Байесовский подход
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2019-01-11 20:02
В этом посте расскажем о формуле Байеса и её применении в машинном обучении. С этого года я буду читать много всяких новых курсов, в том числе, потоковый курс по «Машинному обучению и анализу данных» на факультете ВМК МГУ. Поэтому сейчас пребываю в поисках правильных формы/объёма/манеры подачи материала (чтобы не сильно лезть в теорию, но дать представление, зачем теория нужна). Постарался сделать максимально доступно, но предварительные знания по терверу нужны…

Формула Байеса хорошо известна из курса теории вероятностей и математической статистики и позволяет пересчитывать условную вероятность (или плотность) P(A|B) через P(B|A), см. рис. 1.

Рис. 1. Формула Байеса.
Прежде чем читать дальше полезно посмотреть этот небольшой пост, содержащий решение задачи «Тест на болезнь «зеленуху» имеет вероятность ошибки 0.1 (как позитивной, так и негативной), зеленухой болеет 10% населения. Какая вероятность того, что человек болен зеленухой, если у него позитивный результат теста (т.е. тест говорит «болен»)?» (а лучше попробовать самостоятельно решить эту задачу и потом проверить себя).
Кстати, задача решается очень просто графически, на рис. 2 показано множество всех людей в виде квадрата: левая часть (90%) — здоровые, правая часть (10%) — больные. Верхняя часть (90%) — те, у кого тест показывает верный результат, нижняя часть (10%) — те, у кого тест обманывает.
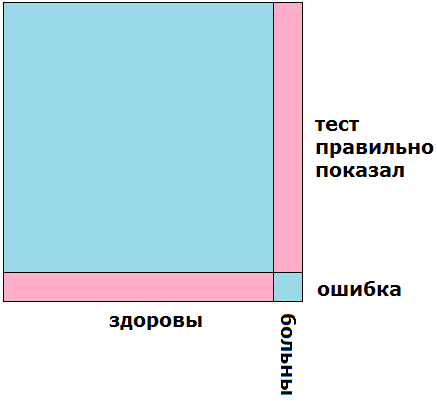
Рис. 2. Графическое решение задачи о зеленухе.
Розовым цветом выделено множество людей, у которых тест показывает «болен»: это больные с правильными показаниями и здоровые с ошибочными. Теперь видно, что эти две розовые группы «одного объёма». Поэтому, если тест показывает «болен», то с вероятностью 0.5 человек болен и тест верен, а с вероятностью 0.5 он здоров и тест ошибается.
Как видите, очень простое графическое решение — без всяких формул. На самом деле, почти все задачи в теории вероятностей можно решать вот так — на картинках, поскольку теория вероятностей — это часть теории меры, т.е. о том, как измерять «объём» множества, и если это множество умело изобразить, то и ответ будет понятен.
Оптимальное решение задач классификации
Предположим, что в задаче классификации на K классов мы знаем такие вероятности
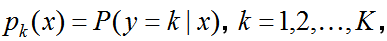
— вероятности принадлежности к классам (conditional class probabilities), т.е. вероятности того, что объект принадлежит классу k при условии, что его признаковое описание x. Тогда очевидно, что для решения задачи классификации надо просто выбрать максимальную вероятность! Именно это и делает байесовский классификатор. Кстати, P может быть и плотностью (для них всё аналогично и даже формула Байеса верна, и дальше мы будем их часто «путать»).
Но как же вычислить указанные вероятности? Давайте воспользуемся формулой Байеса…

искомая вероятность выражается через априорную вероятность (prior probability) класса P(y=k) (смысл очевиден — если дан случайный объект, то с какой вероятностью он принадлежит классу k) и вероятность / плотность (density) распределения объектов класса P(x|y=k).
Смысл P(x|y=k) тоже понятен: если мы будем рассматривать только объекты класса k, то они как-то распределены… дискретное распределение описывается вероятностями, а непрерывное — плотностями. Здесь как раз стоит одна из таких функций, в которую мы подставили x (признаковое описание).
В знаменателе формулы стоит P(x) — это уже вероятность / плотность распределения всех объектов, но, по сути, она нам не очень нужна: выбор максимальной вероятности принадлежности к классам не зависит от этого значения.
Посмотрим на рис. 3 — розовая и синяя линии изображают плотности распределения двух классов в однопризнаковой задаче. Они могут быть заданы изначально, а могут быть восстановлены по данным (возможно, с некоторыми априорными предположениями, например, что данные распределены нормально). Если бы классы были равновероятны, то точки пересечения линий определяли бы «разделяющие поверхности классов» (да, у нас одномерное пространство, поэтому точки тут это «поверхности»).

