Пицца аля-semi-supervised
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-10-04 01:20
системы технического зрения, алгоритмы машинного обучения, реализация нейронной сети

Задача
Есть определенный процесс приготовления пиццы и фотографии с его разных стадий (в том числе не только пиццы). Известно, что если рецептура теста испорчена, то на коржике будут белые пупырышки. Также есть бинарная разметка качества теста каждого экземпляра пиццы, сделанная специалистами. Необходимо разработать алгоритм, который будет определять качество теста по фотографии.
Датасет состоит из фотографий, сделанных с разных телефонов, в разных условиях, разных ракурсах. Экземпляров пицц — 17к. Всего фотографий — 60к.
На мой взгляд, задача вполне типичная и хорошо подходит, чтобы показать разные подходы обращения с данными. Для ее решения необходимо:
- Выбрать фотографии, где есть коржик пиццы;
- На выбранных фотографиях выделить коржик;
- Обучить нейросеть на выделенных участках.
Фильтрация фотографий
На первый взгляд кажется, что проще всего было бы отдать эту задачу разметчикам, и потом на чистых данных обучить датасет. Однако я решил, что мне проще самому разметить малую часть, чем объяснять разметчиком, какой ракурс — правильный. Тем более, у меня и не было жесткого критерия правильного ракурса.
Поэтому вот как я поступил:
- Разметил 100 фоток кромки;

2. Посчитал фичи после глобального пуллинга из сетки resnet-152 с весами от imagenet11k_places365;

3. Взял среднее от фичей каждого класса, получив два анкора;
4. Посчитал расстояние от каждого анкора до всех фичей оставшихся 50к фоток;
5. Топ-300 по близости от одного анкора релевантны положительному классу, топ500 самых близких от другого анкора — отрицательный класс;

6. На этих сэмплах обучил LightGBM на тех же фичах (на картинке указан XGboost, потому что у него есть лого и он более узнаваем, а у LightGBM лого нет);
7. С помощью этой модели получил разметку всего датасета.
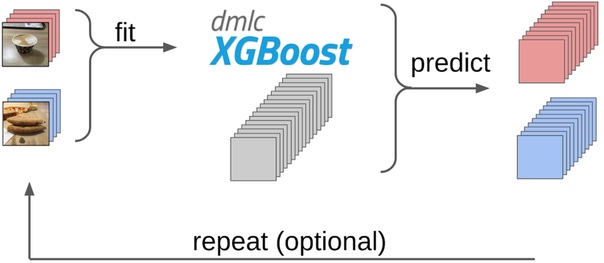
Примерно такой же подход я использовал в kaggle соревнованиях в качестве бейзлайна.
Объяснение на пальцах почему такой подход вообще работает
Нейросеть можно воспринимать как сильно нелинейное преобразование картинки. В случае классификации картинка преобразуется в вероятности классов, которые были в обучающей выборке. И эти вероятности по сути можно использовать как фичи для Light GBM. Однако это достатоно бедное описание и в случае пиццы мы будет таким образом говорить, что класс коржика это условно 0.3 кошки и 0.7 собаки, а треш это все остальное. Вместо этого можно использовать менее разреженные фичи, после Global Average Pooling. Они обладают таким свойством, что из сэмплов обучающей выборки генерият фичи, которые должны разделяться линейным преобразованием (полносвязным слоем с Softmax'ом). Однако из-за того, что в трейне imagenet'a не было пиццы в явном виде, то чтобы разделить классы новой обучающей выборки, лучше взять нелинейное преобразование в виде деревьев. В принципе, можно пойти еще дальше и взять фичи из каких-то промежуточных слоев нейросети. Они будут лучше в том, что не еще не потеряли локальность объектов. Но они сильно хуже из-за размера вектора фичей. И кроме того менее линейны, чем перед полносвязным слоем.
Небольшое лирическое отступление
В ODS недавно жаловались, что никто не пишет про свои фейлы. Исправляю ситуацию. Примерно год назад я участвовал в соревновании Kaggle Sea Lions вместе с Евгением Нижибицким. Задача состояла в подсчете морских котиков на снимках с беспилотника. Разметка была дана просто в виде координат тушек, но в какой-то момент Владимир Игловиков разметил их ббоксами и великодушно поделился этим с сообществом. На тот момент я считал себя батей семантической сегментации (после Kaggle Dstl) и решил, что Unet сильно облегчит задачу подсчета, если научиться классно выделять котиков.
Пояснение про семантическую сегментацию
Семантическая сегментация это по сути попиксельная классификация картинки. То есть каждому исходному пикселю картинки нужно поставить в соответствие класс. В случае бинарной сегментации (случай статьи), это будет либо положительный, либо отрицательный класс. В случае многоклассовой сегментации, каждому пикселю вставится в соответствие класс из обучающей выборки (фон, трава, котик, человек и т.д.). В случае бинарной сегментации в то время хорошо себя зарекомендовала архитектура нейросети U-net. Эта нейросеть по структуре похожая на обычный энкодер-декодер, но с пробросами фичей из энкодер-части в декодер на соответствующих по размеру стадиях.
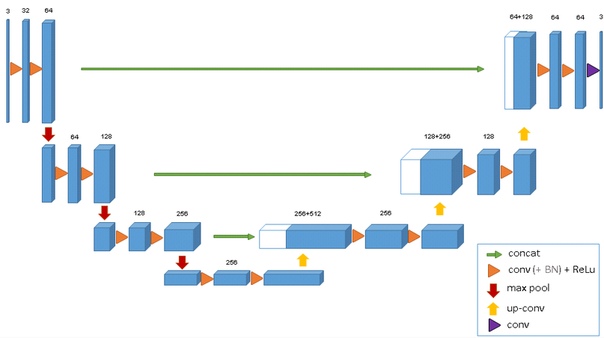
В ванильном виде, правда, ее никто уже не использует, а как минимум добавляют Batch Norm. Ну и как правило берут жирный энкодер и раздувают декодер. Еще на смену U-net-like архектурам сейчас пришли новомодные FPN сегментационные сетки, которые показывают хороший перфоманс на некоторых задачах. Однако Unet-like архитектуры и по сей день не потеряли актуальность. Они хорошо работают как бейзлайн, их легко обучать и очень просто варьировать глубину / размер нейрости меняя разные экнкодеры.
Соответственно, я начал обучать сегментацию, имея в качестве таргета на первом этапе только ббоксы котиков. После первой стадии обучения я предсказал трейн и посмотрел, как выглядят предикты. С помощью эвристик можно было выбрать из маски абстрактный confidence (уверенность предсказаний) и условно разделить предсказания на две группы: где все хорошо и где все плохо.

