Как Яндекс применил компьютерное зрение для повышения качества видеотрансляций. Технология DeepHD
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-09-25 16:01
Когда люди ищут в интернете картинку или видео, они часто прибавляют к запросу фразу «в хорошем качестве». Под качеством обычно имеется в виду разрешение — пользователи хотят, чтобы изображение было большим и при этом хорошо выглядело на экране современного компьютера, смартфона или телевизора. Но что делать, если источника в хорошем качестве просто не существует?
Сегодня мы расскажем о том, как с помощью нейронных сетей нам удается повышать разрешение видео в режиме реального времени. Вы также узнаете, чем отличается теоретический подход к решению этой задачи от практического. Если вам не интересны технические детали, то можно смело пролистать пост – в конце вас ждут примеры нашей работы.

В интернете много видеоконтента в низком качестве и разрешении. Это могут быть фильмы, снятые десятки лет назад, или трансляции тв-каналов, которые по разным причинам проводятся не в лучшем качестве. Когда пользователи растягивают такое видео на весь экран, то изображение становится мутным и нечётким. Идеальным решением для старых фильмов было бы найти оригинал плёнки, отсканировать на современном оборудовании и отреставрировать вручную, но это не всегда возможно. С трансляциями всё ещё сложнее – их нужно обрабатывать в прямом эфире. В связи с этим наиболее приемлемыи? для нас вариант работы — увеличивать разрешение и вычищать артефакты, используя технологии компьютерного зрения.
В индустрии задачу увеличения картинок и видео без потери качества называют термином super-resolution. На эту тему уже написано множество статей, но реалии «боевого» применения оказались намного сложнее и интереснее. Коротко о главных проблемах, которые нам пришлось решать в собственной технологии DeepHD:
- Нужно уметь восстанавливать детали, которых не было на оригинальном видео ввиду его низкого разрешения и качества, “дорисовывать” их.
- Решения из области super-resolution восстанавливают детали, но они делают чёткими и детализованными не только объекты на видео, но и артефакты сжатия, что вызывает неприязнь у зрителей.
- Есть проблема со сбором обучающеи? выборки – требуется большое количество пар, в которых одно и то же видео присутствует и в низком разрешении и качестве, и в высоком. В реальности для плохого контента обычно нет качественнои? пары.
- Решение должно работать в реальном времени.
Выбор технологии
В последние годы использование нейронных сетей привело к значительным успехам в решении практически всех задач компьютерного зрения, и задача super-resolution не исключение. Наиболее перспективными нам показались решения на основе GAN (Generative Adversarial Networks, генеративные соперничающие сети). Они позволяют получить фотореалистичные изображения высокой чёткости, дополняя их недостающими деталями, например прорисовывая волосы и ресницы на изображениях людей.
В самом простом случае нейронная сеть состоит из двух частей. Первая часть – генератор – принимает на вход изображение и возвращает увеличенное в два раза. Вторая часть – дискриминатор – получает на вход изображение, сгенерированные и “настоящие”, и пытается отличить друг от друга.
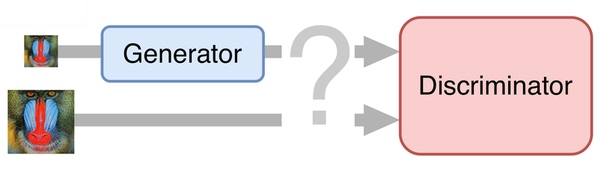
Подготовка обучающего множеств
Для обучения мы собрали несколько десятков роликов в UltraHD-качестве. Сначала мы уменьшили их до разрешения 1080p, получив тем самым эталонные примеры. Затем мы уменьшили эти ролики ещё вдвое, попутно сжав с разным битрейтом, чтобы получить что-то похожее на реальное видео в низком качестве. Полученные ролики мы разбили на кадры и в таком виде использовали для обучения нейронной сети.
Деблокинг
Конечно же, нам хотелось получить end-to-end-решение: обучать нейросеть генерировать видео высокого разрешения и качества сразу из оригинального. Однако GAN'ы оказались очень капризны и постоянно пытались уточнять артефакты сжатия, а не устранять их. Поэтому пришлось разбить процесс на несколько этапов. Первый – подавление артефактов сжатия видео, также известный как деблокинг.
Пример работы одного из методов деблокинга:

На этом этапе мы минимизировали среднеквадратичное отклонение между сгенерированным и исходным кадром. Тем самым мы хоть и увеличивали разрешение изображения, но не получали реального повышения разрешения за счёт регрессии к среднему: нейросеть, не зная, в каких конкретно пикселях проходит та или иная граница на изображении, была вынуждена усреднять несколько вариантов, получая размытый результат. Главное, чего мы добились на этом этапе – устранение артефактов сжатия видео, так что генеративной сети на следующем этапе нужно было только повысить чёткость и добавить недостающие мелкие детали, текстуры. После сотен экспериментов мы подобрали оптимальную по соотношению производительности и качества архитектуру, отдалённо напоминающую архитектуру DRCN:
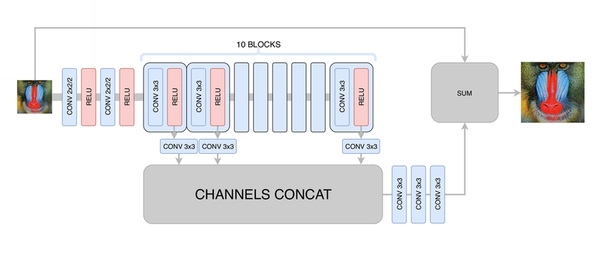
Основная идея такой архитектуры состоит в желании получить максимально глубокую архитектуру, при этом не получив проблем со сходимостью при её обучении. С одной стороны, каждый следующий свёрточный слой извлекает всё более сложные признаки входного изображения, что позволяет определять, что за объект находится в данной точке изображения и восстанавливать сложные и сильно повреждённые детали. С другой стороны, расстояние в графе нейронной сети от любого её слоя до выхода остаётся небольшим, благодаря чему улучшается сходимость нейросети и появляется возможность использовать большое количество слоёв.
Обучение генеративной сети
За основу нейронной сети для повышения разрешения мы взяли архитектуру SRGAN. Прежде чем обучать соревновательную сеть, нужно предобучить генератор – обучить его тем же способом, что и на этапе деблокинга. В противном случае в начале обучения генератор будет возвращать только шум, дискриминатор сразу начнёт «выигрывать» – легко научится отличать шум от реальных кадров, и никакого обучения не получится.
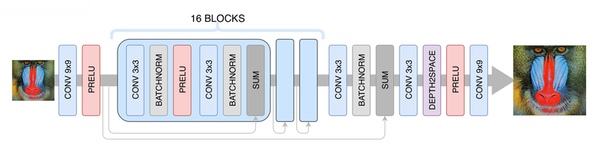
Далее обучаем GAN, но и тут есть свои нюансы. Нам важно, чтобы генератор создавал не только фотореалистичные кадры, но и сохранял имеющуюся на них информацию. Для этого к классической архитектуре GAN'а мы добавляем контентную функцию потерь (content loss). Она представляет собой несколько слоёв нейросети VGG19, обученной на стандартном датасете ImageNet. Эти слои преобразуют изображение в карту признаков, которая содержит информацию о содержимом изображения. Функция потерь минимизирует расстояние между такими картами, полученными из сгенерированного и исходного кадров. Также наличие такой функции потерь позволяет не испортить генератор на первых шагах обучения, когда дискриминатор ещё не обучен и выдает бесполезную информацию.

Ускорение нейросети
Всё шло хорошо, и после цепочки экспериментов мы получили неплохую модель, которую уже можно было применять к старым фильмам. Однако для обработки потокового видео она все ещё была слишком медленной. Оказалось, что просто уменьшить генератор без существенной потери качества итоговой модели нельзя. Тогда нам на помощь пришёл подход knowledge distillation («дистилляция» знаний). Этот метод предусматривает обучение более лёгкой модели таким образом, чтобы она повторяла результаты более тяжёлой. Мы взяли множество реальных видео в низком качестве, обработали их полученной на предыдущем шаге генеративной нейросетью и обучили более лёгкую сеть получать из тех же кадров такой же результат. За счёт этого приёма мы получили сеть, которая не очень сильно уступает по качеству исходной, но быстрее её в десятки раз: на обработку одного телеканала в разрешении 576p требуется одна карта NVIDIA Tesla V100.

Оценка качества решений
Пожалуй, самый сложный момент при работе с генеративными сетями – это оценка качества полученных моделей. Здесь нет понятной функции ошибки, как, например, при решении задачи классификации. Вместо этого мы знаем только точность дискриминатора, которая никак не отражает интересующее нас качество генератора (хорошо знакомый с этой сферой читатель мог бы предложить использовать метрику Вассерштайна, но, к сожалению, у нас она давала заметно более плохой результат).
Решить эту проблему нам помогли люди. Мы показывали пользователям сервиса Яндекс.Толока пары изображений, одно из которых было исходным, а другое – обработанным нейросетью, либо оба были обработанными разными версиями наших решений. За вознаграждение пользователи выбирали более качественное видео из пары, так мы получали статистически значимое сравнение версий даже при сложно различимых глазом изменениях. Наши итоговые модели одерживают победу в более чем 70% случаев, что достаточно много, учитывая, что пользователи тратят на оценку пары видео всего несколько секунд.
Интересным результатом также стал тот факт, что видео в разрешении 576p, увеличенное технологией DeepHD до 720p, выигрывает у такого же оригинального видео с разрешением 720p в 60% случаев – т.е. обработка не только повышает разрешение видео, но и улучшает его визуальное восприятие.
Примеры
Весной мы испытали технологию DeepHD на нескольких старых фильмах, посмотреть которые можно на КиноПоиске: «Радуга» Марка Донского (1943), «Летят журавли» Михаила Калатозова (1957), «Дорогой мой человек» Иосифа Хейфица (1958), «Судьба человека» Сергея Бондарчука (1959), «Иваново детство» Андрея Тарковского (1962), «Отец солдата» Резо Чхеидзе (1964) и «Танго нашего детства» Альберта Мкртчяна (1985).

Разница между версиями до и после обработки особенно заметна, если вглядываться в детали: изучать мимику героев на крупных планах, рассматривать фактуру одежды или рисунок ткани. Удалось компенсировать и некоторые недостатки оцифровки: например, убрать пересветы на лицах или сделать более заметными предметы, размещённые в тени.
Позднее технология DeepHD стала использоваться для улучшения качества трансляций некоторыхканалов в сервисе Яндекс.Эфир. Распознать такой контент легко по метке dHD.
Теперь на Яндексе в улучшенном качестве можно посмотреть «Снежную королеву», «Бременских музыкантов», «Золотую антилопу» и другие популярные мультики киностудии «Союзмультфильм».
Для требовательных к качеству изображения зрителей разница будет особенно заметной: изображение стало более резким, лучше видны листья деревьев, снежинки, звёзды на ночном небе над джунглями и другие мелкие детали.
Дальше – больше.
Телеграм: t.me/ainewsline
Источник: m.vk.com