Рис. 3. Плотности распределения в классах.
Но если классы не равновероятны, то эти самые вероятности классов по формуле Байеса «масштабируют» наши плотности и смещают разделяющие поверхности, см. рис. 4:
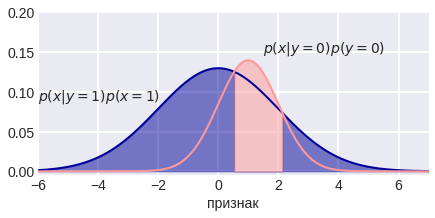
Рис. 4. Разделяющие точки для неравновероятных классов.
Можно подробно рассмотреть случай однопризнаковой задачи бинарной классификации с нормальными распределениями классов:

Здесь знак «<>» означает сравнение с целью определения максимального значения и классификации. В итоге (после логарифмирования) всё свелось к неравенству порядка не выше 2 (старшая степень при x). Если дисперсии распределений обоих классов равны, то для классификации мы будем значение признака просто сравнивать с порогом, что согласуется с рис. 5.

Рис. 5. Разделяющая точка в случае равных дисперсий.
Если дисперсии различны, то обязательно получится неравенство 2го порядка и здесь разделяющая поверхность состоит из 2х точек (см. рис. 4) или ни одной… если неравенство не имеет решения или решение — вся числовая прямая (это соответствует ситуации, когда какой-то класс очень редкий — вероятность принадлежности к нему близка к нулю).
Кстати, если классы равновероятны и нормально распределены с одинаковой дисперсией, то разделяющая поверхность — точка, которая является средним арифметическим матожиданий классов.

Рис. 6. Разделяющая точка в случае равновероятных классов и одинаковых дисперсий.
Аналогично можно рассмотреть двухпризнаковую задачу бинарной классификации. Там разделяющие поверхности не сложнее поверхностей 2-го порядка, т.е. в этом случае байесовский классификатор также разделяет классы достаточно простыми поверхностями.
В различных библиотеках алгоритмов машинного обучения Вы встретите, скорее всего, реализацию наивного байесовского классификатора (naive Bayes). Связано это со сложностью оценки плотностей. Вероятность класса можно оценить пропорцией, в которой представители этого класса есть в обучающей выборке. А вот плотность распределения в классе в многомерном пространстве сложно оценить надёжно из-за проклятия размерности. Поэтому делают сильное предположение, что все признаки независимы, тогда плотность представляется в виде произведения плотностей по отдельным признакам:
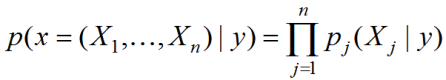
Не смотря на то, что предположение сильное и на практике почти никогда не выполняется (если Вы сами не преобразуете признаки), метод часто работает неплохо… почему? Потому что поиск решения в классе простых решений — хороший способ борьбы с переобучением;)
Метод максимального правдоподобия (MLE)
Прежде чем описывать байесовский подход, вспомним самый популярный метод оценивания параметров в математической статистике — метод максимального правдоподобия. Если есть плотность (вероятность) распределения p(y|?), известная с точностью до параметра ?, то для его оценки надо максимизировать функцию правдоподобия — произведение значений вероятностей в элементах нашей выборки (предполагаем, что они независимые и распределены по p(y|*), * — неизвестное нам истинное значение параметра ?):

Точка, в которой правдоподобие достигает максимального значения называется оценкой максимального правдоподобия (MLE = Maximum Likelihood Estimation). Кстати, будем держать в уме, что параметр ? может быть вектором (т.е. это параметры).

