Пятую статью курса мы посвятим простым методам композиции: бэггингу и случайному лесу. Вы узнаете, как можно получить распределение среднего по генеральной совокупности, если у нас есть информация только о небольшой ее части; посмотрим, как с помощью композиции алгоритмов уменьшить дисперсию и таким образом улучшить точность модели; разберём, что такое случайный лес, какие его параметры нужно «подкручивать» и как найти самый важный признак. Сконцентрируемся на практике, добавив «щепотку» математики.
UPD: теперь курс — на английском языке под брендом mlcourse.ai со статьями на Medium, а материалами — на Kaggle (Dataset) и на GitHub.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
Из прошлых лекций вы уже узнали про разные алгоритмы классификации, а также научились правильно валидироваться и оценивать качество модели. Но что делать, если вы уже нашли лучшую модель и повысить точность модели больше не можете? В таком случае нужно применить более продвинутые техники машинного обучения, которые можно объединить словом «ансамбли». Ансамбль — это некая совокупность, части которой образуют единое целое. Из повседневной жизни вы знаете музыкальные ансамбли, где объединены несколько музыкальных инструментов, архитектурные ансамбли с разными зданиями и т.д.
Ансамбли
Хорошим примером ансамблей считается теорема Кондорсе «о жюри присяжных» (1784). Если каждый член жюри присяжных имеет независимое мнение, и если вероятность правильного решения члена жюри больше 0.5, то тогда вероятность правильного решения присяжных в целом возрастает с увеличением количества членов жюри и стремится к единице. Если же вероятность быть правым у каждого из членов жюри меньше 0.5, то вероятность принятия правильного решения присяжными в целом монотонно уменьшается и стремится к нулю с увеличением количества присяжных. — количество присяжных — вероятность правильного решения присяжного — вероятность правильного решения всего жюри — минимальное большинство членов жюри, — число сочетаний из по
Если , то Если , то
Давайте рассмотрим ещё один пример ансамблей — "Мудрость толпы". Фрэнсис Гальтон в 1906 году посетил рынок, где проводилась некая лотерея для крестьян. Их собралось около 800 человек, и они пытались угадать вес быка, который стоял перед ними. Бык весил 1198 фунтов. Ни один крестьянин не угадал точный вес быка, но если посчитать среднее от их предсказаний, то получим 1197 фунтов. Эту идею уменьшения ошибки применили и в машинном обучении.
Бутстрэп
Bagging (от Bootstrap aggregation) — это один из первых и самых простых видов ансамблей. Он был придуман Ле?о Бре?йманом в 1994 году. Бэггинг основан на статистическом методе бутстрэпа, который позволяет оценивать многие статистики сложных распределений.
Метод бутстрэпа заключается в следующем. Пусть имеется выборка размера . Равномерно возьмем из выборки объектов с возвращением. Это означает, что мы будем раз выбирать произвольный объект выборки (считаем, что каждый объект «достается» с одинаковой вероятностью ), причем каждый раз мы выбираем из всех исходных объектов. Можно представить себе мешок, из которого достают шарики: выбранный на каком-то шаге шарик возвращается обратно в мешок, и следующий выбор опять делается равновероятно из того же числа шариков. Отметим, что из-за возвращения среди них окажутся повторы. Обозначим новую выборку через . Повторяя процедуру раз, сгенерируем подвыборок . Теперь мы имеем достаточно большое число выборок и можем оценивать различные статистики исходного распределения.
Давайте для примера возьмем уже известный вам набор данных telecom_churn из прошлых уроков нашего курса. Напомним, что это задача бинарной классификации оттока клиентов. Одним из самых важных признаков в этом датасете является количество звонков в сервисный центр, которые были сделаны клиентом. Давайте попробуем визулизировать данные и посмотреть на распределение данного признака.
Код для загрузки данных и построения графика
import pandas as pd from matplotlib import pyplot as plt plt.style.use('ggplot') plt.rcParams['figure.figsize'] = 10, 6 import seaborn as sns %matplotlib inline telecom_data = pd.read_csv('data/telecom_churn.csv') fig = sns.kdeplot(telecom_data[telecom_data['Churn'] == False]['Customer service calls'], label = 'Loyal') fig = sns.kdeplot(telecom_data[telecom_data['Churn'] == True]['Customer service calls'], label = 'Churn') fig.set(xlabel='Количество звонков', ylabel='Плотность') plt.show()
Как вы уже могли заметить, количество звонков в сервисный центр у лояльных клиентов меньше, чем у наших бывших клиентов. Теперь было бы хорошо оценить, сколько в среднем делает звонков каждая из групп. Так как данных в нашем датасете мало, то искать среднее не совсем правильно, лучше применить наши новые знания бутстрэпа. Давайте сгенерируем 1000 новых подвыборок из нашей генеральной совокупности и сделаем интервальную оценку среднего.
Код для построения доверительного интервала с помощью бутстрэпа
import numpy as np def get_bootstrap_samples(data, n_samples): # функция для генерации подвыборок с помощью бутстрэпа indices = np.random.randint(0, len(data), (n_samples, len(data))) samples = data[indices] return samples def stat_intervals(stat, alpha): # функция для интервальной оценки boundaries = np.percentile(stat, [100 * alpha / 2., 100 * (1 - alpha / 2.)]) return boundaries # сохранение в отдельные numpy массивы данных по лояльным и уже бывшим клиентам loyal_calls = telecom_data[telecom_data['Churn'] == False]['Customer service calls'].values churn_calls= telecom_data[telecom_data['Churn'] == True]['Customer service calls'].values # ставим seed для воспроизводимости результатов np.random.seed(0) # генерируем выборки с помощью бутстрэра и сразу считаем по каждой из них среднее loyal_mean_scores = [np.mean(sample) for sample in get_bootstrap_samples(loyal_calls, 1000)] churn_mean_scores = [np.mean(sample) for sample in get_bootstrap_samples(churn_calls, 1000)] # выводим интервальную оценку среднего print("Service calls from loyal: mean interval", stat_intervals(loyal_mean_scores, 0.05)) print("Service calls from churn: mean interval", stat_intervals(churn_mean_scores, 0.05))
В итоге мы получили, что с 95% вероятностью среднее число звонков от лояльных клиентов будет лежать в промежутке между 1.40 и 1.50, в то время как наши бывшие клиенты звонили в среднем от 2.06 до 2.40 раз. Также ещё можно обратить внимание, что интервал для лояльных клиентов уже, что довольно логично, так как они звонят редко (в основном 0, 1 или 2 раза), а недовольные клиенты будут звонить намного чаще, но со временем их терпение закончится, и они поменяют оператора.
Бэггинг
Теперь вы имеете представление о бустрэпе, и мы можем перейти непосредственно к бэггингу. Пусть имеется обучающая выборка . С помощью бутстрэпа сгенерируем из неё выборки . Теперь на каждой выборке обучим свой классификатор . Итоговый классификатор будет усреднять ответы всех этих алгоритмов (в случае классификации это соответствует голосованию): . Эту схему можно представить картинкой ниже.
Рассмотрим задачу регрессии с базовыми алгоритмами . Предположим, что существует истинная функция ответа для всех объектов , а также задано распределение на объектах . В этом случае мы можем записать ошибку каждой функции регрессии
и записать матожидание среднеквадратичной ошибки
Средняя ошибка построенных функций регрессии имеет вид
Предположим, что ошибки несмещены и некоррелированы:
Построим теперь новую функцию регрессии, которая будет усреднять ответы построенных нами функций:
Найдем ее среднеквадратичную ошибку:
Таким образом, усреднение ответов позволило уменьшить средний квадрат ошибки в n раз!
Напомним вам из нашего предыдущего урока, как раскладывается общая ошибка:
Бэггинг позволяет снизить дисперсию (variance) обучаемого классификатора, уменьшая величину, на сколько ошибка будет отличаться, если обучать модель на разных наборах данных, или другими словами, предотвращает переобучение. Эффективность бэггинга достигается благодаря тому, что базовые алгоритмы, обученные по различным подвыборкам, получаются достаточно различными, и их ошибки взаимно компенсируются при голосовании, а также за счёт того, что объекты-выбросы могут не попадать в некоторые обучающие подвыборки.
