Вопрос: Что там начитывают? Ответ: Современную математику. Покажем на примере улучшения процесса IT-рекрутинга.
Под катом читателя ждёт история о том, как руководителя проектов дискретная математика до нейросетей довела, почему внедряющим ERP и управляющим продуктами стоит почитывать журнал Биоинформатика, как появилась и решается задача рекомендации связей, кому нужны графовые эмбеддинги и откуда взялись, а также мнение о том, как перестать бояться вопросов про деревья на собеседованиях, и чего всё это может стоить. Погнали!
Курс Юре Лесковека Analysis of Networks выделяется в плеяде образовательных продуктов факультета вычислительных наук университета Стенфорда. Отличие от прочих в том, что программа охватывает очень широкий спектр вопросов. Именно междисциплинарный характер делает приключение вызовом. Призом же становится универсальный язык описания сложных систем — теория графов, разобраться с которой предлагается за десять недель.
Вторым в приключении идёт CS229 Machine Learning Эндрю Ына, который рекламировать излишне.
Далее следует CS246 Mining Massive Data Sets Юре Лесковека, в котором желающим предлагается упороться MapReduce и Spark-ом.
Завершает банкет CS276 Information Retrieval and Web Search Криса Маннинга.
В качестве бонуса предлагается CS246H Mining Massive Data Sets: Hadoop Labs специально для тех, кому было мало. Опять в гостях у Юре.
В целом, обещают, что прошедшие программу приобретут навыки и знания, достаточные для поиска информации в интернете (без всяких гуглов и иже им подобных).
Ехать или шашечки
Когда-то давно мой руководитель и ментор, на тот момент — СТО в украинском Nestl?, втолковывал мне, молодому и амбициозному, порывавшемуся получить МВА чтобы стать ещё звездатее, истину о том, что на рынке труда покупают и продают опыт и знания, а не дипломы и результаты тестов.
Описанную выше специализацию можно пройти онлайн за символические $18,900.
В среднем, приключение занимает 1-2 года, но не более 3. Для получения сертификата требуется пройти все курсы с оценкой не ниже В (3.0).
Есть и другой путь.
Все материалы курсов Юре Лесковека публикуются открыто и весьма оперативно. Поэтому желающие могут страдать в любое удобное время, согласуя нагрузку со способностями. Особо одарённым рекомендую попробовать режим приключения "Это Стенфорд, лапочки!" — прохождение параллельно курсу — видеозаписи лекций выкладывают в течении пары дней, дополнительная литература доступна сразу, домашки и решения открываются постепенно.
Основы вычислительных наук на уровне, достаточном для написания нетривиальных программ.
Основы теории вероятностей.
Основы линейной алгебры.
Как я до всего этого докатился
Жил себе, не тужил. Руководил проектами внедрения SAP. Временами — выступал в роли играющего тренера по своей основной специализации — и гайки CRM крутил. Можно сказать, почти никого не трогал. Самообразованием занимался. В какой-то момент решил специализироваться в области трансформации бизнеса (или проведении организационных изменений). Задача анализа организаций до и после перемен — важная часть этой работы. Знание откуда и куда меняться — здорово помогает. Понимание связей между людьми — весомый фактор успеха. Несколько лет уделил изучению "мягких" методологий исследования организаций, да всё никак удовлетвориться не мог — вопросом: "А кто кого заборет: главнокоммивояжер главносчетовода, или же завскладом всех сильнее?" задаюсь уж несколько лет кряду. Всё ищу способ наверняка измерить.
Переломным стал 2014 год, когда я отказался от грёз о МВА и в качестве второго высшего выбрал (тут звучит барабанная дробь) снова статистику и управление информацией в новом лиссабонском университете (первое — и ныне здравствующая кафедра телекоммуникаций уже несуществующего факультета авиационных и космических систем киевского политеха + кафедра связи на военке).
В первый же семестр второй магистратуры распробовал анализ социальных сетей — одно из применений теории графов. Тогда-то и узнал, что вот-то оно что, оказывается, есть алгоритмы, которые решают задачи вроде кто с кем против команды внедрения новых технологий дружить будет, а я-то раньше не знал и голову сушил, анализируя связи людей в уме — она от этого реально пухнет. Совершенно случайно оказалось, что анализ сетей, после первых шагов, — это сплошное копание данных и машинное обучение то с учителем, то без.