Рис. 7. Оценка максимального правдоподобия.
Приведём в качестве примера проблему нечестной монетки (coin-toss problem). Пусть кто-то бросает монету и мы наблюдаем исходы: 1 — выпал орёл, 0 — выпала решка. Наша задача оценить вероятность выпадения орла. Предполагая, что наблюдаемая случайная величина подчиняется распределению Бернулли, получаем:

Здесь вместо максимизации правдоподобия применили стандартный приём — максимизацию его логарифма. Максимум ищется просто приравниванием к нулю производной (функция вогнута). Я опускаю некоторые довольно простые выкладки. Получили достаточно очевидный ответ: оценка параметра распределения Бернулли (который и является вероятностью выпадения орла) — среднее арифметическое наблюдаемых случайных величин, т.е. доля выпадения орла.
Отметим недостатки полученной оценки:
- ненадёжность при малом числе экспериментов и явная склонность к переобучению (например, если после двух бросков выпали два орла, то мы утверждаем, что вероятность равна 1).
- отсутствие возможности внести некоторую дополнительную информацию (например, до бросков мы знаем, что у этой монеты орёл выпадает чаще)
А теперь подход, который одним махом исправит все эти недостатки;)
Байесовский подход
Перепишем формулу Байеса в терминах задачи моделирования данных и приведём нужные термины:
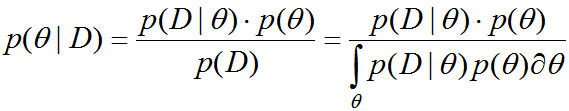
Наша задача найти некоторый параметр ? (параметр(ы) нашей модели), у нас есть априорная плотность распределения (prior) этого параметра p(?) , мы наблюдаем данные D, p(D) — вероятность данных (evidence), как видно выполняет роль нормировки, чтобы слева получалась плотность. p(D|?) — правдоподобие (likehood), p(?|D) — апостериорная плотность распределения (posterior). Для дискретных распределений плотности заменяются вероятностями, а интеграл суммой.
Апостериорная плотность именно то, что нам и нужно после наблюдения данных D. С помощью формулы Байеса мы видим, как наша априорная плотность (до наблюдения данных) превращается в апостериорную. Важно сразу понять, что формулу можно применять итерационно после поступления каждой новой порции данных. Текущее распределение параметра считается априорным, поступили данные — получили апостериорное распределение, потом, при необходимости, оно становится априорным для нового применения формулы.
Посмотрим, что даст применение байесовского подхода в задаче с монеткой… Допустим, у нас нет никаких априорных знаний о монетке, тогда считаем, что априорное распределение параметра равномерное p(?)=1 на отрезке [0, 1]. Напомним, что это параметр распределения Бернулли и одновременно вероятность выпадения орла. Если был произведён ровно один бросок и выпал орёл, то правдоподобие p(y|?) = ?. На рис. 8 показаны априорное распределение, правдоподобие и их произведение, нормированное так, чтобы получилась плотность (площадь под кривой равнялась единице): 1·? / 0.5.
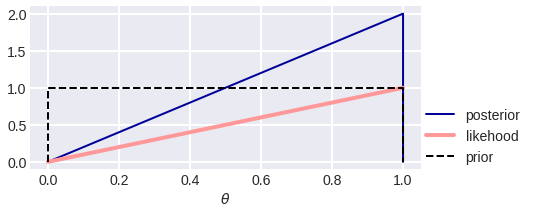
Рис. 8. Превращение априорного распределения в апостериорное после выпадения орла.
Теперь пусть наше априорное распределение это полученное апостериорное p(?) = 2?, т.е. мы верим, что скорее монета выпадает орлом, а не решкой. Пусть опять сделан ровно один бросок и выпала решка, тогда функция правдоподобия p(y|?) = 1-?, после применения формулы Байеса (перемножения и нормировки) получили апостериорную плотность p(?|y) =6?(1-?)