В библиотеке scikit-learn есть реализации BaggingRegressor и BaggingClassifier, которые позволяют использовать большинство других алгоритмов "внутри". Рассмотрим на практике, как работает бэггинг, и сравним его с деревом решений, пользуясь примером из документации.
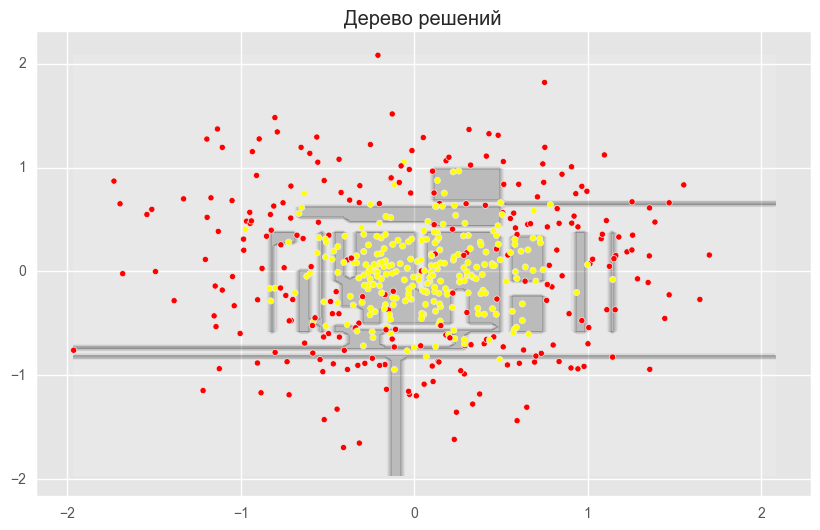
Ошибка дерева решений
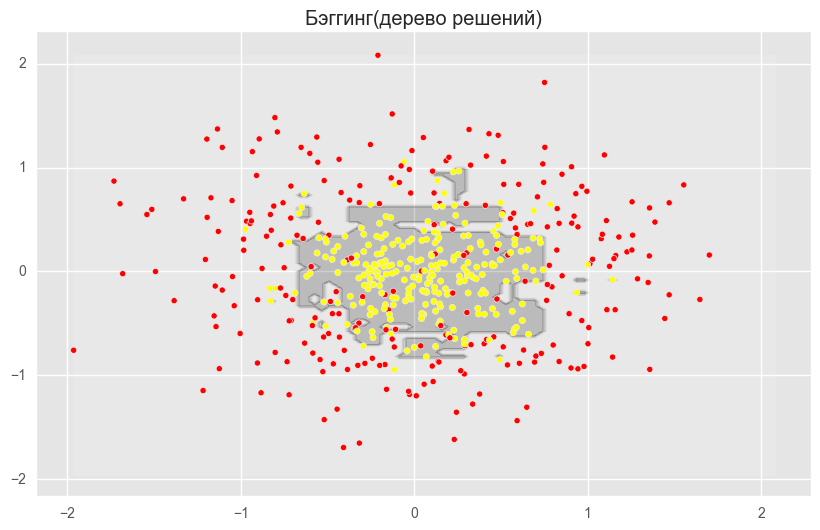
Ошибка бэггинга
По графику и результатам выше видно, что ошибка дисперсии намного меньше при бэггинге, как мы и доказали теоретически выше.
Бэггинг эффективен на малых выборках, когда исключение даже малой части обучающих объектов приводит к построению существенно различных базовых классификаторов. В случае больших выборок обычно генерируют подвыборки существенно меньшей длины.
Следует отметить, что рассмотренный нами пример не очень применим на практике, поскольку мы сделали предположение о некоррелированности ошибок, что редко выполняется. Если это предположение неверно, то уменьшение ошибки оказывается не таким значительным. В следующих лекциях мы рассмотрим более сложные методы объединения алгоритмов в композицию, которые позволяют добиться высокого качества в реальных задачах.
Out-of-bag error
Забегая вперед, отметим, что при использовании случайных лесов нет необходимости в кросс-валидации или в отдельном тестовом наборе, чтобы получить несмещенную оценку ошибки набора тестов. Посмотрим, как получается "внутренняя" оценка модели во время ее обучения.
Каждое дерево строится с использованием разных образцов бутстрэпа из исходных данных. Примерно 37% примеров остаются вне выборки бутстрэпа и не используются при построении k-го дерева.
Это можно легко доказать: пусть в выборке объектов. На каждом шаге все объекты попадают в подвыборку с возвращением равновероятно, т.е отдельный объект — с вероятностью Вероятность того, что объект НЕ попадет в подвыборку (т.е. его не взяли раз): . При получаем один из "замечательных" пределов . Тогда вероятность попадания конкретного объекта в подвыборку .
Давайте рассмотрим, как это работает на практике:
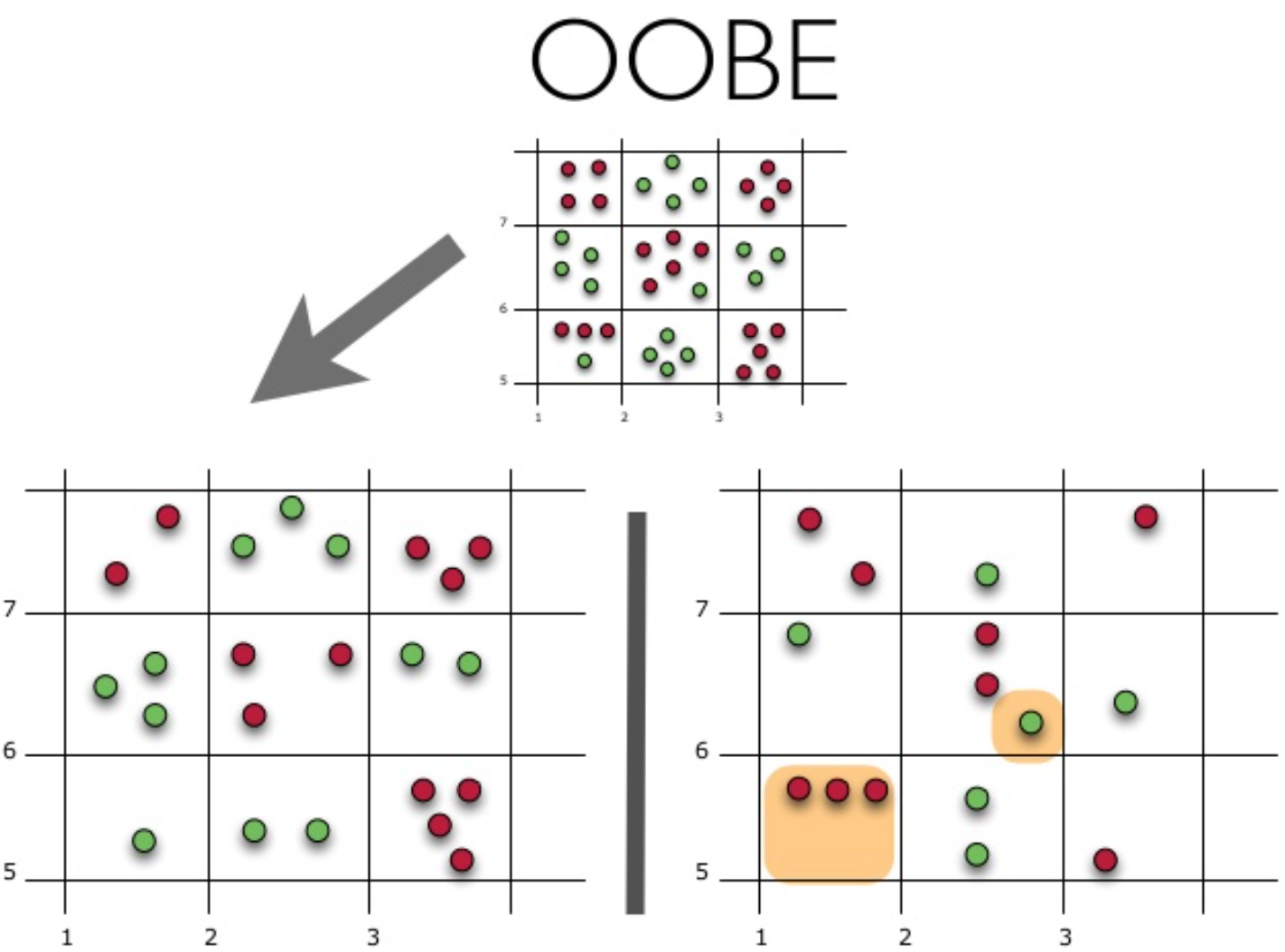
На рисунке изображена оценка oob-ошибки. Верхний рисунок – это наша исходная выборка, ее мы делим на обучающую(слева) и тестовую(справа). На рисунке слева у нас есть сетка из квадратиков, которая идеально разбивает нашу выборку. Теперь нужно оценить долю верных ответов на нашей тестовой выборке. На рисунке видно, что наш классификатор ошибся в 4 наблюдениях, которые мы не использовали для обучения. Значит, доля верных ответов нашего классификатора:
Получается, что каждый базовый алгоритм обучается на ~63% исходных объектов. Значит, на оставшихся ~37% его можно сразу проверять. Out-of-Bag оценка — это усредненная оценка базовых алгоритмов на тех ~37% данных, на которых они не обучались.