Поначалу хватало классики.
Захотелось большего. Чтобы разобраться с эмбеддингами (и перепилить под свои задачи работы Маринки Житник), пришлось вникать в глубокое обучение, в чём здорово помог курс о Deep Learning на пальцах. Учитывая то, с какой скоростью группа Лесковека создаёт новое знание, для того, чтобы решать управленческие задачи автоматически, достаточно просто следить за их работой.
Зачем почитывать журнал Биоинформатика
Командообразование — задача непростая. Кого с кем в одну лодку садить не стоит — один из насущных вопросов. Особенно, когда лица новые. И местность незнакомая. А вести к далёким берегам нужно не одну лодку, но целую флотилию. И в пути обязательно тесное взаимодействие как в лодках, так и между ними. Обычные будни внедрения SAP, когда Заказчику нужно поставить сконфигурированную под его специфику систему из кучи модулей, и план проекта состоит из тысячи строк. За всю свою рабочую деятельность, ни разу никого не нанимал — всегда выдавали команду. Ты — руководитель проектов, на тебе полномочия, и крутись. Как-то так. Выкручивался.
Пример из жизни:
Я-то сам не собеседовал, но тимлидов для этого выделял. А за ресурсы — спрос с меня. И интеграция новых членов команды — тоже область ответственности руководителя проекта. Полагаю, многие согласятся с тем, что чем качественнее подготовлен список кандидатов, тем процесс приятнее для всех участников. Эту задачу мы и рассмотрим в деталях.
Природная лень требовала — найди способ автоматизации. Нашёл. Делюсь.
Немного управленческой теории. Методология Адизеса основана на базовом принципе: организации, как живые организмы, имеют свой жизненный цикл и демонстрируют предсказуемые и повторяющиеся поведенческие проявления в процессе роста и старения. На каждом этапе организационного развития компанию ожидает специфичный набор проблем. То, насколько хорошо менеджмент компании справляется с ними, насколько успешно осуществляет изменения, необходимые для здорового перехода с этапа на этап, и определяет конечный успех или неудачи этой организации.
С идеями Ицхака Адизеса я знаком уже лет десять и во многом согласен.
Личности сотрудников — как витамины — влияют на успех в определенных условиях. Известны примеры того, как успешные руководители, перейдя из одной отрасли, проваливались в другой. Бывает и хуже. Например, Марисса Майер, поднявшая поиск Google, уронила Yahoo. Уоррен Баффет говорит, что навряд-ли добился бы успеха, родившись в Бангладеш. Среда и способы взаимодействия в ней — важный фактор.
Хорошо бы предсказывать осложнения до экспериментов на живом, верно?
В эту канву ложится очередное исследование Маринки Житник, опубликованное в журнале Биоинформатика. Задача предсказания побочных эффектов при совместном применении препаратов математически близка к управленческой. Всё благодаря универсальности языка графов. Рассмотрим её детальнее.
Графовая свёрточная сеть Decagon — инструмент предсказания связей в мультимодальных сетях.
Метод состоит в построении мультимодального графа взаимодействий белок-белок, препарат-белок, и побочных эффектов от комбинации препаратов, которые представляются связями препарат-препарат, где каждый из побочных эффектов — ребро определённого типа. Decagon предсказывает конкретный вид побочного эффекта, если таковой есть, который проявляется в клинической картине.
