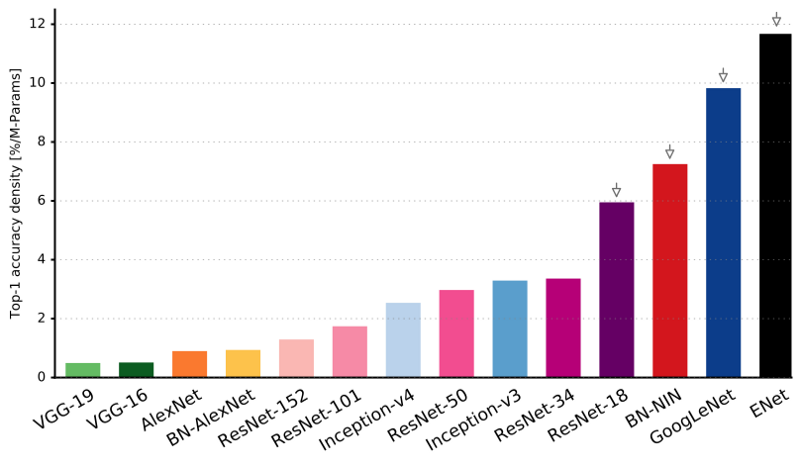
Алгоритмы глубоких нейросетей сегодня обрели большую популярность, которая во многом обеспечивается продуманностью архитектур. Давайте рассмотрим историю их развития за последние несколько лет. Если вас интересует более глубокий анализ, обратитесь к этой работе. Сравнение популярных архитектур по Top-1 one-crop-точности и количеству операций, необходимых для одного прямого прохода. Подробнее здесь.
LeNet5
В 1994-м была разработана одна из первых свёрточных нейросетей, положившая начало глубокому обучению. Эта пионерская работа Яна Лекуна (Yann LeCun) после многих успешных итераций начиная с 1988-го получила название LeNet5!
Архитектура LeNet5 стала фундаментальной для глубокого обучения, особенно с точки зрения распределения свойств изображения по всей картинке. Свёртки с обучаемыми параметрами позволяли с помощью нескольких параметров эффективно извлекать одинаковые свойства из разных мест. В те годы ещё не было видеокарт, способных ускорить процесс обучения, и даже центральные процессоры были медленными. Поэтому ключевым преимуществом архитектуры оказалась возможность сохранять параметры и результаты вычислений, в отличие от использования каждого пикселя в качестве отдельных входных данных для большой многослойной нейросети. В LeNet5 в первом слое пиксели не используются, потому что изображения сильно коррелированы пространственно, так что использование отдельных пикселей в качестве входных свойств не позволит воспользоваться преимуществами этих корреляций. Особенности LeNet5:
Свёрточная нейросеть, использующая последовательность из трёх слоёв: слои свёртки (convolution), слои группирования (pooling) и слои нелинейности (non-linearity) –> с момента публикации работы Лекуна это, пожалуй, одна из главных особенностей глубокого обучения применительно к изображениям.
Использует свёртку для извлечения пространственных свойств.
Подвыборка с использованием пространственного усреднения карт.
Нелинейность в виде гиперболического тангенса или сигмоид.
Финальный классификатор в виде многослойной нейросети (MLP).
Разреженная матрица связности между слоями позволяет уменьшить объём вычислений.
Эта нейросеть легла в основу многих последующих архитектур и вдохновила множество исследователей.
Развитие
С 1998-го по 2010-й нейросети пребывали в состоянии инкубации. Большинство людей не замечали их растущих возможностей, хотя многие разработчики постепенно оттачивали алгоритмы. Благодаря расцвету камер мобильных телефонов и удешевлению цифровых фотоаппаратов нам становилось доступно всё больше данных для обучения. Заодно росли и вычислительные возможности, процессоры становились мощнее, а видеокарты превратились в основной вычислительный инструмент. Все эти процессы позволяли развиваться и нейросетям, пусть и довольно медленно. Возрастал интерес к задачам, которые можно было решить с помощью нейросетей, и наконец ситуация стала очевидной…
Dan Ciresan Net
В 2010-м Дан Кирешан (Dan Claudiu Ciresan) и Йорген Шмидхубер (Jurgen Schmidhuber) опубликовали одно из первых описаний реализации GPU-нейросетей. Их работа содержала прямую и обратную реализацию 9-слойной нейросети на NVIDIA GTX 280.
