Обучение и тестирование нейронных сетей на PyTorch с помощью Ignite
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-10-08 17:15
Привет, Хабр, в этой статье я расскажу про библиотеку ignite, с помощью которой можно легко обучать и тестировать нейронные сети, используя фреймворк PyTorch.
С помощью ignite можно писать циклы для обучения сети буквально в несколько строк, добавлять из коробки расчет стандартных метрик, сохранять модель и т.д. Ну, а для тех кто переехал с TF на PyTorch, можно сказать, что библиотека ignite — Keras для PyTorch.
В статье будет детально разобран пример обучения нейронной сети для задачи классификации, используя ignite

Добавим еще больше огня в PyTorch
Не буду тратить время, рассказывая о том, насколько крутой фреймворк PyTorch. Тот, кто им уже пользовался, понимает, о чём я пишу. Но, при всех его достоинствах, он все же является низкоуровневым в плане написания циклов для обучения, проверки, тестирования нейронных сетей.
Если мы посмотрим официальные примеры использования фреймворка PyTorch, то увидим в коде обучения сетки как минимум два цикла итераций по эпохам и по батчам обучающей выборки:
for epoch in range(1, epochs + 1): for batch_idx, (data, target) in enumerate(train_loader): # ...Основная идея библиотеки ignite заключается в том, чтобы факторизовать эти циклы в единый класс, при этом позволив пользователю взаимодействовать с этими циклами с помощью обработчиков событий.
В итоге, в случае стандартных задач глубокого обучения мы можем неплохо сэкономить на количестве строк кода. Меньше строк — меньше ошибок!
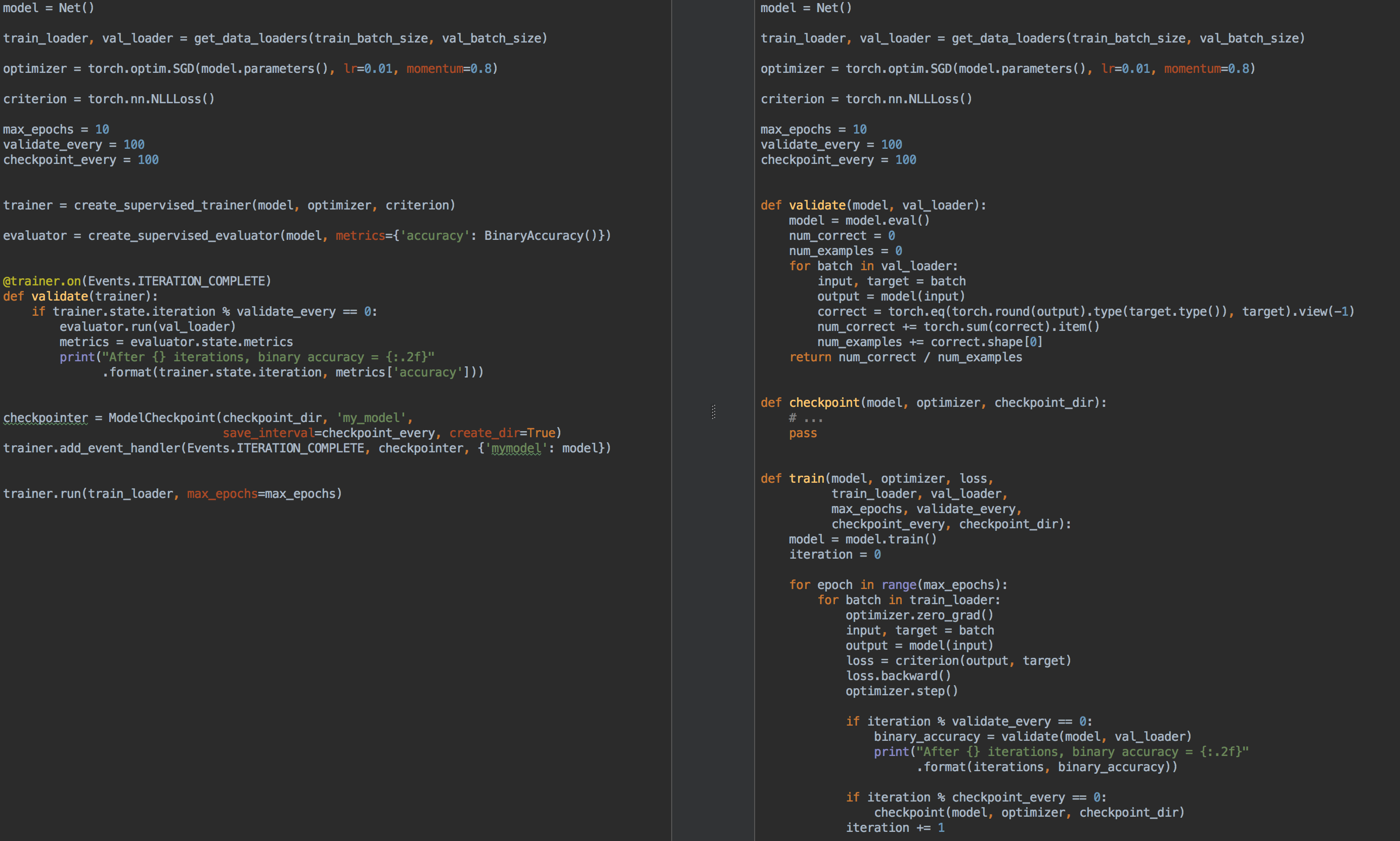
К примеру, для сравнения, слева код для обучения и валидации модели, используя ignite, а справа — на чистом PyTorch:
Итак, ещё раз, чем же хорош ignite?
- больше не нужно писать для каждой задачи циклы
for epoch in range(n_epochs)иfor batch in data_loader. - позволяет лучше факторизовать код
- позволяет вычислять базовые метрики из коробки
- предоставляет “плюшки” типа
- сохранение последней и лучших моделей (также оптимизатора и learning rate scheduler) во время обучения,
- ранняя остановка обучения
- итд
- легко интегрируется с инструментами визуализации: tensorboardX, visdom, ...
В каком-то смысле, как уже было упомянуто, библиотеку ignite можно сравнить со всем известным Keras и его API для обучения и тестирования сетей. Также, библиотека ignite с первого взгляда очень похожа на библиотеку tnt, поскольку изначально обе библиотеки преследовали единые цели и имеют схожие идеи по их реализации.
