Open source инструмент на Python для выбора признаков нейросети
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-12-11 14:12

Перевод статьи «A Feature Selection Tool for Machine Learning in Python» by William Koehrsen, ссылка на оригинал в подвале статьи.
Разочарованный специальными методами выбора признаков, которые я раз за разом применял для задач машинного обучения, я построил класс для их выбора на Python, код доступен на GitHub. FeatureSelector включает в себя некоторые наиболее распространенные методы отбора, а именно:
- С высоким процентом пропущенных значений;
- Коллинеарные (сильно коррелированные);
- С нулевой важностью в древовидной модели;
- С низкой важностью;
- С единственным уникальным значением.
В этой статье мы рассмотрим работу FeatureSelector. Он позволяет нам быстро внедрять эти методы, обеспечивая более эффективный рабочий процесс. Feature Selector — это незавершенный проект, который будет продолжать улучшаться в зависимости от потребностей сообщества.
Датасет
В этом примере мы будем использовать датасет из соревнования Keggle Home Credit Default Risk machine learning competition. (Информация об этом соревновании приведена здесь). Весь датасет доступен для скачивания, и мы будем использовать его в качестве иллюстративного материала.

На соревновании была предложена задача контролируемой классификации, и это хороший пример датасета, поскольку он имеет множество пропущенных значений, многочисленные коррелированные (коллинеарные) и ряд нерелевантных признаков, которые не помогают модели машинного обучения.
Запуск кода
Чтобы запустить FeatureSelector, нам необходимо передать структурированный датасет с метками в строках и признаками в столбцах. Для некоторых методов нужны только сами признаки, но для анализирующих важность методов также нужны метки. Поскольку рассматривается контролируемая задача классификации, мы будем использовать набор признаков и набор меток.
(Обязательно запустите эти строки в том же каталоге, что и feature_selector.py)
from feature_selector import FeatureSelector
# Features are in train and labels are in train_labels fs = FeatureSelector(data = train, labels = train_labels)
У нас есть пять методов поиска признаков для удаления. Мы можем получить доступ к любому свойству и удалить его из данных вручную или использовать функцию remove в FeatureSelector.
Здесь мы рассмотрим каждый из методов идентификации, а также покажем, как запустить все пять штук сразу. FeatureSelector дополнительно может построить несколько графиков, поскольку визуальный контроль данных является важнейшей частью машинного обучения.
Пропущенные значения
Первый метод удаления является простым: он находит признаки с долей пропущенных значений выше указанного порога. В приведенном ниже примере ищутся признаки с более чем 60% пропущенных значений (жирным приведен результат поиска).
fs.identify_missing(missing_threshold = 0.6)
17 features with greater than 0.60 missing values.
Мы можем увидеть долю пропущенных значений в каждом столбце таблицы:
fs.missing_stats.head()
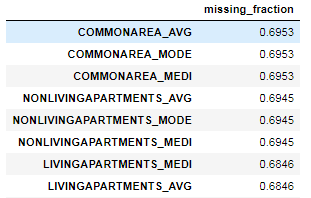
Чтобы увидеть признаки для удаления, мы получаем доступ к атрибуту ops в FeatureSelector:
missing_features = fs.ops['missing'] missing_features[:5]
['OWN_CAR_AGE', 'YEARS_BUILD_AVG', 'COMMONAREA_AVG', 'FLOORSMIN_AVG', 'LIVINGAPARTMENTS_AVG']
Наконец, можно вывести график распределения пропущенных значений во всех признаках:
fs.plot_missing()
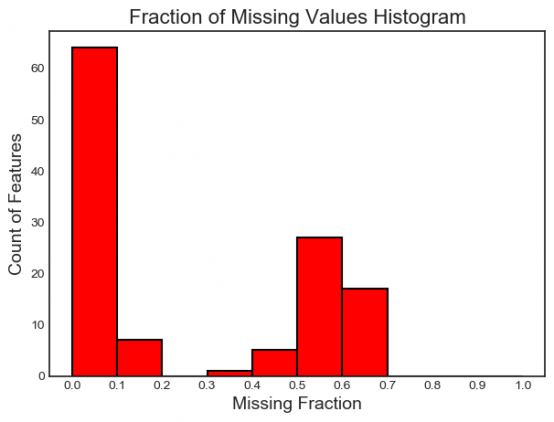
Коллинеарные признаки
Коллинеарные признаки сильно коррелируют друг с другом. В машинном обучении это приводит к снижению эффективности работы из-за высокой дисперсии и меньших возможностей для интерпретации модели.
