Языковой барьер и NLP. Почему чат-боты нас не понимают?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-09-20 16:15

С чего все начиналось?
Первые разговоры об обработке естественного языка компьютером начались еще в 30-е годы XX-го века с философских рассуждений Айера — он предлагал отличать разумного человека от глупой машины с помощью эмпирического теста. В 1950 году Алан Тьюринг в философском журнале Mind предложил такой тест, где судья должен определить, с кем он ведет диалог: с человеком или компьютером. С помощью теста задали критерии оценки работы искусственного интеллекта, возможность его построения не подвергали сомнению. Тест имеет множество ограничений и недостатков, но он оказал значительное влияние на развитие чат-ботов.
Первой областью, где успешно применили языковой процессинг, стал машинный перевод. В 1954 году Джорджтаунский университет совместно с компанией IBM продемонстрировали программу машинного перевода с русского на английский, которая работала на базе словаря из 250 слов и набора из 6 грамматических правил. Программа была далека от того, что действительно можно назвать машинным переводом, и на демонстрации перевела 49 заранее отобранных предложений. До середины 60-х было предпринято множество попыток создать полноценно работающую программу-переводчик, но в 1966 году Консультативная комиссия по автоматической обработке языка (англ. ALPAC) объявила машинный перевод бесперспективным направлением. Государственные дотации на какое-то время прекратились, общественный интерес к машинному переводу снизился, однако исследования на этом не остановились.

Язык имеет значение
Сегодня чат-боты по-прежнему работают на основе набора правил и сценариев поведения, однако естественный язык нечеткий и неоднозначный, одна мысль может иметь много способов изложения, поэтому коммерческий успех диалоговых систем зависит от решения задач языкового процессинга. Машину нужно научить четко классифицировать все разнообразие входящих вопросов и четко их интерпретировать.
Все языки устроены по-разному, и это имеет большое значение для парсинга. С точки зрения морфологического состава значимые элементы слова могут присоединяться к корню последовательно, как, например, в тюркских языках, а могут разбивать корень, как в арабском и иврите. С точки зрения синтаксиса одни языки допускают свободный порядок слов во фразе, а другие организованы более жестко. В классических системах порядок слов играет существенную роль. Для современных статистических методов NLP он не имеет такого значения, поскольку обработка происходит не на уровне слов, а целых предложений.
Другие сложности при разработке чат-ботов возникают в связи с развитием мультиязыковой коммуникации. Сейчас люди часто общаются не на родных языках, используют слова неправильно. Например, во фразе «I have shipped two days ago, but goods didn’t come» с точки зрения лексики речь должна идти о доставке физических объектов, например, товаров, а не об электронной денежной транзакции, которую описывает этими словами человек, говорящий не на родном языке. Но в реальном общении человек поймет собеседника верно, а у чат-бота могут возникнуть проблемы. В определенных темах, как например инвестиции, банкинг или IT, люди часто переходят на другие языки. Но чат-бот вряд ли поймет, о чем идет речь, поскольку с большой вероятностью обучен на одном языке.
История успеха: машинные переводчики
До появления голосовых помощников и масштабного распространения чат-ботов наиболее востребованной интеллектуальной задачей, где требовалась обработка естественного языка, был машинный перевод. Разговоры о нейронных сетях и глубоком обучении ходили уже в 90-е годы, а первый нейрокомпьютер «Марк-1» появился вообще в 1958 году. Но повсеместно применять их не было возможности из-за низкой производительности ЭВМ и отсутствия достаточных по объему языковых корпусов. Только крупные научные коллективы могли себе позволить заниматься исследованиями в области нейронных сетей.
Машинные переводчики в середине XX века были далеки от Google Translate и Яндекс.Переводчика, но с каждым новым методом перевода появлялись идеи, которые применяются в том или ином виде даже сегодня.
1970 г. Машинный перевод на основе правил (англ. RBMT) был первой попыткой научить машину переводить. Перевод получался как у пятиклассника со словарем, но в том или ином виде правила для машинного переводчика или чат-бота используют и сейчас.
1984 г. Машинный перевод на основе примеров (англ. EBMT) был способен переводить даже совсем не похожие друг на друга языки, где задавать какие-то правила было бесполезно. Все современные машинные переводчики и чат-боты используют готовые примеры и паттерны.
1990 г. Статистический машинный перевод (англ. SMT) в эпоху развития интернета позволил использовать не только готовые языковые корпуса, но даже книги и вольно переведенные статьи. Большее количество имеющихся данных повышало качество перевода. Статистические методы и сейчас активно используются в языковом процессинге.
Нейронные сети на службе у NLP
По мере развития обработки естественного языка множество задач решалось классическими статистическими методами и множеством правил, однако проблему нечеткости и неоднозначности в языке это не решало. Если мы скажем «лук» без какого-либо контекста, то даже живой собеседник вряд ли поймет, о чем идет речь. Семантику слова в тексте определяют слова-соседи. Но как объяснить это машине, если она понимает только числовое представление? Так родился статистический метод анализа текста word2vec (англ. Word to vector).
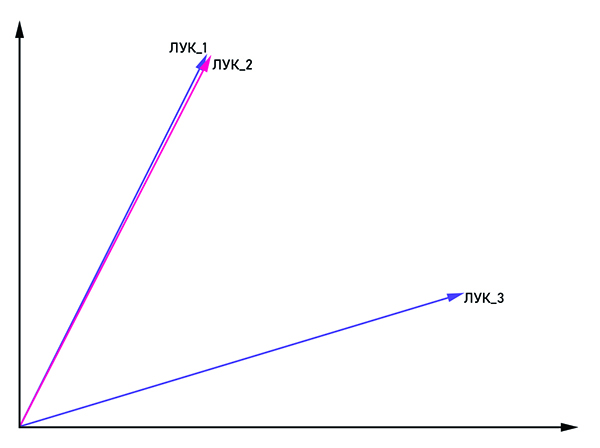
Идея вполне очевидна из названия: представить слово в виде вектора с координатами (x1, x2,...,xn). Для борьбы с омонимией одинаковым словам присоединяется тег: «лук_1», «лук_2» и так далее. Если векторы «лук_n» и «лук_m» параллельны, то их можно считать одним словом. В ином случае эти слова — омонимы. На выходе у каждого слова появляется свое векторное представление в многомерном пространстве (размерность векторного пространства может варьироваться от 50 до 1000).

На сегодняшний день есть огромное множество библиотек для обработки естественного языка. Если говорить о языке Python, который часто используется для анализа данных, то это NLTK и Spacy. Крупные компании также принимают участие в разработке библиотек для NLP, как например NLP Architect от Intel или PyTorch от исследователей из Facebook и Uber. Несмотря на такую большую заинтересованность в нейросетевых методах обработки языка со стороны крупных компаний, связные диалоги строятся в основном на основе классических методов, а нейросеть играет вспомогательную роль, решая задачи предварительной обработки речи и классификации.
Как можно применять NLP в бизнесе?
Самой очевидной сферой применения обработки естественного языка можно назвать машинные переводчики, чат-боты и голосовые ассистенты — то, с чем мы сталкиваемся каждый день. Большую часть сотрудников колл-центра можно заменить на виртуальных помощников, поскольку около 80% обращений клиентов в банки касаются довольно типичных вопросов. Чат-бот также спокойно справится с первичным собеседованием кандидата и запишет его на «живую» встречу. Как ни странно, юриспруденция достаточно точное направление, поэтому даже здесь чат-бот может стать успешным консультантом.

Телеграм: t.me/ainewsline
Источник: habr.com