Итак, зажигаем:
pip install pytorch-igniteили
conda install ignite -c pytorchДалее на конкретном примере мы ознакомимся с API библиотеки ignite.
Задача классификации с ignite
В этой части статьи рассмотрим школьный пример обучения нейронной сети для задачи классификации, используя библиотеку ignite.
Итак, возьмём простой датасет с картинками фруктов с kaggle. Задача заключается в том, чтобы каждой картинке с фруктом сопоставить соответствующий класс.
Прежде чем использовать ignite, давайте определим основные компоненты:
Поток данных (dataflow):
- загрузчик батчей обучающей выборки,
train_loader - загрузчик батчей проверочной выборки,
val_loader
Модель:
- возьмем маленькую сетку SqueezeNet из
torchvision
Алгоритм оптимизации:
- возьмем SGD
Функция потерь:
- Cross-Entropy
from pathlib import Path import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torch.utils.data.dataset import Subset from torchvision.datasets import ImageFolder from torchvision.transforms import Compose, RandomResizedCrop, RandomVerticalFlip, RandomHorizontalFlip from torchvision.transforms import ColorJitter, ToTensor, Normalize FRUIT360_PATH = Path(".").resolve().parent / "input" / "fruits-360_dataset" / "fruits-360" device = "cuda" train_transform = Compose([ RandomHorizontalFlip(), RandomResizedCrop(size=32), ColorJitter(brightness=0.12), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) val_transform = Compose([ RandomResizedCrop(size=32), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) batch_size = 128 num_workers = 8 train_dataset = ImageFolder((FRUIT360_PATH /"Training").as_posix(), transform=train_transform, target_transform=None) val_dataset = ImageFolder((FRUIT360_PATH /"Test").as_posix(), transform=val_transform, target_transform=None) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device) import torch.nn as nn from torchvision.models.squeezenet import squeezenet1_1 model = squeezenet1_1(pretrained=False, num_classes=81) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device)import torch.nn as nn from torch.optim import SGD optimizer = SGD(model.parameters(), lr=0.01, momentum=0.5) criterion = nn.CrossEntropyLoss()Итак, теперь пришло время запускать ignite:
from ignite.engine import Engine, _prepare_batch def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item() trainer = Engine(process_function)Давайте разберемся, что означает этот код.
