Беспилотному авто не обойтись без понимания, что находится вокруг и где именно. В декабре прошлого года разработчик Виктор Отлига vitonka выступил на «Дата-елке» с докладом о детекции 3D-объектов. Виктор работает в направлении беспилотных автомобилей Яндекса, в группе обработки дорожной ситуации (а также преподает в ШАДе). Он объяснил, как мы решаем задачу распознавания других участников дорожного движения в трехмерном облаке точек, чем эта задача отличается от распознавания объектов на изображении и как извлечь пользу из совместного использования разных типов сенсоров.
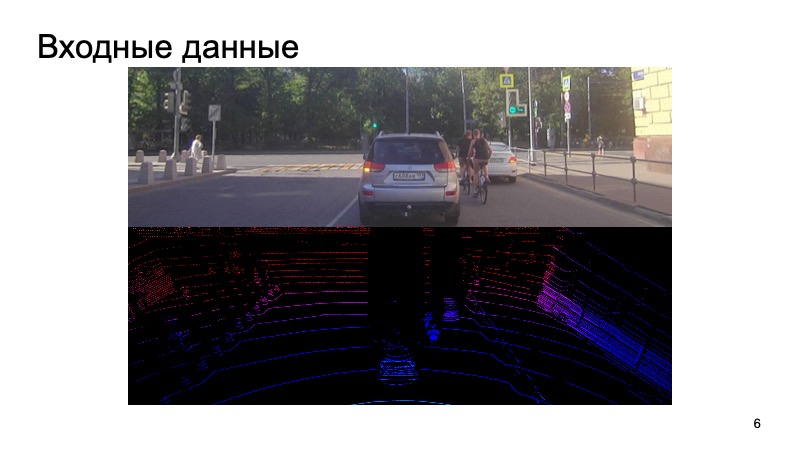
— Всем привет! Меня зовут Виктор Отлига, я работаю в офисе Яндекса в Минске, занимаюсь разработкой беспилотных автомобилей. Сегодня я расскажу о достаточно важной задаче для беспилотников — распознавании 3D-объектов вокруг нас. Чтобы ездить, надо понимать, что находится вокруг. Я коротко расскажу, какие датчики и сенсоры используются на беспилотных автомобилях и какие используем мы. Расскажу, что представляет собой задача детекции 3D-объектов и как померить качество детекции. Потом расскажу, на чем это качество можно мерить. И потом сделаю краткий обзор хороших современных алгоритмов, в том числе тех, на идеях из которых основаны наши решения. А в конце — маленькие результаты, сравнение этих алгоритмов, и нашего в том числе. Примерно так сейчас выглядит наш рабочий прототип беспилотного автомобиля. Именно такое такси может прокатить любого желающего без водителя в городе Иннополис в России, а также в Сколково. И если приглядеться, сверху большая плашка. Что же там внутри? Внутри нехитрый набор сенсоров. Есть антенна GNSS и GSM, чтобы определять, где находится автомобиль, и иметь связь с внешним миром. Куда же без такого классического датчика, как камеры. Но нас сегодня будут интересовать лидары. Лидар выдает примерно такое облако точек вокруг себя, у которых есть три координаты. И с ними приходится работать. Я расскажу, как, используя картинку с камеры и лидарное облако, распознать какие-нибудь объекты. В чем задача? На вход поступает картинка с камеры, камера синхронизирована с лидаром. Было бы странно использовать картинку с камеры секунду назад, брать лидарное облако совсем с другого момента и пытаться на нем распознать объекты. Мы как-то синхронизируем камеры и лидары, это отдельная непростая задача, но мы с ней успешно справляемся. На вход поступают такие данные, и в конце хотим получить коробочки, bounding boxes, которые ограничивают объект: пешеходов, велосипедистов, машин и прочих участников дорожного движения и не только. Задачу поставили. Как мы будем ее оценивать?
Широко изучена задача 2D-распознавания объектов на изображении.
