PyTorch и TensorFlow: отличия и сходства фреймворков
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-01-12 15:00

В статье будет рассказано о главных сходствах и различиях между двумя популярными фреймворками глубокого обучения — PyTorch и TensorFlow. Почему такой выбор библиотек? Существует много фреймворков глубокого обучения, многие из которых жизнеспособны, но я выбрал только PyTorch и TensorFlow, так как интересно сравнить эти два инструмента.
Перед вами перевод статьи PyTorch vs TensorFlow — spotting the difference, автор — Кирилл Добовиков. Ссылка на оригинал — в подвале статьи.
Корни
TensorFlow разработан подразделением Google, Google Brain, и активно используется компанией как для исследований, так и для продакшена. Его ближайший предшественник с закрытым кодом — DistBelief.
PyTorch — брат фреймворка Torch, созданного на основе языка программирования Lua, который разработан компанией Facebook и используется ею. Однако PyTorch это не просто набор оболочек для поддержки популярного языка, PyTorch переписан и скроен так, чтобы быть быстрым и интуитивно понятным.
Лучший способ сравнить два фреймворка — закодить на каждом из фреймворков. В этом репозитории также доступен Jupyter ноутбук с кодом для этой статьи. Кроме того, необходимый код будет представлен здесь тоже.
Для начала давайте напишем на двух фреймворках код для аппроксимации такой функции:
![]()
Попробуем найти неизвестный параметр f пользуясь данными х и значениями функции f(x). Да, для такой задачи использование стохастического градиентного спуска будет излишним, так как аналитическое решение выводится легко. Но эта задача, как простой пример, поможет разрешить наш спор о лучшем фреймворке.
Для начала решим задачу на PyTorch:
При должном опыте работы с фреймворками глубокого обучения можно заметить, что реализуется градиентный спуск вручную. Это не слишком удобно. На этот случай в PyTorch есть модуль optimize, который содержит реализации популярных оптимизационных алгоритмов — RMSProp или Adam. Будем использовать стохастический градиентный спуск (SGD) c инерцией:
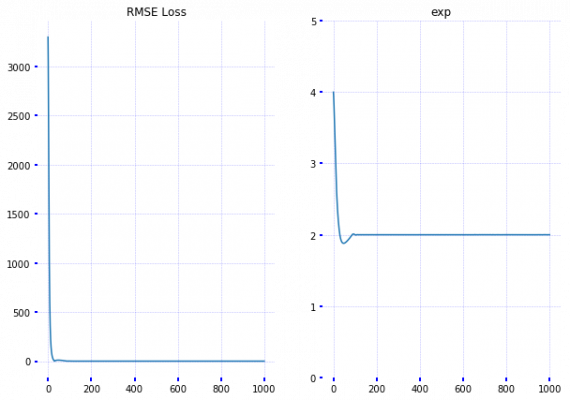
Из графиков видно, что показатель степени быстро найден на основе тренировочных данных. Теперь проделаем тоже самое на TensorFlow:
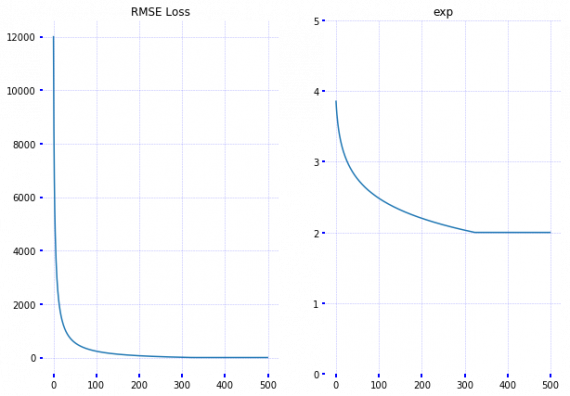
Видно, что реализация на TensorFlow тоже работает. Однако в этом случае потребовалось больше итераций для поиска показателя. Уверен, что причина такого различия — не достаточно хорошая настройка параметров оптимизатора.
Теперь рассмотрим отличия.
Отличие №0 — Распространение
TensorFlow считается стандартом для исследователей и профессионалов из индустрии. Фреймворк отлично задокументирован и, даже если что-то упущено из виду, в интернете есть большое количество подробно написанных туториалов. Легко находятся сотни написанных и обученных моделей на GitHub, начиная отсюда.
Статья по теме: TensorFlow туториал. Часть 2: установка и начальная настройка
PyTorch относительно новый по сравнению с противником (и еще находится в beta-версии), но быстро набирает обороты. Документация и официальные туториалы тоже на высоком уровне. PyTorch также содержит несколько реализация популярных архитектур компьютерного зрения, которые легко использовать.
Статья по теме: Сверточная нейронная сеть на PyTorch: пошаговое руководство
Отличие №1 — Динамическое vs Статическое определение графа
Оба фреймворка работают с тензорами и рассматривают любую модель, как направленный ациклический граф (DAG), но коренным образом отличается способ определения.
TensorFlow следует идиоме “Данные = код, код = данные”. В TensorFlow граф определяется статически перед запуском модели. Связь с внешним миром осуществляется с помощью объекта tf.Session и tf.Placeholder — тензорами, которые во время выполнения программы будут заменены внешними данными.