Движок Engine
Класс ignite.engine.Engine — каркас библиотеки, а объект этого класса trainer:
trainer = Engine(process_function) определен со входной функцией process_function для обработки одного батча и служит для реализации проходов по обучающей выборке. Внутри класса ignite.engine.Engine происходит следующее:
while epoch < max_epochs: # run once on data for batch in data: output = process_function(batch) Вернемся к функции process_function:
def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item() Мы видим, что внутри функции мы, как обычно в случае обучения модели, вычисляем предсказания y_pred, рассчитываем функцию потерь loss и градиенты. Последние позволяют обновить веса модели: optimizer.step().
В общем случае, нет никаких ограничений на код функции process_function. Отметим только, что она принимает на вход два аргумента: объект Engine (в нашем случае trainer) и батч от загрузчика данных. Поэтому, например, для тестирования нейронной сети мы можем определить другой объект класса ignite.engine.Engine, в котором входная функция просто вычисляет предсказания, и реализовать проход по проверочной выборке один единственный раз. Об этом читайте далее.
Итак, выше приведенный код лишь только определяет необходимые объекты без запуска обучения. В принципе, в минимальном примере, можно вызвать метод:
trainer.run(train_loader, max_epochs=10)и данного кода достаточно, чтобы "тихо" (без какого-либо вывода промежуточных результатов) обучить модель.
Отметим также, что для задач такого типа в библиотеке есть удобный метод создания объекта trainer:
from ignite.engine import create_supervised_trainer trainer = create_supervised_trainer(model, optimizer, criterion, device)Конечно, на практике вышеприведенный пример представляет мало интереса, поэтому давайте добавим следующие опции для "тренера":
- вывод на экран значения функции потерь через каждые 50 итераций
- запуск расчета метрик на обучающей выборке при фиксированной модели
- запуск расчета метрик на проверочной выборке после каждой эпохи
- сохранение параметров модели после каждой эпохи
- сохранение трёх лучших моделей
- изменение скорости обучения в зависимости от эпохи (learning rate scheduling)
- ранняя остановка обучения (early-stopping)
События и обработчики событий
Чтобы добавить вышеперечисленные опции для "тренера" в библиотеке ignite предусмотрена система событий и запуск пользовательских обработчиков событий. Таким образом, пользователь может управлять объектом класса Engine на каждом этапе:
- движок запустился/завершил запуск
- эпоха началась/завершилась
- батч итерация началась/завершилась
и запускать свой код на каждом событии.
Вывод на экран значения функции потерь
Для этого нужно просто определить функцию, в которой будет происходит вывод на экран, и добавить ее к "тренеру":
from ignite.engine import Events log_interval = 50 @trainer.on(Events.ITERATION_COMPLETED) def log_training_loss(engine): iteration = (engine.state.iteration - 1) % len(train_loader) + 1 if iteration % log_interval == 0: print("Epoch[{}] Iteration[{}/{}] Loss: {:.4f}" .format(engine.state.epoch, iteration, len(train_loader), engine.state.output)) На самом деле есть два способа добавить обработчик событий: через add_event_handler, либо через декоратор on. Тоже самое, что и выше, можно сделать так:
from ignite.engine import Events log_interval = 50 def log_training_loss(engine): # ... trainer.add_event_handler(Events.ITERATION_COMPLETED, log_training_loss)Заметим, что в функцию обработки события можно передать любые аргументы. В общем случае, такая функция будет выглядеть так:
def custom_handler(engine, *args, **kwargs): pass trainer.add_event_handler(Events.ITERATION_COMPLETED, custom_handler, *args, **kwargs) # или @trainer.on(Events.ITERATION_COMPLETED, *args, **kwargs) def custom_handler(engine, *args, **kwargs): passИтак, давайте запустим обучение на одной эпохе и посмотрим, что будет:
output = trainer.run(train_loader, max_epochs=1)Epoch[1] Iteration[50/322] Loss: 4.3459 Epoch[1] Iteration[100/322] Loss: 4.2801 Epoch[1] Iteration[150/322] Loss: 4.2294 Epoch[1] Iteration[200/322] Loss: 4.1467 Epoch[1] Iteration[250/322] Loss: 3.8607 Epoch[1] Iteration[300/322] Loss: 3.6688Неплохо! Пойдем далее.