Ссылка со слайда
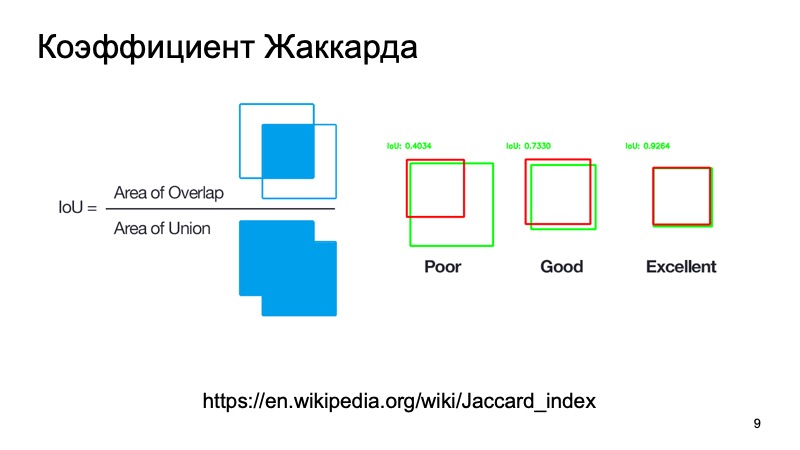
Можно воспользоваться стандартными метриками или их аналогами. Есть коэффициент Жаккарда или intersection over union, замечательный коэффициент, который показывает, насколько хорошо мы объект задетектили. Можем взять коробочку, где, как мы предполагаем находится объект, и коробочку, где он находится на самом деле. Посчитать эту метрику. Есть стандартные пороги — допустим, для машин часто берут порог в 0,7. Если эта величина больше, чем 0,7, мы считаем, что успешно задетектировали объект, что объект там находится. Мы молодцы, можем ехать дальше.
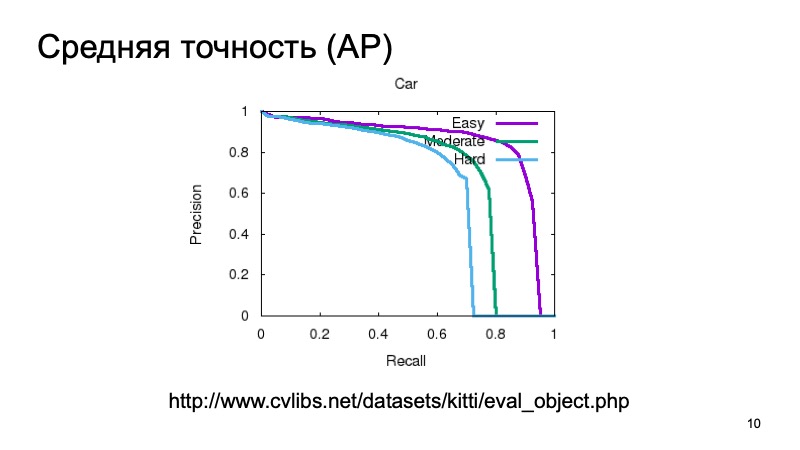
Кроме того, чтобы задетектить объект и понять, что он где-то есть, нам хотелось бы считать какую-то уверенность в том, что мы действительно видим там объект, и ее тоже мерить. Можно мерить нехитро, считать среднюю точность. Можно взять кривую precision recall и площадь под ней и говорить: чем она больше, тем намного лучше.
Ссылка со слайда
Обычно для измерения качества 3D-детекции берут датасет и делят его на несколько частей, потому что объекты могут находиться близко или дальше, могут быть частично заслонены чем-то другим. Поэтому часто валидационную выборку делят на три части. Объекты, которые легко задетектировать, средней сложности и сложные, далекие или которые заслонены сильно. И меряют отдельно на трех частях. И в результатах при сравнении мы тоже будем брать такое разбиение.
Мерить качество можно как в 3D, аналог intersection over union, но уже не отношение площадей, а, например, объемов. Но беспилотному автомобилю, как правило, не очень важно, что творится по координате Z. Мы можем взять вид сверху, bird’s eye view, и считать какую-то метрику, как будто мы смотрим это все в 2D. Человек навигируется более-менее в 2D, и беспилотный автомобиль так же. Насколько высока коробочка, не очень часто важно. На чем мерить? Наверное, все, кто хоть как-то сталкивался с задачей детекции в 3D по лидарному облаку, слышали о таком датасете, как KITTI.
Ссылка со слайда
В некоторых городах Германии был записан датасет, ездила машинка, оборудованная сенсорами, у нее были и GPS датчики, и камеры, и лидары. Потом было размечено порядка 8000 сцен, и было поделено на две части. Одна часть тренировочная, на которой все могут тренироваться, а вторая — валидационная, чтобы мериться результатами. Валидационная выборка KITTI считается мерилом качества. Во-первых, на сайте датасета KITTI есть лидер-борд, туда можно посылать свое решение, свои результаты на валидационном датасете, и сравниваться с решениями других игроков на рынке или исследователями. Но также этот датасет доступен публично, можно скачать, никому не рассказать, проверить свои, сравниться и с конкурентами, но публично не выкладывать.
