Нейросеть для разработчиков C++
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-10-22 17:28

Написал библиотеку для обучения нейронной сети. Кому интересно, прошу.
Давно хотел сделать себе инструмент такого уровня. C лета взялся за дело. Вот что получилось:
- библиотека написана с нуля на C++ (только STL + OpenBLAS для расчета), C-интерфейс, win/linux;
- cтруктура сети задается в JSON;
- базовые слои: полносвязный, сверточный, пулинг. Дополнительные: resize, crop..;
- базовые фишки: batchNorm, dropout, оптимизаторы весов — adam, adagrad..;
- для расчета на CPU используется OpenBLAS, для видеокарты — CUDA/cuDNN. Заложил еще реализацию на OpenCL, пока на будущее;
- для каждого слоя есть возможность отдельно задать на чем считать — CPU или GPU(и какая именно);
- размер входных данных жестко не задается, может меняться в процессе работы/обучения;
- сделал интерфейсы для C++ и Python. C# тоже будет позже.
Библиотеку назвал «SkyNet». (Сложно все с именами, другие были варианты, но что-то все не то..).
Cравнение с «PyTorch» на примере MNIST:
PyTorch: Accuracy: 98%, Time: 140 sec
SkyNet: Accuracy: 95%, Time: 150 sec
Машина: i5-2300, GF1060. Код теста.
Архитектура ПО
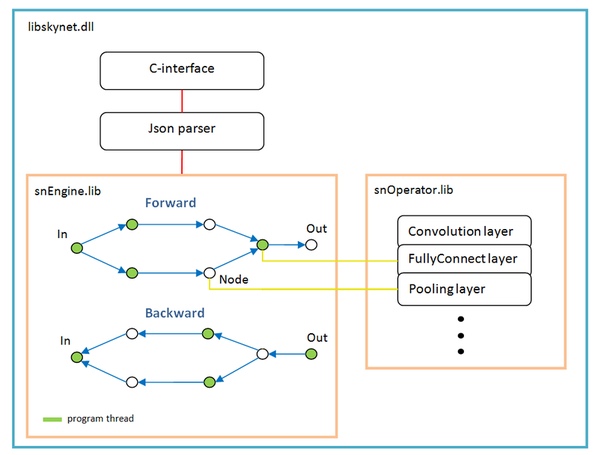
В основе лежит граф операций, создается динамически один раз после разбора структуры сети.
На каждое ветвление — новый поток. Каждый узел сети (Node) — это слой расчета.
Есть особенности работы:
- функция активации, нормализация по батчу, dropout — они все реализованы как параметры конкретных слоев, другими словами, эти функции не существуют как отдельные слои. Возможно batchNorm стоит выделить в отдельный слой, в будущем;
- функция softMax так же не является отдельным слоем, она принадлежит к специальному слою «LossFunction». В котором используется при выборе конкретного типа расчета ошибки;
- слой «LossFunction» используется для автоматического расчета ошибки, те явно можно не использовать шаги forward/backward (ниже пример работы с этим слоем);
- нет слоя «Flatten», он не нужен поскольку слой «FullyConnect» сам вытягивает входной массив;
- оптимизатор весов нужно задавать для каждого весового слоя, по умолчанию 'adam' используется у всех.
Примеры
MNIST

Код на С++ выглядит так:
// создание сети sn::Net snet; snet.addNode("Input", sn::Input(), "C1") .addNode("C1", sn::Convolution(15, 0, sn::calcMode::CUDA), "C2") .addNode("C2", sn::Convolution(15, 0, sn::calcMode::CUDA), "P1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "FC1") .addNode("FC1", sn::FullyConnected(128, sn::calcMode::CUDA), "FC2") .addNode("FC2", sn::FullyConnected(10, sn::calcMode::CUDA), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output"); ............. // получение-подготовка изображений // цикл обучения for (int k = 0; k < 1000; ++k){ targetLayer.clear(); srand(clock()); // заполнение батча for (int i = 0; i < batchSz; ++i){ ............. } // вызов метода обучения сети float accurat = 0; snet.training(lr, inLayer, outLayer, targetLayer, accurat); } Полный код доступен здесь. Немного картинок добавил в репозиторий, находятся рядом с примером. Для чтения изображений использовал opencv, в комплект ее не включал.
