Глубины SIEM: Корреляции «из коробки»
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-09-20 07:30

Как часто вы слышите утверждение что правила корреляции, поставляемые производителем SIEM, не работают и удаляются, или отключаются сразу же после инсталляции продукта? На мероприятиях по информационной безопасности любая секция, посвященная SIEM, так или иначе затрагивает данный вопрос.
Давайте рискнем и попробуем найти решение проблемы.

Чаще всего основной проблемой называют то, что правила корреляции производителя SIEM изначально не адаптированы под особенности инфраструктуры конкретного заказчика.
Анализируя проблемы, озвучиваемые на разных площадках, складывается ощущение, что решения у проблемы нет. Внедряя SIEM все равно придется либо очень сильно доработать то, что поставляет производитель, либо выкинуть все правила и писать свои с нуля, при этом данная проблема присуща всем решениям, из любой части квадранта Gartner.
Невольно задаешься вопросом действительно ли все так плохо и данный Гордиев узел невозможно разрубить? Неужели выражение «Правила корреляции, работающие из коробки» — всего лишь маркетинговый слоган, за которым ничего не стоит?
Статья может вас заинтересовать, если:
- Вы уже работаете с каким-то SIEM-решением.
- Только планируете его внедрение.
- Собрались строить свой SIEM с блекджеком и корреляциями на базе ELK-стека, или чего-то иного.
О чем будут статьи
В рамках данной серии статей перечислим главные проблемы, которые препятствуют реализации концепции «Правил корреляции, работающих из коробки», а также попробуем описать системный подход для их решения.
Сразу оговорюсь, что техническими специалистами именно эта статья может быть охарактеризована как: «вода», «ни о чем». Все так и есть, но не совсем. Перед тем как разбираться с какой-то сложной задачей, хочется сначала выяснить почему она возникла и что нам дает ее решение.
Для лучшего понимания всего круга вопросов, которые будут изложены, приведу общую структуру всего цикла статей:
- Статья 1: Данная статья. Поговорим о постановке задачи и попытаемся понять, зачем нам вообще нужны правила «Правила корреляции, работающие из коробки». Статья будет носить идеологический характер и, если станет совсем скучно, ее можно пропустить. Но, не советую это делать, т.к. в следующих статьях я буду часто на нее ссылаться. Здесь же обсудим основные проблемы, стоящие на нашем пути, и методы их решения.
- Статья 2: Ура! Вот тут-то мы и дойдем до первых деталей предлагаемого подхода к решению задачи. Опишем то, как должен «видеть» нашу защищаемую информационную систему SIEM. Поговорим о том каким должен быть набор полей, необходимый для нормализации событий.
- Статья 3: Опишем роль категоризации событий и то, как на ее базе выстраивается методология нормализации событий. Покажем чем отличаются события ИТ от событий ИБ и почему у них должны быть разные принципы категоризации. Приведем живые примеры работы данной методологии.
- Статья 4: Пристально посмотрим на активы, из которых состоит наша автоматизированная система и посмотрим как они влияют на работоспособность правил. Убедимся, что с ними тоже не все так просто: их необходимо идентифицировать и постоянно поддерживать в актуальном состоянии.
- Статья 5: То, ради чего все и затевалось. Опишем подход к написанию правил корреляции, опираясь на все то, что было изложено в предыдущих статьях.
Постановка задачи и почему это важно
Попробуем в общих чертах, простыми словами, сформулировать нашу задачу: «Я, как клиент, купивший SIEM решение, подписку на обновлении базы правил и платящий производителю (а иногда и интегратору) за поддержку, хочу, чтобы мне оперативно поставлялись правила корреляции, которые устанавливались бы в мой SIEM и сразу же приносили пользу». Как по мне, так вполне себе здравое пожелание, не обремененное какими-то архитектурными или структурными техническими ограничениями.
А теперь, внимание, давайте допустим, что мы уже решили все проблемы и наша задача уже выполнена. Что нам это дает?
- Во-первых, экономим трудозатраты наших специалистов. Теперь им не надо тратить время на изучение логики работы каждого нового правила и адаптацию его к реалиям конкретной автоматизированной системы.
