К Как это сделано
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-11-23 10:17
разработка беспилотных автомобилей, системы технического зрения
В прошлом видео был уже готовый результат; а теперь о том, как он был получен.
Процесс называется «сегментация изображения с помощью нейросети».
То есть сначала нужна нейросеть – в данном случае это была сеть SegNet в MATLAB. Потом нужны сами изображения – кадры видеозаписи. Вот один из кадров:

Исходный кадр
Он уже загружен в инструмент Image Labeler для ручной разметки. Нейросеть ведь пока не знает, чего мы от неё хотим. Поэтому дальше нужно вручную указать, где на картинке дорога, где машины, где знаки, люди и так далее. Выглядит это так, как будто маленький ребёнок добрался до Paint'а из Windows 95:
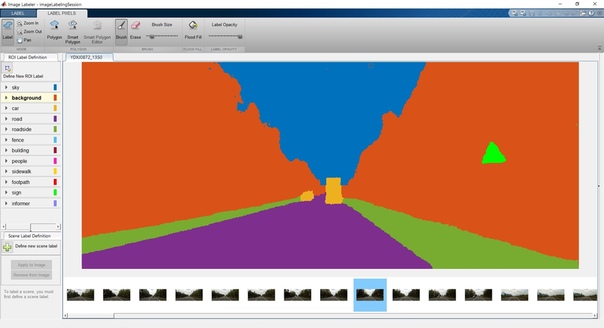
Я умею рисовать!
Но тем не менее это серьёзная работа, при это довольно кропотливая и муторная – нужно «раскрасить» несколько десятков, а лучше сотен кадров. Для нашего ролика за несколько полных дней было размечено 200 изображений-кадров. Потом сегментированные вручную изображения отдаются нейросети в качестве обучающей выборки, и нейросеть обучается. На GPU GeForce GTX 1080 обучение проходит примерно за два часа. Затем результат проверяется на другом отрывке видеоролика, огрехи заново сегментируются вручную, и процесс повторяется.
В результате нейросеть наконец-то начинает понимать, где что на картинке, и может сама его сегментировать:

Human casualties: 0.0
Едем!
Телеграм: t.me/ainewsline
Источник: m.vk.com