Внешние датасеты — это хорошо, на них не надо тратить свое время и ресурсы, но как правило, машина, которая ездила в Германии, может быть оборудована совсем другими датчиками. И всегда хорошо иметь свой внутренний датасет. Тем более внешний датасет расширять за счет других тяжелее, а свой проще, можно этим процессом управлять. Поэтому мы используем замечательный сервис Яндекс.Толока. Мы доработали свою специальную систему для заданий. Пользователю, который хочет помочь в разметке и получить за это вознаграждение, мы выдаем картинку с камеры, выдаем лидарное облако, которое можно повертеть, приблизить, отдалить, и просим его поставить коробочки, ограничивающие наше пространство bounding boxes, чтобы в них попадала машина или пешеход, или что-то другое. Таким образом мы собираем внутреннюю выборку для личного использования. Допустим, мы определились, какую задачу мы будем решать, как будем считать, что мы это сделали хорошо или плохо. Взяли где-то данные.
Какие есть алгоритмы? Начнем с 2D. Задача детекции 2D очень хорошо известна и изучена.
Ссылка со слайда
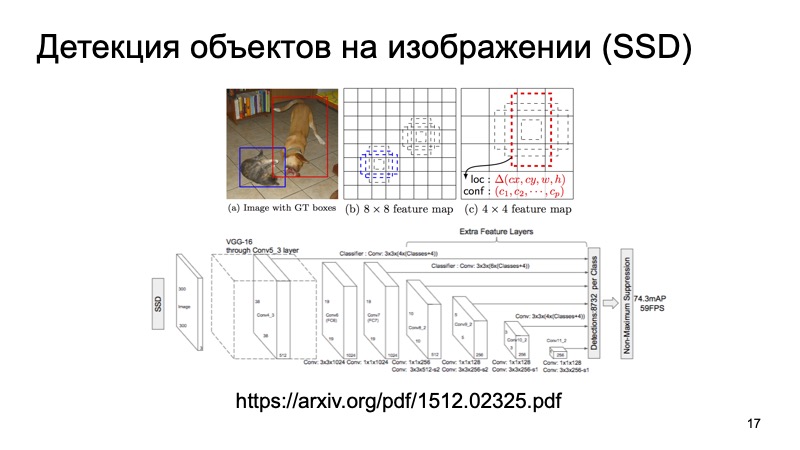
Наверняка многие знают об алгоритме SSD, который является одним из state of the art методов детекции 2D-объектов, и в принципе можно считать, что в некотором роде задача детекции объектов на изображении достаточно хорошо решена. Если что, мы можем пользоваться этими результатами как какой-то дополнительной информацией.
Но у нашего лидарного облака есть свои особенности, которые сильно отличают его от изображения. Во-первых, оно очень разрежено. Если картинка — это плотная структура, пиксели рядом, все плотно, то облако очень разреженное, точек там не так много, и у него не регулярная структура. Чисто физически там точек вблизи намного больше, чем вдали, и чем дальше, тем меньше точек, тем меньше точность, тем сложнее что-то определять.
Ну и точки в принципе из облака приходят в непонятном порядке. Никто не гарантирует, что одна точка всегда будет раньше другой. Они приходят в относительно случайном порядке. Можно как-то договориться, чтобы их заранее сортировать или переупорядочивать, и только тогда подавать на вход модели, но это будет достаточно неудобно, нужно затратить время, чтобы их поменять, и так далее.
Мы бы хотели придумать такую систему, которая будет инвариантна к нашим проблемам, будет все эти проблемы решать. Благо на прошлом CVPR в прошлом году такую систему презентовали. Была такая архитектура — PointNet. Как она работает?