- Во-вторых, экономим бюджет, т.к. не просим интегратора, или кого-то еще за отдельную денежку написать или адаптировать для нас правила.
- В-третьих, у всех значимых игроков рынка SIEM есть исследовательские подразделения и отделы, которые целенаправленно занимаются анализом угроз информационной безопасности. Важно использовать их опыт, особенно, если мы за него платим.
- В-четвертых, сокращаем время нашей реакции на новые угрозы. Я не буду писать о той вечности, которая проходит между появлением угрозы, разработкой правил корреляции для ее детектирования и имплементацией в конкретный продукт у конкретного заказчика, по этой теме уже написано немало статей.
- В-пятых, это приближает нас всех к возможности делиться между собой унифицированными правилами, которые будут работать у любого заказчика, в рамках определенного SIEM-решения, конечно.
Многие технические специалисты, кто сталкивался с решением поставленной задачи и дочитавшие до этого места, сразу возразят: «Да, плюсы конечно есть, но это технически нереализуемо». Лично я считаю, что задача вполне «подъемная» и уже сейчас, как на западном, так и российском рынке есть SIEM, которые содержат все элементы, необходимы для ее решения. Хочу акцентировать на этом ваше внимание – продукты позволяют не решить задачу, а лишь содержат все необходимые блоки, из которые, как из конструктора, можно собрать искомое нами решение.
Считаю это очень важным, т.к. все, что будет описано дальше, возможно реализовать практически в любом существующим и зрелом SIEM.
Довольно лирики, далее мы поговорим более подробно о тех проблемах, которые возникают на пути решения нашей задачи.
Проблемы, с которыми нам предстоит столкнуться
В поисках решения поставленной выше задачи, давайте посмотрим с какими-же проблемами нам придется столкнуться. Выделение основных проблем позволит лучше понять проблематику, а также выработать системный подход для их разрешения.
Те проблемы, с которым мы столкнемся представляют собой снежный ком, каждая из которых драматически усугубляет ситуацию. Множество всех этих проблем ведет к тому что создать «Правила корреляции, работающие из коробки» крайне затруднительно.
В целом проблемы подразделяются на следующие четыре крупных блока:
- Потеря данных при нормализации, связанная с трансформациями моделей «мира».
- Отсутствие четких и всеми принятых правил нормализации событий.
- Постоянная «мутация» объекта защиты – нашей автоматизированной системы.
- Отсутствие правил написания правил корреляции.

Давайте теперь рассмотрим эти проблемы более подробно.
Трансформация модели мира
Данную проблему проще всего описать, пользуясь следующей аналогией.
Мир вокруг нас многообразен и многогранен, но наш слух и зрение фиксирует только ограниченный спектр излучений. Увидев или услышав какое-то явление, мы строим у себя в голове образ данного события, оперируя уже его урезанной моделью. К примеру, наш глаз не видит в инфракрасном спектре, а ухо не улавливает колебания ниже 16 Гц. Это первая трансформация исходного явления. Бывает в эту модель наша фантазия приносим то, чего в исходном явлении не было. Об этом явлении мы можем рассказать собеседнику, используя устную речь со всеми ее ограничениями и особенностями. Это вторая трансформация модели. Наконец собеседник, с наших слов, решит написать об этом явлении своему коллеге в мессенджере. Это третья и, скорее всего, самая драматическая с точки зрения потери информации трансформация модели.
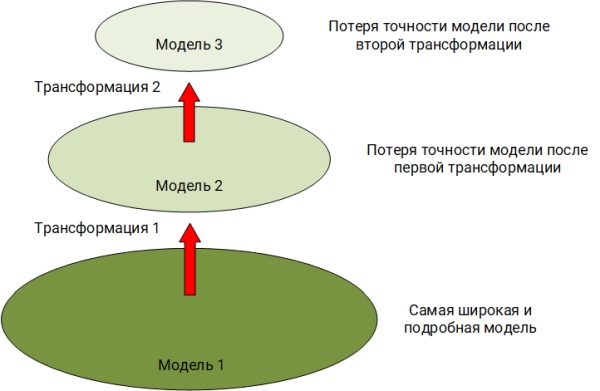
В описанном выше примере мы наблюдаем классическую проблему, к которой исходная «концептуальная модель» (Советов Б. Я., Яковлев С. А., Моделирование систем) путем упрощения трансформируется в другую модель при этом теряя в детальности.