Запуск расчета метрик на обучающей и тестовой выборках
Давайте будем вычислять следующие метрики: средняя точность, средняя полнота после каждой эпохи на части обучающей и всей тестовой выборках. Заметим, что мы будем вычислять метрики на части обучающей выборки после каждой эпохи обучения, а не во время обучения. Таким образом замер эффективности будет более точным, поскольку модель не изменяется во время вычисления.
Итак, определим метрики:
from ignite.metrics import Loss, CategoricalAccuracy, Precision, Recall metrics = { 'avg_loss': Loss(criterion), 'avg_accuracy': CategoricalAccuracy(), 'avg_precision': Precision(average=True), 'avg_recall': Recall(average=True) } Далее мы создадим два движка для оценки модели, используя ignite.engine.create_supervised_evaluator:
from ignite.engine import create_supervised_evaluator # Напомним, что device = “cuda” был определен выше train_evaluator = create_supervised_evaluator(model, metrics=metrics, device=device) val_evaluator = create_supervised_evaluator(model, metrics=metrics, device=device) Мы создаем два движка для того, чтобы на один из них (val_evaluator) далее прицепить дополнительные обработчики событий для сохранения модели и ранней остановки обучения (обо всем этом далее).
Давайте также более детально рассмотрим, как определен движок для оценки модели, а именно, как определена входная функция process_function для обработки одного батча:
def create_supervised_evaluator(model, metrics={}, device=None): if device: model.to(device) def _inference(engine, batch): model.eval() with torch.no_grad(): x, y = _prepare_batch(batch, device=device) y_pred = model(x) return y_pred, y engine = Engine(_inference) for name, metric in metrics.items(): metric.attach(engine, name) return engineПродолжаем далее. Выберем случайным образом часть обучающей выборки, на которой будем вычислять метрики:
import numpy as np from torch.utils.data.dataset import Subset indices = np.arange(len(train_dataset)) random_indices = np.random.permutation(indices)[:len(val_dataset)] train_subset = Subset(train_dataset, indices=random_indices) train_eval_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device)Далее, давайте определим в какой момент обучения мы будем запускать вычисление метрик и будем производить вывод на экран:
@trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_offline_train_metrics(engine): epoch = engine.state.epoch print("Compute train metrics...") metrics = train_evaluator.run(train_eval_loader).metrics print("Training Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall'])) @trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_val_metrics(engine): epoch = engine.state.epoch print("Compute validation metrics...") metrics = val_evaluator.run(val_loader).metrics print("Validation Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall'])) Можно запускать!
output = trainer.run(train_loader, max_epochs=1)Получаем на экране
Epoch[1] Iteration[50/322] Loss: 3.5112 Epoch[1] Iteration[100/322] Loss: 2.9840 Epoch[1] Iteration[150/322] Loss: 2.8807 Epoch[1] Iteration[200/322] Loss: 2.9285 Epoch[1] Iteration[250/322] Loss: 2.5026 Epoch[1] Iteration[300/322] Loss: 2.1944 Compute train metrics... Training Results - Epoch: 1 Average Loss: 2.1018 | Accuracy: 0.3699 | Precision: 0.3981 | Recall: 0.3686 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 2.0519 | Accuracy: 0.3850 | Precision: 0.3578 | Recall: 0.3845 Уже лучше !
Немного деталей
Давайте немного разберемся в предыдущем коде. Читатель, возможно, обратил внимание на следующую строку кода:
metrics = train_evaluator.run(train_eval_loader).metrics и, вероятно, был вопрос о типе объекта, полученного из функции train_evaluator.run(train_eval_loader), у которого есть атрибут metrics.