Метод identify_collinear находит коллинеарные признаки по заданному значению коэффициента корреляции. Для каждой пары коррелированных свойств он выбирает одно их них для удаления (поскольку нам нужно только удалить только одно из двух):
fs.identify_collinear(correlation_threshold = 0.98)
21 features with a correlation magnitude greater than 0.98.
Оптимальная визуализация, которую мы можем сделать с корреляциями, — это тепловая карта. Она показывает все признаки, которые имеют по крайней мере одну корреляцию выше порога:
fs.plot_collinear()
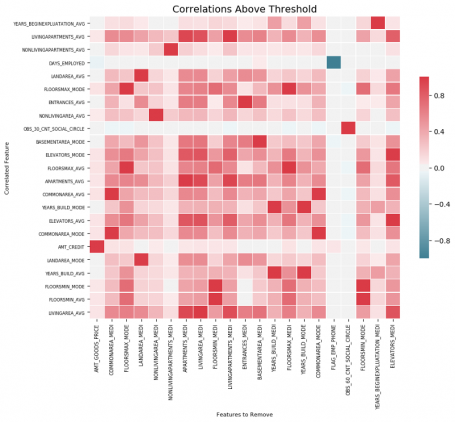
Как и раньше, мы можем получить доступ ко всему списку коррелированных свойств, которые будут удалены, или увидеть высококоррелированные пары свойств в таблице.
# list of collinear features to remove collinear_features = fs.ops['collinear']
# dataframe of collinear features fs.record_collinear.head()

Если мы хотим исследовать наш датасет, мы также можем построить график всех корреляций в данных с помощью команды plot_all = True:
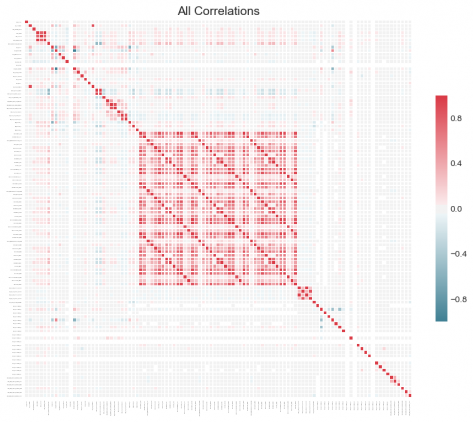
Признаки с нулевой важностью
Предыдущие два метода могут быть применены к любому структурированному датасету, и эти методы детерминированы — результаты будут одинаковыми каждый раз для заданного порога. Следующий метод предназначен только для контролируемых задач машинного обучения, где у нас есть метки для обучения модели и не является детерминированным. Функция ident_zero_importance находит признаки, которые имеют нулевое значение важности в соответствии с моделью обучения GBM.
С помощью древовидных моделей машинного обучения можно вычислить важность признака. Абсолютное значение важности не так важно, как относительные значения, которые мы можем использовать для определения наиболее важных для задачи свойств. Мы также можем использовать эту величину для выбора свойств, которые можно удалить. В древовидной модели признаки с нулевой важностью не используются для разделения любых узлов, поэтому мы можем удалить их, не меняя производительность модели.
FeatureSelector вычисляет важность признаков с помощью Gradient Boosting Maching из библиотеки LightGBM. Важность признака усредняется по 10 циклам GBM, для уменьшения дисперсии. Кроме того, модель обучается с датасетом для проверки и ранней остановкой (эту опцию можно отключить), чтобы предотвратить переобучение.