2. Случайный лес
Лео Брейман нашел применение бутстрэпу не только в статистике, но и в машинном обучении. Он вместе с Адель Катлер усовершенстовал алгоритм случайного леса, предложенный Хо, добавив к первоначальному варианту построение некоррелируемых деревьев на основе CART, в сочетании с методом случайных подпространств и бэггинга.
Решающие деревья являются хорошим семейством базовых классификаторов для бэггинга, поскольку они достаточно сложны и могут достигать нулевой ошибки на любой выборке. Метод случайных подпространств позволяет снизить коррелированность между деревьями и избежать переобучения. Базовые алгоритмы обучаются на различных подмножествах признакового описания, которые также выделяются случайным образом. Ансамбль моделей, использующих метод случайного подпространства, можно построить, используя следующий алгоритм:
Пусть количество объектов для обучения равно , а количество признаков .
Выберите как число отдельных моделей в ансамбле.
Для каждой отдельной модели выберите как число признаков для . Обычно для всех моделей используется только одно значение .
Для каждой отдельной модели создайте обучающую выборку, выбрав признаков из , и обучите модель.
Теперь, чтобы применить модель ансамбля к новому объекту, объедините результаты отдельных моделей мажоритарным голосованием или путем комбинирования апостериорных вероятностей.
Алгоритм
Алгоритм построения случайного леса, состоящего из деревьев, выглядит следующим образом:
Для каждого :
Сгенерировать выборку с помощью бутстрэпа;
Построить решающее дерево по выборке : — по заданному критерию мы выбираем лучший признак, делаем разбиение в дереве по нему и так до исчерпания выборки — дерево строится, пока в каждом листе не более объектов или пока не достигнем определенной высоты дерева — при каждом разбиении сначала выбирается случайных признаков из исходных, и оптимальное разделение выборки ищется только среди них.
Итоговый классификатор , простыми словами — для задачи кассификации мы выбираем решение голосованием по большинству, а в задаче регрессии — средним.
Рекомендуется в задачах классификации брать , а в задачах регрессии — , где — число признаков. Также рекомендуется в задачах классификации строить каждое дерево до тех пор, пока в каждом листе не окажется по одному объекту, а в задачах регрессии — пока в каждом листе не окажется по пять объектов.
Таким образом, случайный лес — это бэггинг над решающими деревьями, при обучении которых для каждого разбиения признаки выбираются из некоторого случайного подмножества признаков.
Сравнение с деревом решений и бэггингом
Код для сравнения решающего дерева, бэггинга и случайного леса для задачи регрессии
Как мы видим из графиков и значений ошибки MSE, случайный лес из 10 деревьев дает лучший результат, чем одно дерево или бэггинг из 10 деревьев решений. Основное различие случайного леса и бэггинга на деревьях решений заключается в том, что в случайном лесе выбирается случайное подмножество признаков, и лучший признак для разделения узла определяется из подвыборки признаков, в отличие от бэггинга, где все функции рассматриваются для разделения в узле.
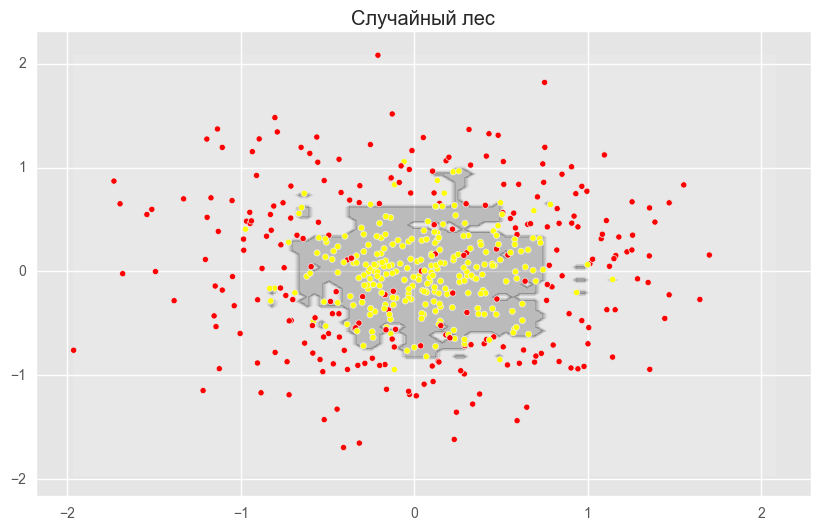
Также можно увидеть преимущество случайного леса и бэггинга в задачах классификации.
Код для сравнения решающего дерева, бэггинга и случайного леса для задачи классификации
На рисунках выше видно, что разделяющая граница дерева решений очень «рваная» и на ней много острых углов, что говорит о переобучении и слабой обобщающей способности. В то время как у бэггинга и случайного леса граница достаточно сглаженная и практически нет признаков переобучения.
Давайте теперь попробуем разобраться с параметрами, с помощью подбора которых мы cможем увеличить долю правильных ответов.
Параметры
Метод случайного леса реализован в библиотеке машинного обучения scikit-learn двумя классами RandomForestClassifier и RandomForestRegressor.
Полный список параметров случайного леса для задачи регрессии:
class sklearn.ensemble.RandomForestRegressor( n_estimators — число деревьев в "лесу" (по дефолту – 10) criterion — функция, которая измеряет качество разбиения ветки дерева (по дефолту — "mse" , так же можно выбрать "mae") max_features — число признаков, по которым ищется разбиение. Вы можете указать конкретное число или процент признаков, либо выбрать из доступных значений: "auto" (все признаки), "sqrt", "log2". По дефолту стоит "auto". max_depth — максимальная глубина дерева (по дефолту глубина не ограничена) min_samples_split — минимальное количество объектов, необходимое для разделения внутреннего узла. Можно задать числом или процентом от общего числа объектов (по дефолту — 2) min_samples_leaf — минимальное число объектов в листе. Можно задать числом или процентом от общего числа объектов (по дефолту — 1) min_weight_fraction_leaf — минимальная взвешенная доля от общей суммы весов (всех входных объектов) должна быть в листе (по дефолту имеют одинаковый вес) max_leaf_nodes — максимальное количество листьев (по дефолту нет ограничения) min_impurity_split — порог для остановки наращивания дерева (по дефолту 1е-7) bootstrap — применять ли бустрэп для построения дерева (по дефолту True) oob_score — использовать ли out-of-bag объекты для оценки R^2 (по дефолту False) n_jobs — количество ядер для построения модели и предсказаний (по дефолту 1, если поставить -1, то будут использоваться все ядра) random_state — начальное значение для генерации случайных чисел (по дефолту его нет, если хотите воспроизводимые результаты, то нужно указать любое число типа int verbose — вывод логов по построению деревьев (по дефолту 0) warm_start — использует уже натренированую модель и добавляет деревьев в ансамбль (по дефолту False) )
Для задачи классификации все почти то же самое, мы приведем только те параметры, которыми RandomForestClassifier отличается от RandomForestRegressor
class sklearn.ensemble.RandomForestClassifier( criterion — поскольку у нас теперь задача классификации, то по дефолту выбран критерий "gini" (можно выбрать "entropy") class_weight — вес каждого класса (по дефолту все веса равны 1, но можно передать словарь с весами, либо явно указать "balanced", тогда веса классов будут равны их исходным частям в генеральной совокупности; также можно указать "balanced_subsample", тогда веса на каждой подвыборке будут меняться в зависимости от распределения классов на этой подвыборке. )
Далее рассмотрим несколько параметров, на которые в первую очередь стоит обратить внимание при построении модели:
n_estimators — число деревьев в "лесу"
criterion — критерий для разбиения выборки в вершине
max_features — число признаков, по которым ищется разбиение
min_samples_leaf — минимальное число объектов в листе
max_depth — максимальная глубина дерева
Рассмотрим применение случайного леса в реальной задаче
Для этого будем использовать пример с задачей оттока клиентов. Это задача классификации, поэтому будем использовать метрику accuracy для оценки качества модели. Для начала построим самый простой классификатор, который будет нашим бейслайном. Возьмем только числовые признаки для упрощения.
