Глубокое обучение для идентификации картин
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-09-08 11:32
машинное обучение python, архитектура нейронных сетей, техническое зрение

Сегодня я хочу рассказать о том, как глубокое обучение помогает нам лучше разобраться в искусстве. Статья разбита на части в соответствии с задачами, которые мы решали:
- поиск картины в базе данных по фотографии, сделанной мобильным телефоном;
- определение стиля и жанра картины, которой нет в базе данных.
Все это должно было стать частью сервиса БД Артхив и его мобильных приложений.
Задача идентификации картин состояла в том, чтобы по изображению, приходящему от мобильного приложения, найти в базе данных соответствующую картину, затратив на это менее одной секунды. Обработка целиком в мобильном устройстве была исключена на этапе предпроектного исследования. Кроме того, оказалось, что невозможно трудно гарантированно выполнить на мобильном устройстве отделение картины от фона в реальных условиях съемки. Поэтому мы решили, что наш сервис будет принимать на вход фотографию с мобильного телефона целиком, со всеми искажениями, шумами и возможным частичным перекрытием.

База произведений искусства Артхив включает почти 250 000 изображений, вместе с различными метаданными. База непрерывно пополняется — от десятков до сотен изображений в день. Даже выкачанные с ограниченным разрешением (не более 1400 пикселей по большей из сторон) изображения занимают более 80 гигабайт. К сожалению, база «грязная»: присутствуют битые или слишком маленькие файлы, невыровненные и необработанные изображения, дублирующиеся изображения. Однако, в целом это хорошие данные.
Сравнение картин
Посмотрим, как выглядят изображения в базе:

Оранжевое, красное, желтое

Монахиня

Женщины из тропиков
В основном в базе изображения выровнены, обрезаны по границам полотна, цвета сохранены.
А вот как могут выглядеть запросы с мобильных устройств:

Цвета почти всегда искажены – встречается сложное освещение, присутствуют блики, встречаются даже отражения других картин в стекле. Сами изображения перспективно искажены, могут быть частично обрезаны или же напротив, занимать менее половины снимка, могут быть частично закрыты, например, людьми.
Для того, чтобы идентифицировать картины нужно уметь сравнивать изображения из запросов с изображениями в базе данных.
Для сравнения изображений подверженных перспективным искажениям и искажениям цвета, мы используем сопоставление ключевых точек. Для этого мы находим на изображениях ключевые точки с дескрипторами, находим их соответствие, а затем гомографическое отображение соответствующих точек методом RANSAC. Делается это в целом так же, как описано в примере OpenCV. Если количество «хороших точек» (inlier), найденных RANSAC, достаточно велико, а найденное гомографическое преобразование выглядит достаточно правдоподобным (не имеет сильного масштабирования или поворотов), то можно считать, что искомые изображения – это одна и та же картина, подверженная перспективным искажениям.
Пример сопоставления ключевых точек:

Пример негативного сопоставления:

Сопоставления картин из примера выше:






Конечно, поиск ключевых точек обычно достаточно медленный процесс, но для поиска в базе данных можно заранее найти ключевые точки всех картин и сохранить некоторое их количество. В наших экспериментах мы пришли к выводу, что менее чем 1000 точек достаточно для уверенного поиска картин. При использовании 64 байт на точку (координаты + дескриптор AKAZE) для хранения 1024 точек достаточно 64 кбайт на каждое изображение или около 15 Гбайт на всю базу.
Сравнение картинок по ключевым точкам в нашем случае занимало примерно 15 мс, то есть, для полного перебора базы из 250 000 картин нужно около 1 часа. Это много.
С другой стороны, если научиться быстро выбирать из всей базы несколько (скажем, 100) наиболее вероятных кандидатов – мы уложимся в целевое время в 1 секунду на запрос.
Ранжирование картин по похожести
Глубокие свёрточные сети зарекомендовали себя как хороший способ поиска похожих изображений. Сеть используется для извлечения признаков и вычисления на их основе дескриптора, обладающего тем свойством, что расстояние (евклидово, косинусное или другое) между дескрипторами похожих изображений будет меньше, чем для различных изображений.
Можно натренировать сеть таким образом, чтобы для изображения картины из базы и ее искаженного изображения из фотографии она выдавала близкие дескрипторы, а для разных картин – более далекие. Далее такая сеть используется для вычисления дескрипторов всех изображений в базе и дескрипторов фотографий в запросах. Достаточно быстро можно выбрать ближайшие изображения и упорядочить их по расстоянию между дескрипторами.
Базовый способ обучения сети для вычисления дескриптора – использование сиамской сети.
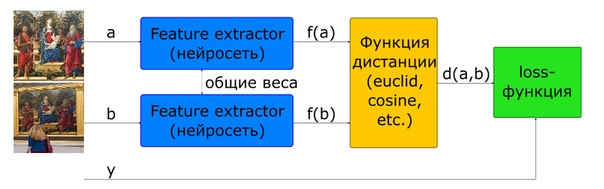
a,b – входные изображения
y=1, если a и b – один класс, 0 если разные
f(a),f(b)D?R^d – дескрипторы изображений
d(a,b)=d(f(a),f(b)) — расстояние между парой векторов признаков
loss=y?d(a,b)+(1?y)?max(0,margin?d(a,b)) — целевая функция
Для построения такой архитектуры сеть, которая вычисляет дескриптор (Feature Extractor), используется в модели 2 раза с общими весами. На вход сети подается пара изображений. Feature Extractor сети вычисляет дескрипторы изображений, затем сеть вычисляет расстояние в соответствии с заданной метрикой (обычно используется евклидово либо косинусное расстояние). Целевая функция обучения сети построена таким образом, чтобы для позитивных пар (изображения одной картины) расстояние уменьшалось, а для негативных (изображения разных картин) увеличивалось. Для снижения влияния негативных пар расстояние между ними ограничивается величиной margin.
Таким образом, можно сказать, что в процессе обучения сеть стремится вычислять дескрипторы похожих изображений внутри гиперсферы радиусом margin, а дескрипторы разных – вытолкнуть за пределы этой сферы.
Например, вот так может выглядеть обучение двухмерного дескриптора с помощью сиамской сети на датасете MNIST.
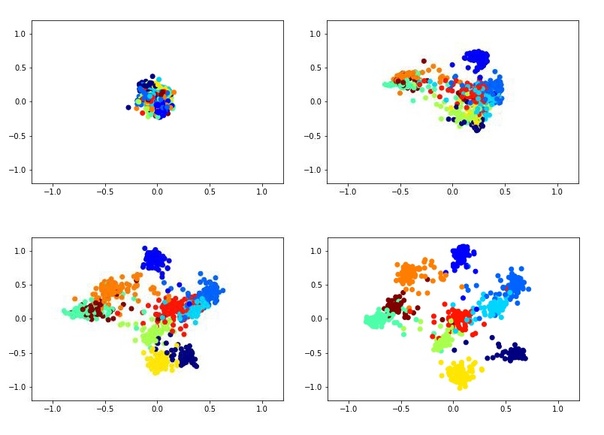
Анимация обучения:
Для обучения сиамской сети необходимо подавать на вход пары картинок и метку, которая равна 1, если картинки принадлежат одному классу, или 0, если разным. Существует проблема выбора пропорции позитивных и негативных пар. В идеале, конечно, надо было бы подавать на обучение сети все возможные комбинации пар из обучающей выборки, однако это технически невозможно. Да и количество негативных пар в этом случае существенно превосходит количество позитивных, что тоже не очень хорошо скажется на процессе обучения.
Частично проблема с выбором пропорции пар для обучения решается применением архитектуры triplet.
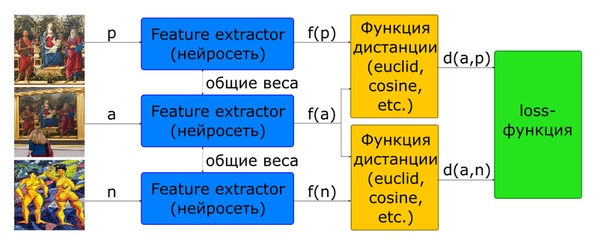
a,p,n – входные изображения: a,p — одной картины, n — другой
loss=max(d(a,p)?d(a,n)+margin,0) — целевая функция
На вход такой сети подаются сразу 3 картинки, образующие позитивную и негативную пары.
Кроме того, практически все исследователи сходятся на том, что выбор негативных пар критически важен для обучения сети. Целевая функция для многих сэмплов (пар для siamese, троек для triplet) получается равна 0, если они не нарушают ограничение margin, следовательно, такие сэмплы не участвуют в обучении сети. Со временем процесс обучения еще больше замедляется, так как сэмплов с ненулевым значением целевой функции становится все меньше. Для решения этой проблемы негативные пары выбираются не случайно, а с помощью поиска трудных случаев (hard case mining). На практике для этого выбирается несколько кандидатов негативов, для каждого из которых вычисляется дескриптор с использованием последней версии весов сети (с предыдущей эпохи или даже с текущей). Имея дескриптор, можно выбрать негатив в каждую тройку такой, который выдает заведомо ненулевой loss.
Для поиска похожих изображений от сети отделяют Feature Extractor и используют его для вычисления дескрипторов. Для изображений в базе дескрипторы вычисляются заранее при их добавлении. Таким образом, задача поиска похожих изображений состоит в вычислении дескриптора изображения в запросе и поиске ближайших по заданной метрике дескрипторов в базе данных.
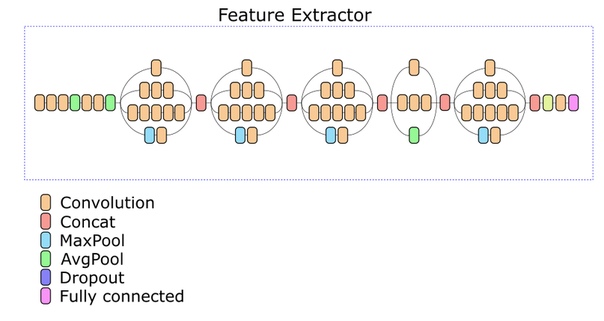
Feature Extractor нашей сети основан на архитектуре Inception v3. Экспериментально был выбран один из промежуточных слоев, на основе выхода которого вычисляется дескриптор из 512 вещественных чисел.
Аугментация данных
Было бы хорошо, если бы мы могли поместить каждую картину в разные рамки, на разные стены и сфотографировать каждый раз с разного ракурса на разные телефоны. На практике это, конечно же, невозможно. Поэтому приходится генерировать обучающие данные.
Для генерации данных были собраны около 500 фотографий различных картин с разными фонами при различном освещении. Для каждой фотографии были выделены 4 точки, соответствующие углам холста картины. По четырем точкам мы можем произвольно вписать любую картинку в рамку, заменив тем самым изображение и получив почти случайное перспективное искажение картины из базы данных. Дополнив этот процесс случайными кропами, шумами и искажениями цвета, мы получаем возможность генерировать вполне годные изображения, имитирующие фотографии картин.