Ровно тоже самое происходит и в мире событий, порождаемых программным или аппаратным обеспечением.
Пояснением может служить вот такая упрощенная картина уже из нашей предметной области:
- Первая трансформация модели. В оперативную память был загружен исполняемый файл, ОС начала выполнять описанные в нем инструкции. Операционная система передает в демон/сервис журналирования (auditd, eventlog и т.п.) часть информацию об этой операции. Если не включить расширенный аудит действий, то часть информации в данный демон не попадает. Но даже в при расширенном аудите часть информации все же будет отброшена, т.к. разработчики ОС решили, что именного такого объема информации достаточно для понимания происходящего явления.
- Вторая трансформация модели. А теперь демон/сервис создает событие, пишет информацию на диск и тут мы понимаем, что длинна строки события может быть ограничена определенным числом байт. Если демон/сервис ведет структурированный лог, то в нем заложена некоторая схема события с определенными полями. Что делать если информации настолько много, что она не умещается в «зашитую» схему? Правильно, скорее всего эта информация будет просто отброшена.
Теперь как это выглядит в рамках нашей задачи.
Мы имеем уже упрощенную модель (уже потерявшую много деталей) какого-то явления, представленного записью в лог-файле – событием. SIEM зачитывает это событие, нормализует его путем распределения данных по полям своей схемы. Количество полей в схеме априори не может содержать их столько, сколько необходимо чтобы покрыть все возможные семантики всех событий от всех источников, то есть на этом шаге также происходит трансформация модели и потеря данных.

Важно понимать, что из-за наличия этой проблемы эксперт, анализируя логи в SIEM или описывая правило корреляции, видит не само исходное событие, а его как минимум дважды искаженную модель, потерявшую достаточно много информации. И, если потерянная информация крайне важна в расследовании инцидента и, как следствии написании правила, ее придется откуда-то извлечь. Найти же недостающую информацию эксперту возможно либо путем обращения к первоисточнику (сырому событию, дампу памяти и т.д.), либо смоделировав недостающие данные у себя в голове на основе своего опыта, что сделать непосредственно из правил корреляции практически невозможно.
Хорошим индикатором данной проблемы служат, как не странно, поля типа Customer device string, Datafield или что-то иное. Эти поля представляют собой некую «свалку» куда, помещают данные, которые не знают куда положить, или когда все остальные подходящие поля попросту заполонены.
Набор полей таксономии, как правило, отражает модель «мира» так, как видит предметную область разработчик SIEM. Если модель очень «узкая», то в ней небольшое количество полей и при нормализации части событий их будет попросту не хватать. Таким проблемой часто обладают SIEM с изначально фиксированным и динамически нерасширяемым набором полей.
С другой стороны, если полей слишком много, появляются проблемы, связанные с непониманием в какое поле необходимо положить те или иные данные исходного события. Такая ситуация влечет за собой возможность появления смыслового дублирования, когда семантически одни и те же данные исходного события подходят сразу под несколько полей. Такое часто наблюдается в решениях, где набор полей схемы динамически может быть расширен любым модулем нормализации при поддержке нового источника.
Если под рукой есть «боевой» SIEM, посмотрите на свои события. Как часто при нормализации вы используете зарезервированные дополнительные поля (Custom device string, Datafield, и т.д.)? Множество типов событий с заполненными дополнительными полями говорят о том, что вы наблюдаете первую проблему. А теперь вспомните, или спросите у коллег, как часто при поддержке нового источника им приходилось добавлять новое поле, так как зарезервированных не хватило? Ответ на данный вопрос служит индикатором второй проблемы.