Предсказания, где все хорошо, можно было использовать для обучения следующей итерации модели. Предикты, где все плохо, можно было выбрать с большими площадями без котиков, занулить руками маски и тоже докинуть в трейн. И так итерационно мы с Евгением обучили модель, которая научилась даже сегментировать плавники морских котиков для больших особей.
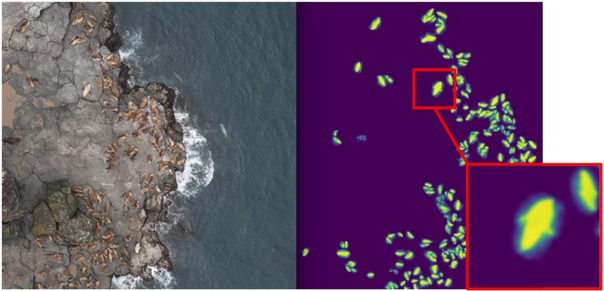
Но это был лютый фейл: мы потратили кучу времени на то, чтобы научиться круто сегментировать котиков и… Это почти никак не помогло в их подсчете. Предположение о том, что плотность котиков (количество особей на единицу площади маски) постоянна, не работало, потому что беспилотник летал на разной высоте, и фотки имели разный масштаб. И при этом, сегментация все равно не выделяла отдельных особей, если они лежали плотно — что происходило довольно часто. А до инновационного подхода по разделению объектов команды Tocoder’ов на DSB2018 оставался еще год. В итоге мы остались у разбитого корыта и финишировали на 40 месте из 600 команд.
Однако я сделал два вывода: семантическая сегментация — это удобный подход для визуализации и анализа работы алгоритма, а из ббоксов при некотором старании можно сварить маски.
Но вернемся к пицце. Чтобы на отобранных и отфильтрованных фотографиях выделить коржик, самым правильным вариантом было бы отдать задачу разметчикам. На тот момент у нас уже был реализованы ббоксы и алгоритм консенсуса для них. Поэтому я просто накидал пару примеров и отдал на разметку. В итоге я получил 500 сэмплов с точно выделенной областью коржика.
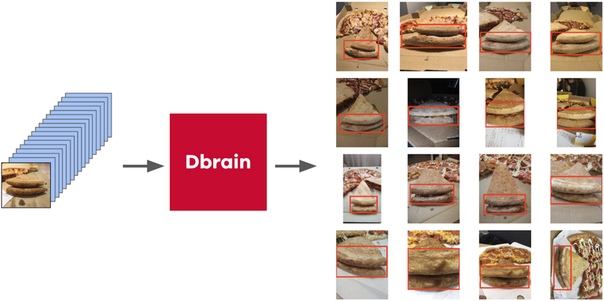
Затем я откопал свой код с котиков и более формально подошел к теперешней процедуре. После первой итерации обучения было так же хорошо видно, где ошибается модель. И уверенность предсказаний можно определить так:
1 — (площадь серой зоны) / (площадь маски) # тут будет формула, обещаю
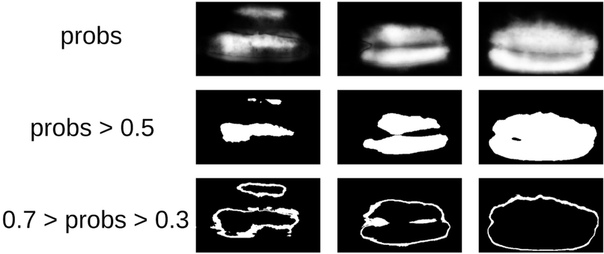
Теперь, чтобы сделать следующую итерацию натягивания ббоксов на маски, небольшой ансамбль предскажем трейн с ТТА. Это можно считать в некоторой степени WAAAAGH knowledge distillation, но правильней называть Pseudo Labeling.