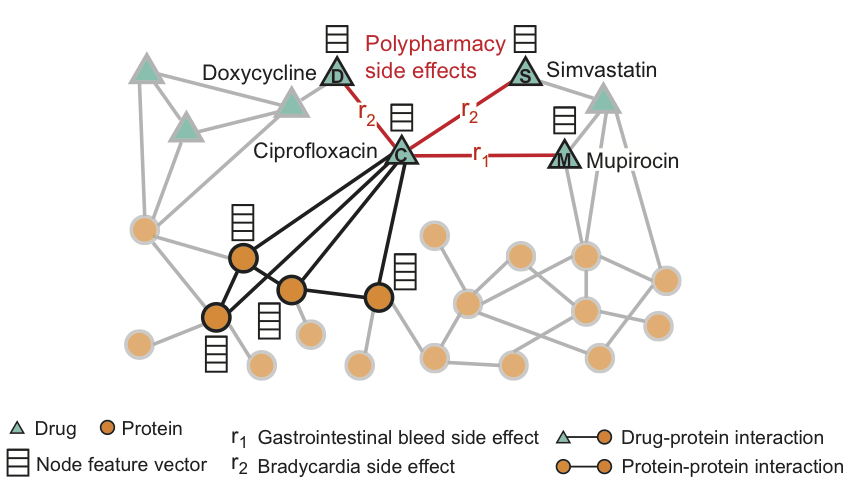
На рисунке приведен пример графа побочных эффектов, полученных из данных генома и популяции. Всего — 964 различных вида побочных эффектов (обозначенных рёбрами типа ri, i = 1, ..., 964). Дополнительная информация в модели представлена в виде векторов свойств протеинов и препаратов.
Для препарата Ciprofloxacin (узел C) подсвеченные соседи по графу отражают воздействия на четыре белка и три других препарата. Мы видим, что Ciprofloxacin (узел C), принятый одновременно с Doxycycline (узел D) или Simvastatin (узел S), повышают риск побочного эффекта, выражающегося в замедлении сердечного ритма (побочный эффект типа r2), а комбинация с Mupirocin (M) — повышает риск кровотечений желудочно-кишечного тракта (побочный эффект типа r1).
Decagon предсказывает ассоциации между парами препаратов и побочными эффектами (показаны красным) с целью идентификации побочных эффектов от одновременного приёма, т.е. тех побочных эффектов, которые нельзя связать ни с одним из препаратов из пары по-отдельности.
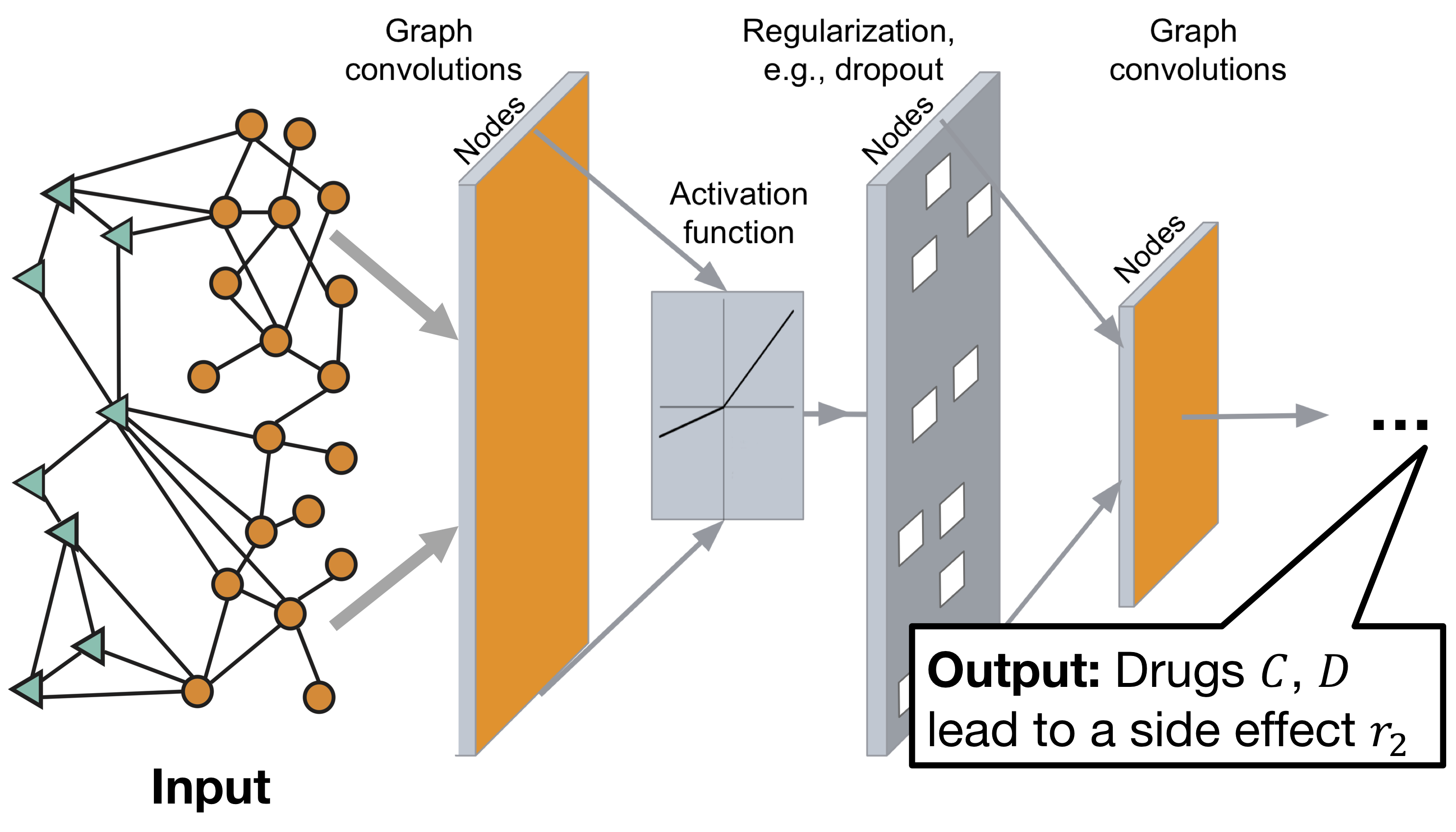
Архитектура графовой свёрточной нейронной сети Decagon:
Модель состоит из двух частей:
Энкодер: графовая свёрточная сеть (GCN) принимающая граф и производящая эмбеддинги для узлов, Декодер: тензорная факторизационная модель, использующая эти эмбеддинги для выявления побочных эффектов.
Подробнее можно узнать на сайте проекта или ниже по тексту.
Здорово, а как это к командообразованию прикрутить?
Вот для того, чтобы чувствовать себя комфортно в области исследований, подобных описанному, и стоит копнуть гранит науки. Правда, копать доведётся интенсивно — теория графов активно развивается. На то оно и остриё прогресса — там мало кому комфортно бывает.
Чтобы разобраться с деталями функционирования Decagon, совершим экскурс в историю.
Что такое графовые эмбеддинги и откуда взялись