Рис. 9. Превращение априорного распределение в апостериорное после выпадения решки.
Уже видно фундаментальное отличие от MLE, которое является характерным для байесовского подхода. В MLE мы получаем конкретное значение параметра, а здесь — работаем с распределениями и в итоге получаем апостериорное распределение на значение нашего параметра.
Как ответить, какая вероятность выпадения орла? Мы получили целое распределение на возможных значениях этой вероятности. Можно найти моду (точку, в которой она максимальна) — это метод максимизации апостериорной плотности (MAP = Maximum a Posteriori). На рис. 9 это 0.5, что вполне логично после двух бросков и одного выпавшего орла. Давайте прологарифмируем формулу Байеса и запишем задачу максимизации:

(максимизация производится по ?, мы удалили слагаемое, которое от него не зависит).
Видно, что метод MAP максимизирует логарифм правдоподобия (как и MLE) плюс логарифм априорного распределения. Второе слагаемое играет роль своеобразного регуляризатора, которое позволяет не переобучаться (ниже покажем почему).
Задача с монеткой и MAP
Предположим, что априорное распределение на значения оцениваемого параметра распределения Бернулли — бета-распределение:

Если вдруг Вам показалось такое предположение странным и/или Вы вообще до этого не работали с бета-распределением, боитесь гамма-функций (но они тут только для вычислений нормировочных констант), то подождите немного, дальше будет понятно, почему выбрано именно оно. Пока скажем, что это довольно большой класс распределений, на рис. 10 показаны некоторые его представители

Рис. 10. Представители семейства бета-распределений.
Запишем выражение для максимизации методом MAP, возьмём производную и приравняем к нулю:
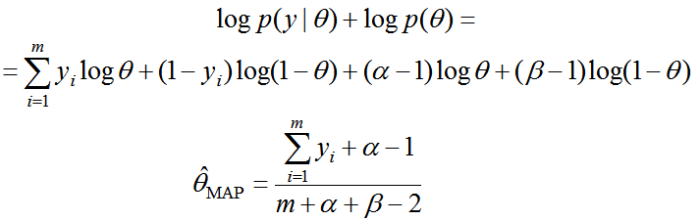
Интересно, что при ?=?=1 оценки MLE и MAP совпадают. Если же ?+?>2 и эти параметры целые, то по-сути они играют роль фиктивных экспериментов в количестве ?+?-2 штук, в которых выпал ?—1 орёл. Теперь оценка параметра будет адекватнее вести себя при малом числе экспериментов! Кстати, такая оценка часто называется сглаживанием Лапласа.
Почему же мы взяли бета-распределение? Всё дело в том, что если функцию правдоподобия для распределения Бернулли умножить на плотность бета-распределения, то мы снова получим бета-распределение:

Таким образом, мы не просто переходим от априорного распределения к апостериорному, а ещё и остаёмся в одном классе распределений! Да и вообще, все формулы красиво аналитически считаются… Распределения, которые не выводят из класса априорного распределения (как здесь Бернулли и бета), называются сопряжёнными.
С помощью бета-распределений удобно формализовать свою веру в то, что вероятность имеет определённое значение. Как мы видели, это вера будет просто эквивалентна серии фиктивных бросков. На рис. 11 показано несколько функций, которые формализуют априорную информацию о том, что ?=2/3.
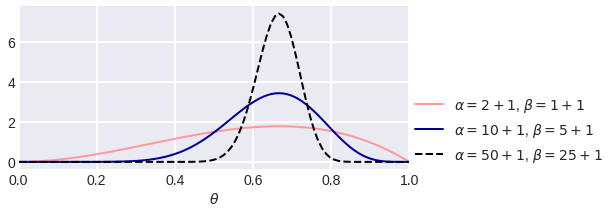
Рис. 11. Представители бета-распределения с центром в точке 2/3.
Обоснование регуляризации
Вспомним статистическую теорию линейной регрессии. Пусть нам известно, что целевая переменная зависит от других линейно с точностью до нормального шума:
Тогда можно искать коэффициенты с помощью MLE:

Задача максимизации логарифма правдоподобия обучающей выборке свелась к минимизации квадратичной ошибки, что, собственно, обосновывает использование этой функции ошибки в задачах регрессии.
Теперь давайте применим байесовский подход. До наблюдения обучающей выборки мы ничего не знаем о нашей модели, но мы можем сформулировать наши пожелания. Например, пусть неизвестные (а, следовательно, случайные) коэффициенты линейной регрессии будут нормально распределены:

