4 концепта, необходимые специалисту по машинному обучению
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-12-09 09:00

Несколько полезных концептов, которые нужно изучить начинающему и не очень специалисту по машинному обучению и нейронным сетям.
Предположим, вы пытаетесь что-то вспомнить, например, сколько синих зонтиков вы видели в своей жизни. Recall определяет, сколько раз вы смогли запомнить эту ситуацию. Например, вы решили, что видели такие зонтики 10 раз (а на самом деле всего 8, остальные 2 случая вы перепутали), тогда, получается, что вы вспомнили про все ситуации, которые с вами случались, и recall равен 100%.
Идём дальше. Precision же помогает определить, сколько ситуаций вы определили правильно. В странном примере выше из 10 воспоминаний только 8 были правильными. Поэтому ваша точность составляет около 80%.
Итак, что важнее? Ну, это зависит от целей. Если вы используете технологии машинного обучения для того, чтобы идентифицировать рак по фотографиям родинок, вполне разумно как можно меньше говорить пациентам о том, что у них рак (потому что вероятность ошибки довольно высока).
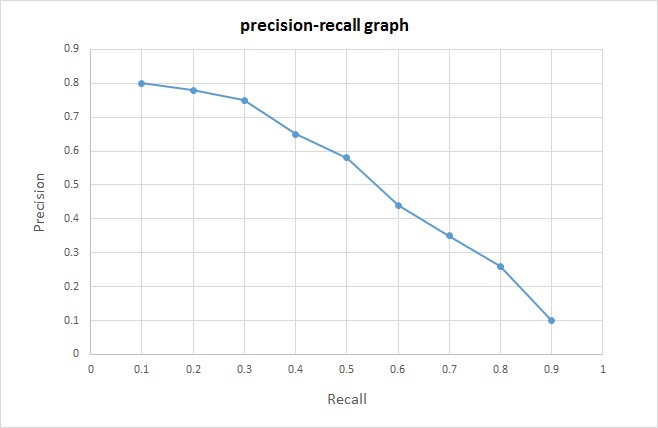
Дело в том, что эти две функции не могут работать одновременно, должен быть компромисс: либо всё будет крайне радужно, либо обманчиво. Звучит довольно сложно, но при решении конкретной задачи определить, что использовать, будет проще.
Применение машинного обучения позволяет например, распознавать (detection) лица на фотографиях или обнаруживать (recognition) логотипы брендов. Но в чем разница между этими двумя функциями?

Объясним на примерах. Face Recognition ? модель машинного обучения распознает человека и сообщает его имя. Face Detection ? модель обозначает границы лица, таким образом говоря, где именно на изображении находится лицо (но не имя человека).
Image Recognition ? на входе само изображение, а на выходе ? определённые характеристики в виде хештегов. Например, #туман или #пейзаж. Object Detection ? модель получает изображение и определяет область, в которой расположен объект.
Многие из вещей, реализованных с помощью машинного обучения, на самом деле являются классификаторами. Например, является ли статья уткой, лист дуба ? листом клёна и так далее.
Вы обучаете модели машинного обучения так, чтобы входные данные определялись в какой-то класс. Опять же, фотография может быть определена в класс «Природа» или «Пейзаж». Чтобы это нормально работало, нужно соблюдать некоторые правила:
- Между количеством изображений должен быть баланс. Если у вас 50 фотографий кошек и 100 фотографий собак, то модель будет обучена неверно и станет более предвзятой по отношению к классу с большим количеством изображений-примеров.
- Модель не будет искать ошибки в ваших примерах, поэтому сделайте так, чтобы фотографии кошек лежали в отдельной папке, а не смешались с другими.

Глубокое обучение ? звучит потрясающе, не так ли? Большинство моделей глубокого обучения основаны на искусственных нейронных сетях. Нейронная сеть является слоем на слоях узлов, которые каким-то образом соединяются друг с другом. Когда у вас более 1 слоя между слоями ввода и вывода, есть глубокая сеть! Когда вы тренируете сеть, она сама определяет, как организовать себя, чтобы распознавать лица (например) и критерии тоже придумывает сама.
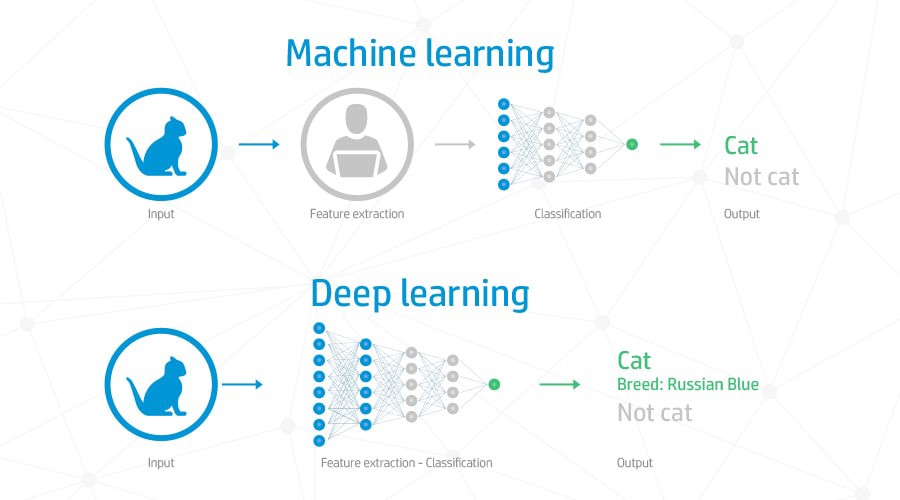
Но это ещё не все. Выполнение подобных операций нагружает графические процессоры. Это значит, что там где можно без этого обойтись, лучше не тратить лишние ресурсы, а найти более дешевый в плане реализации способ.
Понравилась статья о концептах, необходимых специалисту по машинному обучению? Похожие материалы:
Источник: Что стоит знать специалисту по машинному обучению on Towardscience
Телеграм: t.me/ainewsline
Источник: proglib.io