Линейная регрессия: примеры и вычисление функции потерь
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-10-11 11:19

Линейная регрессия (Linear regression) — модель зависимости переменной x от одной или нескольких других переменных (факторов, регрессоров, независимых переменных) с линейной функцией зависимости.
Линейная регрессия относится к задаче определения «линии наилучшего соответствия» через набор точек данных и стала простым предшественником нелинейных методов, которые используют для обучения нейронных сетей. В этой статье покажем вам примеры линейной регрессии.
Применение линейной регрессии
Предположим, нам задан набор из 7 точек (таблица ниже).
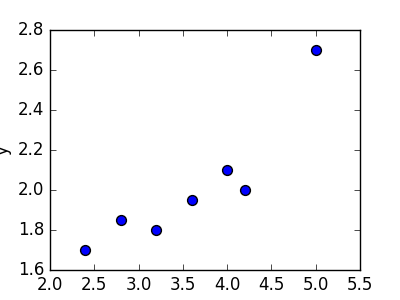
Цель линейной регрессии — поиск линии, которая наилучшим образом соответствует этим точкам. Напомним, что общее уравнение для прямой есть f (x) = m?x + b, где m — наклон линии, а b — его y-сдвиг. Таким образом, решение линейной регрессии определяет значения для m и b, так что f (x) приближается как можно ближе к y. Попробуем несколько случайных кандидатов:
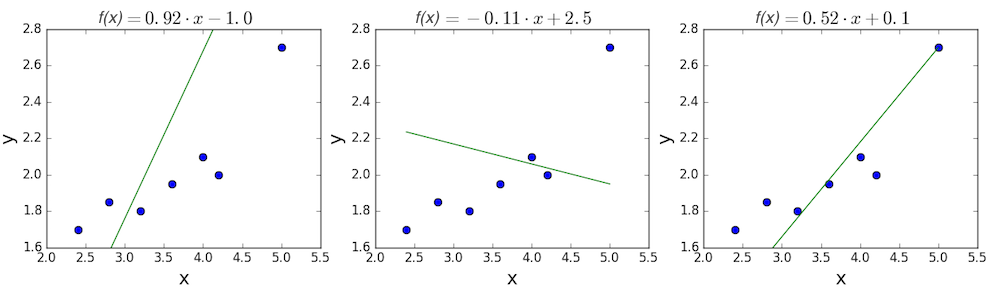
Довольно очевидно, что первые две строки не соответствуют нашим данным. Третья, похоже, лучше, чем две другие. Но как мы можем это проверить? Формально нам нужно выразить, насколько хорошо подходит линия, и мы можем это сделать, определив функцию потерь.
Функция потерь — метод наименьших квадратов
Функция потерь — это мера количества ошибок, которые наша линейная регрессия делает на наборе данных. Хотя есть разные функции потерь, все они вычисляют расстояние между предсказанным значением y(х) и его фактическим значением. Например, взяв строку из среднего примера выше, f(x)=?0.11?x+2.5, мы выделяем дистанцию ошибки между фактическими и прогнозируемыми значениями красными пунктирными линиями.
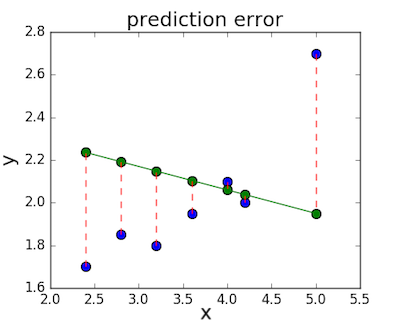
Одна очень распространенная функция потерь называется средней квадратичной ошибкой (MSE). Чтобы вычислить MSE, мы просто берем все значения ошибок, считаем их квадраты длин и усредняем.
Вычислим MSE для каждой из трех функций выше: первая функция дает MSE 0,17, вторая — 0,08, а третья — 0,02. Неудивительно, что третья функция имеет самую низкую MSE, подтверждая нашу догадку, что это линия наилучшего соответствия.
Рассмотрим приведенный ниже рисунок, который использует две визуализации средней квадратичной ошибки в диапазоне, где наклон m находится между -2 и 4, а b между -6 и 8.
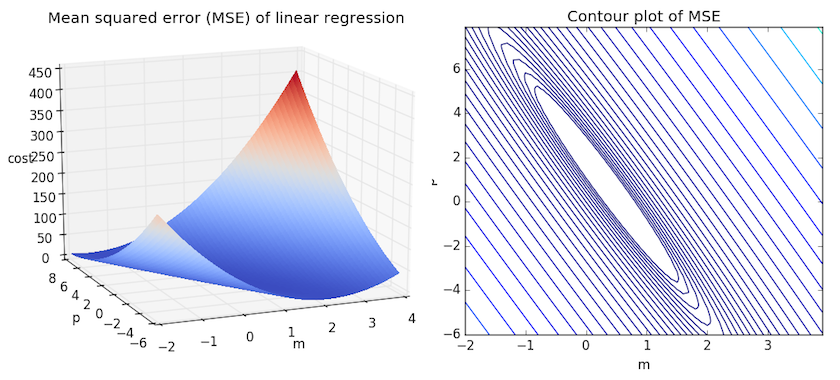
Глядя на два графика, мы видим, что наш MSE имеет форму удлиненной чаши, которая, по-видимому, сглаживается в овале, грубо центрированном по окрестности (m, p) ? (0.5, 1.0). Если мы построим MSE линейной регрессии для другого датасета, то получим аналогичную форму. Поскольку мы пытаемся минимизировать MSE, наша цель — выяснить, где находится самая низкая точка в чаше.
