Tensorflow Lite теперь быстрее на мобильных графических процессорах
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-01-16 22:06
Выполнение вывода на моделях вычислительного машинного обучения на мобильных устройствах требует ресурсов из-за ограниченной обработки и мощности устройств. В то время как преобразование в модель с фиксированной точкой является одним из способов ускорения, наши пользователи попросили нас о поддержке GPU в качестве опции для ускорения вывода исходных моделей с плавающей точкой без дополнительной сложности и потенциальной потери точности квантования.
Мы слушали, и мы рады сообщить, что вы теперь сможете использовать мобильный GPU для некоторых моделей (перечислены ниже) с выпуском предварительного просмотра разработчика ГПУ бэкэнд для TensorFlow облегченная; он вернется на процессор вывода для части модели, которые не поддерживаются. В ближайшие месяцы мы продолжим добавлять дополнительные ops и улучшать общее предложение GPU backend.
Этот новый бэкенд рычаги:
- Поддержка OpenGL Эс 3.1 вычислительные шейдеры на Android устройства
- Металл вычислительные шейдеры на iOS устройств
Сегодня мы выпускаем предкомпилированный двоичный предварительный просмотр новой серверной части GPU, что позволяет разработчикам и исследователям машинного обучения рано шанс попробовать эту захватывающую новую технологию. Полный релиз с открытым исходным кодом планируется в конце 2019 года, включая обратную связь, которую мы получаем от вашего опыта.

Обнаружение контура лица (не распознавание лица) с помощью tensorflow Lite CPU с плавающей точкой вывода сегодня. Используя новую серверную часть GPU в будущем, можно ускорить вывод с ~4x на Pixel 3 и Samsung S9 до ~6x на iPhone7.
Производительность GPU и CPU
В Google мы уже несколько месяцев используем новую серверную часть GPU в наших продуктах, ускоряя вычислительные сети, которые позволяют использовать наши пользователи.
В портретном режиме на пикселей 3, Tensorflow Лайт ГПУ вывод ускоряет на переднем плане-фон модель по более 4х и новую глубину оценивание модели по более 10х и процессора логического вывода с плавающей точкой. В Ютубе рассказы и площадкой наклейки наши видео в реальном времени сегментация модель ускоряется на 5–10х в различных телефонах.
Мы нашли, что в целом новый графический бэкэнд выполняет 2–7х быстрее , чем с плавающей точкой процессора для реализации широкий спектр разнообразных глубоких нейронных сетевых моделей. Ниже мы сравнили 4 общественные и 2 внутренние модели, охватывающие общие случаи использования разработчики и исследователи сталкиваются с набором устройств Android и Apple:
Публичные модели:
- Сайт MobileNet В1 (224x224) изображения классификация [скачать](изображение классификации модель, предназначенная для мобильных и встраиваемых приложений на основе видения)
- PoseNet для ставят оценку [скачать](видение модели, которая по оценкам позы человека(ов), в изображения или видео)
- DeepLab сегментация (257x257) [скачать](сегментация изображения модели, которая присваивает семантических меток (например, собака, кошка, машина) для каждого пикселя входного изображения)
- Сайт MobileNet ССД обнаружения объектов [скачать](изображение классификации модель, которая обнаруживает несколько объектов с ограничивающими рамками)
Примеры использования Google:
- Контуры лица как используется MLKit
- В реальном времени Видео сегментация как используется площадка стикеры и рассказы на YouTube
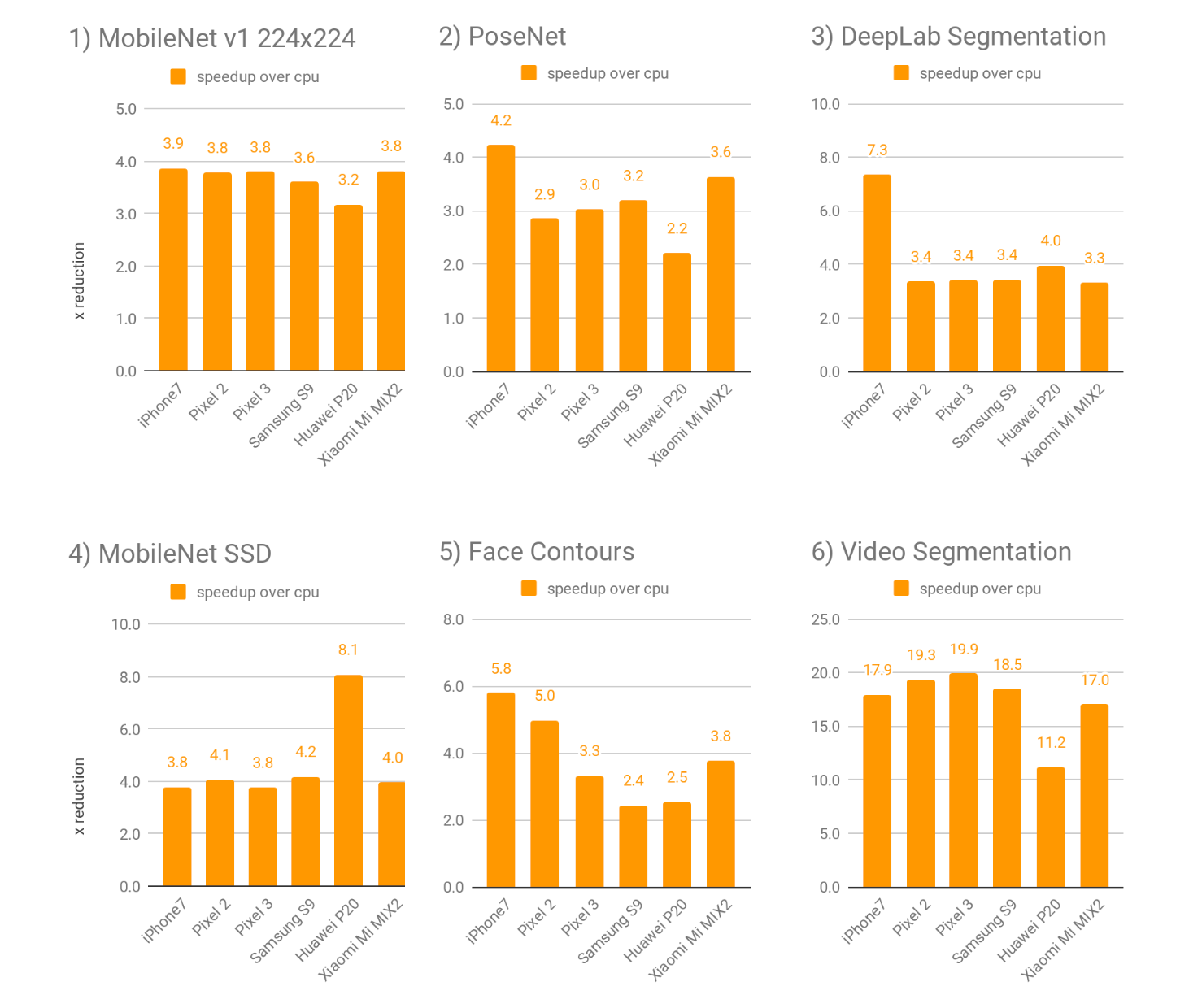
Таблица 1. Средняя производительность ускоряется на GPU по сравнению с базовой производительности процессора на 6 моделей на различных устройствах Android и Apple. Более высокий множитель более лучший.
Ускорение GPU является наиболее значимым для более сложных нейросетевых моделей, которые лучше подходят для использования GPU, таких как плотные задачи прогнозирования/сегментации или классификации. На очень маленьких моделях скорость может быть меньше, и использование ЦП вместо этого может иметь преимущество, чтобы избежать затрат на задержку, присущих передаче памяти.
Как Я Могу Его Использовать?
Руководства
Самый простой способ начать-это следовать нашим руководство по использованию TensorFlow облегченную демо-приложений с GPU делегата. Краткое описание использования также представлено ниже. Для еще более подробной информации смотрите наш полный документации.
Использование Java для Android
Мы подготовили полный Архив Android (AAR), который включает Tensorflow Lite с серверной частью GPU. Отредактируйте файл gradle, чтобы включить этот AAR вместо текущего выпуска, и добавьте этот фрагмент кода инициализации Java.
// Initialize interpreter with GPU delegate.
| GpuDelegate delegate = new GpuDelegate(); |
| Interpreter.Options options = (new Interpreter.Options()).addDelegate(delegate); |
| Interpreter interpreter = new Interpreter(model, options); |
| // Run inference. |
| while (true) { |
| writeToInputTensor(inputTensor); |
| interpreter.run(inputTensor, outputTensor); |
| readFromOutputTensor(outputTensor); |
}
Использование C++ для iOS
Шаг 1. Загрузите двоичный выпуск Tensorflow Lite.
