Статьи, лежащие в основе подхода Facebook к компьютерному зрению
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-09-04 18:02
распознавание образов, системы технического зрения, реализация нейронной сети
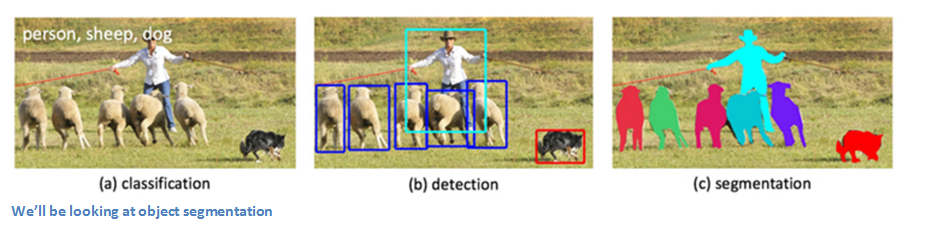
С точки зрения анализа изображений Facebook весьма далеко продвинулся со сверточными нейронными сетями (Convolutional Neural Network, CNN). В августе подразделение Facebook по исследованиям в области искусственного интеллекта (Facebook AI Research, сокращенно FAIR) опубликовала блог-пост об алгоритмах компьютерного зрения, которые лежат в основе некоторых их алгоритмов сегментации изображений. В этом посте мы кратко изложим и разъясним три статьи, на которые ссылается этот блог.
DeepMask
Введение
Эта работа, принадлежащая Педро Пинэйро, Роману Коллоберту и Петру Доллару, называется “Учимся выделять объекты-кандидаты” (“Learning to Segment Object Candidates”). Для решения задачи сегментации изображений авторы предлагают алгоритм, который, получая фрагмент изображения, выводит маску объекта и вероятность того, что в центре фрагмента находится объект целиком. Этот процесс применяется ко всему изображению так, чтобы маска была создана для каждого объекта. Весь процесс осуществляется с помощью всего одной CNN, так как оба компонента используют одни и те же слои сети.
Входные и выходные данные
Для начала изобразим то, что мы ждем от модели. Мы хотим для входного изображения получить набор масок или силуэтов каждого объекта. Можем предcтавить исходное изображение как множество фрагментов. Для каждого входного кусочка на выходе получаем двоичную маску, содержащую силуэт главного объекта на нем, а также оценку того, насколько вероятно, что данный фрагмент содержит объект (от -1 до 1).


Снизу. Примеры обучающих троек: входной фрагмент x, маска m и метка y. Зеленые фрагменты содержат объекты, удовлетворяющие определенным условиям и поэтому помеченные y = 1. Заметьте, что маски из негативных примеров (красных) не используются и показаны только для иллюстрации.
Архитектура сети
Сеть была заранее обучена классификации изображений на базе ImageNet (Transfer Learning в действии). Изображение проходит через VGG-подобную модель (без полносвязных слоев) с восемью сверточными слоями размера 3х3 и пятью слоями maxpool 2х2. В зависимости от размеров исходного изображения, вы получите определенный объем выходных данных (в данном случае, 512х14х14).
Input: 3 x h x w
Output: 512 x h/16 x w/16
Затем сеть разделяется на два компонента, описанных выше. Один из них берет на себя сегментацию, в то время как второй определяет, есть ли на изображении искомый объект.
Компонент сегментации (Segmentation Head)
Теперь берем выходные данные, передаем их через внутренний слой и ReLU слой. Сейчас у нас есть слой из w’ x h’ (где w’ и h’ меньше, чем w и h исходного изображения) классификаторов пикселей, которые определяют, является ли данный пиксель частью объекта в центре изображения (если размер изображения 28х28, то классификаторов будет менее 784). Затем берем выходные значения классификаторов, методом билинейной интерполяции повышаем разрешение изображения до исходного и получаем двоичную маску (1 — если пиксель принадлежит искомому объекту, 0 — если нет).
Компонент “объектности” (Objectness Head)
Второй компонент сети определяет, содержит ли изображение объект нужного масштаба в центре. Передавая выходные данные VGG-подобных слоев через maxpool-слой размерности 2х2, модуль dropout и два полносвязных слоя, мы можем получить нашу вероятностную оценку.
Обучение
Оба компонента сети обучаются параллельно, так как функция потерь — это сумма потерь логистической регрессии (потери Objectness Head плюс потери применения Segmentation Head к каждому фрагменту). Алгоритм обратного распространения ошибки пробегает либо по Objectness Head, либо по Segmentation Head. Для улучшения модели был использован прием расширения обучающего множества (Data Augmentation). Модель обучали методом стохастического градиентного спуска на графическом процессоре Nvidia Tesla K40m в течение пяти дней.
Чем крута эта статья
Одна сверточная нейронная сеть. Нам не понадобился дополнительный шаг генерации гипотез местоположения объекта (object proposals) или какой-либо сложный процесс обучения. Этой модели присуща определенная простота, что обеспечивает гибкость сети, а также эффективность и скорость.
SharpMask
Введение
Предыдущая группа исследователей (совместно с Цунг-Йи Лином) также являются авторами статьи под названием “Учимся улучшать сегменты объектов” (“Learning to Refine Object Segments”). Как видно из названия, эта статья рассказывает об улучшении масок, созданных на этапе DeepMask. Главная проблема DeepMask в том, что эта модель использует простую сеть прямого распространения, которая успешно создает “грубые” маски, но не выполняет сегментацию с точностью до пикселя. Причина этого в том, что, если помните, в DeepMask имеет место билинейная интерполяция, которая служит для подгона под размер исходного изображения. Поэтому соответствие реальным границам очень приблизительно. Чтобы решить эту проблему, модель SharpMask объединяет информацию низкоуровневых характеристик, которую мы получаем от первых слоем сети, с высокоуровневой информацией об объекте, которая приходит от более глубоких слоев. Сначала модель создает грубую маску каждого входного фрагмента (работа DeepMask), а затем передает через несколько уточняющих модулей. Рассмотрим этот этап более детально.