В PyTorch всё более императивно и динамично: можно определять, изменять и выполнять узлы как вам угодно без дополнительных session- и placeholder-интерфейсов. В общем PyTorch лучше интегрирован с языком Python и ощущается более «естественно» в большинстве случаев. Когда вы пишите на TensorFlow, иногда кажется, что с моделью можно связываться через несколько крошечных отверстий в кирпичной стене, за которой и прячется модель. Тем не менее, последнее является делом вкуса.
Однако такие подходы отличаются не только со стороны разработки программного обеспечения: существуют архитектуры нейронных сетей, которые получают преимущества от динамического подхода. Вспомним рекуррентные нейронные сети (RNN): со статическим графом длина входной последовательности остается постоянной. Это означает, что если вы разрабатываете модель семантического анализа для русскоязычных предложений, необходимо зафиксировать длину предложения на максимальном значении, а все более мелкие последовательности заполнять нулями. Не очень удобно. А при работе с рекурсивными RNN и tree-RNN появляется еще больше проблем. На данный момент TensorFlow имеет ограниченную поддержку динамических входных данных при помощи TensorFlow Fold. В PyTorch такая поддержка реализована по умолчанию.
Отличие №2 — Отладка
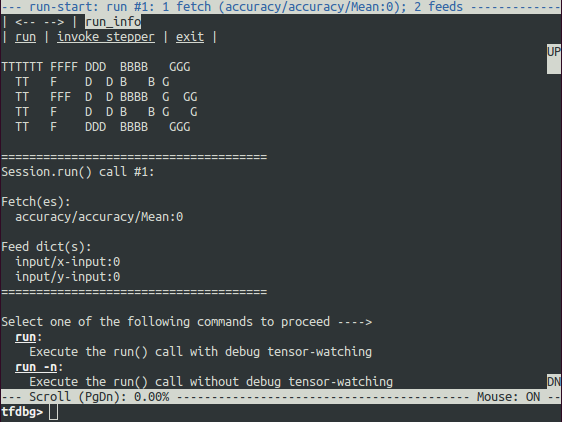
Так как вычислительный граф в PyTorch определяется во время выполнения программы, есть возможность использовать любой инструмент отладки — pdb, ipdb, PyCharm или старые добрые print statements.
С TensorFlow всё не так. Вы можете использовать специальный инструмент — tfdbg, который во время выполнения оценивает выражения и просматривает все тензоры и операции в рамках сессии. Конечно, здесь нет возможности отлаживать код, поэтому необходимо отдельно использовать pdb.
Отличие №3 — Визуализация
Когда дело касается визуализации, мощным инструментом является Tensorboard. Этот инструмент идет вместе с TensorFlow, он очень полезен для отладки и сравнения нескольких тренировочных прогонов. Например, вы обучили модель, потом отрегулировали гиперпараметры и обучили снова. Чтобы увидеть различия, оба запуска могут одновременно быть отображены в Tensorboard. Возможности Tensorboard:
- Отображение графа модели;
- Визуализация распределений и гистограмм;
- Визуализация изображений;
- Визуализация вложений;
- Проигрывание аудио.
Tensorboard показывает сводки, которые собираются модулем tf.summary. Определим для нашего игрушечного примера операции подбора сводок и используем tf.summary.FileWriter для сохранения их на диск.
Для запуска Tensorboard выполним команду tensorboard —logdir=./tensorboard. Этот инструмент очень прост в использовании в облаке, если имеем дело с веб-приложением.
PyTorch противопоставляет Tensorboard свой инструмент — visdom. В нем не так много функций, но он проще в использовании. Также существует интеграция с Tensorboard. Кроме названных инструментов, можно использовать стандартные средства визуализации — matplotlib и seaborn.
Отличие №4 — Развертывание
TensorFlow на данный момент абсолютный победитель по этому показателю, так как имеет фреймворк TensorFlow Serving для развертывания модели на специальном gRPC сервере. Развертывание на мобильных устройствах также возможно.
Вернемся к PyTorch. Здесь можно использовать Flask или любую другую альтернативу, чтобы реализовать REST API поверх модели. Это также можно сделать и с TensorFlow моделям, если по каким-либо причинам для вашего случая не подходит gRPC. Однако, TensorFlow Serving будет лучшим выбором, если производительность является проблемой.
TensorFlow также поддерживает распределенное обучение, которого пока нет в PyTorch.
Отличие №5 — Параллелизм данных
Одно из основных отличий PyTorch от TensorFlow — объявительное распараллеливание данных. Используя torch.nn.DataParallel на любом модуле можно добиться почти магического параллелизма данных по размеру батча. Так преимущества GPU используются почти без усилий.