Код для построения бейслайна для случайного леса
import pandas as pd from sklearn.model_selection import cross_val_score, StratifiedKFold, GridSearchCV from sklearn.metrics import accuracy_score # Загружаем данные df = pd.read_csv("../../data/telecom_churn.csv") # Выбираем сначала только колонки с числовым типом данных cols = [] for i in df.columns: if (df[i].dtype == "float64") or (df[i].dtype == 'int64'): cols.append(i) # Разделяем на признаки и объекты X, y = df[cols].copy(), np.asarray(df["Churn"],dtype='int8') # Инициализируем страифицированную разбивку нашего датасета для валидации skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) # Инициализируем наш классификатор с дефолтными параметрами rfc = RandomForestClassifier(random_state=42, n_jobs=-1, oob_score=True) # Обучаем на тренировочном датасете results = cross_val_score(rfc, X, y, cv=skf) # Оцениваем долю верных ответов на тестовом датасете print("CV accuracy score: {:.2f}%".format(results.mean()*100))
Получили долю верных ответов 91.21%, теперь попробуем улучшить этот результат и посмотреть, как ведут себя кривые валидации при изменении основных параметров.
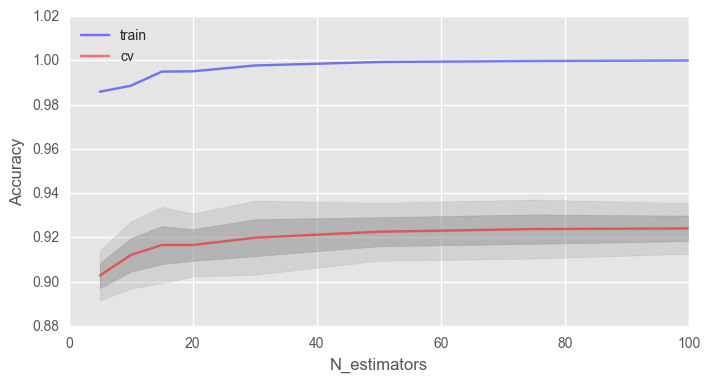
Начнем с количества деревьев:
Код для построения кривых валидации по подбору количества деревьев
# Инициализируем валидацию skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) # Создаем списки для сохранения точности на тренировочном и тестовом датасете train_acc = [] test_acc = [] temp_train_acc = [] temp_test_acc = [] trees_grid = [5, 10, 15, 20, 30, 50, 75, 100] # Обучаем на тренировочном датасете for ntrees in trees_grid: rfc = RandomForestClassifier(n_estimators=ntrees, random_state=42, n_jobs=-1, oob_score=True) temp_train_acc = [] temp_test_acc = [] for train_index, test_index in skf.split(X, y): X_train, X_test = X.iloc[train_index], X.iloc[test_index] y_train, y_test = y[train_index], y[test_index] rfc.fit(X_train, y_train) temp_train_acc.append(rfc.score(X_train, y_train)) temp_test_acc.append(rfc.score(X_test, y_test)) train_acc.append(temp_train_acc) test_acc.append(temp_test_acc) train_acc, test_acc = np.asarray(train_acc), np.asarray(test_acc) print("Best accuracy on CV is {:.2f}% with {} trees".format(max(test_acc.mean(axis=1))*100, trees_grid[np.argmax(test_acc.mean(axis=1))]))
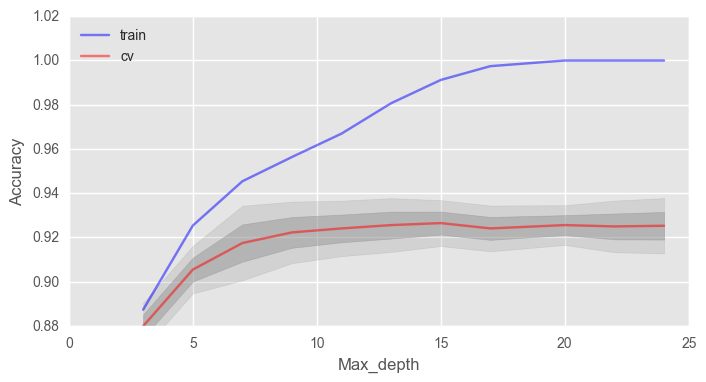
Как видно, при достижении определенного числа деревьев наша долья верных ответов на тесте выходит на асимптоту, и вы можете сами решить, сколько деревьев оптимально для вашей задачи. На рисунке также видно, что на тренировочной выборке мы смогли достичь 100% точности, это говорит нам о переобучении нашей модели. Чтобы избежать переобучения, мы должны добавить параметры регуляризации в модель.
Параметр max_depth хорошо справляется с регуляризацией модели, и мы уже не так сильно переобучаемся. Долья верных ответов нашей модели немного возросла.
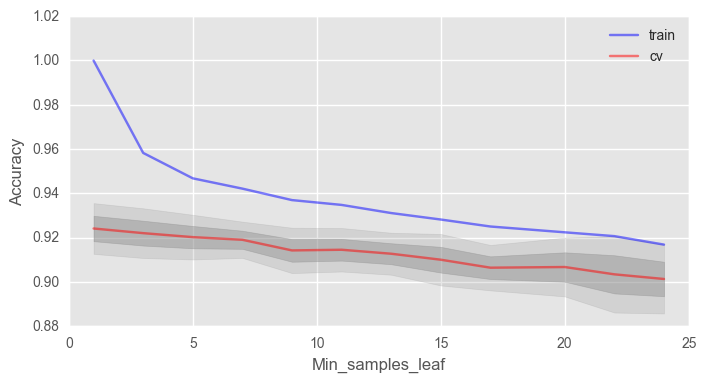
Еще важный параметр min_samples_leaf, он также выполняет функцию регуляризатора.
Код для построения кривых валидации по подбору минимального числа объектов в одном листе дерева
# Создаем списки для сохранения точности на тренировочном и тестовом датасете train_acc = [] test_acc = [] temp_train_acc = [] temp_test_acc = [] min_samples_leaf_grid = [1, 3, 5, 7, 9, 11, 13, 15, 17, 20, 22, 24] # Обучаем на тренировочном датасете for min_samples_leaf in min_samples_leaf_grid: rfc = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1, oob_score=True, min_samples_leaf=min_samples_leaf) temp_train_acc = [] temp_test_acc = [] for train_index, test_index in skf.split(X, y): X_train, X_test = X.iloc[train_index], X.iloc[test_index] y_train, y_test = y[train_index], y[test_index] rfc.fit(X_train, y_train) temp_train_acc.append(rfc.score(X_train, y_train)) temp_test_acc.append(rfc.score(X_test, y_test)) train_acc.append(temp_train_acc) test_acc.append(temp_test_acc) train_acc, test_acc = np.asarray(train_acc), np.asarray(test_acc) print("Best accuracy on CV is {:.2f}% with {} min_samples_leaf".format(max(test_acc.mean(axis=1))*100, min_samples_leaf_grid[np.argmax(test_acc.mean(axis=1))]))
В данном случае мы не выигрываем в точности на валидации, но зато можем сильно уменьшить переобучение до 2% при сохранении точности около 92%.