На самом деле, у класса Engine содержится структура под названием state (тип State) для того, чтобы была возможность передавать данные между обработчиками событий. Этот атрибут state содержит базовую информацию о текущей эпохе, итерации, о количестве эпох и т.д. Также его можно использовать для передачи любых пользовательских данных, в том числе и результатов расчета метрик.
state = train_evaluator.run(train_eval_loader) metrics = state.metrics # или просто train_evaluator.run(train_eval_loader) metrics = train_evaluator.state.metricsРасчет метрик во время обучения
Если в задаче огромная обучающая выборка и расчет метрик после каждой эпохи обучения стоит дорого, а при этом все же хотелось бы видеть изменение некоторых метрик во время обучения, то можно использовать из коробки следующий обработчик событий RunningAverage. Например, мы хотим рассчитывать и выводить на экран точность классификатора:
acc_metric = RunningAverage(CategoryAccuracy(...), alpha=0.98) acc_metric.attach(trainer, 'running_avg_accuracy') @trainer.on(Events.ITERATION_COMPLETED) def log_running_avg_metrics(engine): print("running avg accuracy:", engine.state.metrics['running_avg_accuracy']) Чтобы использовать функционал RunningAverage, то нужно установить ignite из исходников:
pip install git+https://github.com/pytorch/igniteИзменение скорости обучение (learning rate scheduling)
Есть несколько способов изменять скорость обучения с помощью ignite. Далее рассмотрим самый простой способ, вызывая функцию lr_scheduler.step() в начале каждой эпохи.
from torch.optim.lr_scheduler import ExponentialLR lr_scheduler = ExponentialLR(optimizer, gamma=0.8) @trainer.on(Events.EPOCH_STARTED) def update_lr_scheduler(engine): lr_scheduler.step() # Вывод значений скорости обучения: if len(optimizer.param_groups) == 1: lr = float(optimizer.param_groups[0]['lr']) print("Learning rate: {}".format(lr)) else: for i, param_group in enumerate(optimizer.param_groups): lr = float(param_group['lr']) print("Learning rate (group {}): {}".format(i, lr)) Сохранение лучших моделей и других параметров во время обучения
Во время обучения было бы здорово записывать на диск веса лучшей модели, а также периодически сохранять веса модели, параметры оптимизатора и параметры изменения скорости обучения. Последнее может быть полезно для того, чтобы возобновить обучение из последнего сохраненного состояния.
В ignite для этого есть специальный класс ModelCheckpoint. Итак, давайте создадим обработчик событий ModelCheckpoint и будем сохранять лучшую модель по значению точности на проверочной выборке. В таком случае, определим score_function функцию, которая выдает значение точности в обработчик событий и он решает нужно ли сохранять модель или нет:
from ignite.handlers import ModelCheckpoint def score_function(engine): val_avg_accuracy = engine.state.metrics['avg_accuracy'] return val_avg_accuracy best_model_saver = ModelCheckpoint("best_models", filename_prefix="model", score_name="val_accuracy", score_function=score_function, n_saved=3, save_as_state_dict=True, create_dir=True) # "best_models" - Папка куда сохранять 1 или несколько лучших моделей # Имя файла -> {filename_prefix}_{name}_{step_number}_{score_name}={abs(score_function_result)}.pth # save_as_state_dict=True, # Сохранять как `state_dict` val_evaluator.add_event_handler(Events.COMPLETED, best_model_saver, {"best_model": model}) Теперь создадим еще один обработчик событий ModelCheckpoint для того, чтобы сохранять состояние обучения через каждые 1000 итераций:
training_saver = ModelCheckpoint("checkpoint", filename_prefix="checkpoint", save_interval=1000, n_saved=1, save_as_state_dict=True, create_dir=True) to_save = {"model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler} trainer.add_event_handler(Events.ITERATION_COMPLETED, training_saver, to_save)Итак, уже почти все готово, добавим последний элемент:
Ранняя остановка обучения (early-stopping)
Давайте добавим еще один обработчик событий, который остановит обучение, если не будет происходить улучшение качества модели в течение 10 эпох. Качество модели будем снова оценивать с помощью фунцкии score_function.