Методология нормализации событий
Важно вспомнить кто и как нормализует события, т.к. это играет немаловажную роль. Часть источников поддерживает непосредственно разработчик SIEM решения, часть интегратор, внедрявший вам SIEM, а часть вы сами. Вот тут-то нас и поджидает следующая проблема: Каждый из участников по-своему трактует смысл полей схемы событий и поэтому по-разному проводит нормализацию. Таким образом семантически одинаковые данные разные участники могут разложить в разные поля. Безусловно, есть ряд полей, название которые не допускает двойственной трактовки. Допустим src_ip или dst_ip, но даже с ними бывают трудности. Например, в сетевых событиях, надо ли менять src_ip на dst_ip при нормализации входящего и исходящего соединения в рамках одной сессии?
Исходя из вышеописанного возникает необходимость создания четкой методология поддержки источников, в рамках которой было бы явно указано:
- Какие поля схемы для чего нужны.
- Какие типы данных каким полям соответствуют.
- Какая информация нам важна в рамках каждого типа событий.
- Каковы правила заполнения полей.
Модель объекта защиты и ее мутация
В рамках решения поставленной задачи объектом защиты является наша автоматизированная система (АС). Да, именно АС в определении ГОСТ 34.003-90, со всеми ее процессами, людьми и технологиями. Это важное замечание, к нему мы вернемся позже, в следующих статьях.
Слово «мутация» здесь выбрано не случайно. Давайте вспомним, что в биологии под мутацией понимают стойкие изменения в геноме. Что есть геном АС? В рамках данного цикла статей под геномом АС я буду понимать ее архитектуру и структуру. А «стойкие изменения» — не что иное как результат ежедневной работы системных администраторов, сетевых инженеров, инженеров информационной безопасности. Под действиями этих изменений АС каждую минуту переходит из одного состояния в другое. Какие-то состояния характеризуются большим уровнем защищенности, какие-то меньшим. Но, сейчас для нас это не важно.
Важно понимать, модель АС — не статичный, все параметры которого описаны в технической и рабочей документации, а живой, постоянно мутирующий объект. SIEM, строя у себя внутри модель объекта защиты должен это учитывать и быть способен своевременно и оперативно ее обновлять, не отставая за темпами мутации. И, если мы хотим заставить правила корреляции «работать из коробки», необходимо чтобы они учитывали эти мутации и оперировали всегда самой актуальной картиной «мира».
Методология разработки правил корреляции
Из представленной выше «пирамиды» видно, что разрабатывая правила корреляции мы вынуждены бороться о всеми проблемами, лежащими на более низких уровнях. В борьбе с этими проблемами правила наделяют лишней логикой: дополнительной фильтрации событий, проверки на пустые значения, приведения типов данных и трансформации этих данных (к примеру извлечение имени домена из полного имени доменного пользователя), вычленения информации о том, кто и с кем взаимодействует в рамках события.
После всего этого правила обрастают таким количеством уловных выражений, поиска подстрок и регулярных выражений, что логика их работы становится понятна только их авторам и то, до момента их ближайшего отпуска. Мало того, постоянные изменения автоматизированной системы – мутации требуют регулярной актуализации правил борьбе с фалсами. Знакомая картина?
В итоге
В рамках данного цикла статей мы с вами попробуем понять, как сделать так, чтобы правила корреляции работали «из коробки».
Для решения поставленной задачи нам предстоит столкнуться со следующими проблемами:
- Потеря данных при трансформации модели «мира» на этапе нормализации.
- Отсутствие четок определенной методологии нормализации.
- Постоянная мутация объекта защиты под действием людей и процессов.
- Отсутствие методологии написания правил корреляции.
Многие из этих проблем лежат в плоскости построения правильной схемы события – наборе полей и процессе нормализации событий – фундаменте корреляционных правил. Другая часть проблем решается организационными и методологическими методами. Если нам удастся найти решение указанных проблем, то концепция работающих «из коробки» правил даст широкий положительный эффект и поднимет экспертизу, закладываемую в SIEM производителями на новый уровень.
Телеграм: t.me/ainewsline
Источник: m.vk.com