Мне случилось наблюдать изменение в наборе передовых методов решения задач предсказания связей на графах на протяжении минувших четырёх лет. Это было забавно. Почти как в сказке — чем дальше, тем страшнее. Эволюция прошла по пути от эвристик, определявших окружение для вершины графа, к случайным бродягам, потом появились спектральные методы (анализ матриц), и вот теперь — нейронные сети.
Сформулируем задачу предсказания связей:
Рассмотрим ненаправленный граф , где — множество вершин , — множество рёбер , соединяющих вершины и .
Определим множество всех возможных рёбер , его мощность , где , — количество вершин.
Очевидно, что множество несуществующих рёбер можно выразить как .
Мы предполагаем, что в множестве есть пропущенные связи, либо связи, которые появятся в будущем, и хотим их найти.
Решение сводится к определению функции дистанции между вершинами графа, позволяющей по структуре графа , заданной на промежутке времени , предсказать появление рёбер в интервале .
Одна из первых публикаций, которая предлагает перейти от кластеризации к задаче предсказания связей в контексте изучения совместной экспрессии генов, появилась в журнале (как нетрудно догадаться) Биоинформатика в 2000 году. Уже в 2003 вышла статья Джона Клейнберга с обзором актуальных методов решения задачи прогнозирования связей в социальной сети. Его книга "Networks, Crowds, and Markets: Reasoning About a Highly Connected World" — учебник, который рекомендуется читать во время прохождения курса cs224w, большинство глав — указаны в разделе обязательной к прочтению литературы.
Статью можно считать срезом знания в узкой области, как мы видим, поначалу ассортимент методов был невелик и включал в себя:
Методы, основанные на соседях по графу — и самым очевидным из них является количество общих соседей.
Дадим определение:
Вершина является соседом по графу для вершины , если ребро .
Обозначим множество соседей вершины ,
тогда дистанция между вершинами и может быть записана как
.
Интуитивно понятно, что чем больше пересечение множеств соседей двух вершин, тем более вероятна связь между ними — так, например, большинство новых знакомств происходят с друзьями друзей.