Дальше нужно глазами выбрать некоторый порог уверенности, начиная с которого мы формируем новый трейн. И опционально можно разметить самые сложные сэмплы, с которыми ансамбль не справился. Я решил, что это будет полезно, и раскрасил где-то 20 картинок, пока переваривал обед.
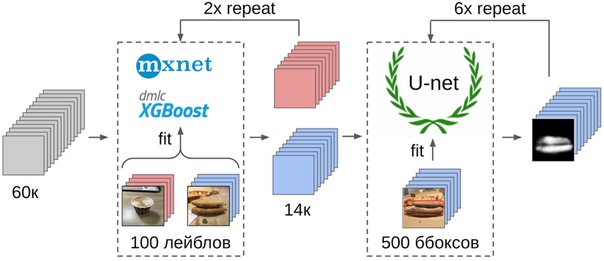
А теперь финальная часть пайплайна: обучение модели. Чтобы подготовить сэмплы, я экстрактнул область коржика по маске. Также я немного раздул маску диляцией и применил ее к картинке, чтобы удалить фон, поскольку там не должно быть информации о качестве теста. А затем я просто зафайнтюнил несколько моделей из зоопарка Imagenet. Всего у меня получилось собрать порядка 12к уверенных сэмплов. Поэтому я обучал не всю нейросеть, а только последнюю группу сверток, чтобы модель не переобучалась.
Зачем нужно замораживать слои?
От этого есть два профита: 1. Сеть обучается быстрее, поскольку не нужно считать градиенты для замороженных слоев. 2. Сеть не переобучается, поскольку у нее теперь меньше свободных параметров. При этом утверждается, что первые несколько групп сверток в ходе обучения на Imagenet генерят достаточно общие признаки типа резких цветовых переходов и текстур, которые подходят для очень широкого класса объектов на фотографии. А это значит, что их можно не обучать в ходе Transer Learning'a.

Лучшей сингл моделью оказалась Inception-Resnet-v2, и для нее ROC-AUC на одном фолде составил 0.700. Если ничего не выделять и подавать сырые картинки как есть, то ROC-AUC составить 0.58. Пока я разрабатывал решение, у DODO пиццы сварилась следующая партия данных, и можно было протестировать весь пайплайн на честном холдауте. Мы проверили на нем весь пайплайн и получили ROC-AUC 0.83.
Давайте теперь посмотрим на ошибки:
Топ False Negative

Тут видно, что они связаны с ошибкой разметки коржика, поскольку явно присутствуют признаки испорченного теста.
Топ False Positive

Здесь ошибки связаны с тем, что первой моделью выбран не очень удачный ракурс, по которому сложно найти ключевые признаки качества теста.
Заключение
Коллеги иногда подкалывают меня, что я многие задачи решаю сегментацией с использованием Unet. Однако, на мой взгляд, это довольно мощный и удобный подход. Он позволяет визуализировать ошибки модели и уверенность ее предсказаний. Кроме того, весь пайплайн выглядит очень просто и сейчас есть куча репозиториев под любой фреймворк.
Телеграм: t.me/ainewsline
Источник: m.vk.com