С другой стороны, TensorFlow позволяет делать тонкую настройку, чтобы выбрать, на каком устройстве выполнить каждую операцию. Тем не менее, параллелизм — работа, требующая большего ручного труда и осторожности. Рассмотрим пример кода на TensorFlow, с помощью которого реализуется операция распараллеливания:
def make_parallel(fn, num_gpus, **kwargs): in_splits = {} for k, v in kwargs.items(): in_splits[k] = tf.split(v, num_gpus)out_split = [] for i in range(num_gpus): with tf.device(tf.DeviceSpec(device_type="GPU", device_index=i)): with tf.variable_scope(tf.get_variable_scope(), reuse=tf.AUTO_REUSE): out_split.append(fn(**{k : v[i] for k, v in in_splits.items()}))return tf.concat(out_split, axis=0)
def model(a, b): return a + b
c = make_parallel(model, 2, a=a, b=b)
Таким образом, при использовании TensorFlow можно достигнуть всего того, что и на PyTorch, но с большими усилиями (в качестве бонуса вы имеете больше контроля над процессом).
Отмечу, что оба фреймворка поддерживают распределенные вычисления и предоставляют высокоуровневые интерфейсы для определения кластеров.
Отличие №6 — Фреймворк или библиотека
Давайте создадим сверточную нейронную сеть (CNN) для классификации рукописных символов. PyTorch начинает выглядеть как фреймворк. Напомним, программный фреймворк предоставляет полезные абстракции в определенной области и позволяет удобно использовать их для решения конкретной проблемы. Это и отличает фреймворк от библиотеки.
Представим здесь модуль dataset, который содержит обертки (wrappers) для популярных датасетов, используемых для оценки качества архитектур глубокого обучения. Модуль nn.Module используется для создания кастомной нейронной сети для нашей задачи классификации. nn.Module — строительный блок, который дает PyTorch для строительства сложной нейросетевой архитектуры. В пакете torch.nn содержится большое количество готовых к использованию модулей, которые можно использовать в нашей модели. Отметим, как PyTorch использует объектно-ориентированный подход, чтобы определить базовые строительные элементы и поставить нас на “рельсы”, по которым надо двигаться, позволяя расширять функциональность с помощью подклассов.
Ниже представлена модифицированная версия https://github.com/pytorch/examples/blob/master/mnist/main.py:
Чистый TensorFlow выглядит больше как библиотека, а не фреймворк: операции низкоуровневые, и вам необходимо писать много шаблонного кода, даже когда вы этого не хотите (определяем смещения и веса снова и снова и снова).
Вокруг TensorFlow стала появляться экосистема высокоуровневых оберток. Каждая обертка направлена на упрощение взаимодействия с библиотекой. Много полезного можно найти в модуле tensorflow.contrib (который не считается стабильным API), а некоторые начинают переходить в основной репозиторий (смотрите tf.layers).
Вы сами можете выбрать, как использовать TensorFLow, и какой фреймворк лучше всего соответствует вашей задаче: TFLearn, tf.contrib.learn, Sonnet, Keras, просто tf.layers или что-то еще. На самом деле, Keras заслуживает отдельного поста, но сейчас находится вне нашего рассмотрения.
Будем для создание нашего классификатора на основе CNN использовать tf.layers и tf.contrib.learn. Код соответствует официальному туториалу по tf..layers:
Таким образом, и TensorFlow и PyTorch предоставляют полезные абстракции для уменьшения количества однотипного кода и ускорения разработки модели. Основное отличие между ними — PyTorch ощущается естественнее на Python и имеет объектно-ориентированный подход, тогда как TensorFlow имеет опции, из которых можно выбрать то, что вам подходит.
PyTorch чище и дружественнее для разработчика. Модуль torch.nn.Module позволяет определять многоразовые модули в манере ООП. Такой подход более гибкий и мощный. Позже вы сможете составлять любые модули при помощи torch.nn.Sequential. Также встроенные модули существуют в функциональной форме, что удобно. Таким образом, части API хорошо согласуются друг с другом.
Конечно, можно писать чистый код на простом TensorFlow, но это требует больше навыков, а реализация будет осуществляться методом проб и ошибок. Что касается высокоуровневых фреймворков, таких как Keras или TFLearn, но они в любом случае теряют в гибкости, которую предлагает TensorFlow.
Заключение
TensorFLow — популярная и зрелая библиотека для глубокого обучения с сильными сторонами в области визуализации и опциями для разработки высокоуровневых моделей. TensorFlow имеет опции для развертывания модели в продакшен и поддержку мобильнх платформ. Эта библиотека станет хорошим выбором, если вы:
- Разрабатываете модель для продакшнаl
- Разрабатываете модель, требующую развертку на мобильном устройстве;
- Хотите поддержку большого комьюнити и качественную документацию;
- Хотите возможности для обучения в различных формах (TensorFlow имеет целый курс, посвященный библиотеке);
- Хотите или вынуждены использовать Tensorboard;
- Вынуждены использовать крупномасштабное распределенное обучение.
PyTorch подойдет, если вы:
- Занимаетесь исследованиями, или к продакшну нет жестких нефункциональных требований;
- Хотите удобнее разрабатывать и отлаживать;
- Просто любите Python;
Если есть время, лучшим решением будет попробовать и PyTorch и TensorFlow и посмотреть, что лучше подходит вам.
Телеграм: t.me/ainewsline
Источник: neurohive.io