Тогда
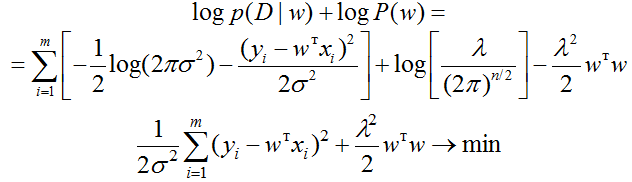
В задаче минимизации мы оставили только слагаемые, которые зависят от w. Здесь легко узнаётся формула, которая используется в ридж-регрессии. Первое слагаемое — квадратичная ошибка, второе — член L2-регуляризации. Как мы и обещали, логарифм априорного распределения играет роль регуляризатора. Таким образом, мы доказали корректность регуляризации (фактически вывели её) в рамках рассматриваемых ограничений.

Рис. 12. Априорные и апостериорные распределения в задаче регрессии.
На рис. 12 показано, как априорная плотность «оттягивает» решение задачи MAP к нулю. MLE получает нерегуляризованное решение. С точки зрения байесовского подхода, регуляризация — априорное распределение параметров.
Отметим, что если бы ошибка была распределена по Лапласу, то мы бы получили L1-регуляризацию. Обычно в ридж-регрессии при регуляризационном члене стоит параметр — коэффициент регуляризации. Здесь он тоже есть, более того, он теперь имеет теоретический смысл: это отношение дисперсий шума и априорного распределения параметров.

Вопрос для проверки понимания: а почему отношение, а не произведение? Аналогично можно было рассмотреть и логистическую регрессию. Там регуляризационный член добавляется к логлоссу.
Итак, байесовский подход теоретически обосновывает регуляризацию (мы привели один пример, но примеров много), придаёт используемым параметрам теоретический смысл.
Байесовский подход к машинному обучению
До сих пор мы говорили о нахождении параметров модели, т.е. фактически о машинном обучении (как известно, сама процедура обучения и есть не что иное, как настройка параметров). Вместо одного значения параметра мы научились находить целое распределение на множестве значений. Что с ним делать дальше, когда потребуется сделать классификацию (или регрессию) новых объектов? Итак, по формуле Байеса, в случае, когда у нас есть обучающая выборка (X, Y), мы получили распределение параметров

Если со штрихами обозначить тестовый объект, то
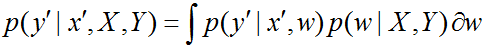
Здесь интегрирование проводится по распределению параметра модели w. Получается своеобразный ансамбль: мы используем модель сразу при всех значениях параметра! Правда, такое интегрирование не всегда удаётся выполнить, поэтому вместо него используют модель с параметром, который получается с помощью MAP-оценки:
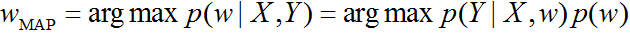
Предположим, что параметр w сам, в свою очередь, зависит от некоторого параметра ?. Тогда надо определить значение ?. Воспользуемся опять формулой Байеса:

Правдоподобие параметра ?
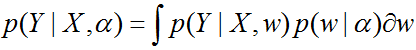
называется обоснованностью (evidence) — интегрированием мы просто исключаем переменную w. Принцип максимальной обоснованности состоит в том, чтобы найти значение параметра

