Владимир Иванов vivanov879, Sr. Deep Learning Engineer в NVIDIA, продолжает рассказывать про обучение с подкреплением. В этой статье речь пойдет про обучение агента для прохождения квестов и о том, как нейросети используют фильтры для распознавания изображений.
В предыдущей статье разбиралось обучение агента для простых стрелялок. Про применение обучения с подкреплением на практике Владимир будет рассказывать на AI Conference 22 ноября. В предыдущий раз мы разбирали примеры видеоигр, где обучение с подкреплением помогает решить поставленную задачу. Любопытно, что для успешной игры нейронной сети понадобилась только визуальная информация. Каждый четвертый фрейм нейронная сеть анализирует снимок экрана и принимает решение.
На первый взгляд, это похоже на волшебство. Некая сложная структура, которую собой представляет нейросеть, получает на вход картинку и выдает правильное решение. Давайте разберемся поэтапно, что происходит внутри: что превращает набор пикселей в действие?
Перед тем как перейти к компьютеру, давайте разберемся, что видит человек.
Когда человек смотрит на изображение, его взгляд цепляется как за мелкие детали (лица, фигуры людей, деревья), так и за картину в целом. Будь то детская игра на аллее или футбольный матч, человеку на основании его жизненного опыта удается понять содержание картины, настроение и контекст сделанного снимка.
Когда мы любуемся работой мастера в картинной галерее, наш жизненный опыт все равно подсказывает нам, что за слоями красок кроются персонажи. Можно угадать их намерения и движение в картине. В случае абстрактной живописи взгляд находит на изображении простые фигуры: круги, треугольники, квадраты. Их найти значительно проще. Порой это все, что удается разглядеть. Предметы можно расположить так, чтобы картина приобрела неожиданный оттенок.
То есть мы можем воспринимать картину в целом, абстрагируясь от конкретных ее составляющих. В отличие от нас, компьютер изначально не обладает такой возможностью. У нас есть богатый жизненный опыт, который подсказывает нам, какие предметы важны и какие у них есть физические свойства. Давайте подумаем, каким бы инструментом наделить машину, чтобы она могла изучать изображения. Многие счастливые обладатели телефонов с качественными камерами перед тем как выложить фотографию с телефона в социальную сеть накладывают на нее различные фильтры. С помощью фильтра можно поменять настроение фотографии. Можно выделить какие-то предметы более отчетливо.
Кроме того, фильтр может выделить края предметов на фотографии.
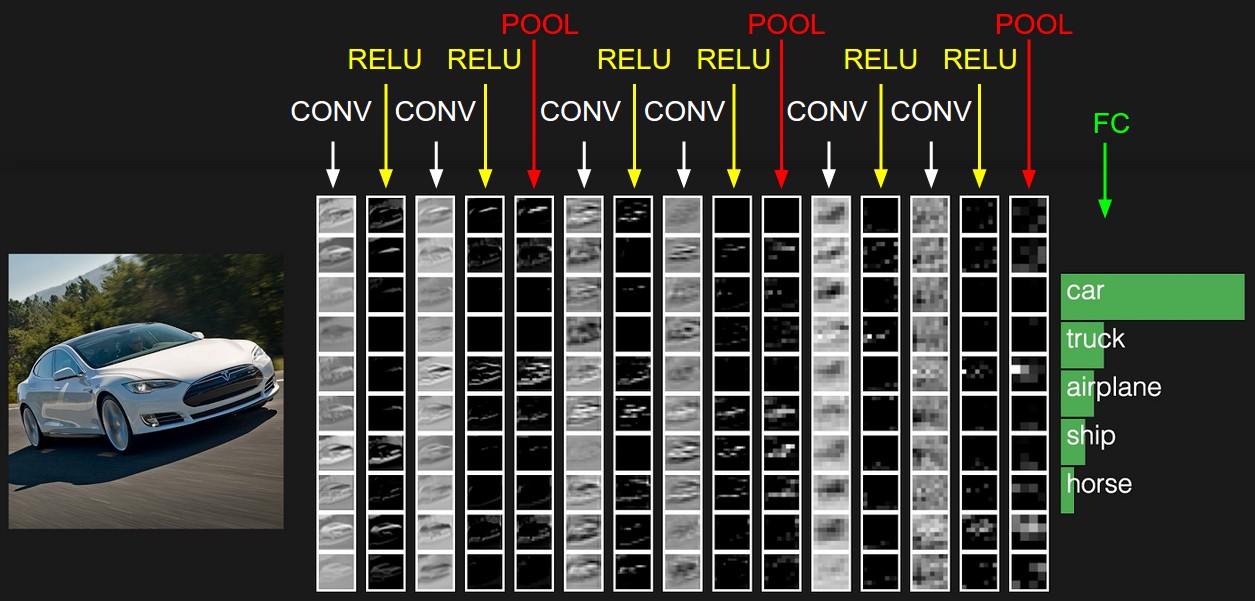
Раз фильтры обладают такой способностью подсвечивать на изображении разные объекты, давайте дадим компьютеру возможность самому подобрать их. Что собой представляет изображение в цифровом виде? Это квадратная матрица чисел, в каждой точке которой расположены значения интенсивности для трех каналов цветов: красного, зеленого и синего. Теперь дадим нейронной сети в распоряжение, например, 32 фильтра. Каждый фильтр по очереди наложим на изображение. Ядро фильтра применяется к соседним пикселям.