Больше размерностей
Вышеприведенный пример очень простой, он имеет только одну независимую переменную x и два параметра m и b. Что происходит, когда имеется больше переменных? В общем случае, если есть n переменных, их линейная функция может быть записана как:
f(x) = b+w_1*x_1 + … + w_n*x_n Один трюк, который применяют, чтобы упростить это — думать о нашем смещении «b», как о еще одном весе, который всегда умножается на «фиктивное» входное значение 1. Другими словами:
f(x) = b*1+w_1*x_1 + … + w_n*x_n Добавление измерений, на первый взгляд, ужасное усложнение проблемы, но оказывается, постановка задачи остается в точности одинаковой в 2, 3 или в любом количестве измерений. Существует функция потерь, которая выглядит как чаша — гипер-чаша! И, как и прежде, наша цель — найти самую нижнюю часть этой чаши, объективно наименьшее значение, которое функция потерь может иметь в отношении выбора параметров и набора данных.
Итак, как мы вычисляем, где именно эта точка на дне? Распространенный подход — обычный метод наименьших квадратов, который решает его аналитически. Когда есть только один или два параметра для решения, это может быть сделано вручную, и его обычно преподают во вводном курсе по статистике или линейной алгебре.
Проклятие нелинейности
Увы, обычный МНК не используют для оптимизации нейронных сетей, поэтому решение линейной регрессии будет оставлено как упражнение, оставленное читателю. Причина, по которой линейную регрессию не используют, заключается в том, что нейронные сети нелинейны.
Различие между линейными уравнениями, которые мы составили, и нейронной сетью — функция активации (например, сигмоида, tanh, ReLU или других).
Эта нелинейность означает, что параметры не действуют независимо друг от друга, влияя на форму функции потерь. Вместо того, чтобы иметь форму чаши, функция потерь нейронной сети более сложна. Она ухабиста и полна холмов и впадин. Свойство быть «чашеобразной» называется выпуклостью, и это ценное свойство в многопараметрической оптимизации. Выпуклая функция потерь гарантирует, что у нас есть глобальный минимум (нижняя часть чаши), и что все дороги под гору ведут к нему.
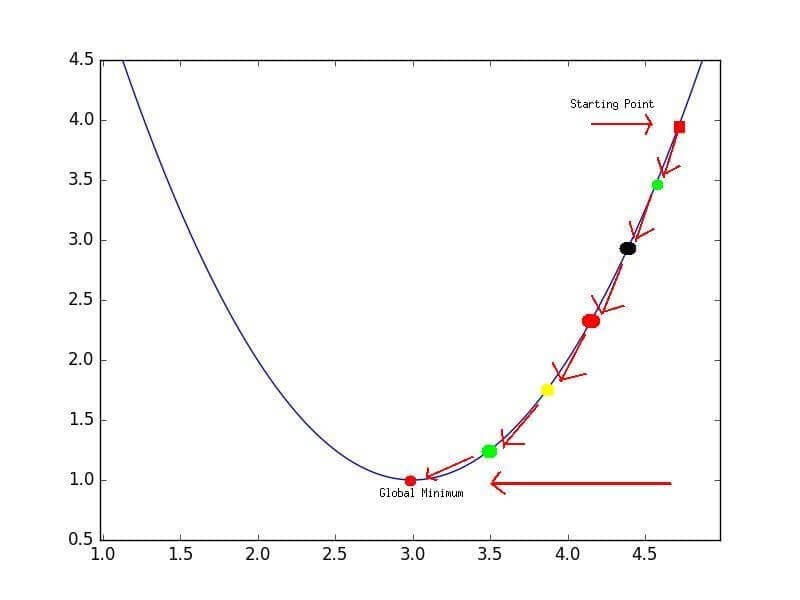
Но, вводя нелинейность, мы теряем это удобство ради того, чтобы дать нейронным сетям гораздо большую «гибкость» при моделировании произвольных функций. Цена, которую мы платим, заключается в том, что больше нет простого способа найти минимум за один шаг аналитически. В этом случае мы вынуждены использовать многошаговый численный метод, чтобы прийти к решению. Хотя существует несколько альтернативных подходов, градиентный спуск остается самым популярным методом.
Телеграм: t.me/ainewsline
Источник: neurohive.io