и потом при классификации / регрессии использовать его. Именно так выводится метод Relevance Vector Machine (RVM). Метод похож на SVM, но вместо опорных векторов, которые находятся на границе классов, здесь решение зависит от «релевантных векторов», которые находятся «внутри класса». Часто это преподносится как большой плюс: при моделировании мы смотрим не на пограничные случаи, а на типичные. Желающие могут почитать классическую работу Типпинга (у которой уже почти 1000 цитирований).
Итак, байесовский подход позволяет получать новые методы машинного обучения!
Что такое случайность
В теории вероятностей есть два классических подхода к пониманию того, что такое случайность. Наиболее широко распространённый — частотный подход, который предполагает, что случайность – объективная неопределённость. Поэтому, чтобы установить истину, надо делать эксперименты… в пределе она и устанавливается, подобно тому, как частота выпадения орлов сходится к вероятности. Понятно, что MLE — классический метод частотников.
Второй подход, более распространённый среди специалистов по машинному обучению, — байесовский (Bayesian). Здесь случайность – мера нашего незнания, соответственно, эксперименты просто уменьшают незнание переходом от априорной информации к апостериорной. MAP — пример метода байесианцев. Заметьте, что даже параметры в распределениях здесь случайные (они же неизвестны!).
Второй подход кажется более общим и красивым (мы уже привели значительное число плюсов). Есть правда несколько «но»
- Сама техника и многие результаты байесианцев плохо интерпретируемы для простых смертных. Можно поверить, что объекты как-то распределены (например, клиенты интернет-магазина), но вот поверить, что параметры распределений как-то распределены нормальному человеку сложнее…
- Мы не зря сказали про сопряжённые распределения, если они не сопряжённые, то нет такой красоты и эффектности.
- Утверждается, что байесовский подход работает даже при отсутствии выборки (экспериментов). Но это рекламный слоган, который описывает наличие априорного распределения, но откуда его взять? Часто его выбор просто эвристика, но тогда зачем навешивать эвристику на распределение? Можно сразу на оценку! Скажем, до сглаживания Лапласа догадываются даже те, кто понятия не имеют о байесовском подходе.
- Удобно вносить свои знания с помощью распределения, но мы можем внести и заблуждения…
- Методы вычислительно ресурсоёмкие (но об этом нужно писать подробнее).
- Методы, полученные с помощью байесовского подхода, не так хороши на практике, как многие эвристические (например, я не встречал, чтобы кто-нибудь использовал RVM в проде или на кэгле).
На самом деле, я описал лишь 2/3 того, что хотел… но пост уже получился большим. Дочитал ли кто-нибудь до конца? Все пожелания и замечания оставляйте в комментариях.
Что почитать
- Универсальный совет: читайте Бишопа и будете умными;)
- По вопросам, связанным с байесовским подходом, в России проводится целая научная школа. Доступны материалы прошлого года. Возможно, будут и этого.
- Есть курс, который так и называется «Байесовские методы машинного обучения», разработанный Д. Ветровым и Д. Кропотовым на факультете ВМК МГУ.
- Неплохая лекция Буре В.М., Грауэр Л.В.
П.С. В заключение несколько малоизвестных фактов.
1. Вы, наверное, видели изображение Томаса Байеса, см. рис.12
 Рис. 12. Томас Байес или кто-то ещё…
Рис. 12. Томас Байес или кто-то ещё…
Так вот, точно не известно, кто изображён на этом рисунке. По одной из гипотез — Байес. На самом деле, о его жизни мы знаем очень мало… например, точно не известен год (1701 или 1702) и место рождения (скорее всего, Hertfordshire).
2. Правильно фамилия учёного произносится [бейз], т.е. надо бы говорить «формула Бейза».
3. На википедии написано, что Байес опубликовал две работы. Одна из них «Divine Benevolence, or an Attempt to Prove That the Principal End of the Divine Providence and Government is the Happiness of His Creatures«. На самом деле, автор этой работы Джон Нун. По одной из гипотез — «Нун» это псевдоним Томаса Байеса.
Немного об основной идее этой работы. Это не математическая, а философская статья, в которой рассматривается проблема существования зла: как в мире, который создал Бог (а Бог есть добро), может существовать зло. Если кратко, то ответ прост — дело в нас (людях).
4. В том виде, в котором мы знаем формулу Байеса, её вывел не Байес, а Пьер-Симон Лаплас. Они с Байесом очень не похожи друг на друга. Например, Лаплас был атеистом, а Байес — священником.
5. Термин «байесовский» (Bayesian) впервые применил Рональд Фишер. Но в его лексиконе этот термин был ругательным. Он считал, что теория Байеса «должна быть полностью отвергнута».
Телеграм: t.me/ainewsline
Источник: dyakonov.org