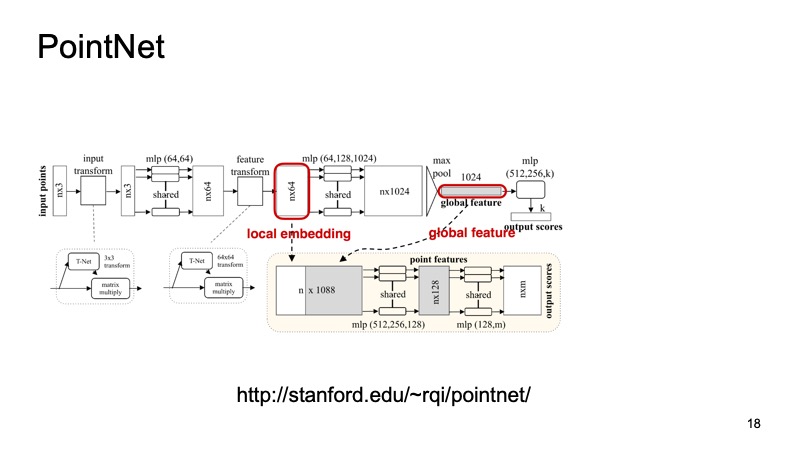
На вход поступает облако, n точек, у каждой три координаты. Потом каждая точка каким-то образом стандартизируется специальным маленьким трансформом. Дальше прогоняется через полносвязную сеть, чтобы эти точки обогатить признаками. Потом опять происходит трансформация, и в конце обогащается дополнительно. В какой-то момент получается n точек, но у каждой примерно по 1024 признака, они как-то стандартизированы. Но пока что мы не решили проблему относительно инвариантности сдвигов, поворотов и так далее. Здесь предлагается сделать max-pooling, взять по каждому каналу максимум среди точек и получить какой-то вектор из 1024 признаков, который будет являться некоторым дескриптором нашего облака, который будет сжато содержаться информацию обо всем облаке. А дальше с этим дескриптором можно делать много разных вещей.
Ссылка со слайда
Например, можно подклеивать его к дескрипторам отдельных точек и решать задачу сегментации, для каждой точки определять, к какому объекту она принадлежит. Это просто дорога или человек, или машина. И тут представлены результаты из статьи.
Ссылка со слайда
Можно заметить, что этот алгоритм очень хорошо справляется. В частности, мне очень нравится тот столик, в котором часть данных о столешнице выкинули, и он, тем не менее, определил, где ножки и где столешница. И этот алгоритм, в частности, можно использовать как кирпичик для построения дальнейших систем.
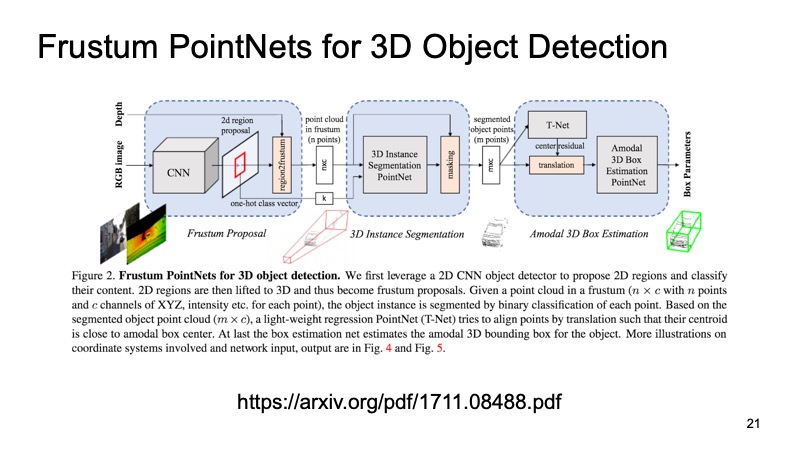
Одним из подходов, которые это используют, является подход Frustum PointNets или подход с усеченной пирамидой. Идея примерно такая: давайте распознаем объекты в 2D, это мы хорошо умеем делать.
Потом, зная, как работает камера, мы можем прикинуть, в какой области может лежать интересующий нас объект, машина. Спроецировать, вырезать только эту область, и уже на ней решать задачу поиска интересного объекта, например, машины. Это намного проще, чем искать какое угодно количество машин по всему облаку. Искать одну машину ровно в одном облаке, кажется, намного понятнее и эффективнее.
Ссылка со слайда
Архитектура выглядит примерно так. Сначала мы как-то выделяем регионы, которые нас интересуют, в каждом регионе делаем сегментацию, а потом решаем задачу нахождения bounding box, который ограничивает интересующий нас объект.