Еще одна сеть того же плана, посложнее.
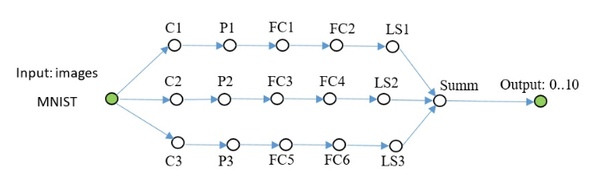
Код для создания такой сети:
// создание сети sn::Net snet; snet.addNode("Input", sn::Input(), "C1 C2 C3") .addNode("C1", sn::Convolution(15, 0, sn::calcMode::CUDA), "P1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "FC1") .addNode("C2", sn::Convolution(12, 0, sn::calcMode::CUDA), "P2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "FC3") .addNode("C3", sn::Convolution(12, 0, sn::calcMode::CUDA), "P3") .addNode("P3", sn::Pooling(sn::calcMode::CUDA), "FC5") .addNode("FC1", sn::FullyConnected(128, sn::calcMode::CUDA), "FC2") .addNode("FC2", sn::FullyConnected(10, sn::calcMode::CUDA), "LS1") .addNode("LS1", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Summ") .addNode("FC3", sn::FullyConnected(128, sn::calcMode::CUDA), "FC4") .addNode("FC4", sn::FullyConnected(10, sn::calcMode::CUDA), "LS2") .addNode("LS2", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Summ") .addNode("FC5", sn::FullyConnected(128, sn::calcMode::CUDA), "FC6") .addNode("FC6", sn::FullyConnected(10, sn::calcMode::CUDA), "LS3") .addNode("LS3", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Summ") .addNode("Summ", sn::Summator(), "Output"); ............. В примерах ее нет, можете скопировать отсюда.
На Python код выглядит также:
// создание сети snet = snNet.Net() snet.addNode("Input", Input(), "C1 C2 C3") .addNode("C1", Convolution(15, 0, calcMode.CUDA), "P1") .addNode("P1", Pooling(calcMode.CUDA), "FC1") .addNode("C2", Convolution(12, 0, calcMode.CUDA), "P2") .addNode("P2", Pooling(calcMode.CUDA), "FC3") .addNode("C3", Convolution(12, 0, calcMode.CUDA), "P3") .addNode("P3", Pooling(calcMode.CUDA), "FC5") .addNode("FC1", FullyConnected(128, calcMode.CUDA), "FC2") .addNode("FC2", FullyConnected(10, calcMode.CUDA), "LS1") .addNode("LS1", LossFunction(lossType.softMaxToCrossEntropy), "Summ") .addNode("FC3", FullyConnected(128, calcMode.CUDA), "FC4") .addNode("FC4", FullyConnected(10, calcMode.CUDA), "LS2") .addNode("LS2", LossFunction(lossType.softMaxToCrossEntropy), "Summ") .addNode("FC5", FullyConnected(128, calcMode.CUDA), "FC6") .addNode("FC6", FullyConnected(10, calcMode.CUDA), "LS3") .addNode("LS3", LossFunction(lossType.softMaxToCrossEntropy), "Summ") .addNode("Summ", LossFunction(lossType.softMaxToCrossEntropy), "Output") ............. CIFAR-10
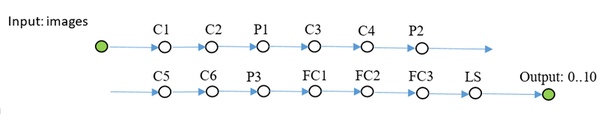
Здесь уже пришлось включить batchNorm. Эта сетка учится до 50% точности в течении 1000 итераций, batch 100.
Код такой получился:
sn::Net snet; snet.addNode("Input", sn::Input(), "C1") .addNode("C1", sn::Convolution(15, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C2") .addNode("C2", sn::Convolution(15, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(25, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C4") .addNode("C4", sn::Convolution(25, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(40, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C6") .addNode("C6", sn::Convolution(40, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P3") .addNode("P3", sn::Pooling(sn::calcMode::CUDA), "FC1") .addNode("FC1", sn::FullyConnected(2048, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC2") .addNode("FC2", sn::FullyConnected(128, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC3") .addNode("FC3", sn::FullyConnected(10, sn::calcMode::CUDA), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output"); Думаю, понятно, что можно подставить любые классы картинок.