Рассмотрим такой параметр как max_features. Для задач классификации по умолчанию используется , где n — число признаков. Давайте проверим, оптимально ли в нашем случае использовать 4 признака или нет.
Код для построения кривых валидации по подбору максимального количества признаков для одного дерева
# Создаем списки для сохранения точности на тренировочном и тестовом датасете train_acc = [] test_acc = [] temp_train_acc = [] temp_test_acc = [] max_features_grid = [2, 4, 6, 8, 10, 12, 14, 16] # Обучаем на тренировочном датасете for max_features in max_features_grid: rfc = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1, oob_score=True, max_features=max_features) temp_train_acc = [] temp_test_acc = [] for train_index, test_index in skf.split(X, y): X_train, X_test = X.iloc[train_index], X.iloc[test_index] y_train, y_test = y[train_index], y[test_index] rfc.fit(X_train, y_train) temp_train_acc.append(rfc.score(X_train, y_train)) temp_test_acc.append(rfc.score(X_test, y_test)) train_acc.append(temp_train_acc) test_acc.append(temp_test_acc) train_acc, test_acc = np.asarray(train_acc), np.asarray(test_acc) print("Best accuracy on CV is {:.2f}% with {} max_features".format(max(test_acc.mean(axis=1))*100, max_features_grid[np.argmax(test_acc.mean(axis=1))]))
В нашем случае оптимальное число признаков — 10, именно с таким значением достигается наилучший результат.
Мы рассмотрели, как ведут себя кривые валидации в зависимости от изменения основных параметров. Давайте теперь с помощью GridSearchCV найдем оптимальные параметры для нашего примера.
Код для подбора оптимальных параметров модели
# Сделаем инициализацию параметров, по которым хотим сделать полный перебор parameters = {'max_features': [4, 7, 10, 13], 'min_samples_leaf': [1, 3, 5, 7], 'max_depth': [5,10,15,20]} rfc = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1, oob_score=True) gcv = GridSearchCV(rfc, parameters, n_jobs=-1, cv=skf, verbose=1) gcv.fit(X, y)
Лучшая доля верных ответов, который мы смогли достичь с помощью перебора параметров — 92.83% при 'max_depth': 15, 'max_features': 7, 'min_samples_leaf': 3.
Вариация и декорреляционный эффект
Давайте запишем дисперсию для случайного леса как
Тут
– корреляция выборки между любыми двумя деревьями, используемыми при усреднении
где и – случайно выбранная пара деревьев на случайно выбранных объектах выборки — это выборочная дисперсия любого произвольно выбранного дерева:
Легко спутать со средней корреляцией между обученными деревьями в данном случайном лесе, рассматривая деревья как N-векторы и вычисляя среднюю парную корреляцию между ними. Это не тот случай. Эта условная корреляция не имеет прямого отношения к процессу усреднения, а зависимость от в предупреждает нас об этом различии. Скорее является теоретической корреляцией между парой случайных деревьев, оцененных в объекте , которая была вызвана многократным сэмплированием обучающей выборки из генеральной совокупности , и после этого выбрана данная пара случайных деревьев. На статистическом жаргоне это корреляция, вызванная выборочным распределением и .
По факту, условная ковариация пары деревьев равна 0, потому что бустрэп и отбор признаков — независимы и одинаково распределены.
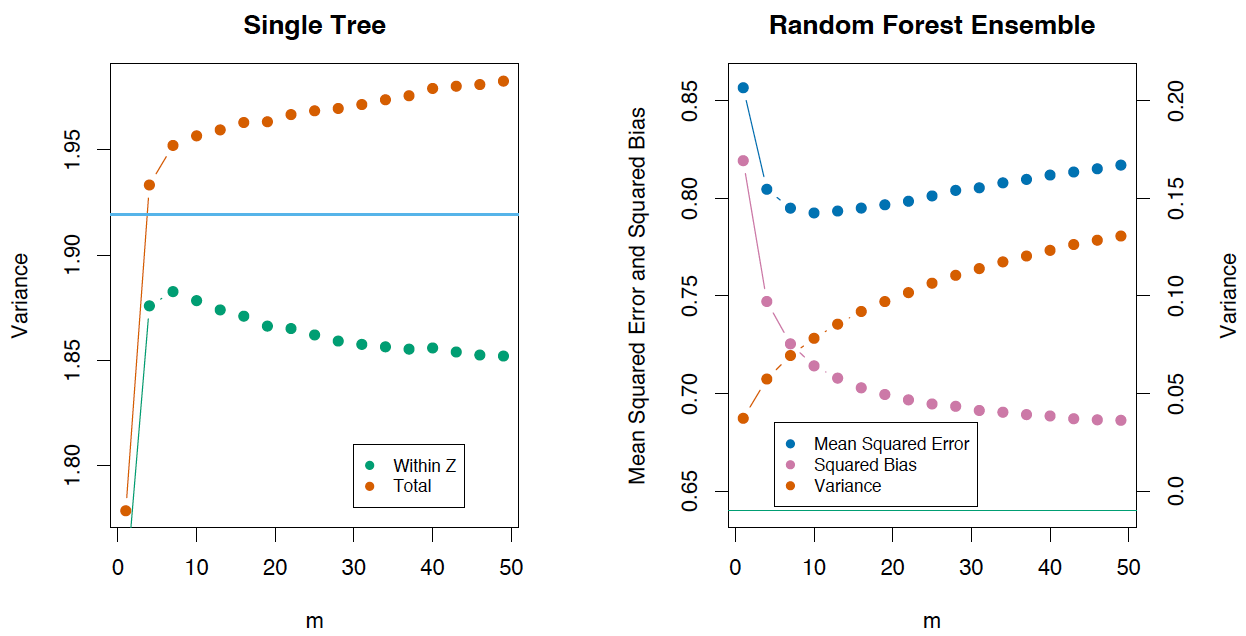
Если рассмотреть дисперсию по одному дереву, то она практически не меняется от переменных для разделения (), а вот для ансамбля это играет большую роль, и дисперсия для дерева намного выше, чем для ансамбля. В книге The Elements of Statistical Learning (Trevor Hastie, Robert Tibshirani и Jerome Friedman) есть отличный пример, который это демонстрирует.
Смещение
Как и в бэггинге, смещение в случайном лесе такое же, как и смещение в отдельно взятом дереве :
Это также обычно больше (в абсолютных величинах), чем смещение «неусеченного» (unprunned) дерева, поскольку рандомизация и сокращение пространства выборки налагают ограничения. Следовательно, улучшения в прогнозировании, полученные с помощью бэггинга или случайных лесов, являются исключительно результатом уменьшения дисперсии.
Сверхслучайные деревья
В сверхслучайных деревьях (Extremely Randomized Trees) больше случайности в том, как вычисляются разделения в узлах. Как и в случайных лесах, используется случайное подмножество возможных признаков, но вместо поиска наиболее оптимальных порогов, пороговые значения произвольно выбираются для каждого возможного признака, и наилучший из этих случайно генерируемых порогов выбирается как лучшее правило для разделения узла. Это обычно позволяет немного уменьшить дисперсию модели за счет несколько большего увеличения смещения.
В библиотеке scikit-learn есть реализация ExtraTreesClassifier и ExtraTreesRegressor. Данный метод стоит использовать, когда вы сильно переобучаетесь на случайном лесе или градиентном бустинге.
Схожесть случайного леса с алгоритмом k-ближайших соседей
Метод случайного леса схож с методом ближайших соседей. Случайные леса, по сути, осуществляют предсказания для объектов на основе меток похожих объектов из обучения. Схожесть объектов при этом тем выше, чем чаще эти объекты оказываются в одном и том же листе дерева. Покажем это формально.