AlexNet
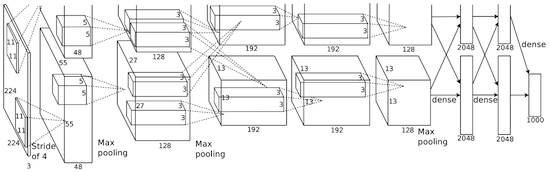
В 2012-м Алексей Крижевский опубликовал AlexNet, углублённую и расширенную версию LeNet, которая с большим отрывом победила в сложном соревновании ImageNet.
В AlexNet результаты вычислений LeNet масштабированы в гораздо более крупную нейросеть, которая способна изучить намного более сложные объекты и их иерархии. Особенности этого решения:
Использование блоков линейной ректификации (ReLU) в качестве нелинейностей.
Использование методики отбрасывания для выборочного игнорирования отдельных нейронов в ходе обучения, что позволяет избежать переобучения модели.
Перекрытие max pooling, что позволяет избежать эффектов усреднения average pooling.
К тому времени количество ядер в видеокартах сильно выросло, что позволило примерно в 10 раз сократить время обучения, и в результате стало возможно использовать куда более крупные датасеты и картинки.
Успех AlexNet запустил небольшую революцию, свёрточные нейросети превратились в рабочую лошадку глубокого обучения — этот термин отныне означал «большие нейросети, способные решать полезные задачи».
Overfeat
В декабре 2013-го лаборатория NYU Яна Лекуна опубликовала описание Overfeat, разновидности AlexNet. Также в статье описывались обучаемые bounding boxes, и впоследствии вышло много других работ по этой тематике. Мы считаем, что лучше научиться сегментировать объекты, а не использовать искусственные bounding boxes.
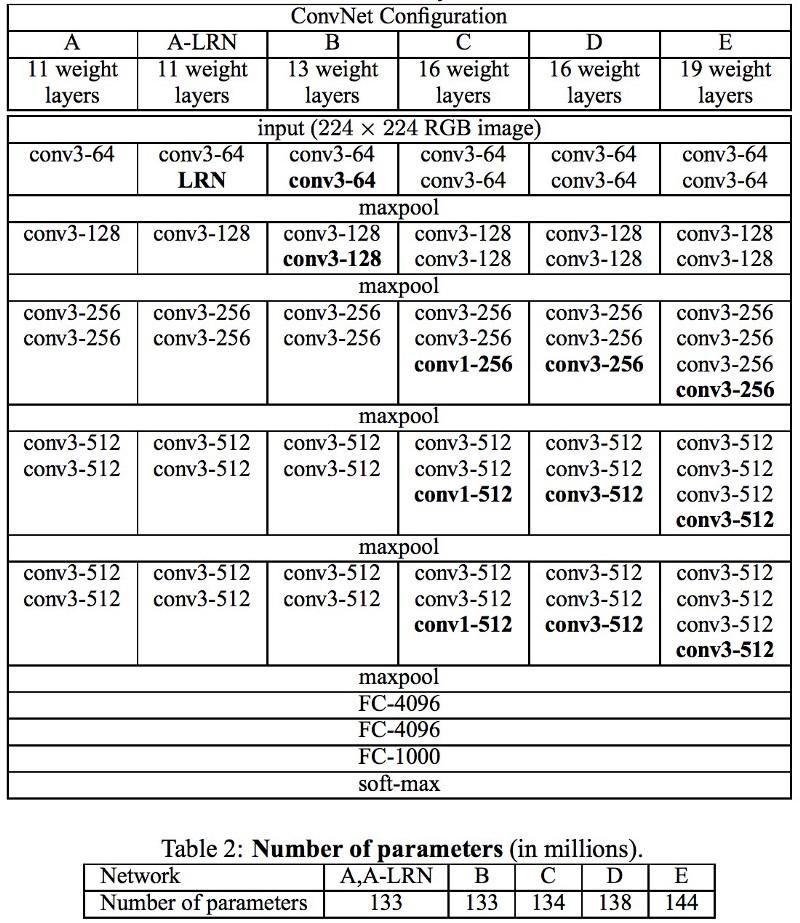
VGG
В разработанных в Оксфорде VGG-сетях в каждом свёрточном слое впервые применили фильтры 3х3, да ещё и объединили эти слои в последовательности свёрток. Это противоречит заложенным в LeNet принципам, согласно которым большие свёртки использовались для извлечения одинаковых свойств изображения. Вместо применяемых в AlexNet фильтров 9х9 и 11х11 стали применять гораздо более мелкие фильтры, опасно близкие к свёрткам 1х1, которых старались избежать авторы LeNet, по крайней мере в первых слоях сети. Но большим преимуществом VGG стала находка, что несколько свёрток 3х3, объединённых в последовательность, могут эмулировать более крупные рецептивные поля, например, 5х5 или 7х7. Эти идеи позднее будут использованы в архитектурах Inception и ResNet.