Приведенный ниже код вызывает метод и ищет признаки с нулевой важностью:
# Pass in the appropriate parameters fs.identify_zero_importance(task = 'classification', eval_metric = 'auc', n_iterations = 10, early_stopping = True)
# list of zero importance features zero_importance_features = fs.ops['zero_importance']
63 features with zero importance after one-hot encoding.
Мы передаем следующие параметры:
- task: либо «классификация», либо «регрессия», в зависимости от вашей задачи;
- eval_metric: показатель, используемый для ранней остановки (не нужно, если ранняя остановка отключена);
- n_iterations: количество циклов обучения;
- early_stopping: использовать или не использовать раннюю остановку для обучения модели.
На этот раз мы получим два графика с помощью команды plot_feature_importances:
# plot the feature importances fs.plot_feature_importances(threshold = 0.99, plot_n = 12)
124 features required for 0.99 of cumulative importance
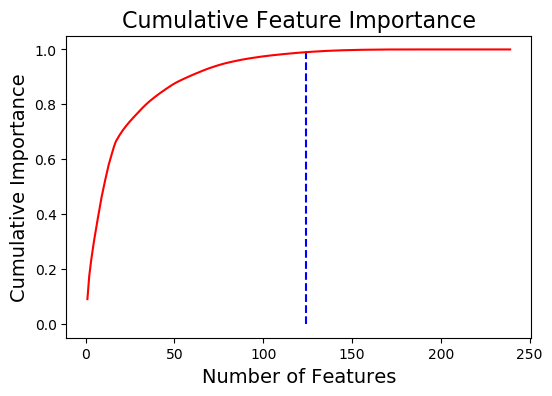
Два важных замечания касательно метрики важности:
- Обучение GBM является стохастическим, важность свойств будет разной при каждом запуске модели.
Это не должно оказать большое влияние (самые важные признаки не перестанут быть таковыми), но изменит порядок расположения некоторых признаков. Это также может повлиять на количество признаков с нулевой важностью. Не удивляйтесь, что значения характеристик меняются каждый раз!
- Для обучения модели машинного обучения происходит прямое кодирование признаков. Это означает, что некоторые признаки с нулевой важностью могут быть напрямую закодированными признаками, добавленными в ходе моделирования.
Возможность удалить любые напрямую закодированные признаки есть. Однако, если мы будем заниматься машинным обучением после выбора признаков, нам все равно придется проводить прямое кодирование признаков!
Признаки с низкой важностью
Метод identify_low_importance ищет признаки с наименьшей важностью, которые не играют важную роль в обучении модели.
Например, приведенный ниже код выводит признаки с важностью менее 99%:
fs.identify_low_importance(cumulative_importance = 0.99)
123 features required for cumulative importance of 0.99 after one hot encoding. 116 features do not contribute to cumulative importance of 0.99.
Основываясь на графике важности (см. выше) и этой информации, GBM приходит к выводу, что большинство признаков не нужно для обучения. Опять же, результаты этого метода будут меняться при каждом запуске.
Чтобы просмотреть все значения важности, введите:
fs.feature_importances.head(10)
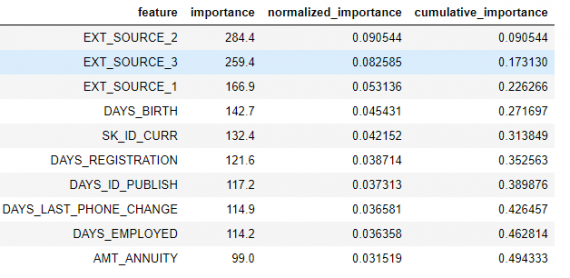
Метод low_importance заимствован из одного из PCA, где обычно остается только PC, необходимый для сохранения определенного процента отклонения (например, 95%). Процент от общей важности учитывается на основе той же идеи.
Методы, основанные на значении важности, действительно применимы только в том случае, если мы собираемся использовать древовидную модель для прогнозирования. Помимо стохастичности, основанные на важности методы используют подход «черного ящика», в котором мы действительно не знаем, почему модель считает какие-то признаки важными. Если вы пользуетесь этими методами, запускайте их по несколько раз, чтобы посмотреть, как меняются результаты. Возможно придется создать несколько датасетов для проверки различных параметров!