Рассмотрим задачу регрессии с квадратичной функцией потерь. Пусть — номер листа -го дерева из случайного леса, в который попадает объект . Ответ объекта равен среднему ответу по всем объектам обучающей выборки, которые попали в этот лист . Это можно записать так
где
Тогда ответ композиции равен
Видно, что ответ случайного леса представляет собой сумму ответов всех объектов обучения с некоторыми весами. Отметим, что номер листа , в который попал объект, сам по себе является ценным признаком. Достаточно неплохо работает подход, в котором по выборке обучается композиция из небольшого числа деревьев с помощью случайного леса или градиентного бустинга, а потом к ней добавляются категориальные признаки . Новые признаки являются результатом нелинейного разбиения пространства и несут в себе информацию о сходстве объектов.
Все в той же книге The Elements of Statistical Learning есть хороший наглядный пример сходства случайного леса и k-ближайших соседей.
Преобразование признаков в многомерное пространство
Все привыкли использовать случайный лес для задач обучения с учителем, но также есть возможность проводить обучение и без учителя. С помощью метода RandomTreesEmbedding мы можем сделать трансформацию нашего датасета в многомерное разреженное его представление. Его суть в том, что мы строим абсолютно случайные деревья, и индекс листа, в котором оказалось наблюдение, мы считаем за новый признак. Если в первый лист попал объект, то мы ставим 1, а если не попал, то 0. Так называемое бинарное кодирование. Контролировать количество переменных и также степень разреженности нашего нового представления датасета мы можем увеличивая/уменьшая количество деревьев и их глубины. Поскольку соседние точки данных скорее всего лежат в одном и том же листе дерева, преобразование выполняет неявную, непараметрическую оценку плотности.
3. Оценка важности признаков
Очень часто вы хотите понять свой алгоритм, почему он именно так, а не иначе дал определенный ответ. Или если не понять его полностью, то хотя бы какие переменные больше всего влияют на результат. Из случайного леса можно довольно просто получить данную информацию.
Суть метода
По данной картинке интуитивно понятно, что важность признака «Возраст» в задаче кредитного скоринга выше, чем важность признака «Доход». Формализуется это с помощью понятия прироста информации.
Если построить много деревьев решений (случайный лес), то чем выше в среднем признак в дереве решений, тем он важнее в данной задаче классификации/регрессии. При каждом разбиении в каждом дереве улучшение критерия разделения (в нашем случае неопределенность Джини(Gini impurity)) — это показатель важности, связанный с переменной разделения, и накапливается он по всем деревьям леса отдельно для каждой переменной.
Давайте немного углубимся в детали. Среднее снижение точности, вызываемое переменной, определяется во время фазы вычисления out-of-bag ошибки. Чем больше уменьшается точность предсказаний из-за исключения (или перестановки) одной переменной, тем важнее эта переменная, и поэтому переменные с бо?льшим средним уменьшением точности более важны для классификации данных. Среднее уменьшение неопределенности Джини (или ошибки mse в задачах регрессии) является мерой того, как каждая переменная способствует однородности узлов и листьев в окончательной модели случайного леса. Каждый раз, когда отдельная переменная используется для разбиения узла, неопределенность Джини для дочерних узлов рассчитывается и сравнивается с коэффициентом исходного узла. Неопределенность Джини является мерой однородности от 0 (однородной) до 1 (гетерогенной). Изменения в значении критерия разделения суммируются для каждой переменной и нормируются в конце вычисления. Переменные, которые приводят к узлам с более высокой чистотой, имеют более высокое снижение коэффициента Джини.
А теперь представим все вышеописанное в виде формул.
— предсказание класса перед перестановкой/удалением признака — предсказание класса после перестановки/удаления признака Заметим, что , если не находится в дереве
Расчет важности признаков в ансамбле: — ненормированные
— нормированные
Пример
Рассмотрим результаты анкетирования посетителей хостелов с сайтов Booking.com и TripAdvisor.com. Признаки — средние оценки по разным факторам (перечислены ниже) — персонал, состояние комнат и т.д. Целевой признак — рейтинг хостела на сайте.
Код для оценки важности признаков
from __future__ import division, print_function # отключим всякие предупреждения Anaconda import warnings warnings.filterwarnings('ignore') %pylab inline import seaborn as sns # russian headres from matplotlib import rc font = {'family': 'Verdana', 'weight': 'normal'} rc('font', **font) import pandas as pd import numpy as np from sklearn.ensemble.forest import RandomForestRegressor hostel_data = pd.read_csv("../../data/hostel_factors.csv") features = {"f1":u"Персонал", "f2":u"Бронирование хостела ", "f3":u"Заезд в хостел и выезд из хостела", "f4":u"Состояние комнаты", "f5":u"Состояние общей кухни", "f6":u"Состояние общего пространства", "f7":u"Дополнительные услуги", "f8":u"Общие условия и удобства", "f9":u"Цена/качество", "f10":u"ССЦ"} forest = RandomForestRegressor(n_estimators=1000, max_features=10, random_state=0) forest.fit(hostel_data.drop(['hostel', 'rating'], axis=1), hostel_data['rating']) importances = forest.feature_importances_ indices = np.argsort(importances)[::-1] # Plot the feature importancies of the forest num_to_plot = 10 feature_indices = [ind+1 for ind in indices[:num_to_plot]] # Print the feature ranking print("Feature ranking:") for f in range(num_to_plot): print("%d. %s %f " % (f + 1, features["f"+str(feature_indices[f])], importances[indices[f]])) plt.figure(figsize=(15,5)) plt.title(u"Важность конструктов") bars = plt.bar(range(num_to_plot), importances[indices[:num_to_plot]], color=([str(i/float(num_to_plot+1)) for i in range(num_to_plot)]), align="center") ticks = plt.xticks(range(num_to_plot), feature_indices) plt.xlim([-1, num_to_plot]) plt.legend(bars, [u''.join(features["f"+str(i)]) for i in feature_indices]);
На рисунке выше видно, что люди больше всего обращают внимание на персонал и соотношение цена/качество и на основе впечатления от данных вещей пишут свои отзывы. Но разница между этими признаками и менее влиятельными признаками не очень значительная, и выкидывание какого-то признака приведет к уменьшению точности нашей модели. Но даже на основе нашего анализа мы можем дать рекомендации отелям в первую очередь лучше готовить персонал и/или улучшить качество до заявленной цены.
4. Плюсы и минусы случайного леса
Плюсы: — имеет высокую точность предсказания, на большинстве задач будет лучше линейных алгоритмов; точность сравнима с точностью бустинга — практически не чувствителен к выбросам в данных из-за случайного сэмлирования — не чувствителен к масштабированию (и вообще к любым монотонным преобразованиям) значений признаков, связано с выбором случайных подпространств — не требует тщательной настройки параметров, хорошо работает «из коробки». С помощью «тюнинга» параметров можно достичь прироста от 0.5 до 3% точности в зависимости от задачи и данных — способен эффективно обрабатывать данные с большим числом признаков и классов — одинаково хорошо обрабатывет как непрерывные, так и дискретные признаки — редко переобучается, на практике добавление деревьев почти всегда только улучшает композицию, но на валидации, после достижения определенного количества деревьев, кривая обучения выходит на асимптоту — для случайного леса существуют методы оценивания значимости отдельных признаков в модели — хорошо работает с пропущенными данными; сохраняет хорошую точность, если большая часть данных пропущенна — предполагает возможность сбалансировать вес каждого класса на всей выборке, либо на подвыборке каждого дерева — вычисляет близость между парами объектов, которые могут использоваться при кластеризации, обнаружении выбросов или (путем масштабирования) дают интересные представления данных — возможности, описанные выше, могут быть расширены до неразмеченных данных, что приводит к возможности делать кластеризацию и визуализацию данных, обнаруживать выбросы — высокая параллелизуемость и масштабируемость.