Отделение картины от фона
Качество работы и модели идентификации картин, и модели классификации жанров/стилей в значительной мере зависит от того, насколько хорошо картина отделена от фона. В идеале, перед тем, как скормить картину в модель, нужно найти 4 угла ее холста и отобразить перспективно на квадрат. Практически же реализовать алгоритм, позволяющий сделать это гарантированно, оказалось очень трудно. С одной стороны, имеется значительное разнообразие фонов, рамок и предметов, которые могут попасть в кадр возле картины. С другой стороны, есть картины, внутри которых имеются достаточно заметные очертания прямоугольных форм (окна, фасады зданий, картина-в-картине). В результате, зачастую весьма трудно сказать, где заканчивается картина и начинается ее окружение.
В конечном счете мы остановились на простой реализации, основанной на классических методах компьютерного зрения (детектирование границ + морфологическая фильтрация + анализ связных компонент), который позволяет уверенно отсечь однотонные фоны, но не потерять часть картины.
Скорость работы
Алгоритм обработки запросов состоит из следующих основных шагов:
- подготовка — фактически реализован простейший детектор картины, который хорошо работает, если изображение содержит однотонный фон;
- вычисление дескриптора картины с помощью глубокой сети;
- ранжирование картин по расстоянию до дескрипторов в базе данных;
- поиск ключевых точек на картине;
- проверка кандидатов в порядке ранжирования.
Мы протестировали скорость работы сети на 200 запросах, получилось следующее время обработки каждого из этапов (время в секундах):

Так как проверка кандидатов прекращается сразу, как будет найдена картина с достаточной уверенностью, то можно считать что минимальное время обработки запросов соответствует картинам, найденным среди первых кандидатов. Максимальное же время запроса получается для картин, вовсе не найденных — проверка прекращается после 500 кандидатов.
Видно, что основное время тратится на выбор кандидатов и их проверку. Стоит заметить, что реализация этих шагов сделана весьма неоптимально и обладает огромным потенциалом для ускорения.
Поиск дубликатов
Построив полный индекс базы картин, мы применили его для поиска дубликатов в базе. После примерно 3 часов просмотра базы было обнаружено, что по крайней мере 13657 изображений повторяются в базе два раза (а некоторые и три).
При этом были найдены и весьма интересные случаи, не являющиеся дубликатами.


А также пример неверного срабатывания идентификации по ключевым точкам.

Сопоставление ключевых точек:

Вместо заключения
В целом мы довольны результатом работы сервиса.
На тестовых наборах достигается точность идентификации свыше 80%. На практике часто оказывается, что если картина не найдена с первого раза, то достаточно сфотографировать ее под другим углом, и она находится. Ошибки, когда находится неверное изображение, практически не встречаются.
Все вместе решение было завернуто в контейнер docker и отдано заказчику. Сейчас идентификация картин по фото доступна в приложениях, использующих сервис Артхив, например “пушкинский музей”, доступных в Play Market (однако, там реализовано отделение картины от фона, требующее, чтобы фон был светлым, что иногда затрудняет фотографирование).
Телеграм: t.me/ainewsline
Источник: m.vk.com