Сети VGG для представления сложных свойств используют многочисленные свёрточные слои 3x3. Обратите внимание на блоки 3, 4 и 5 в VGG-E: для извлечения более сложных свойств и их комбинирования применяются последовательности 256?256 и 512?512 фильтров 3?3. Это равносильно большим свёрточным классификаторам 512х512 с тремя слоями! Это даёт нам огромное количество параметров и прекрасные способности к обучению. Но учить такие сети было сложно, приходилось разбивать их на более мелкие, добавляя слои один за другим. Причина заключалась в отсутствии эффективных способов регуляризации моделей или каких-то методов ограничения большого пространства поиска, которому способствует множество параметров. VGG во многих слоях используют большое количество свойств, поэтому обучение требовало больших вычислительных затрат. Снизить нагрузку можно уменьшив количество свойств, как это сделано в bottleneck-слоях архитектуры Inception.
Network-in-network
В основе архитектуры Network-in-network (NiN) лежит простая идея: использование свёрток 1x1 для увеличения комбинаторности свойств в свёрточных слоях. В NiN после каждой свёртки применяются пространственные MLP-слои, чтобы лучше скомбинировать свойства перед подачей в следующий слой. Может показаться, что использование свёрток 1х1 противоречит исходным принципам LeNet, но на самом деле это позволяет комбинировать свойства лучше, чем просто набивая больше свёрточных слоёв. Этот подход отличается от использования голых пикселей в качестве входных данных для следующего слоя. В данном случае свёртки 1х1 применяются для пространственного комбинирования свойств после свёртки в рамках карт свойств, так что можно использовать гораздо меньше параметров, которые являются общими для всех пикселей этих свойств!
MLP позволяют сильно повысить эффективность отдельных свёрточных слоёв посредством их комбинирования в более сложные группы. Эта идея позднее была использована в других архитектурах, таких как ResNet, Inception и их вариантах.
GoogLeNet и Inception
Кристиан Жегеди (Christian Szegedy) из Google озаботился снижением объёма вычислений в глубоких нейросетях, и в результате создал GoogLeNet — первую архитектуру Inception. К осени 2014-го модели глубокого обучения стали очень полезны в категоризировании содержимого изображений и кадров из видео. Многие скептики признали пользу глубокого обучения и нейросетей, а интернет-гиганты, в том числе Google, сильно заинтересовались развёртыванием на своих серверных мощностях эффективных и крупных сетей. Кристиан искал пути уменьшения вычислительной нагрузки в нейросетях, добиваясь высочайшей производительности (например, в ImageNet). Или сохраняя объём вычислений, но всё равно при этом повышая производительность.
