PyTorch RNN: Определяем язык по фамилии человека
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-11-14 02:24

В данном руководстве, мы построим Рекуррентную Нейронную Сеть (Recurrent Neural Network, далее — RNN) в PyTorch, которая будет классифицировать имена людей по их языкам. Предположим, что у читателя есть основы понимания PyTorch и машинного обучения в Python.
В конце данного руководства, мы сможем предугадывать язык на котором разговаривает человек по его имени.
Набор данных имён, приведенный в данном руководстве можно скачать здесь: data.zip
Это руководство — адаптация официальной документации PyTorch. Вы можете узнать больше из документации.
Установка PyTorch
Заходим на сайт: https://pytorch.org/
На сайте будет вот такая форма, где вы сможете выбрать свою операционную систему, менеджер пакетов, версия Python (Есть даже для самого нового Python 3.7) и версия CUDA (можно выбрать None если он не установлен). В зависимости от вашего выбора, вы получите инструкцию по установке.
Предварительная обработка данных
Как и в случае с любой другой задачей для машинного обучения, мы начнем с загрузки и подготовки нашего набора данных. После загрузки набора данных, обратите внимание на то, что в папке с данными есть папка под названием names. Она содержит текстовые файлы с фамилиями на восемнадцати разных именах.
Чтобы загрузить все файлы одним махом, мы используем модуль Python под названием glob. Модуль glob находит все совпадения названий путей по особому шаблону, в соответствии с правилами, используемыми в оболочке Unix. Результаты возвращаются в произвольном порядке. Мы используем его для загрузки всех файлов с окончанием .txt в папку.
Python
| 1 2 3 4 | importglob all_text_files=glob.glob('data/names/*.txt') print(all_text_files) |

В данный момент, названия находятся в формате Unicode. Однако, нам нужно конвертировать их в стандарт ASCII. Это поможет с удалением диакритиков в словах. Например, французское имя B?ringer будет конвертировано в Beringer.
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | importunicodedata importstring all_letters=string.ascii_letters+" .,;'" n_letters=len(all_letters) defunicode_to_ascii(s): return''.join( cforcinunicodedata.normalize('NFD',s) ifunicodedata.category(c)!='Mn' andcinall_letters ) print(unicode_to_ascii('B?ringer')) |
Следующий шаг — создание словаря со списком имен для каждого языка.
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | category_languages={} all_categories=[] defreadLines(filename): lines=open(filename).read().strip().split(' ') return[unicode_to_ascii(line)forline inlines] forfilename inall_text_files: category=filename.split('/')[-1].split('.')[0] all_categories.append(category) languages=readLines(filename) category_languages[category]=languages no_of_languages=len(all_categories) print('There are {} langauages'.format(no_of_languages)) |
Мы можем ознакомиться с первыми 15 именами во французском словаре, как показано ниже.

Превращение имен в тензоры PyTorch
Работая с данными в PyTorch, нам нужно конвертировать их в тензоры PyTorch. Это очень похоже на массивы NumPy. В нашем случае, нам нужно конвертировать каждую букву в тензор torch. Это будет один вектор, наполненный нулями, за исключением единицы в индексе текущей буквы. Посмотрим, как это работает, и затем конвертируем M в один вектор.
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | importtorch importstring all_letters=string.ascii_letters+" .,;'" n_letters=len(all_letters) defletter_to_tensor(letter): tensor=torch.zeros(1,n_letters) letter_index=all_letters.find(letter) tensor[0][letter_index]=1 returntensor defline_to_tensor(line): tensor=torch.zeros(len(line),1,n_letters) forli,letter inenumerate(line): letter_index=all_letters.find(letter) tensor[li][0][letter_index]=1 returntensor |
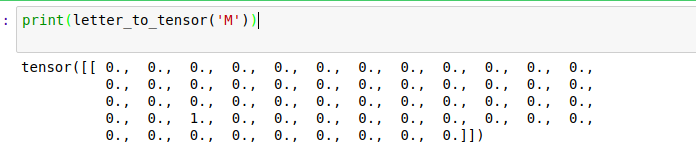
Чтобы сформировать одно имя, нам нужно соединить несколько векторов, чтобы создать двухмерную матрицу.
