Насколько данные для обучения модели (не)похожи на тестовую выборку?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-09-05 12:31
Есть такая поговорка: «Не сравнивайте яблоки с апельсинами». Но что делать, если нужно сравнить один набор яблок с апельсинами с другим, но распределения фруктов в двух наборах разное? Сможете работать с данными? И как будете это делать?
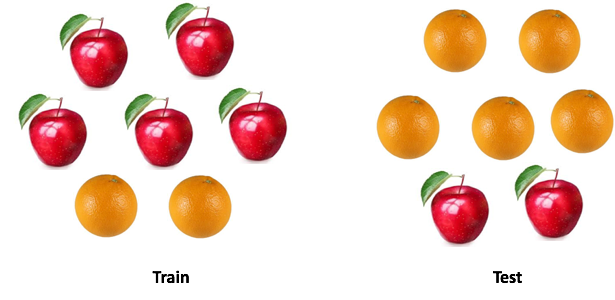
И речь здесь идет не о переобучении. Допустим, что мы построили модель, которая дает отличный результат на кросс-валидации, однако показывает плохой результат на тесте. Значит в тестовой выборке есть информация, которую мы не учитываем.
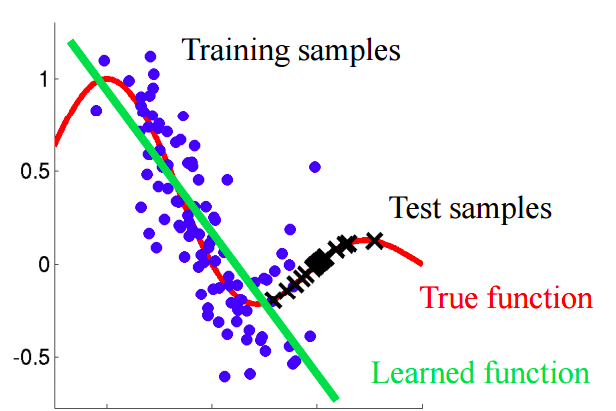
Представьте ситуацию, в которой мы прогнозируем поведение клиента в магазине. Если обучающая и тестовая выборка выглядят так, как показано на картинке ниже, это явная проблема:

В этом тексте мы поговорим о «наивных» подходах, позволяющих выявить подобные явления и попробовать их устранить.
Ковариационный сдвиг
Дадим более аккуратное определение данному понятию. Ковариация относится к значениям признаков, а под ковариационным сдвигом понимается ситуация, когда распределения значений признаков в обучающей и тестовой выборке имеют разные характеристики (параметры).
В реальных задачах с большим количеством переменных ковариационный сдвиг трудно обнаружить. В статье обсуждается метод выявления, а также учета ковариационного сдвига в данных.
Основная идея
Если в данных существует сдвиг, то при смешивании двух выборок мы сможем построить классификатор, способный определить принадлежность объекта к обучающей либо тестовой выборке.