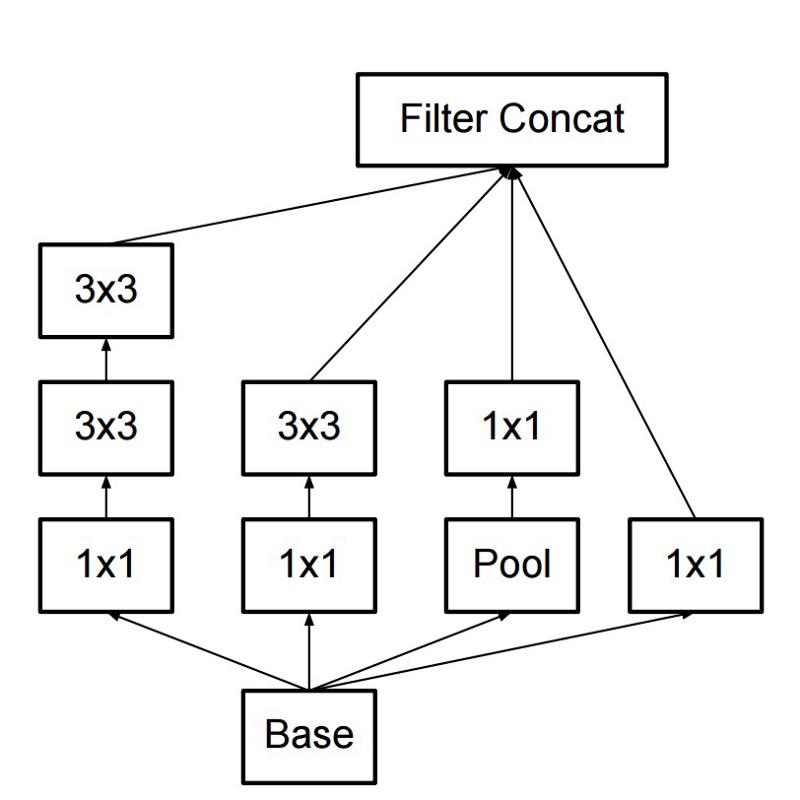
В результате команда создала модуль Inception:
На первый взгляд, это параллельная комбинация свёрточных фильтров 1х1, 3х3 и 5х5. Но изюминка заключалась в использовании свёрточных блоков 1х1 (NiN) для уменьшения количества свойств перед подачей в «дорогие» параллельные блоки. Обычно эту часть называют bottleneck, подробнее она описывается в следующей главе. В GoogLeNet в качестве начального слоя применяется stem без Inception-модулей, а также используется average pooling и softmax-классификатор, аналогичный NiN. Этот классификатор выполняет крайне мало операций по сравнению с AlexNet и VGG. Это также помогло создать очень эффективную архитектуру нейросети.
Bottleneck-слой
Этот слой уменьшает количество свойств (а значит и операций) в каждом слое, так что скорость получения результата можно сохранить на высоком уровне. Прежде чем передавать данные в «дорогие» свёрточные модули, количество свойств уменьшается, скажем, в 4 раза. Это сильно сокращает объём вычислений, что и обеспечило архитектуре популярность.
Давайте разберёмся. Пусть у нас 256 свойств на входе и 256 на выходе, и пусть Inception-слой выполняет только свёртки 3х3. Получаем 256х256х3х3 свёрток (589 000 операций умножения с накоплением, то есть MAC-операций). Это может выходить за рамки наших требований к скорости вычислений, допустим, чтобы слой обрабатывался за 0,5 миллисекунды на Google Server. Тогда уменьшим количество свойств для свёртывания до 64 (256/4). В этом случае сначала выполним свёртку 1х1 256 -> 64, затем ещё 64 свёрток во всех Inception-ветках, а потом снова применим свёртку 1x1 из 64 -> 256 свойств. Количество операций:
256?64 ? 1?1 = 16 000
64?64 ? 3?3 = 36 000
64?256 ? 1?1 = 16 000
Всего около 70 000, снизили количество операций почти в 10 раз! Но при этом мы не потеряли обобщённости в этом слое. Bottleneck-слои продемонстрировали превосходную производительность на датасете ImageNet, и стали применяться в более поздних архитектурах, таких как ResNet. Причина их успеха в том, что входные свойства коррелированы, а значит можно избавиться от избыточности, правильно комбинируя свойства со свёртками 1х1. А после свёртывания с меньшим количеством свойств можно на следующем слое опять развернуть их в значимую комбинацию.
Inception V3 (и V2)
Кристиан и его команда оказались очень эффективными исследователями. В феврале 2015-го в качестве второй версии Inception была представлена архитектура Batch-normalized Inception. Пакетная нормализация (batch-normalization) вычисляет среднее и среднеквадратичное отклонение всех карт распределения свойств в выходном слое, и нормализует их отклики с этими значениями. Это соответствует «отбеливанию» данных, то есть отклики всех нейронных карт лежат в одном диапазоне и с нулевым средним. Такой подход облегчает обучение, потому что последующий слой не обязан запоминать смещения (offsets) входных данных и может заниматься только поиском лучших комбинаций свойств. В декабре 2015-го вышла новая версия модулей Inception и соответствующей архитектуры. В авторской статье лучше объясняется оригинальная архитектура GoogLeNet, там гораздо подробнее рассказано о принятых решениях. Основные идеи:
Максимизация потока информации в сети за счёт аккуратного баланса между её глубиной и шириной. Перед каждым pooling-ом увеличиваются карты свойств.