from ignite.handlers import EarlyStopping early_stopping = EarlyStopping(patience=10, score_function=score_function, trainer=trainer) val_evaluator.add_event_handler(Events.EPOCH_COMPLETED, early_stopping)Запуск обучения
Для того, чтобы запустить обучение нам достаточно вызвать метод run(). Будем обучать модель в течение 10 эпох:
max_epochs = 10 output = trainer.run(train_loader, max_epochs=max_epochs)Learning rate: 0.01 Epoch[1] Iteration[50/322] Loss: 2.7984 Epoch[1] Iteration[100/322] Loss: 1.9736 Epoch[1] Iteration[150/322] Loss: 4.3419 Epoch[1] Iteration[200/322] Loss: 2.0261 Epoch[1] Iteration[250/322] Loss: 2.1724 Epoch[1] Iteration[300/322] Loss: 2.1599 Compute train metrics... Training Results - Epoch: 1 Average Loss: 1.5363 | Accuracy: 0.5177 | Precision: 0.5477 | Recall: 0.5178 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 1.5116 | Accuracy: 0.5139 | Precision: 0.5400 | Recall: 0.5140 Learning rate: 0.008 Epoch[2] Iteration[50/322] Loss: 1.4076 Epoch[2] Iteration[100/322] Loss: 1.4892 Epoch[2] Iteration[150/322] Loss: 1.2485 Epoch[2] Iteration[200/322] Loss: 1.6511 Epoch[2] Iteration[250/322] Loss: 3.3376 Epoch[2] Iteration[300/322] Loss: 1.3299 Compute train metrics... Training Results - Epoch: 2 Average Loss: 3.2686 | Accuracy: 0.1977 | Precision: 0.1792 | Recall: 0.1942 Compute validation metrics... Validation Results - Epoch: 2 Average Loss: 3.2772 | Accuracy: 0.1962 | Precision: 0.1628 | Recall: 0.1918 Learning rate: 0.006400000000000001 Epoch[3] Iteration[50/322] Loss: 0.9016 Epoch[3] Iteration[100/322] Loss: 1.2006 Epoch[3] Iteration[150/322] Loss: 0.8892 Epoch[3] Iteration[200/322] Loss: 0.8141 Epoch[3] Iteration[250/322] Loss: 1.4005 Epoch[3] Iteration[300/322] Loss: 0.8888 Compute train metrics... Training Results - Epoch: 3 Average Loss: 0.7368 | Accuracy: 0.7554 | Precision: 0.7818 | Recall: 0.7554 Compute validation metrics... Validation Results - Epoch: 3 Average Loss: 0.7177 | Accuracy: 0.7623 | Precision: 0.7863 | Recall: 0.7611 Learning rate: 0.005120000000000001 Epoch[4] Iteration[50/322] Loss: 0.8490 Epoch[4] Iteration[100/322] Loss: 0.8493 Epoch[4] Iteration[150/322] Loss: 0.8100 Epoch[4] Iteration[200/322] Loss: 0.9165 Epoch[4] Iteration[250/322] Loss: 0.9370 Epoch[4] Iteration[300/322] Loss: 0.6548 Compute train metrics... Training Results - Epoch: 4 Average Loss: 0.7047 | Accuracy: 0.7713 | Precision: 0.8040 | Recall: 0.7728 Compute validation metrics... Validation Results - Epoch: 4 Average Loss: 0.6737 | Accuracy: 0.7778 | Precision: 0.7955 | Recall: 0.7806 Learning rate: 0.004096000000000001 Epoch[5] Iteration[50/322] Loss: 0.6965 Epoch[5] Iteration[100/322] Loss: 0.6196 Epoch[5] Iteration[150/322] Loss: 0.6194 Epoch[5] Iteration[200/322] Loss: 0.3986 Epoch[5] Iteration[250/322] Loss: 0.6032 Epoch[5] Iteration[300/322] Loss: 0.7152 Compute train metrics... Training Results - Epoch: 5 Average Loss: 0.5049 | Accuracy: 0.8282 | Precision: 0.8393 | Recall: 0.8314 Compute validation metrics... Validation Results - Epoch: 5 Average Loss: 0.5084 | Accuracy: 0.8304 | Precision: 0.8386 | Recall: 0.8328 Learning rate: 0.0032768000000000007 Epoch[6] Iteration[50/322] Loss: 0.4433 Epoch[6] Iteration[100/322] Loss: 0.4764 Epoch[6] Iteration[150/322] Loss: 0.5578 Epoch[6] Iteration[200/322] Loss: 0.3684 Epoch[6] Iteration[250/322] Loss: 0.4847 Epoch[6] Iteration[300/322] Loss: 0.3811 Compute train metrics... Training Results - Epoch: 6 Average Loss: 