Создание RNN
При создании нейронной сети в PyTorch, мы используем torch.nn.Module, который является основным классом для всех модулей нейронных сетей. В то же время, torch.autograd предоставляет классы и функции, реализующие автоматическое дифференцирование произвольных скалярных функций. И torch.nn.LogSoftmax применяет функцию Log(Softmax(x)) к n-мерному тензору ввода.
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | importtorch importtorch.nn asnn fromtorch.autograd importVariable importunicodedata importstring importglob all_letters=string.ascii_letters+" .,;'" n_letters=len(all_letters) defunicode_to_ascii(s): return''.join( cforcinunicodedata.normalize('NFD',s) ifunicodedata.category(c)!='Mn' andcinall_letters ) defletter_to_tensor(letter): tensor=torch.zeros(1,n_letters) letter_index=all_letters.find(letter) tensor[0][letter_index]=1 returntensor defline_to_tensor(line): tensor=torch.zeros(len(line),1,n_letters) forli,letter inenumerate(line): letter_index=all_letters.find(letter) tensor[li][0][letter_index]=1 returntensor classRNN(nn.Module): def__init__(self,input_size,hidden_size,output_size): super(RNN,self).__init__() self.input_size=input_size self.hidden_size=hidden_size self.output_size=output_size self.i2h=nn.Linear(input_size+hidden_size,hidden_size) self.i2o=nn.Linear(input_size+hidden_size,output_size) self.softmax=nn.LogSoftmax() defforward(self,input,hidden): combined=torch.cat((input,hidden),1) hidden=self.i2h(combined) output=self.i2o(combined) output=self.dim=output returnoutput,hidden definit_hidden(self): returnVariable(torch.zeros(1,self.hidden_size)) if__name__=='__main__': category_languages={} all_categories=[] all_text_files=glob.glob('data/names/*.txt') forfilename inall_text_files: category=filename.split('/')[-1].split('.')[0] all_categories.append(category) languages=[unicode_to_ascii(line.strip())forline inopen(filename).readlines()] category_languages[category]=languages no_of_languages=len(all_categories) |
Тестирование RNN
Мы начнем с создания экземпляра класса RNN и передачи необходимых аргументов.
Python
| 1 2 | n_hidden=128 rnn=RNN(n_letters,n_hidden,no_of_languages) |
Мы хотим, чтобы сеть давала нам вероятность каждого языка. Чтобы достичь этого, мы передадим тензор текущей буквы.
Python
| 1 2 3 4 5 6 7 8 9 10 11 | input=Variable(letter_to_tensor('D')) hidden=rnn.init_hidden() output,next_hidden=rnn(input,hidden) print('output.size =',output.size()) input=Variable(line_to_tensor('Derrick')) hidden=Variable(torch.zeros(1,n_hidden)) output,next_hidden=rnn(input[0],hidden) print(output) |
Наш __main__ будет выглядеть так:
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | if__name__=='__main__': category_languages={} all_categories=[] all_text_files=glob.glob('data/names/*.txt') forfilename inall_text_files: category=filename.split('/')[-1].split('.')[0] all_categories.append(category) languages=[unicode_to_ascii(line.strip())forline inopen(filename).readlines()] category_languages[category]=languages no_of_languages=len(all_categories) n_hidden=128 rnn=RNN(n_letters,n_hidden,no_of_languages) input=Variable(letter_to_tensor('D')) hidden=rnn.init_hidden() output,next_hidden=rnn(input,hidden) print('output.size =',output.size()) input=Variable(line_to_tensor('Derrick')) hidden=Variable(torch.zeros(1,n_hidden)) output,next_hidden=rnn(input[0],hidden) print(output) |
Результат работы:
Python
| 1 2 3 4 | output.size=torch.Size([1,18]) tensor([[-0.0286,0.0233,-0.1256,0.0964,-0.0281,-0.0697,-0.0022,0.0985, -0.0928,-0.1271,-0.0176,0.0327,-0.0561,-0.0078,-0.0051,0.0560, -0.0135,-0.0472]],grad_fn=<ThAddmmBackward>) |
Тренировка RNN
Чтобы получить вероятность для каждого языка, мы используем Tensor.topk для получения индекса наибольшего значения.