Минусы: — в отличие от одного дерева, результаты случайного леса сложнее интерпретировать — нет формальных выводов (p-values), доступных для оценки важности переменных — алгоритм работает хуже многих линейных методов, когда в выборке очень много разреженных признаков (тексты, Bag of words) — случайный лес не умеет экстраполировать, в отличие от той же линейной регрессии (но это можно считать и плюсом, так как не будет экстремальных значений в случае попадания выброса) — алгоритм склонен к переобучению на некоторых задачах, особенно на зашумленных данных — для данных, включающих категориальные переменные с различным количеством уровней, случайные леса предвзяты в пользу признаков с большим количеством уровней: когда у признака много уровней, дерево будет сильнее подстраиваться именно под эти признаки, так как на них можно получить более высокое значение оптимизируемого функционала (типа прироста информации) — если данные содержат группы коррелированных признаков, имеющих схожую значимость для меток, то предпочтение отдается небольшим группам перед большими — больший размер получающихся моделей. Требуется памяти для хранения модели, где — число деревьев.
5. Домашнее задание
Актуальные домашние задания объявляются во время очередной сессии курса, следить можно в группе ВК и в репозитории курса.
В качестве закрепления материала предлагаем выполнить это задание – разобраться с бэггингом и обучить модели случайного леса и логистической регрессии для решения задачи кредитного скоринга. Проверить себя можно отправив ответы в веб-форме (там же найдете и решение).
6. Полезные источники
– Open Machine Learning Course. Topic 5. Bagging and Random Forest (перевод этой статьи на английский) – Видеозапись лекции по мотивам этой статьи – 15 раздел книги “Elements of Statistical Learning” Jerome H. Friedman, Robert Tibshirani, and Trevor Hastie – Блог Александра Дьяконова – Больше про практические применение случайного леса и других алгоритмов-композиций в официальной документации scikit-learn – Курс Евгения Соколова по машинному обучению (материалы на GitHub). Есть дополнительные практические задания для углубления ваших знаний – Обзорная статья "История развития ансамблевых методов классификации в машинном обучении" (Ю. Кашницкий)
Статья написана в соавторстве с yorko (Юрием Кашницким). Автор домашнего задания – vradchenko (Виталий Радченко). Благодарю bauchgefuehl (Анастасию Манохину) за редактирование.

 — количество присяжных
— количество присяжных — вероятность правильного решения присяжного
— вероятность правильного решения присяжного — вероятность правильного решения всего жюри
— вероятность правильного решения всего жюри — минимальное большинство членов жюри,
— минимальное большинство членов жюри, 
 — число сочетаний из
— число сочетаний из  по
по 

 , то
, то 
 , то
, то 

 размера
размера  ), причем каждый раз мы выбираем из всех исходных
), причем каждый раз мы выбираем из всех исходных  . Повторяя процедуру
. Повторяя процедуру  раз, сгенерируем
раз, сгенерируем  . Теперь мы имеем достаточно большое число выборок и можем оценивать различные статистики исходного распределения.
. Теперь мы имеем достаточно большое число выборок и можем оценивать различные статистики исходного распределения. 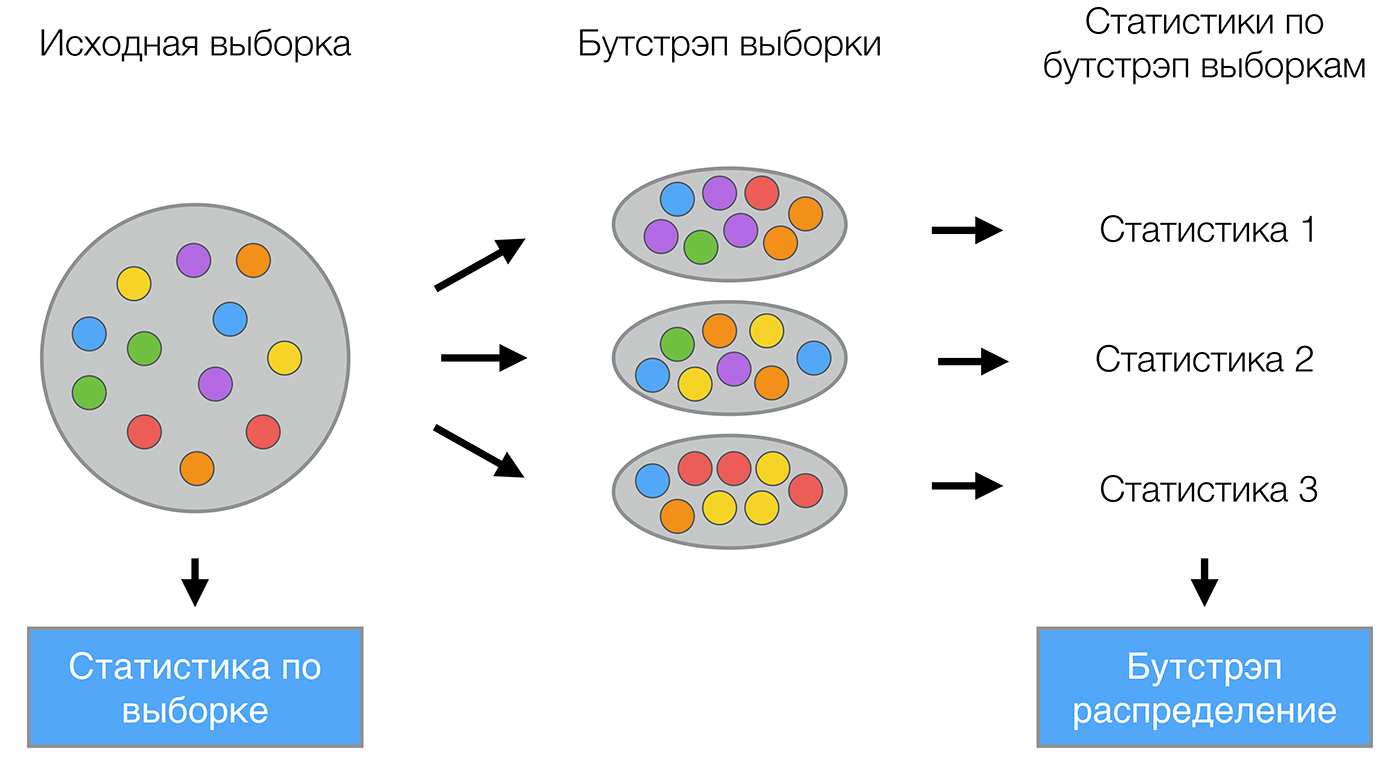

 . Итоговый классификатор будет усреднять ответы всех этих алгоритмов (в случае классификации это соответствует голосованию):
. Итоговый классификатор будет усреднять ответы всех этих алгоритмов (в случае классификации это соответствует голосованию):  . Эту схему можно представить картинкой ниже.
. Эту схему можно представить картинкой ниже. 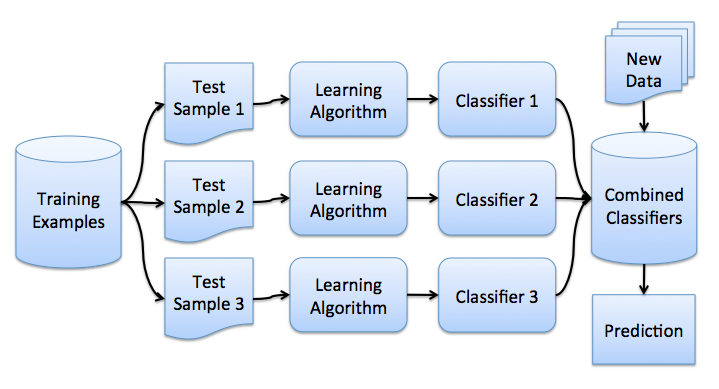
 . Предположим, что существует истинная функция ответа для всех объектов
. Предположим, что существует истинная функция ответа для всех объектов  , а также задано распределение на объектах
, а также задано распределение на объектах  . В этом случае мы можем записать ошибку каждой функции регрессии
. В этом случае мы можем записать ошибку каждой функции регрессии 









 объектов. На каждом шаге все объекты попадают в подвыборку с возвращением равновероятно, т.е отдельный объект — с вероятностью
объектов. На каждом шаге все объекты попадают в подвыборку с возвращением равновероятно, т.е отдельный объект — с вероятностью  Вероятность того, что объект НЕ попадет в подвыборку (т.е. его не взяли
Вероятность того, что объект НЕ попадет в подвыборку (т.е. его не взяли  . При
. При  получаем один из "замечательных" пределов
получаем один из "замечательных" пределов  . Тогда вероятность попадания конкретного объекта в подвыборку
. Тогда вероятность попадания конкретного объекта в подвыборку  .