Изначально значения ядра каждого фильтра выберем случайными. Но дадим нейросети возможность их настраивать в зависимости от задачи. После первого слоя с фильтрами мы можем поставить еще несколько. Поскольку фильтров получается много, нам нужно много данных, чтобы их настроить. Для этого подойдет какой-нибудь большой банк размеченных картинок. Например, датасет MSCoco. Нейросеть подстроит веса под решение данной задачи. В нашем случае — для сегментации изображения, то есть определения класса каждого пикселя изображения. Теперь давайте посмотрим, как будет выглядеть изображения после каждого слоя фильтров. Если приглядеться, можно заметить, что фильтры в той или иной степени оставляют автомобиль, и убирают окружающую местность — дорогу, деревья и небо. Вернемся к агенту, который учится играть в игры. К примеру, возьмем гоночную игру Mario Kart.
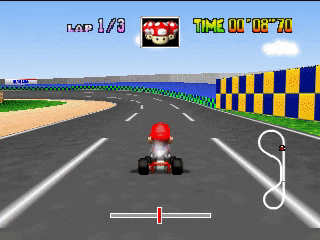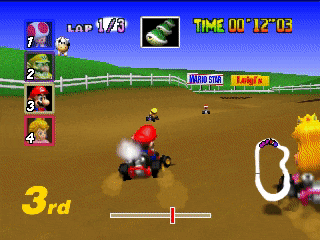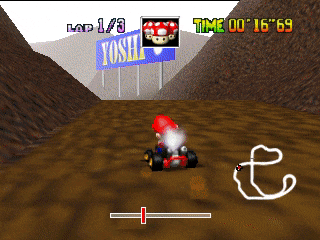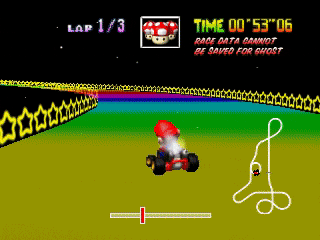
Мы ему дали мощный инструмент анализа изображений — нейронную сеть. Посмотрим, какие он будет подбирать фильтры, чтобы научиться ездить. Возьмем для начала открытую местность.
Посмотрим, как выглядит изображение после первых 24-х фильров. Здесь они расположены в виде таблицы 8х3.
Совершенно необязательно, чтобы каждый из 24-х выходов имел очевидный смысл, ведь картинки идут далее на вход следующим фильтрам. Зависимости могут быть совершенно разные. Тем не менее, в данном случае можно обнаружить некую логику в выходах. Например, второй фильтр в первой строке выделяет дорогу черным. Первый фильтр седьмой строки дублирует его функцию. А на большинстве остальных фильтров отчетливо виден карт, которым мы управляем. В этой игре меняется окружающая местность и встречаются тоннель. На что обращает внимание гоночная нейросеть, когда встречает въезд в тоннель?
Выходы первого слоя фильтров:
В шестой строке первый фильтр выделяет въезд в тоннель. Таким образом, во время езды сеть научилась их определять. А что происходит, когда машинка попадает в тоннель?
Результат действия первых 24-х фильтров:
Несмотря на то, что освещенность сцены поменялась, как и окружение, нейронная сеть выхватывает самое главное — дорогу и карт. Опять же, второй фильтр в первой строке, который отвечал за нахождение пути на открытой местности, в тоннеле сохраняет свои функции. И точно так же первый фильтр седьмой строки, как и раньше, находит дорогу. Теперь, когда мы разобрались, что видит нейронная сеть, давайте попробуем этим воспользоваться для решения более сложных задач. До этого мы рассматривали задачи, где практически не нужно думать наперед, а нужно решать задачу, которая стоит перед нами прямо сейчас. В стрелялках и гонках нужно действовать “рефлекторно”, быстро реагируя на резкие изменения в игре. А как насчет прохождения игры-квеста? Например, игры Montezuma Revenge, в которой необходимо отыскать ключи и открыть запертые двери, чтобы выбраться из пирамиды. В предыдущий раз мы обсуждали, что агент не выучится искать новые ключи и двери, поскольку эти действия занимают много игрового времени, и поэтому сигнал в виде полученных очков будет очень редок. Если же использовать очки за побитых врагов в качестве награды агенту, он так и будет постоянно выбивать катающиеся черепа и не станет искать новые ходы. Давайте вознаграждать агента за открытые новые комнаты. Воспользуемся априори известным фактом, что это квест, и все комнаты в нем разные. Поэтому, если картинка на экране в корне не похожа на то что мы видели раньше, агент получает вознаграждение. До этого мы рассматривали игровых агентов, которые опираются исключительно на визуальные данные во время обучения. Но если у нас есть доступ к другим данным из игры, будем пользоваться ими тоже. Рассмотрим, к примеру, игру Дота. Здесь на вход сеть получает двадцать тысяч чисел, которые полностью описывают состояние игры. Например, положение союзников, здоровье башен. Игроки делятся на две команды, по пять человек в каждой. Игра длится в среднем 40 минут. Каждый игрок выбирает героя с уникальными способностями. И каждый игрок может купить предметы, которые изменяют параметры урона, скорости и поля видимости. Несмотря на то, что игра на первый взгляд значительно отличается от Doom, процесс обучения остается таким же. За исключением нескольких моментов. Поскольку горизонт планирования в данной игре выше, чем в Doom, будем обрабатывать последние 16 кадров для принятия решений. И сигнал наград, который получает агент, будет несколько сложнее. Он включает в себя количество поверженных врагов, нанесенного урона, а также заработанные в игре деньги. Для того, чтобы нейросети играли сообща, включим в награду благополучие участников команды агента. В результате команда ботов обыгрывает достаточно сильные команды людей, но проигрывает чемпионам. Причина поражения состоит в том, что боты редко играли матчи длиной в час. А игры с настоящими людьми затянулись дольше тех, что играли на симуляторах. То есть, если агент оказывается в ситуации, к которой он не тренировался, у него начинают возникать сложности.