Более продвинутые эвристики — коэффициент Жаккара (которому уже тогда было сто лет) и недавно (на то время) предложенная дистанция Адамик/Адар развивают идею путем нехитрых преобразований.
Методы, базирующиеся на путях по графу — идея в том, что кратчайший путь между двумя вершинами на графе соотносится с шансом появления связи между ними — чем путь короче, тем шанс выше. Можно пойти дальше и учитывать не только кратчайший, но и все прочие возможные пути между парами вершин, например, взвешивать пути, как это делает дистанция Катца. Уже тогда упоминается ожидаемая длина пути случайного бродяги — предтеча основы метода рекомендации знакомых в Фейсбук.
Оценим качество прогноза:
Для каждой пары вершин каждого несуществующего ребра вычислим дистанцию на графе .
Отсортируем пары по убыванию дистанции .
Отберём пар с наибольшими значениями — это наш прогноз.
Посмотрим, сколько из предсказанных рёбер появились в .
Важно помнить, что количество общих соседей и дистанция Адамик/Адар — мощные методы, задающие базовый уровень качества прогноза по одной только структуре связей, и если ваша система рекомендаций показывает результат слабее, то что-то не так.
Обобщённо, графовые эмбеддинги — это способ представления графов компактно для задач машинного обучения с помощью функции преобразования .
Мы рассмотрели несколько таких функций, самые эффективные из первых. Более широкий перечень описан в статье Клейнберга. Как мы видим из обзора, уже тогда начинали применять высокоуровневые методы, вроде разложения матриц, предварительной кластеризации, и инструменты из арсенала вычислительной лингвистики. Пятнадцать лет назад всё только начиналось. Эмбеддинги были одномерные.
Случайный бродяга в форме матрицы
Следующей вехой на пути к тем самым графовым эмбеддингам стало развитие методов случайных блужданий. Придумывать и обосновывать новые формулы для вычисления дистанции, видимо, стало влом. В некоторых приложениях, похоже, стоит просто полагаться на волю случая и довериться бродягам.
Дадим определение:
Матрица смежности графа с конечным числом вершин (пронумерованных числами от 1 до ) — это квадратная матрица размера , в которой значение элемента равно весу ребра .
Примечание: здесь мы намеренно отойдём от использовавшихся ранее индикаторов вершин и будем использовать привычные для линейной алгебры и вообще в работе с матрицами обозначения .
Проиллюстрируем рассмотренные концепции:
Пусть — граф из четырёх вершин , соединенных рёбрами.
С целью упрощения построений, примем допущение, что рёбра нашего графа — двунаправленные, т.е. .
Изобразим множества рёбер: — синим, а — зелёным цветом.
Запись графа в матричной форме открывает интересные возможности. Чтобы их продемонстрировать, заглянем в работу Сергея Брина и Ларри Пейджа, и разберёмся с тем, как работает PageRank — алгоритм ранжирования вершин графа, до сих пор являющийся важной частью поиска Google.
PageRank — придуман, чтобы искать самые лучшие страницы в интернете. Страница считается хорошей, если её ценят (ссылаются на неё) другие хорошие страницы. Чем больше страниц содержат ссылки на неё, и чем выше их рейтинг, тем выше PageRank для данной страницы.
Рассмотрим интерпретацию работы метода с помощью цепей Маркова.
Дадим определение:
Степень вершины (degree) — мощность множества соседей: ,
Различают in-degree и out-degree. Для нашего примера они эквивалентны.
Обратите внимание, что столбцы должны в сумме давать 1 (т.е. — "столбцовая стохастическая матрица"). Элементы каждого столбца задают вероятность перехода из вершины в одну из соседних вершин по графу .
Пусть будет значением PageRank для вершины , у которой исходящих рёбер. Тогда мы можем выразить PageRank для её соседа как
Таким образом, каждый из соседей вершины вносит вклад в её PageRank, и его размер прямо пропорционален авторитету соседа (т.е. его PageRank), и обратно пропорционален размеру окружения соседа.
Мы можем и будем хранить значения PageRank для всех вершин в векторе — это позволит записать уравнение компактно в виде скалярного произведения:
Представьте веб-сёрфера, который проводит бесконечное количество времени в интернете (что недалеко от реальности). В любой момент времени он находится на странице и в момент переходит по одной из ссылок на одну из соседних страниц , выбирая её случайным образом, причём все переходы — равновероятны.
