются, Кодд сформулировал в 1970-м. Легко понимать, легко оптимизировать, отсутствует вложенность, декларативная запись, чистый язык запросов на реляционная алгебре.
Сегодня вообще-то в приличном обществе SQL упоминать уже не принято, но 50 лет он был эталонным примером правильного подхода к разработке.
Но элегантность SQL быстро привела к несоответствию импеданса, как выразились в 1984-м Copeland и Maier, классики computer science. SQL был настолько стройным, что обычные языки программирования со своими кривыми абстракциями никак с ним не состыковывались, и пришлось изобретать объектно-реляционный маппинг -- очень тормозную, как правило, прослойку между СУБД и прикладным кодом, отображение структур таблиц в классы.
Потом появились noSQL-системы, работающие с иерархически организованными документами, потом их снова скрестили с классической реляционкой, получив NewSQL... Однако сильной математики внутри всего этого ньювейва пока так и не проявилось.
При том, что отдельные системы на хорошем фундаменте есть, и очень классные, ну а почему они не становятся массовыми, множество разных причин. Например, в яндексовской ШАД упоминается алгоритмическая технология COLA (optimization scheme for fusing compile-time operators into reasonably-sized run-time software units called processing elements), за реализацию движков на основе которой просят приличные денежки. Узкая ниша, расширяться особо не хотят, ну и замечательно.
А вот на помощь массовому программированию неотвратимо приходит теория категорий, по-хорошему никуда без неё. Да, алгебра монад, композиции морфизмов, но это всё must know, в топ без этого никак. Например, можно скрестить реляционную алгебру и категории Клейсли. В некотором смысле, система типов .NET поддерживает монады (например, IEnumerable<> как функтор), и в частности, LINQ -- весьма мощная реализация кусочков теорката с провязкой релационной алгебры.
.NET-программисты об этом наверняка не подозревают :)
Классический мир разработки, Software 1.0 -- это тройка
язык программирования + библиотеки + рантайм
Профессор Эрик Мейер, занимавшийся разработкой компилятора Haskell, работавший архитектором Microsoft и развивавший вышеупомянутую тему в .NET, а затем помогавший Фейсбуку с языком Hack (диалект PHP для виртуалки HipHop), Нетфликсу с библиотекой RxJava (расширение реактивного программирования для JVM) и Гуглу с языком Dart,
похоронил эту тройку ещё в 2017-м. Про деление на фронтенд, мобилки и бэкенд можно также плавно забывать.
Потому что Software 2.0 по Андрею Карпати
https://vk.com/wall-152484379_402
на самом деле уже тут.
Как пока ещё программируют человеки, не желающие изучать теоркат?
Хлебанул кофейку, простимулировал мозг, кое-как выдал код.
Дональд Кнут в 1961-м учит своего котика денотационной семантике
Каким путём к созданию программ подбирается искусственный интеллект?
Мы пишем программы с одной целью -- чтобы они выполняли действия, заданные техническим заданием, спецификациями. И вот AI/ML подход в том, что исходный код в классическом понимании больше не будет нужен. На вход ML-системе подаём набор формализованных требований и наборы обучающих данных, на выходе получаем модель, которая это всё "как-то" делает.
И вот здесь остаётся небольшой зазор для белковых организмов, как иронизировал Михаил Донской, который позволяет забраться внутрь этого весьма закрытого процесса Software 2.0 (а не просто приклеиться к нему), и, когда это всё наконец массово расцветёт, оказаться на волне. Оседлать тигра. Но сроки, думаю, очень ограниченные, ну может лет десять максимум. Эти технологии что-то уж слишком быстро развиваются.
Дальше рассмотрим, какая математика заложена в основу ML, и самое главное, где же пересекается машинное обучение и классическое программирование (глубинно, а не на уровне интерфейсов к массовым фреймворкам вроде TensorFlow и PyTorch), и что тут желательно срочно изучать.
И как ещё не поздно попасть в этот тренд даже тем, кто пока даже не умеет программировать.
Классическое программирование развивается прежде всего как инженерная отрасль, однако максимальный эффект дают совсем иные подходы. Детерминированность и аристотелева логика против неопределённости и непрерывности -- концепции моделирования, зародившейся как наука почти полтысячи лет назад, а во всей красе расцветшей в 18-м веке: Томас Байес, легендарная байесовская вероятность, на основе которой, например, мистер Скрепка когда-то давал рекомендации.
Идея моделирования технически проста: имеется чёрный ящик с моделируемой функцией, в реальном мире она, получая на вход x, выдаёт y, а в модели -- y`, и мы различными приёмчиками стараемся сделать так, чтобы на контрольном датасете результаты были примерно такие же, как и в реале. Ну и дальше понеслась backpropagation, можно использовать и линейную регрессию, и градиентный спуск, и ещё много чего другого. Кто делал у меня занятия по нейросетям, помнит схему перцептрона, которая примитивно реализуется одним циклом корректировки весов.