Шаг 2. Изменить свой код так, чтобы он вызывал ModifyGraphWithDelegate() после создания модели.
// Initialize interpreter with GPU delegate.
| std::unique_ptr<Interpreter> interpreter; |
| InterpreterBuilder(model, op_resolver)(&interpreter); |
| auto* delegate = NewGpuDelegate(nullptr); // default config |
| if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; |
| // Run inference. |
| while (true) { |
| WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); |
| if (interpreter->Invoke() != kTfLiteOk) return false; |
ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0));
Что Сейчас Ускоряется?
ГПУ бэкэнд поддерживает операции Select (см. документацию). Ваша модель будет работать быстрее, когда содержит только эти операции; неподдерживаемые операции GPU автоматически вернуться к CPU.
Как Это Работает?
Глубокие нейронные сети выполняют сотни операций в последовательности, что делает их очень подходящими для графических процессоров, которые разработаны с учетом ориентированных на пропускную способность параллельных рабочих нагрузок.
ГПУ делегат инициализирован, когда Interpreter::ModifyGraphWithDelegate() называется на языке Objective-C++ или косвенно путем вызова Interpreterс конструктора Interpreter.Options в Java. В этой фазе инициализации на основе плана выполнения, полученного из фреймворка, строится каноническое представление входной нейронной сети. С этим новым представлением применяется набор правил преобразования. Они включают, но не ограничиваются:
- Отбраковка ненужных операций
- Замена ops другими эквивалентными ops, которые имеют лучшую производительность
- Слияние операций ops для уменьшения конечного числа созданных шейдерных программ
На основе этого оптимизированного графа генерируются и компилируются вычислительные шейдеры; в настоящее время мы используем вычислительные шейдеры OpenGL ES 3.1 на Android и вычислительные шейдеры Metal на iOS. При создании этих вычислительных шейдеров мы также используем различные оптимизации, зависящие от архитектуры, такие как:
- Применение специализации определенных операций вместо их (более медленных) универсальных реализаций
- Ослабляя давление регистра
- Выбор оптимальных размеров рабочей группы
- Безопасно уравновешивающ точность
- Изменение порядка явных математических операций
В конце этих оптимизаций компилируются шейдерные программы, которые могут занять несколько миллисекунд до половины секунды, как и мобильные игры. После компиляции программ шейдера новый механизм вывода GPU готов к действию.
При выводе для каждого входа:
- Входы перешел в ГПУ, если это необходимо: входной тензоры, если не был сохранен как GPU памяти, становятся доступными для ГПУ структурой, создавая ГЛ буферов и текстур или MTLBuffers, при этом возможно копирование данных. Поскольку графические процессоры наиболее эффективны с 4-канальными структурами данных, тензоры с размерами каналов, не равными 4, преобразуются в более удобный для графического процессора макет.
- Шейдерные программы выполняются: вышеупомянутый шейдерные программы вставляются команды буфера очереди и ГПУ осуществляет их. На этом этапе мы также управляем памятью GPU для промежуточных тензоров, чтобы сохранить объем памяти нашей серверной части как можно меньше.
- Выходы переехал в процессор, если это необходимо: после того, как глубокие нейронные сети закончил обработку, рамки, копирование результата из памяти графического процессора для процессора, памяти, если выход в сеть можно напрямую выводить на экран и эта передача не нужен.
Для удобства рекомендуется оптимизировать копирование тензора ввода / вывода и / или сетевую архитектуру. Подробную информацию о такой оптимизации можно найти в TensorFlow облегченная ГПУ документации. Для представления лучших практик, пожалуйста, прочитайте это руководство.
Насколько Она Велика?
Делегат GPU добавит около 270KB к Android armeabi-V7A APK и 212KB к iOS на включенную архитектуру. Однако серверная часть является необязательной, поэтому, если Вы не используете делегат GPU, его не нужно включать.
будущая работа
Это только начало наших усилий по поддержке GPU. Наряду с обратной связью сообщества, мы намерены добавить следующие улучшения:
- Расширить охват операций
- Оптимизация производительности
- Разработка и доработка API
Мы призываем вас оставлять свои мысли и комментарии на нашем сайте GitHub и сайте StackOverflow страницы.
Телеграм: t.me/ainewsline
Источник: medium.com