С увеличением глубины также систематически увеличивается количество свойств или ширина слоя.
Ширина каждого слоя увеличивается ради увеличения комбинации свойств перед следующим слоем.
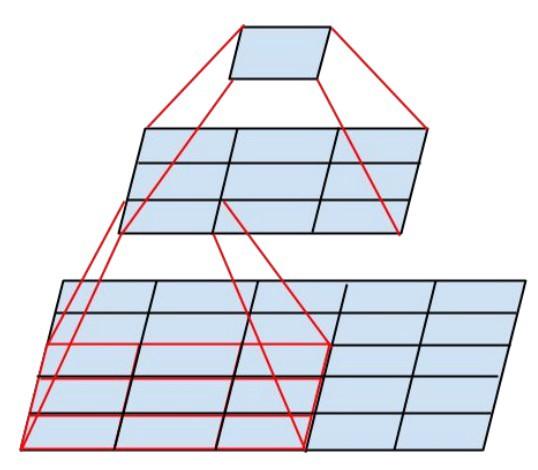
По мере возможности используются только свёртки 3x3. Учитывая, что фильтры 5x5 и 7x7 можно декомпозировать с помощью нескольких 3x3
новый Inception-модуль выглядит так:
Фильтры также можно декомпозировать с помощью сглаженных свёрток в более сложные модули:
Inception-модули могут с помощью pooling-а в ходе Inception-вычислений уменьшать размер данных. Это аналогично выполнению свёртки со страйдами параллельно с простым pooling-слоем:
В качестве финального классификатора Inception использует pooling-слой с softmax.
ResNet
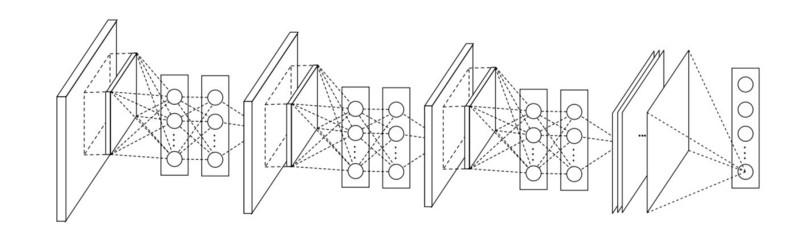
В декабре 2015-го, примерно в то же время, как была представлена архитектура Inception v3, произошла революция — опубликовали ResNet. В ней заложены простые идеи: подаём выходные данные двух успешных свёрточных слоёв И обходим входные данные для следующего слоя!
Такие идеи уже предлагались, например, здесь. Но в данном случае авторы обходят ДВА слоя и применяют подход в больших масштабах. Обход одного слоя не даёт особой выгоды, а обход двух — ключевая находка. Это можно рассматривать как маленький классификатор, как сеть-в-сети! Также это был первый в истории пример обучения сети из нескольких сотен, даже тысячи слоёв. В многослойной ResNet применили bottleneck-слой, аналогичный тому, что применяется в Inception: Этот слой уменьшает количество свойств в каждом слое, сначала используя свёртку 1х1 с меньшим выходом (обычно четверть от входа), затем идёт слой 3х3, а потом опять свёртка 1х1 в большее количество свойств. Как и в случае с Inception-модулями, это позволяет экономить вычислительные ресурсы, сохраняя богатство комбинаций свойств. Сравните с более сложными и менее очевидными stem-ами в Inception V3 и V4.
В качестве финального классификатора в ResNet используется pooling-слой с softmax. Каждый день появляются дополнительные сведения об архитектуре ResNet:
Её можно рассматривать как систему одновременно параллельных и последовательных модулей: во многих модулях inout-сигнал приходит параллельно, а выходные сигналы каждого модуля соединяются последовательно.
Выяснилось, что ResNet обычно оперирует блоками относительно небольшой глубины в 20-30 слоёв, работающих параллельно, а не прогоняя последовательно по всей длине сети.