Признаки с единственным уникальным значением
Последний метод довольно простой: нужно найти любые столбцы, которые имеют единственное уникальное значение. Признаки с единственным уникальным значением бесполезны для машинного обучения, поскольку они имеют нулевую дисперсию. Например, древовидная модель никогда не может сделать разбиение по признаку только с одним значением.
В этом методе нет параметров для инициализации, в отличие от других методов:
fs.identify_single_unique()
4 features with a single unique value.
Можно построить гистограмму количества уникальных значений в каждой категории:
fs.plot_unique()
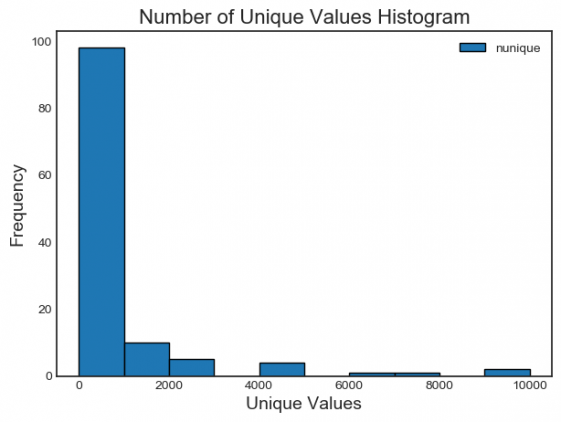
Важный момент — NaN по умолчанию отбрасываются до вычисления уникальных значений в Pandas.
Удаление признаков
Как только мы выбрали признаки для удаления, у нас есть два способа это сделать. Все признаки для удаления хранятся в ops, и мы можем использовать списки для удаления признаков вручную. Другой вариант — использовать встроенную функцию remove.
Если мы хотим удалить все признаки, выбранные пятью методами, нужно ввести methods = ‘all’:
# Remove the features from all methods (returns a df) train_removed = fs.remove(methods = 'all')
['missing', 'single_unique', 'collinear', 'zero_importance', 'low_importance'] methods have been run Removed 140 features.
Этот код возвращает таблицу с удаленными признаками. Чтобы также удалить напрямую закодированные признаки, созданные во время машинного обучения, нужно использовать этот код:
train_removed_all = fs.remove(methods = 'all', keep_one_hot=False)
Removed 187 features including one-hot features.
Возможно, было бы полезно проверить признаки, которые будут удалены, прежде чем продолжить работу! Исходный датасет хранится атрибуте data FeatureSelector в качестве резервной копии!
Одновременный запуск всех методов
Вместо использования методов по отдельности мы можем использовать все из них с identify_all. Для этого нужен набор параметров для каждого метода:
fs.identify_all(selection_params = {'missing_threshold': 0.6, 'correlation_threshold': 0.98, 'task': 'classification', 'eval_metric': 'auc', 'cumulative_importance': 0.99}) 151 total features out of 255 identified for removal after one-hot encoding.
Обратите внимание, что количество признаков изменилось, потому что мы повторно запускаем модель. Для удаления признаков нужно вызвать функцию remove.
Заключение
Класс FeatureSelector реализует несколько общих операций для удаления признаков перед обучением модели машинного обучения. Он содержит функции для идентификации признаков для удаления, а также для визуализации. Методы могут выполняться индивидуально или сразу для эффективной работы.
Методы missing, collinear и single_unique детерминированы, в то время как методы, основанные на значении важности, будут меняться при каждом запуске. Выбор признаков, как это часто бывает в машинном обучении, в значительной мере эмпирический и требует тестирования нескольких комбинаций для получения оптимального результате. Лучше всего попробовать несколько конфигураций в схеме модели, и FeatureSelector предлагает быстрый анализ параметров для выбора признаков.
Телеграм: t.me/ainewsline
Источник: neurohive.io