Проблема этих подходов в том, что предлагаемые ими абстракции к повседневному программированию никак не применимы. Всё упирается в технологию определения моделей. Когда вы попробуете заняться этим в TensorFlow или PyTorch, то сразу уткнётесь в море технических деталей, как и в любом сложном инженерном фреймворке. Они не дают вам хороших абстракций, а лишь довольно бессистемный набор вычислительных возможностей.
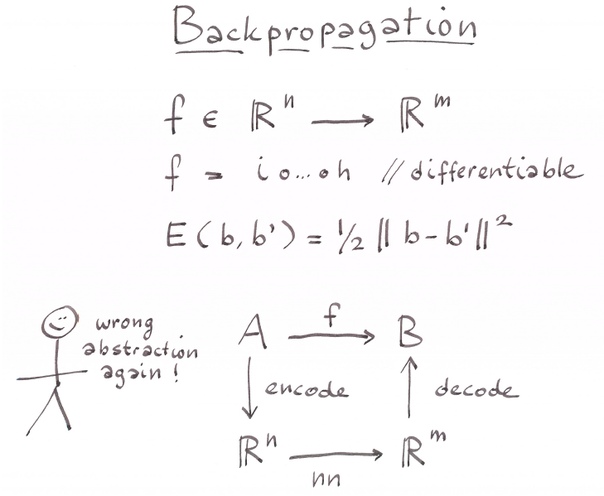
И вот год назад Ян Лекун заявил в своём знаменитом посте: «Deep Learning est mort. Vive Differentiable Programming!»
Что же такое Differentiable Programming? Даже на хабре ни одной заметки не нашлось. Есть ещё Dynamic Differential Programming, но это чистая оптимизация.
Дифференциальное программирование -- это прежде всего автоматическое дифференцирование (АД).
https://habr.com/company/intel/blog/170729/
https://codeforces.com/blog/entry/6808
Что делать, если вам в программе надо вычислить значение производной некоторой функции, но вам очень не хочется прилагать для этого специальные усилия — т.е. не хочется ни дифференцировать на бумажке, ни забивать ваши формулы в Sage/Wolfram Alpha/Maple/...? Тем более если вы не хотите заново проводить все выкладки, если вдруг окажется, что производную надо брать от другой функции?
Короче говоря, причина, по которой Ян Лекун закрыл темку Deep Learning, такая: правильная абстракция для всех современных успешных методов машинного обучения это отнюдь не скрытые слои нейросеток (это скорее техническая фича), а обучение с помощью некоторой формы дифференциального исчисления, как правило, стохастического градиентного спуска. Правда, лет автоматическому дифференцированию столько же, сколько и персептрону :)
"A Simple Automatic Derivative Evaluation Program" Robert Wengert 1964
Но что же в АД оказалось такого сермяжного? Ближе всего оно к численным методам аппроксимации и символьному дифференцированию.

Отличие от первого очевидно: АД всегда вычисляет точно. Кроме того, мнение, что численная аппроксимация очень быстрая, очень обманчиво: да, именно этому учат в универах, но как только мы ставим задачу увеличивать точность результата, начинаются полные тормоза и печаль. И компьютеры не способны эффективно поддерживать высокую точность, и погрешности накапливаются, и про метод Ньютона-Рафсона на русском лишь единичные ссылки выдаются, а эти моменты для многомерности глубинного обучения очень актуальны. Потому и майнинг моделей получается таким долгим.
Символьное дифференцирование смотрится более соблазнительно (привет, Вольфрам!), однако если смотреть вглубь, окажется, что со времен Лиспа 1959-го года ничего нового не появилось, и все системы символьного дифференцирования фактически едины в своей лисповости. Минус здесь, что мы снова завязываемся на конкретные реализации, пакеты, диалекты. И вот что хочется: подавать вход и получать выход в формате стандартной математической нотации. Вроде бы это чисто технический момент -- делаем парсеры для TeX и конкретных библиотек АД для python/java/... , бинго!
Кстати, уже сегодня наверняка можно очень хорошо схантиться, выложив например на гитхаб такой парсер и рассказав о нём на реддите и y-комбинаторе.
И вот гений Ян Лекун выявил глубинные связи между многими даже не и очень смежными темами computer science -- и олдскулом в символической алгебре, и дуальными числами, и декларативным программированием (его движки по сути работают как backpropagates!), и, очевидно, функциональным (мы ведь работаем с чистыми функциями), и метапрограммированием!

Уже самое ближайшее будущее взрослого программирования -- это Haskell, Standard ML, OCaml, MLTT/завтипы Agda/Idris/F* и далее по списку, однозначно!
продолжение следует
Телеграм: t.me/ainewsline
Источник: m.vk.com