0.4383 | Accuracy: 0.8474 | Precision: 0.8618 | Recall: 0.8495 Compute validation metrics... Validation Results - Epoch: 6 Average Loss: 0.4419 | Accuracy: 0.8446 | Precision: 0.8532 | Recall: 0.8442 Learning rate: 0.002621440000000001 Epoch[7] Iteration[50/322] Loss: 0.4447 Epoch[7] Iteration[100/322] Loss: 0.4602 Epoch[7] Iteration[150/322] Loss: 0.5345 Epoch[7] Iteration[200/322] Loss: 0.3973 Epoch[7] Iteration[250/322] Loss: 0.5023 Epoch[7] Iteration[300/322] Loss: 0.5303 Compute train metrics... Training Results - Epoch: 7 Average Loss: 0.4305 | Accuracy: 0.8579 | Precision: 0.8691 | Recall: 0.8596 Compute validation metrics... Validation Results - Epoch: 7 Average Loss: 0.4262 | Accuracy: 0.8590 | Precision: 0.8685 | Recall: 0.8606 Learning rate: 0.002097152000000001 Epoch[8] Iteration[50/322] Loss: 0.4867 Epoch[8] Iteration[100/322] Loss: 0.3090 Epoch[8] Iteration[150/322] Loss: 0.3721 Epoch[8] Iteration[200/322] Loss: 0.4559 Epoch[8] Iteration[250/322] Loss: 0.3958 Epoch[8] Iteration[300/322] Loss: 0.4222 Compute train metrics... Training Results - Epoch: 8 Average Loss: 0.3432 | Accuracy: 0.8818 | Precision: 0.8895 | Recall: 0.8817 Compute validation metrics... Validation Results - Epoch: 8 Average Loss: 0.3644 | Accuracy: 0.8713 | Precision: 0.8784 | Recall: 0.8707 Learning rate: 0.001677721600000001 Epoch[9] Iteration[50/322] Loss: 0.3557 Epoch[9] Iteration[100/322] Loss: 0.3692 Epoch[9] Iteration[150/322] Loss: 0.3510 Epoch[9] Iteration[200/322] Loss: 0.3446 Epoch[9] Iteration[250/322] Loss: 0.3966 Epoch[9] Iteration[300/322] Loss: 0.3451 Compute train metrics... Training Results - Epoch: 9 Average Loss: 0.3315 | Accuracy: 0.8954 | Precision: 0.9001 | Recall: 0.8982 Compute validation metrics... Validation Results - Epoch: 9 Average Loss: 0.3559 | Accuracy: 0.8818 | Precision: 0.8876 | Recall: 0.8847 Learning rate: 0.0013421772800000006 Epoch[10] Iteration[50/322] Loss: 0.3340 Epoch[10] Iteration[100/322] Loss: 0.3370 Epoch[10] Iteration[150/322] Loss: 0.3694 Epoch[10] Iteration[200/322] Loss: 0.3409 Epoch[10] Iteration[250/322] Loss: 0.4420 Epoch[10] Iteration[300/322] Loss: 0.2770 Compute train metrics... Training Results - Epoch: 10 Average Loss: 0.3246 | Accuracy: 0.8921 | Precision: 0.8988 | Recall: 0.8925 Compute validation metrics... Validation Results - Epoch: 10 Average Loss: 0.3536 | Accuracy: 0.8731 | Precision: 0.8785 | Recall: 0.8722Теперь проверим модели и параметры, сохраненные на диск:
ls best_models/ model_best_model_10_val_accuracy=0.8730994.pth model_best_model_8_val_accuracy=0.8712978.pth model_best_model_9_val_accuracy=0.8818188.pthи
ls checkpoint/ checkpoint_lr_scheduler_3000.pth checkpoint_optimizer_3000.pth checkpoint_model_3000.pthПредсказания обученной моделью
Для начала создадим загрузчик тестовых данных (для примера возьмем валидационную выборку) так, чтобы батч данных состоял из изображений и их индексов:
class TestDataset(Dataset): def __init__(self, ds): self.ds = ds def __len__(self): return len(self.ds) def __getitem__(self, index): return self.ds[index][0], index test_dataset = TestDataset(val_dataset) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device) С помощью ignite создадим новый движок для предсказания на тестовых данных. Для этого определим функцию inference_update, которая выдает результат предсказания и индекс изображения. Для повышения точности, мы также будем использовать всем известный трюк “test time augmentation” (TTA).