Python
| 1 2 3 4 5 6 | defcategory_from_output(output): top_n,top_i=output.data.topk(1) category_i=top_i[0][0] returnall_categories[category_i],category_i print(category_from_output(output)) |
Далее, нам нужен быстрый способ получить имя и его выдачу (output). На данный момент у нас такой файл main.py (мы выделили участки кода которые были добавлены):
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 | importtorch importtorch.nn asnn fromtorch.autograd importVariable importunicodedata importstring importglob importrandom all_letters=string.ascii_letters+" .,;'" n_letters=len(all_letters) defunicode_to_ascii(s): return''.join( cforcinunicodedata.normalize('NFD',s) ifunicodedata.category(c)!='Mn' andcinall_letters ) defletter_to_tensor(letter): tensor=torch.zeros(1,n_letters) letter_index=all_letters.find(letter) tensor[0][letter_index]=1 returntensor defline_to_tensor(line): tensor=torch.zeros(len(line),1,n_letters) forli,letter inenumerate(line): letter_index=all_letters.find(letter) tensor[li][0][letter_index]=1 returntensor defcategory_from_output(output): top_n,top_i=output.data.topk(1) category_i=top_i[0][0] returnall_categories[category_i],category_i defrandom_training_pair(): category=random.choice(all_categories) line=random.choice(category_languages[category]) category_tensor=Variable(torch.LongTensor([all_categories.index(category)])) line_tensor=Variable(line_to_tensor(line)) returncategory,line,category_tensor,line_tensor classRNN(nn.Module): def__init__(self,input_size,hidden_size,output_size): super(RNN,self).__init__() self.input_size=input_size self.hidden_size=hidden_size self.output_size=output_size self.i2h=nn.Linear(input_size+hidden_size,hidden_size) self.i2o=nn.Linear(input_size+hidden_size,output_size) self.softmax=nn.LogSoftmax() defforward(self,input,hidden): combined=torch.cat((input,hidden),1) hidden=self.i2h(combined) output=self.i2o(combined) output=self.dim=output returnoutput,hidden definit_hidden(self): returnVariable(torch.zeros(1,self.hidden_size)) if__name__=='__main__': category_languages={} all_categories=[] all_text_files=glob.glob('data/names/*.txt') forfilename inall_text_files: category=filename.split('/')[-1].split('.')[0] all_categories.append(category) languages=[unicode_to_ascii(line.strip())forline inopen(filename).readlines()] category_languages[category]=languages no_of_languages=len(all_categories) n_hidden=128 rnn=RNN(n_letters,n_hidden,no_of_languages) # Тренировка RNN foriinrange(10): category,line,category_tensor,line_tensor=random_training_pair() print('category =',category,'/ line =',line) |
Результат выполнения:
Shell
| 1 2 3 4 5 6 7 8 9 10 | category=Irish/line=John category=German/line=Raske category=German/line=Becke category=Korean/line=Mo category=Spanish/line=Rojo category=Arabic/line=Kanaan category=German/line=Kundert category=Irish/line=Mcguire category=Chinese/line=Duan category=Chinese/line=Chu |
Следующий шаг – определение функции loss и создание оптимизатора, который будет обновлять параметры модели, в соответствии с её градиентами. Мы также устанавливаем скорость обучения нашей модели.
Python
| 1 2 3 4 | criterion=nn.NLLLoss() learning_rate=0.005 optimizer=torch.optim.SGD(rnn.parameters(),lr=learning_rate) |
Мы двигаемся дальше, и определяем функцию, которая будет создавать тензоры ввода и вывода, сравним итоговую выдачу с целевой, и наконец, выполним обратное распространение (back-propagation).
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | deftrain(category_tensor,line_tensor): rnn.zero_grad() hidden=rnn.init_hidden() foriinrange(line_tensor.size()[0]): output,hidden=rnn(line_tensor[i],hidden) loss=criterion(output,category_tensor) loss.backward() optimizer.step() returnoutput,loss.data[0] |
Следующий шаг – это запуск нескольких примеров, используя тренировочную функцию, поскольку мы отслеживаем потери для последующего построения графика.