. 

 .
. как число отдельных моделей в ансамбле.
как число отдельных моделей в ансамбле. выберите
выберите  как число признаков для
как число признаков для  .
. :
: с помощью бутстрэпа;
с помощью бутстрэпа; по выборке
по выборке  объектов или пока не достигнем определенной высоты дерева
объектов или пока не достигнем определенной высоты дерева исходных,
исходных, , простыми словами — для задачи кассификации мы выбираем решение голосованием по большинству, а в задаче регрессии — средним.
, простыми словами — для задачи кассификации мы выбираем решение голосованием по большинству, а в задаче регрессии — средним.  , а в задачах регрессии —
, а в задачах регрессии —  , где
, где 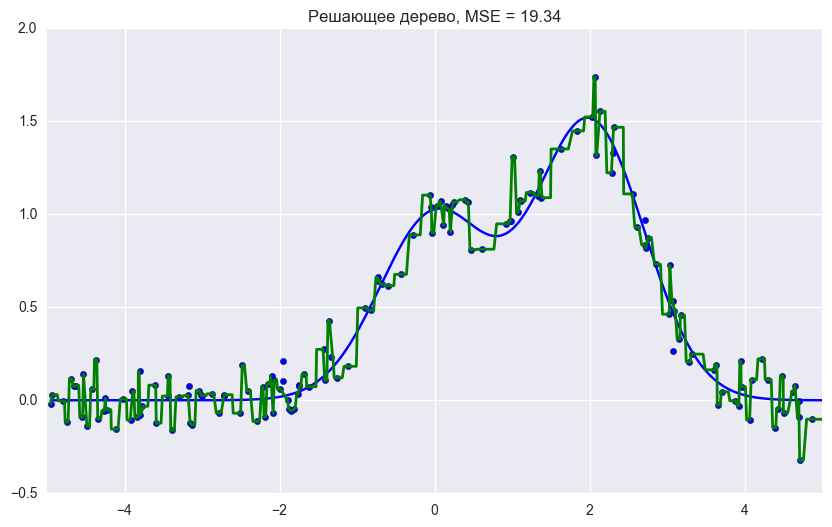


 , где n — число признаков. Давайте проверим, оптимально ли в нашем случае использовать 4 признака или нет.
, где n — число признаков. Давайте проверим, оптимально ли в нашем случае использовать 4 признака или нет. 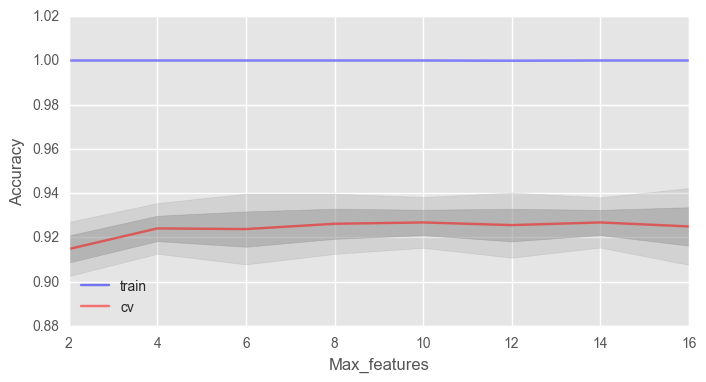

 – корреляция выборки между любыми двумя деревьями, используемыми при усреднении
– корреляция выборки между любыми двумя деревьями, используемыми при усреднении ![$ large ho(x) = corr[T(x;Theta_1(Z)),T(x_2,Theta_2(Z))], $](https://habrastorage.org/getpro/habr/formulas/c09/ac7/dec/c09ac7deca89159a02ce331d2f84d993.svg)
 и
и  – случайно выбранная пара деревьев на случайно выбранных объектах выборки
– случайно выбранная пара деревьев на случайно выбранных объектах выборки 
 — это выборочная дисперсия любого произвольно выбранного дерева:
— это выборочная дисперсия любого произвольно выбранного дерева: 
 со средней корреляцией между обученными деревьями в данном случайном лесе, рассматривая деревья как N-векторы и вычисляя среднюю парную корреляцию между ними. Это не тот случай. Эта условная корреляция не имеет прямого отношения к процессу усреднения, а зависимость от
со средней корреляцией между обученными деревьями в данном случайном лесе, рассматривая деревья как N-векторы и вычисляя среднюю парную корреляцию между ними. Это не тот случай. Эта условная корреляция не имеет прямого отношения к процессу усреднения, а зависимость от  в
в  .
. 
 :
: 
 — номер листа
— номер листа  -го дерева из случайного леса, в который попадает объект
-го дерева из случайного леса, в который попадает объект 
![$ large w_n(x, x_i) = frac{[T_n(x) = T_n(x_i)]}{sum_{j=1}^{l}[T_n(x) = T_n(x_j)]}$](https://habrastorage.org/getpro/habr/formulas/0bf/b0e/2cd/0bfb0e2cdb3da70c5c83a914f7101f76.svg)

 . Новые признаки являются результатом нелинейного разбиения пространства и несут в себе информацию о сходстве объектов.
. Новые признаки являются результатом нелинейного разбиения пространства и несут в себе информацию о сходстве объектов. 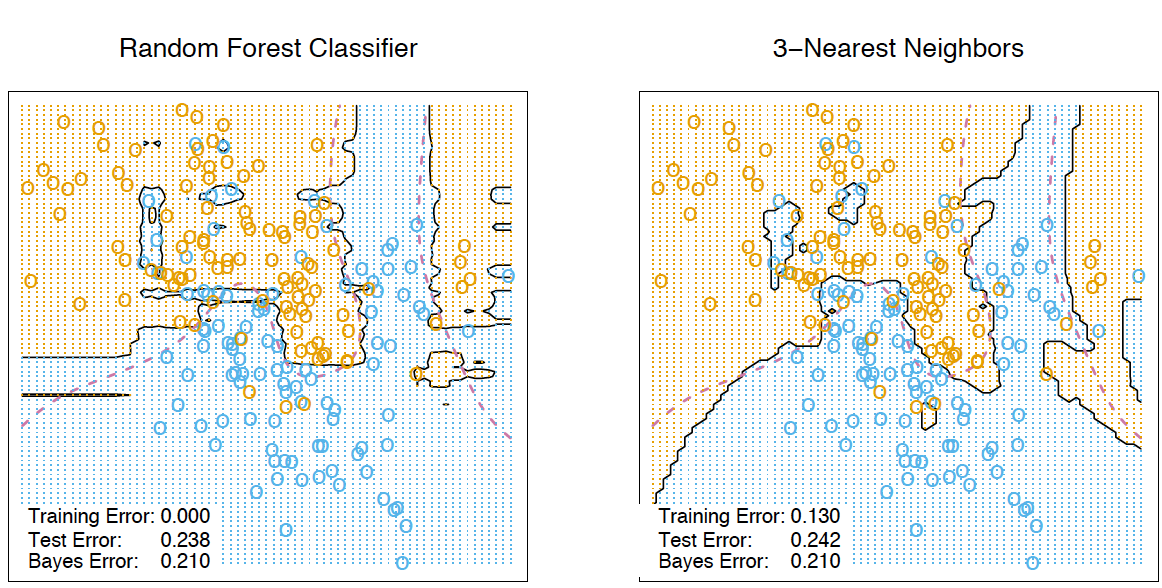


 — предсказание класса перед перестановкой/удалением признака
— предсказание класса перед перестановкой/удалением признака — предсказание класса после перестановки/удаления признака
— предсказание класса после перестановки/удаления признака
 , если
, если  не находится в дереве
не находится в дереве 



 памяти для хранения модели, где
памяти для хранения модели, где  — число деревьев.
— число деревьев.