Подход себя зарекомендовал. На картинках можно заметить, что он достаточно хорошо работает, но в нем есть и недостатки. Подход двухуровневый, из-за этого он может быть медленным. Нам нужно сначала применить сети и распознать 2D-объекты, потом вырезать, а потом уже решить на кусочке облака задачу сегментации и выделения bounding box, поэтому он может работать немного медленно. Другой подход. Почему бы нам не превратить наше облако в какую-нибудь структуру, похожую на картинку? Идея такая: давайте посмотрим сверху и дискретизируем наше лидарное облако. Получим кубики пространств.
Ссылка со слайда
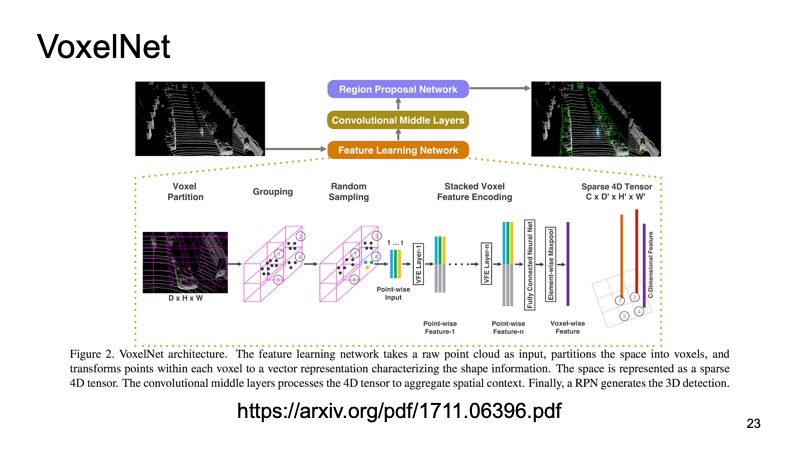
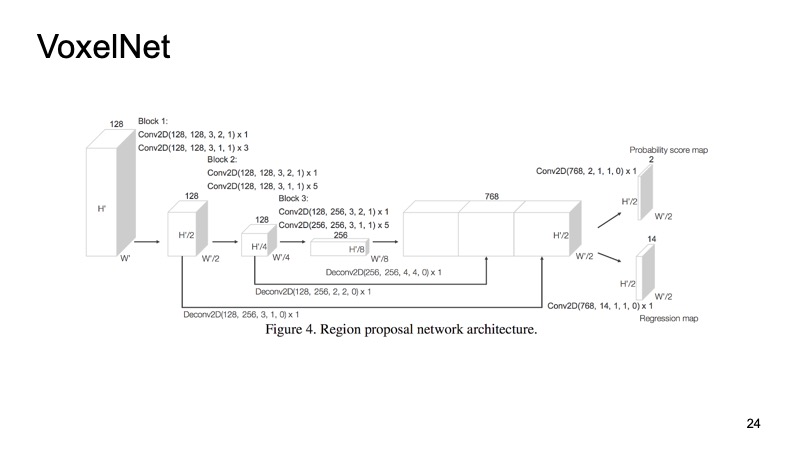
Внутри каждого кубика к нам попали какие-то точки. Можем какие-то фичи по ним посчитать, а можем применить PointNet, который для каждого кусочка пространства посчитает какой-то дескриптор. У нас получится воксель, у каждого вокселя признаковое описание, и это будет более-менее похоже на плотную структуру, как у картинки. Мы уже сможем делать разные архитектуры, например SSD-подобную архитектуру для детекции объектов.
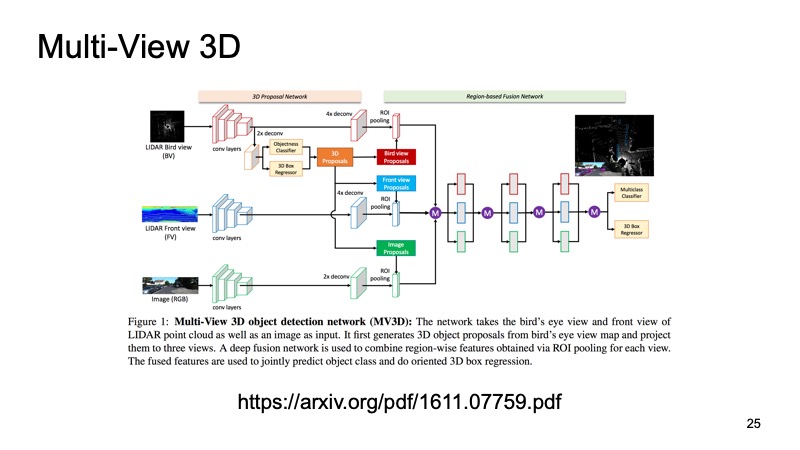
Последний подход, который был одним из самых первых подходов к объединению данных с нескольких сенсоров. Было бы грешно использовать только лидарные данные, когда у нас есть еще и данные с камер. Один из этих подходов называется Multi-View 3D Object Detection Network. Его идея в следующем: подадим на вход большой сети сразу три канала входных данных.