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | importtime importmath n_epochs=100000 print_every=5000 plot_every=1000 current_loss=0 all_losses=[] deftime_since(since): now=time.time() s=now-since m=math.floor(s/60) s-=m*60 return'%dm %ds'%(m,s) start=time.time() forepoch inrange(1,n_epochs+1): category,line,category_tensor,line_tensor=random_training_pair() output,loss=train(category_tensor,line_tensor) current_loss+=loss ifepoch%print_every==0: guess,guess_i=category_from_output(output) correct='?'ifguess==category else'? (%s)'%category print('%d %d%% (%s) %.4f %s / %s %s'%(epoch,epoch/n_epochs*100,time_since(start),loss,line,guess,correct)) ifepoch%plot_every==0: all_losses.append(current_loss/plot_every) current_loss=0 |
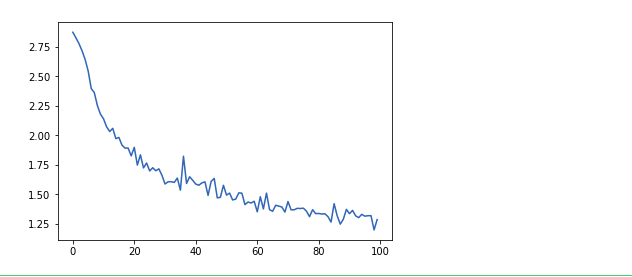
Построение графиков
Мы создаем графики на основе результатов при помощи pyplot от Matplotlib. График покажет нам скорость обучения нашей нейронной сети.
Python
| 1 2 3 4 5 6 7 | importmatplotlib.pyplot asplt importmatplotlib.ticker asticker %matplotlibinline plt.figure() plt.plot(all_losses) |
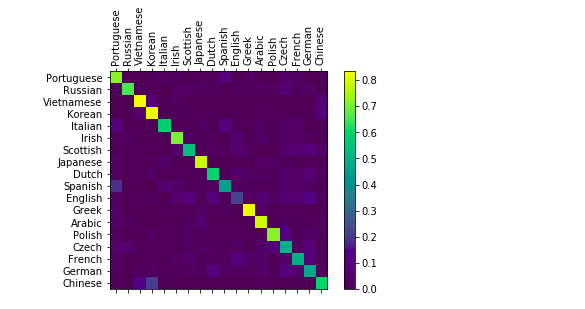
Оценка результатов
Мы создадим запутанную матрицу, чтобы увидеть, как нейронная сеть проявляет себя в разных категориях. Яркие точки на основной оси показывают языки, которые были выбраны неправильно.
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | confusion=torch.zeros(no_of_languages,no_of_languages) n_confusion=10000 defevaluate(line_tensor): hidden=rnn.init_hidden() foriinrange(line_tensor.size()[0]): output,hidden=rnn(line_tensor[i],hidden) returnoutput foriinrange(n_confusion): category,line,category_tensor,line_tensor=random_training_pair() output=evaluate(line_tensor) guess,guess_i=category_from_output(output) category_i=all_categories.index(category) confusion[category_i][guess_i]+=1 foriinrange(no_of_languages): confusion[i]=confusion[i]/confusion[i].sum() fig=plt.figure() ax=fig.add_subplot(111) cax=ax.matshow(confusion.numpy()) fig.colorbar(cax) ax.set_xticklabels(['']+all_categories,rotation=90) ax.set_yticklabels(['']+all_categories) ax.xaxis.set_major_locator(ticker.MultipleLocator(1)) ax.yaxis.set_major_locator(ticker.MultipleLocator(1)) plt.show() |
Угадывание новых имен
Мы определим функцию, которая возьмет имя человека, и вернет языки, которые, скорее всего, родные для этого человека.
Python
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | defpredict(input_line,n_predictions=3): print(' > %s'%input_line) output=evaluate(Variable(line_to_tensor(input_line))) topv,topi=output.data.topk(n_predictions,1,True) predictions=[] foriinrange(n_predictions): value=topv[0][i] category_index=topi[0][i] print('(%.2f) %s'%(value,all_categories[category_index])) predictions.append([value,all_categories[category_index]]) predict('Austin') |

Вывод
Если вы хотите узнать побольше о PyTorch, есть масса руководств в официальной документации. Если вы хотите узнать больше о RNN, Брайан Мванги написал фантастический гайд на эту тему.
Телеграм: t.me/ainewsline
Источник: python-scripts.com