Снова отличились Кристиан и его команда, выпустившие новую версию Inception. Inception-модуль, идущий после stem, такой же, как в Inception V3:
При этом Inception-модуль скомбинирован с ResNet-модулем: Эта архитектура получилась, на мой вкус, сложнее, менее элегантной, а также наполненной малопрозрачными эвристическими решениями. Трудно понять, почему авторы приняли те или иные решения, и столь же трудно дать им какую-то оценку. Поэтому приз за чистую и простую нейросеть, лёгкую в понимании и модифицировании, переходит к ResNet.
SqueezeNet
SqueezeNet опубликовали недавно. Это переделка на новый лад многих концепций из ResNet и Inception. Авторы продемонстрировали, что улучшение архитектуры позволяет уменьшить размеры сетей и количество параметров без сложных алгоритмов сжатия.
ENet
Все особенности недавних архитектур скомбинированы в очень эффективную и компактную сеть, использующую совсем мало параметров и вычислительных мощностей, но при этом дающую превосходные результаты. Архитектура получила название ENet, её разработал Адам Пазке (Adam Paszke). К примеру, мы использовали её для очень точной маркировки объектов на экране и парсинга сцен. Несколько примеров работы Enet. Эти видео не имеют отношения к обучающему датасету. Здесь можно найти технические подробности ENet. Это сеть на основе кодировщика и декодера. Кодировщик построен по обычной схеме CNN для категоризации, а декодер представляет собой сеть с повышением дискретизации (upsampling netowrk), предназначенную для сегментирования посредством распространения категорий обратно в изображение исходного размера. Для сегментации изображений использовались только нейросети, никаких других алгоритмов.
Как видите, ENet имеет наивысшую удельную точность по сравнению со всеми остальными нейросетями. ENet создавалась из расчёта, чтобы с самого начала использовать как можно меньше ресурсов. В результате кодировщик и декодер вместе занимают всего 0,7 Мб с точностью fp16. И при таком крохотном размере ENet по точности сегментирования не уступает или превосходит прочие чисто нейросетевые решения.
Анализ модулей
Опубликовали систематическую оценку CNN-модулей. Оказалось, что выгодно:
Использовать нелинейность ELU без пакетной нормализации (batchnorm) или ReLU с нормализацией.
Применять выученную трансформацию цветового пространства RGB.
Использовать политику линейного ухудшения скорости обучения (linear learning rate decay policy).
Использовать сумму среднего и максимального pooling-слоя.
Использовать мини-пакет размером 128 или 256. Если для вашей видеокарты этого слишком много, уменьшайте скорость обучения пропорционально размеру пакета.
Использовать полносвязные слои в качестве свёрточных и усреднять прогнозы для выдачи финального решения.
Если увеличиваете размера обучающего датасета, удостоверьтесь, что не достигли плато в обучении. Чистота данных важнее размера.
Если не можете увеличить размер входного изображения, уменьшайте страйд в последующих слоях, эффект будет примерно таким же.
Если ваша сеть обладает сложной и высокооптимизированной архитектурой, как в GoogLeNet, то модифицируйте её с осторожностью.
Xception
Xception привнесла в Inception-модуль более простую и элегантную архитектуру, которая не менее эффективна, чем ResNet и Inception V4. Вот как выглядит Xception-модуль:
Эта сеть понравится кому угодно благодаря простоте и элегантности своей архитектуры: Она содержит 36 этапов свёртки, и в этом схожа с ResNet-34. При этом модель и код просты, как в ResNet, и гораздо приятнее, чем в Inception V4. Torch7-реализация этой сети доступна здесь, а реализация на Keras/TF — здесь. Любопытно, что авторы недавней архитектуры Xception тоже вдохновлялись нашей работой над отделяемыми (separable) свёрточными фильтрами.