Ссылка со слайда
Это картинка с камеры и, в двух вариантах, лидарное облако: сверху, с bird’s-eye view, и какое-то представление спереди, то, что мы видим впереди себя. Подадим это на вход нейронке, и она сама внутри себя все сконфигурирует, будет выдавать нам конечный результат — объект.
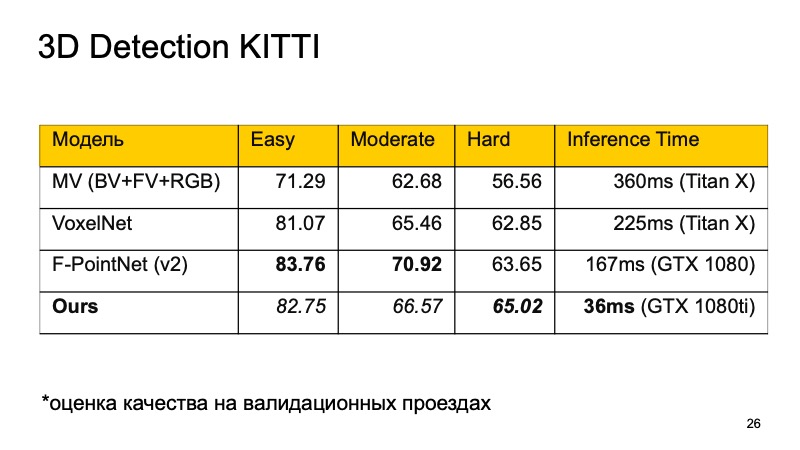
Хочется сравнить эти модели. На датасете KITTI, на валидационных проездах, качество оценивается как проценты в average precision.
Можно заметить, что F-PointNet работает достаточно хорошо и достаточно быстро, выигрывает у всех остальных на разных областях — по крайней мере, по заявлениям авторов. Наш подход основывается на более-менее всех идеях, что я перечислил. Если сравнивать, получается примерно следующая картинка. Если мы не первое место занимаем, то как минимум второе. Причем на тех объектах, которые детектить достаточно сложно, мы вырываемся в лидеры. И что самое главное, наш подход работает достаточно быстро. Это означает, что он уже достаточно хорошо применим для realtime-систем, а ведь беспилотному автомобилю особенно важно мониторить, что же происходит на дороге, и выделять все эти объекты.
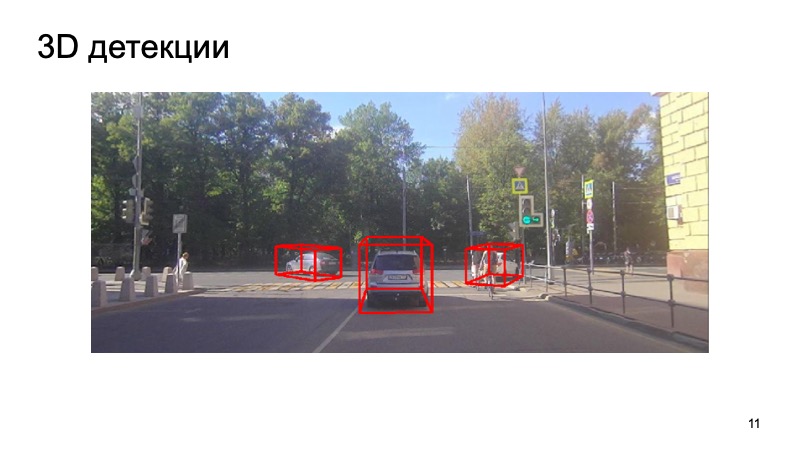
В завершение — пример работы нашего детектора:
Видно, что ситуация сложная: часть объектов закрыты, часть — не видны камере. Пешеходы, велосипедисты. Но детектор достаточно хорошо справляется. Спасибо!