U-Net tyni
Последний пример. Упростил нативную U-Net для демонстрации.
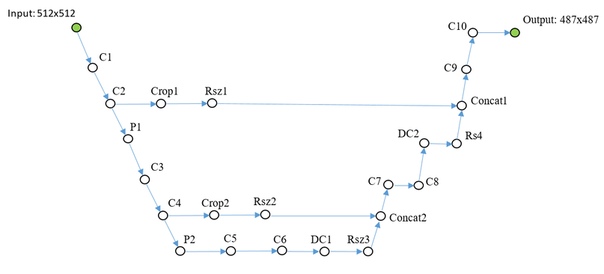
Чуть поясню: слои DC1… — обратная свертка, слои Concat1… — слои сложения каналов, Rsz1… — используются для согласования числа каналов на обратном шаге, поскольку со слоя Concat обратно идет ошибка по сумме каналов.
Код на С++:
sn::Net snet; snet.addNode("In", sn::Input(), "C1") .addNode("C1", sn::Convolution(10, -1, sn::calcMode::CUDA), "C2") .addNode("C2", sn::Convolution(10, 0, sn::calcMode::CUDA), "P1 Crop1") .addNode("Crop1", sn::Crop(sn::rect(0, 0, 487, 487)), "Rsz1") .addNode("Rsz1", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(10, -1, sn::calcMode::CUDA), "C4") .addNode("C4", sn::Convolution(10, 0, sn::calcMode::CUDA), "P2 Crop2") .addNode("Crop2", sn::Crop(sn::rect(0, 0, 247, 247)), "Rsz2") .addNode("Rsz2", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(10, 0, sn::calcMode::CUDA), "C6") .addNode("C6", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC1") .addNode("DC1", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz3") .addNode("Rsz3", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc2") .addNode("Conc2", sn::Concat("Rsz2 Rsz3"), "C7") .addNode("C7", sn::Convolution(10, 0, sn::calcMode::CUDA), "C8") .addNode("C8", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC2") .addNode("DC2", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz4") .addNode("Rsz4", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc1") .addNode("Conc1", sn::Concat("Rsz1 Rsz4"), "C9") .addNode("C9", sn::Convolution(10, 0, sn::calcMode::CUDA), "C10"); sn::Convolution convOut(1, 0, sn::calcMode::CUDA); convOut.act = sn::active::sigmoid; snet.addNode("C10", convOut, "Output"); Полный код и изображения находятся здесь.
Математика из открытых источников типа этого.Все слои тестировал на MNIST, эталоном оценки ошибки служил TF.
Что дальше
Библиотека в ширину расти не будет, то есть никаких opencv, сокетов и тп, чтобы не раздувать.
Интерфейс библиотеки изменяться/расширяться не будет, не скажу что вообще и никогда, но в последнюю очередь.
Только в глубину: сделаю расчет на OpenCL, интерфейс для C#, RNN сеть может быть…
MKL думаю нет смысла добавлять, потому что чуть глубже сеть — быстрее все равно на видеокарте, и карта средней производительности не дефицит совсем.
Импорт/экспорт весов с другими фреймворками — через Python (пока не реализован). Roadmap будет, если интерес возникнет у людей.
Кто может поддержать кодом, прошу. Но есть ограничения, чтобы текущую архитектуру не поломать.
Интерфейс для питона можете расширять до невозможности, так же доки и примеры нужны.
Для установки из Python:
- pip install libskynet — CPU
- pip install libskynet-cu — CPU + CUDA9.2
- pip install libskynet-cudnn — CPU + cuDNN7.3.1
Если сеть у вас не глубокая, используйте реализацию CPU + CUDA, памяти потребляет на порядки меньше по сравнению с cuDNN.
Руководство пользователя wiki.
ПО распространяется свободно, лицензия MIT.
Спасибо.
Телеграм: t.me/ainewsline
Источник: m.vk.com