MobileNets
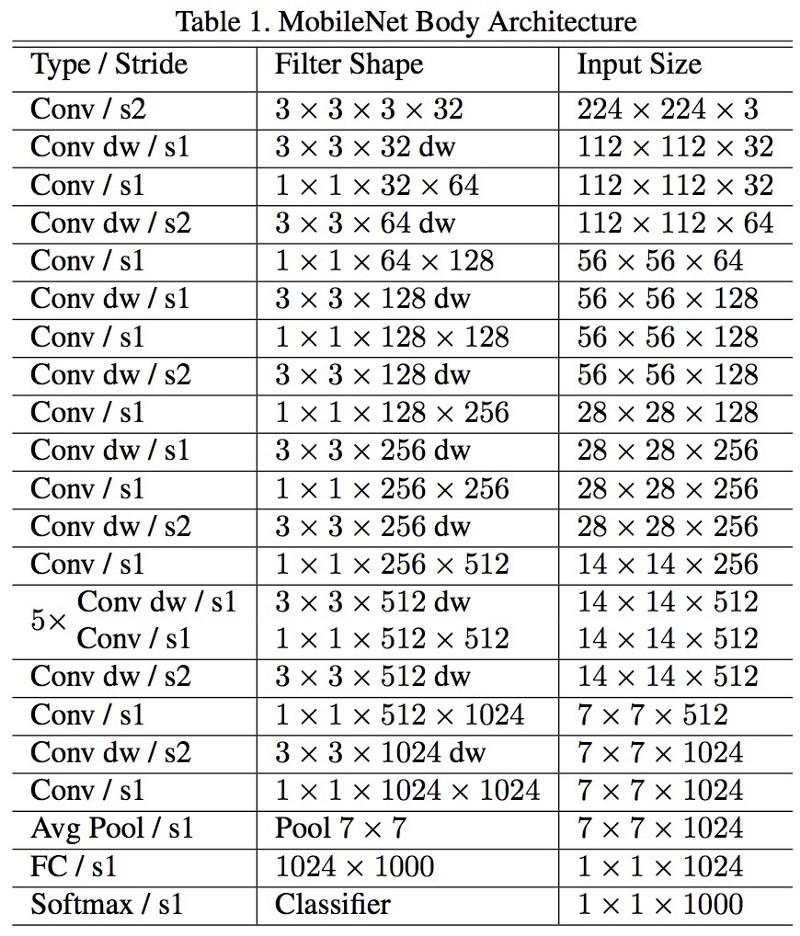
Новая архитектура MobileNets вышла в апреле 2017-го. Для уменьшения количества параметров в ней используются отделяемые свёртки, такие же, как в Xception. Ещё в работе утверждается, что авторы смогли сильно уменьшить количество параметров: примерно вдвое в случае с FaceNet. Полная архитектура модели:
Мы протестировали эту сеть в реальной задаче и обнаружили, что она работает несоизмеримо медленно на пакете из 1 (batch of 1) на видеокарте Titan Xp. Сравните длительность вывода для одного изображения:
resnet18: 0,002871
alexnet: 0,001003
vgg16: 0,001698
squeezenet: 0,002725
mobilenet: 0,033251
Это нельзя назвать быстрой работой! Количество параметров и размер сети на диске уменьшены, но толку от этого нет.
Другие примечательные архитектуры
FractalNet использует рекурсивную архитектуру, которая пока не тестировалась на ImageNet и является производным или более общим вариантом ResNet.
Будущее
Мы верим, что разработка архитектур нейросетей имеет первостепенную важность для развития глубокого обучения. Мы очень рекомендуем внимательно прочитать и обдумать все работы, приведённые здесь.
Вы можете спросить, почему мы должны тратить столько времени на разработку архитектур, и почему вместо этого не используем данные, которые подскажут нам, что именно применять и как объединять модули? Заманчивая возможность, но работы над этим пока ещё ведутся. Здесь есть некоторые начальные результаты. Кроме того, мы разговаривали только об архитектурах для компьютерного зрения. В других сферах разработки тоже ведутся, и было бы интересно изучить эволюцию по другим направлениям. Если вас интересует сравнение работы нейросетей и вычислительной производительности, см. нашу недавнюю работу.






 Этот слой уменьшает количество свойств в каждом слое, сначала используя свёртку 1х1 с меньшим выходом (обычно четверть от входа), затем идёт слой 3х3, а потом опять свёртка 1х1 в большее количество свойств. Как и в случае с Inception-модулями, это позволяет экономить вычислительные ресурсы, сохраняя богатство комбинаций свойств. Сравните с более сложными и менее очевидными stem-ами в Inception V3 и V4.
Этот слой уменьшает количество свойств в каждом слое, сначала используя свёртку 1х1 с меньшим выходом (обычно четверть от входа), затем идёт слой 3х3, а потом опять свёртка 1х1 в большее количество свойств. Как и в случае с Inception-модулями, это позволяет экономить вычислительные ресурсы, сохраняя богатство комбинаций свойств. Сравните с более сложными и менее очевидными stem-ами в Inception V3 и V4.