UFFD - датасет для обнаружения лиц в сложных условиях
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-09-21 15:46

Решение задачи распознавания лица на изображении подразумевает, что сначала нужно обнаружить это лицо. Механизмы детекции лиц улучшилось за последние годы, алгоритмы работают при различающихся масштабах и позах. Тем не менее, некоторые проблемы до сих пор игнорируются в конкретных подходах и датасетах для распознавания лиц.
Группа исследователей, возглавляемя Hajime Nada из Fujitsu, выявила ряд проблем при обнаружении лиц и собрала UFDD датасет, чтобы решить эти проблемы. Датасет включает в себя фотографии в дождь, снег, туман, при слабом освещении и сильно размытые. Кроме того, он также содержит набор дистракторов — изображений, на которых нет лиц, но есть объекты, которые ошибочно принимаются за лица.
Проверим, как современные подходы к обнаружению лиц работают с этим новым сложным датасетом. Виден ли разрыв между качеством работы алгоритмов и требованиями, предъявляемыми к ним? Узнаем прямо сейчас!
Датасеты для обнаружения лиц
Для распознавания лиц было разработано несколько датасетов. В таблице представлены параметры самых популярных используемых из них:
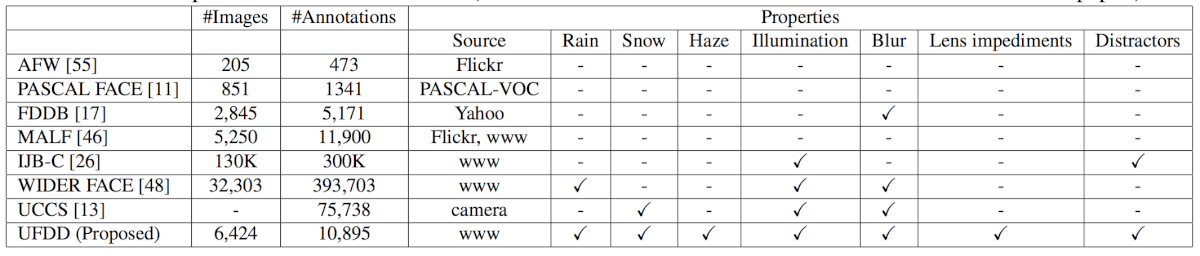
Давайте кратко обсудим некоторые преимущества и недостатки этих датасетов:
- AFW состоит из 205 изображений, собранных на сервисе Flickr. Он содержит 473 вида пометок, включая лицевые лендмарки и ярлыки для разных людей. Различия в стилях и условиях съемки незначительны.
- PASCAL FACE содержит 851 изображение с 1 341 пометкой. Как и в предыдущем датасете, различия в условиях съемки незначительны.
- FDDB — 2 845 изображений с 5 171 пометок. Авторы датасета старались сделать его разнообразным. Однако изображения были взяты из Yahoo! и, в основном, содержат лица знаменитостей.
- MALF — датасет из 5250 изображений и 11 900 пометок. Разработан специально для обработки мелкозернистых изображений.
- IJB-C — большой датасет, содержащий 138 000 изображений с лицами, 11 000 видео и 10 000 изображений без лиц. IJB-C разработан специально для обнаруженияи распознавания лиц.
- WIDER FACE — недавно представленный датасет с более чем 32 300 изображениями. Он включает фотографии с сильно различающимися условиями съемки (масштабом, позой, углом обзора), но не предназначен для учета деградаций, связанных с погодными условиями.
- Датасет UCCS позволяет работать со снимками, сделанными в сложных погодных условиях. Однако изображения собраны с помощью одной камеры наблюдения. Следовательно, этот датасет не представляет многообразие условий съемки.
Несмотря на огромное количество изображений и условий съемки, существующие датасеты не позволяют изучать деградации, связанные с погодными (и другими) условиями, на большой выборке. Именно эту нишу занимает новый датасет.
Датасет UFDD
UFDD включает в себя 6,424 изображения с 10 895 метками. Изображения в нем обладают большой вариабельностью погодных условий (дождь, снег, туман), размытости движений, фокуса, освещения и препятствий на объективе. Количество изображений в группах различных ухудшений приведено в таблице:

Примечательно, что UFDD включает в себя набор изображений-дистракторов, которые обычно отсутствуют в других датасетах. На них либо нет лица, либо есть морды животных. Наличие таких изображений важно для определения эффективности алгоритма и изучения статистики ложно-позитивных срабатываний.
UFDD собран из изображений с Google, Bing, Yahoo, Creative Commons Search, Pixabay, Pixels, Wikimedia commons, Flickr, Unsplash, Vimeo и Baidu. После cбора и удаления дубликатов, изображения были сжаты/растянуты до 1024 пикселей по ширине при сохранении их исходных пропорций.
Для создания пометок изображения загружались в AMT (Amazon Mechanical turk). Для каждого изображения назначалось 5-9 сотрудников, которым было предложено поставить метки распознаваемым лицам. По завершении работы пометки окончательно утверждались и при необходимости объединялись.
Оценка и анализ
Ученые отобрали несколько алгоритмов обнаружения лиц для оценки датасета UFDD. Среди них:
- Faster-RCNN — один из первых сквозных методов обнаружения объектов на основе . Он был выбран в качестве основного алгоритма, так как в нем впервые были использованы anchor boxes — стандартный подход для большинства методов распознавания лиц.
- HR-ER работает с существенно различающимися масштабами, распознавание работает на основе ResNet-101.
- SSH также работает с различными масштабами и состоит из нескольких детекторов на conv-слоях VGG-16.
- S3FD основан на популярной инфраструктуре распознавания объектов, SSD, с VGG-16 в качестве основной сети.
Перечисленные алгоритмы были протестированы на датасете UFDD в двух различных сценариях:
- После предварительного обучения на датасете WIDER FACE;
- После предварительного обучения на датасете WIDER FACE, искусственно дополненном изображениями с ухудшениями, такими как дождь, снег, размытие и препятствия. Пример:

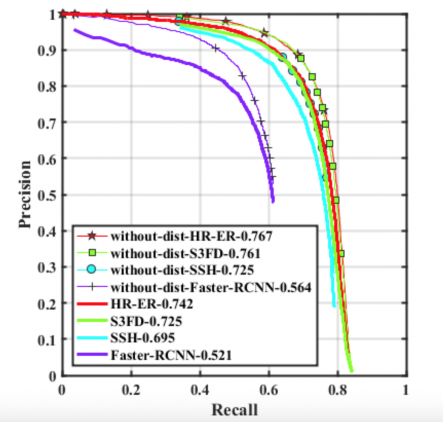
На следующем рисунке приведены зависимости точности алгоритмов от их чувствительности:
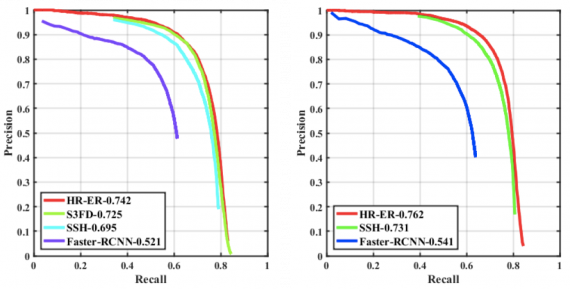
В таблице 3 приведена средняя точность (mAP) алгоритмов в зависимости от тренировочного датасета:
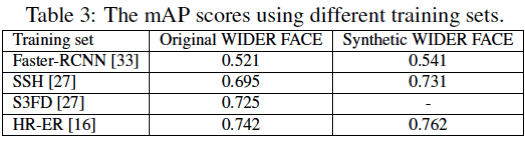
Можно отметить, что современные алгоритмы плохо справляются со сложными типами ухудшений. Однако эффективность обнаружения увеличивается после тренировке на искусственном датасете, что еще раз подтверждает важность датасетов, содержащих деградации (дождь, снег и т. д.).
Анализ по группам
Ученые также проанализировали влияние каждого типа ухудшений на эффективность современных методов обнаружения лиц. Ниже приведены результаты распознавания для всех упомянутых выше алгоритмов:

Графики зависимости точности от чувствительности:
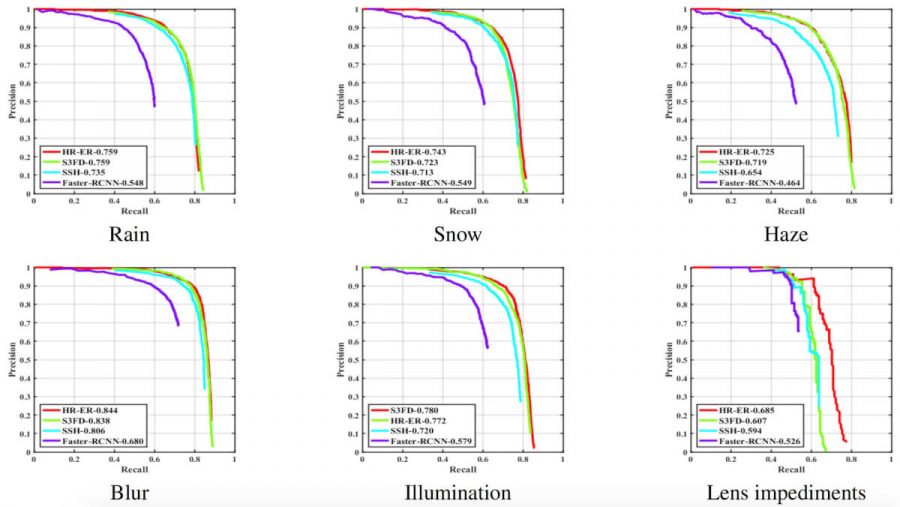
Очевидно, что все рассмотренные типы ухудшений снижают эффективность сравниваемых алгоритмов. Это не удивительно, учитывая, что они обучаются на датасетах, которые обычно не содержат достаточного количества изображений с этими ухудшениями.
Результаты оценки также показывают влияние дистракторов на эффективность алгоритмов распознавания лица. Дистракторы содержат объекты, которые ошибочно принимаются за человеческие лица и, следовательно, приводят к большой вероятности ложно-позитивного срабатывания. Улучшение точности при обучении на дистракторах видно из таблицы:
Несмотря на прогресс в последние несколько лет, алгоритмы обнаружения лиц по-прежнему не справляются с изображениями, сделанными в экстремальных погодных условиях и в движении. Это связано с отсутствием подходящих датасетов для обучения.
Датасет UFDD решает эту проблему. Надеюсь, он будет способствовать дальнейшему развитию техники распознавания лиц, и вскоре мы увидим новые современные подходы, которые могут легко распознавать лица в экстремальных условиях съемки. Датасет доступен по ссылке.
Телеграм: t.me/ainewsline
Источник: neurohive.io