Архитектура сети
Идея SharpMask появилась из следующих соображений: так как для нахождения точной маски объекта нам необходима информация объектного уровня (высокоуровневая), нам необходим нисходящий подход, который вначале строит грубые сегменты, а затем совмещает из с важной низкоуровневой информацией из начальных слоев. Как видно из рисунка выше, исходное изображение вначале проходит через DeepMask для получения грубой сегментации, а затем поступает на вход последовательности уточняющих модулей для более точного увеличения изображения до размеров исходного.
Уточняющий модуль (Refinement module)
Рассмотрим более подробно, как устроен уточняющий модуль. Задача этого модуля — противостоять влиянию слоев подвыборки (pooling layer) на этапе DeepMask (слоев, которые сжали изображение 224x224 до 14x14), увеличивая размерность полученных масок с учетом карт признаков, созданных во время восходящего прохода (мы можем называть DeepMask восходящим проходом, а SharpMask — нисходящим). Говоря языком математики, уточняющий модуль — это функция, которая генерирует расширенную маску М, то есть функция от маски предыдущего слоя и карты признаков F. Количество уточняющих модулей должно равняться количеству слоев подвыборки, используемых в DeepMask.

Обучение
Те же обучающие данные, что использовались для DeepMask, можно применить и для SharpMask. Сначала обучают слои DeepMask. Затем веса замораживают, и начинается обучение SharpMask.
Чем крута эта статья
Эта статья, основываясь на DeepMask, вводит новый, простой в использовании модуль. Авторы открыли, что могут достичь более высокой точности сегментации, просто задействуя низкоуровневую информацию, доступную на более ранних слоях этапа DeepMask.

MultiPathNet
Введение
DeepMask создаеь грубые маски сегментов. SharpMask уточняет контуры объектов. А задача MultiPathNet — идентифицировать или классифицировать объекты в масках. Группа, состоящая из Сергея Загоруйко, Адама Лерера, Ценг-Йи Лина, Педро Пинейро, Сэма Гросса, Сумит Чинтала и Петра Доллара опубликовали статью “Сеть MultiPath для распознавания объектов” (“A MultiPath Network for Object Detection”). Задача этой статьи — улучшить методы распознавания объектов, направив внимание на более точную локализацию, а также на сложные изображения с разными масштабами, большим количеством препятствий и лишних деталей. Эта модель использует Fast R-CNN в качестве отправной точки (см. эту статью или мой предыдущий пост). В сущности, эта модель — реализация Fast R-CNN с генерацией гипотез о местоположении объекта с помощью DeepMask и SharpMask. Три основных изменения, описанных в статье, — форвеальные области (forveal regions), skip connections, интегральная функция потерь (integral loss). Но прежде, чем углубляться, давайте взглянем на архитектуру сети.

Архитектура сети / фовеальные области
Как в Fast R-CNN, мы передает входное изображение через VGG-сеть без полносвязных слоев. ROI pooling слой используется для извлечения признаков из гипотез (region proposals) (как помним из статьи о Fast R-CNN, ROI poling — это метод составления из характеристик изображения карты признаков определенной области изображения). Для каждой гипотезы мы обрезаем изображение четырьмя различными способами, чтобы рассмотреть объект в разных масштабах. Это и есть “фовеальные области”, о которых шла речь во введении. Эти обрезанные фрагменты проходят через полносвязные слои, выходные данные объединяются, а сеть распадается на ветку классификации (classification head) и ветку регрессии (regression head). Авторы предполагают, что это фовеальные области помогут более точно определять местоположение объекта, потому что так сеть сможет видеть объект в различных масштабах и в различном окружении.
Skip Connections
Благодаря Fast R-CNN, после последнего сверточного слоя VGG входное изображение 32х32 будет быстро сжато до размеров 2х2. ROI pooling слой создаст карту 7х7, но мы все равно потеряем много пространственной информации. Чтобы решить эту проблему, мы объединяем признаки из словем conv3, conv4 и conv5, а результат передаем форвеальному классификатору. Как утверждается в статье, это объединение “дает классификатору доступ к информации о признаках из различных областей изображения”.
Интегральная функция потерь
Не хочется углубляться в эту тему, ибо думаю, что вся математика гораздо лучше объясняется в самой статье, но в целом идея в том, что авторы вывели функцию потерь, которая работает лучше с многими значениями Intersection over Union (IoU).
Чем крута эта статья
Если вы поклонник Fast R-CNN, то вам точно понравится эта модель. Она использует основные идеи VGG Net и ROI pooling, в то же время создавая новый способ более точной локализации и классифткации с помощью форвеальных областей, skip connections и интегральной функции потери.
Кажется, Facebook отлично освоил всю эту науку о CNN.
Если вам есть что добавить, или вы можете иначе объяснить какую-либо из статей, дайте знать в комментариях.
Код DeepMask и SharpMask. Код MultuiPathNet. ? Ссылка на оригинал ? Источники
О, а приходите к нам работать? :)wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки. Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь. Присоединяйтесь к нашей команде: wunderfund.io
Телеграм: t.me/ainewsline
Источник: habr.com