import torch.nn.functional as F from ignite._utils import convert_tensor def _prepare_batch(batch): x, index = batch x = convert_tensor(x, device=device) return x, index def inference_update(engine, batch): x, indices = _prepare_batch(batch) y_pred = model(x) y_pred = F.softmax(y_pred, dim=1) return {"y_pred": convert_tensor(y_pred, device='cpu'), "indices": indices} model.eval() inferencer = Engine(inference_update) Далее создадим обработчики событий, которые будут оповещать об этапе предсказаний и сохранять предсказания в выделенный массив:
@inferencer.on(Events.EPOCH_COMPLETED) def log_tta(engine): print("TTA {} / {}".format(engine.state.epoch, n_tta)) n_tta = 3 num_classes = 81 n_samples = len(val_dataset) # Массив для хранения предсказаний y_probas_tta = np.zeros((n_samples, num_classes, n_tta), dtype=np.float32) @inferencer.on(Events.ITERATION_COMPLETED) def save_results(engine): output = engine.state.output tta_index = engine.state.epoch - 1 start_index = ((engine.state.iteration - 1) % len(test_loader)) * batch_size end_index = min(start_index + batch_size, n_samples) batch_y_probas = output['y_pred'].detach().numpy() y_probas_tta[start_index:end_index, :, tta_index] = batch_y_probasПрежде чем запустить процесс, давайте загрузим лучшую модель:
model = squeezenet1_1(pretrained=False, num_classes=64) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device) model_state_dict = torch.load("best_models/model_best_model_10_val_accuracy=0.8730994.pth") model.load_state_dict(model_state_dict)Запускаем:
inferencer.run(test_loader, max_epochs=n_tta) > TTA 1 / 3 > TTA 2 / 3 > TTA 3 / 3Далее, стандартным образом, возьмем среднее от предсказаний TTA и вычислим индекс класса с наибольшей вероятностью:
y_probas = np.mean(y_probas_tta, axis=-1) y_preds = np.argmax(y_probas, axis=-1)И теперь можем посчитать еще раз точность модели по полученным предсказаниям:
from sklearn.metrics import accuracy_score y_test_true = [y for _, y in val_dataset] accuracy_score(y_test_true, y_preds) > 0.9310369676443035Итак, в этой части мы показали, как посчитать предсказания с помощью обученной модели на валидационной выборке. На самом деле, пример очень простой, но из него должно быть понятно, каким образом изпользовать ignite для других и более сложных ситуаций.
Другие примеры с ignite
Полный код данного примера можно найти здесь.
В github репозитории библиотеки можно найти и другие примеры обучения сетей для таких задач как
- fast neural transfer
- reinforcement learning
- dcgan
Заключение
В заключении хочу сказать, что библиотека ignite не является официальным продуктом от Facebook и в её разработке принимают участие программисты на добровольной основе (напр. автор этой статьи). На текущий момент она находится в версии 0.1.0, но основной API (Engine, State, Events, Metric, ...) будет по мере возможного оставаться без изменений и в последующих версиях. Поскольку библиотека находится в стадии активной разработки, в том числе и дополнительных модулей, то разработчики будут рады отзывам, сообщениях об ошибках и pull request-ам в репозитории github.
Спасибо за внимание!
Телеграм: t.me/ainewsline
Источник: habr.com