Реализация
Попробуем применить описанную идею к реальному датасету. Используем датасет из соревнования на Kaggle.
Шаг 1: подготовка данных
Первым делом выполним ряд стандартных шагов: почистить, заполнить пропуски, выполнить label encoding для категориальных признаков. Для рассматриваемого датасета шаг не потребовался, так что пропустим его описание.
import pandas as pd #загрузка датасетов train и test train = pd.read_csv('train.csv',low_memory=True) test = pd.read_csv('test.csv',low_memory=True) Шаг 2: добавление индикатора источника данных
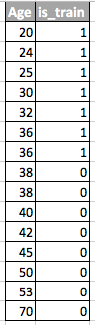
К обеим частям датасета — обучающей и тестовой — необходимо добавить новый признак-индикатор. Для обучающей выборки со значением «1», для тестовой, соответственно, «0».
#добавляем новый столбец к данным, нулевой к test, единичный к train test['is_train'] = 0 train['is_train'] = 1 Шаг 3: объединение обучающей и тестовой выборки
Теперь необходимо объединить два датасета. Ппоскольку обучающий датасет содержит столбец целевых значений 'target', которого нет в тестовом датасете, этот столбец необходимо удалить.
#объединение выборок train, test df_combine = pd.concat([train, test], axis=0, ignore_index=True) #удаление метки target df_combine = df_combine.drop('target', axis =1) y = df_combine['is_train'].values #индикатор источника x = df_combine.drop('is_train', axis=1).values #объединенный датасет tst, trn = test.values, train.values Шаг 4: построение и тестирование классификатора
Для целей классификации будем использовать Random Forest Classifier, который настроим для предсказания меток источника данных в объединенном датасете. Можно использовать любой другой классификатор.
from sklearn.ensemble import RandomForestClassifier import numpy as np rfc = RandomForestClassifier(n_jobs=-1, max_depth=5, min_samples_leaf = 5) predictions = np.zeros(y.shape) #пустой массив для вероятностей классов Используем стратифицированное рандомизированное разбиение на 4 фолда. Таким образом мы сохраним соотношение меток 'is_train' в каждом фолде как в исходной объединенной выборке. Для каждого разбиенения обучим классификатор на большей части разбиения и предскажем метку класса для меньшей отложенной части.
from sklearn.model_selection import StratifiedKFold, cross_val_score skf = StratifiedKFold(n_splits=4, shuffle=True, random_state=100) for fold, (train_idx, test_idx) in enumerate(skf.split(x, y)): X_train, X_test = x[train_idx], x[test_idx] y_train, y_test = y[train_idx], y[test_idx] rfc.fit(X_train, y_train) probs = rfc.predict_proba(X_test)[:, 1] #предсказание вероятностей классов predictions[test_idx] = probs Шаг 5: интерпретация результатов
Посчитаем значение метрики ROC AUC для нашего классификатора. На основе этого значения сделаем вывод, насколько хорошо наш классификатор выявляет ковариационный сдвиг в данных.
Если классификатор с хорошо разделяет объекты на обучающий и тестовый датасет, то значение метрики ROC AUC должно быть значительно больше 0.5, в идеале близко к 1. Такая картина свидетельствует о сильном ковариационном сдвиге в данных.
Найдём значение ROC AUC:
from sklearn.metrics import roc_auc_score print('ROC-AUC:', roc_auc_score(y_true=y, y_score=predictions)) # ROC-AUC: 0.49974692698385287 Получившееся значение близко к 0.5. А это значит, что наш классификатор по качеству такой же, как случайный предсказатель меток. Нет свидетельств наличия ковариационного сдвига в данных.
Поскольку датасет взят с Kaggle, результат довольно предсказуем. Как и в других соревнованиях по машинному обучению, данные тщательно выверены, чтобы убедиться в отсутствии сдвигов.
Но такой подход может быть применен в других задачах науки о данных для проверки наличия ковариационного сдвига непосредственно перед началом решения.
Дальнейшие шаги
Итак, либо мы наблюдаем ковариационных сдвиг, либо нет. Что же делать, чтобы улучшить качество модели на тесте?
- Удалить смещенные признаки
- Использовать весов важностей объектов на основе оценки коэффициента плотности
Удаление смещенных признаков:
Примечание: метод применим, если наблюдается ковариационный сдвиг в данных.
- Извлечь важности признаков из классификатора Random Forest Classifier, который мы построили и обучили ранее.
- Самые важные признаки как раз те, которые смещены и вызывают сдвиг в данных.
- Начиная с самых важных, удалять по одному признаку, строить целевую модель и смотреть на её качество. Собрать все признаки, для которых качество модели не уменьшается.
- Выбросить из данных собранные признаки и построить финальную модель.

Использование весов важностей объектов на основе оценки коэффициента плотности
Примечание: метод применим независимо от того, есть ли ковариационных сдвиг в данных.
Давайте посмотрим на предсказания, которые мы получили в предыдущем разделе. Для каждого объекта предсказание содержит вероятность того, что этот объект принадлежит обучающей выборке для нашего классификатора.
predictions[:10] #array([0.39743827 ... Например, для первого объекта наш Random Forest Classifier считает, что он принадлежит обучающей выборке с вероятностью 0.397. Назовём эту величину . Или можно сказать, что вероятность принадлежности тестовым данным равна 0.603. Аналогично, назовём вероятность .
Теперь небольшой трюк: для каждого объекта обучающего датасета вычислим коэффициент .
Коэффициент говорит нам, насколько объект из обучающей выборки близок к тестовым данным. Основная мысль:
Мы можем использовать как веса в любой из моделей, чтобы увеличить вес тех наблюдений, которые выглядят схожими с тестовой выборкой. Интуитивно это имеет смысл, так как наша модель будет более ориентирована на данные как в тестовом наборе.
Эти веса могут быть вычислены с помощью кода:
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(20,10)) predictions_train = predictions[len(tst):] weights = (1./predictions_train) - 1. weights /= np.mean(weights) #Нормализация весов plt.xlabel('Значение весов w') plt.ylabel('Число сэмплов') sns.distplot(weights, kde=False) Полученные коэффициенты можно передать модели, например, следующим образом:
rfc = RandomForestClassifier(n_jobs=-1,max_depth=5) m.fit(X_train, y_train, sample_weight=weights) 
- Большие значения веса соответствуют наблюдениям, более схожим с тестовой выборкой.
- Почти 70% объектов из обучающей выборки имеют вес, близкий к 1, и, следовательно, находятся в подпространстве, которое одинаково похоже и на тренировочную, и на тестовую выборку. Это соответствует значению AUC, которое мы вычислили ранее.
Заключение
Надеемся, что вам этот пост поможет вам в выявлении «ковариационного сдвига» в данных и борьбе с ним.
Ссылки
[1] Shimodaira, H. (2000). Improving predictive inference under covariate shift by weighting the log-likelihood function. Journal of Statistical Planning and Inference, 90, 227–244.
[2] Bickel, S. et al. (2009). Discriminative Learning Under Covariate Shift. Journal of Machine Learning Research, 10, 2137–2155
[3] github.com/erlendd/covariate-shift-adaption [4] Link to dataset used P.S. Ноутбук с кодом из статьи можно посмотреть здесь.
Телеграм: t.me/ainewsline
Источник: habr.com