Facebook выложил Wav2Letter++ в открытый доступ
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-12-28 16:30

Команда Facebook AI Research выложила в открытый доступ wav2letter ++ — модель распознавания речи, которая использует только сверточные нейронные сети (CNN). В задаче распознавания речи Wav2letter++ демонстрирует уровень ошибок 4.91-5% , для человека этот показатель составляет 5.83%. Сеть написана на C++.
Современное поколение моделей распознавания речи опирается главным образом на рекуррентные нейронные сети (RNN). Хотя методы, основанные на RNN, доказали свою эффективность в задачах распознавания речи, они требуют больших объемов обучающих данных и вычислительной мощности, что часто недоступно для большинства компаний.
Facebook AI Research опубликовала исследовательскую работу, в которой предлагается новый метод распознавания речи — Wav2letter++, основанный исключительно на сверточных нейронных сетях. CNN также требуют много обучающих данных, но разработчики смогли обойти эту проблему.
Исходный код Wav2letter ++ выложен в открытый доступ «с целью содействия исследованиям end-to-end моделей распознавания речи».
Полностью сверточная архитектура
Команда FAIR решила положиться на архитектуру, которая объединяет различные уровни CNN, обеспечивая полный цикл распознавания речи от обработки поступающей звуковой волны до транскрипции итогового слова. Архитектура модели представлена на рисунке ниже.
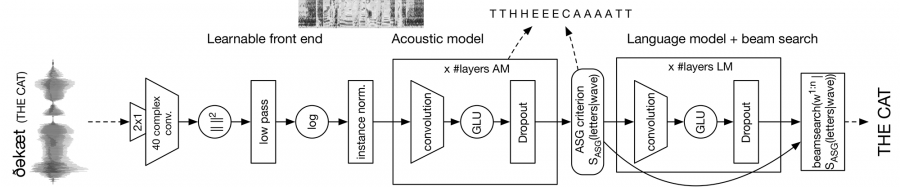
- Сначала сеть обрабатывает исходный аудиопоток и извлекает его ключевые особенности.
- За этим слоем следует сверточная акустическая модель, которая прогнозирует буквы.
- Затем применяется внешняя языковая модель для определения слов и создания итоговой транскрипции.
- После чего декодер генерирует последовательности слов с учетом выходных данных акустической модели.
Модель распознавания речи достигла сопоставимой производительности с другими современными моделями при значительно меньшем количестве обучающих данных. Разработчики FAIR решили открыть исходный код для первоначальной реализации этого подхода.
Wav2letter ++
Инструментарий wave2letter ++ построен на Flashlight. Кроме того, он также написан на C++ с ArrayFire в качестве тензорной библиотеки. ArrayFire позволяет проводить высокопроизводительные параллельные вычисления в аппаратно-независимой модели, которая может выполняться на нескольких внутренних процессорах, включая серверную часть CUDA GPU и серверную часть процессора.
Wav2letter ++ включает в себя разные end-to-end модели, сетевые архитектуры и функции активации.
Результаты
Команда FAIR провела сравнение Wav2letter ++ с рядом современных моделей распознавания речи, таких как ESPNet, Kaldi и OpenSeq2Seq. Эксперименты были основаны на наборе данных Wall Street Journal CSR. Первоначальные результаты показали, что Wav2letter ++ превосходит другие модели в скорости в каждом аспекте:
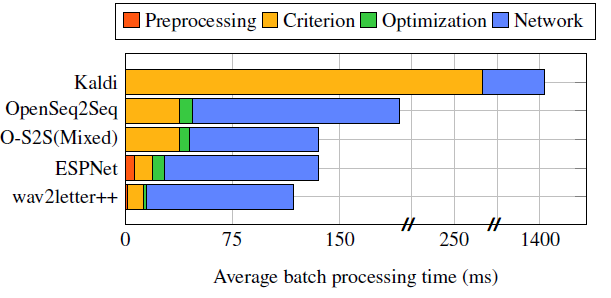
Скорость декодирования Wav2letter++ опережает реализации OpenSeq2Seq и ESPNet при сопоставимом или меньшем уровне ошибок. На тестовом наборе LibriSpeech система демонстрирует уровень ошибок 4.91-5% , в то время как для человека этот показатель составляет 5.83%.
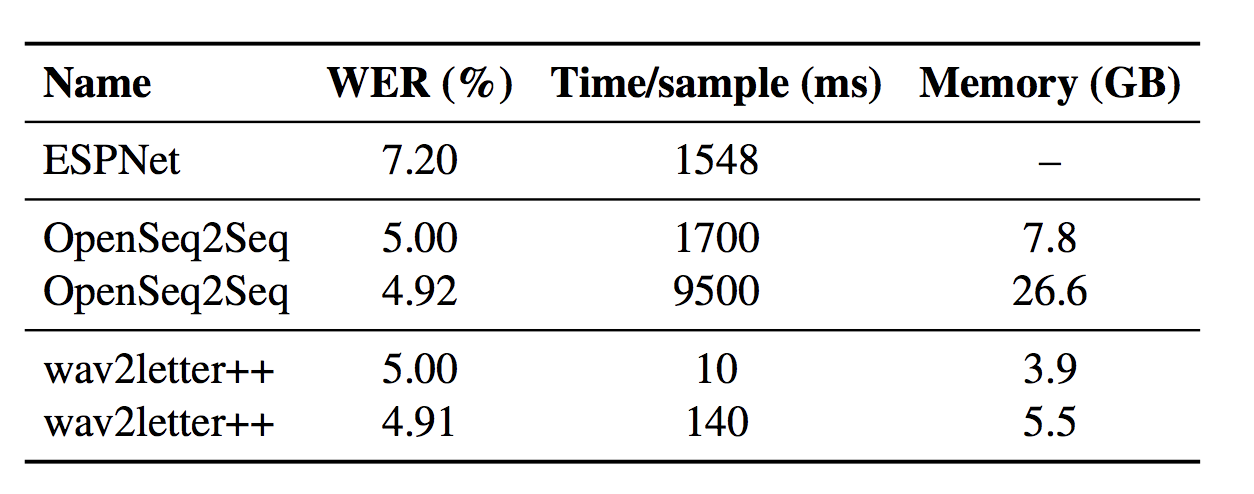
Внедрение систем распознавания речи, полностью основанных на CNN, представляет собой перспективный подход, который оптимизирует вычислительную мощность и менее требователен к данным для обучения.
Телеграм: t.me/ainewsline
Источник: neurohive.io