Обозначим вектор с вероятностями того, что сёрфер находится на странице в момент времени . — распределение вероятностей между страницами, поэтому сумма элементов равна 1.
Вспомним, что — это вероятность перехода от вершины к вершине с учётом того, что сёрфер находится на вершине и — вероятность того, что он находится на странице в момент . Поэтому, для каждой вершины
и это значит, что
Если случайные блуждания когда-либо достигнут состояния, в котором , тогда — стационарное распределение. Вспомним, что уравнение для PageRank в векторной форме . Вывод — вектор значений PageRank — это стационарное распределение случайного бродяги!
На практике для уравнение PageRank зачастую решается степенным методом. Идея в том, что мы инициализируем вектор одинаковыми значениями и последовательно вычисляем для каждого до тех пор, пока значения не сойдутся, т.е. , где — допустимая погрешность. (Обратите внимание, что — это норма, или дистанция Минковского). Тогда значения вектора и будут оценкой Page Rank для вершин. Как правило, хватает 20-30 итераций.
Здесь мемасик про решение задач случайным перебором приобретает новые оттенки.
В описанном "ванильном" виде метод чувствителен к двум проблемам:
Т.н. "паучьи гнёзда" — вершины, ссылающиеся на себя — приводит к тому, что PageRank в них втекает. Весь. И никому больше не достаётся.
Тупики — вершины с одними только входящими рёбрами — через них PageRank утекает из системы. И заканчивается в какой-то момент. Вектор заполняется нулями.
Брин с Пейджем решили проблему 20 лет назад, выдав бродяге дробовик телепорт!
Пусть наш веб-сёрфер с вероятностью выбирает исходящую ссылку, а с вероятностью — телепортируется на случайно выбранную страницу. Обыкновенно значение , т.е. наш веб-сёрфер делает 5-7 шагов между телепортациями. Из тупика — всегда телепортируется. Уравнение для PageRank принимает вид:
(данная формулировка предполагает, что в графе нет тупиков)
Подобно нашей предыдущей матрице , мы можем определить новую матрицу
вероятности переходов. Остаётся решить уравнение аналогичным способом. Ради сохранения интриги, просто скажу, что обобщённый алгоритм описан на слайдах 37-38 в 14-й лекции курса cs224w 2017 года, в которой Юре прекрасно раскрывает все детали и показывает, как метод используется у них в Pinterest (он там главный по науке).
Вернёмся к делам менеджерским. Какой практический толк от всех этих матричных операций?
Подобрать участников групп, наиболее подходящих коллективам.
Первая задача решается построением графа связей и применением классического PageRank. Так, например, мы выловили г-на Барака Обаму из переписки, которой любезно поделилась г-жа Хиллари Клинтон в то время как прочие методы не уделили ему должного внимания.
Оставшиеся две — потребуют модификации алгоритма.
Возвращение случайного бродяги и сила связей
В реальном мире это заняло восемь лет.
Напомним, что ранее наш бродяга с телепортом перемещался в случайно выбранную вершину. А что если мы ограничим множество возможных перемещений неслучайной выборкой по какому-нибудь критерию? Так и сделали в 2006 году коллеги Юре по аспирантуре.
Усовершенствуем наш пример:
Допустим, мы что-то знаем о вершинах рассматриваемого графа , какие-то признаки.
Для каждой вершины зададим вектор из свойств .
Пусть первое из них, будет, скажем, любимый цвет глаз.
Предположим, что читатель дослужился до высоких рангов и у него уже есть команда, которая трудится над созданием нового революционного продукта. В какой-то момент возникает потребность добавить ещё одного игрока. Допустим, что пул кандидатов — достаточно обширный (например, у нас дядя работает на фабрике датасаентистов). Для того, чтобы облегчить жизнь нашему IT-рекрутеру в формировании списка тех, кого мы пригласим собеседоваться с ключевыми участниками команды (их время тоже дорого стоит) — будем решать её алгоритмически.
Допустим, вопрос, которым мы задались — подготовить ранжированный по критерию потенциальной совместимости список кандидатов, наиболее подходящих двум нашим игрокам, и — им голубоглазые симпатичны.
Мы знаем, что предыдущее успешное сотрудничество — залог успеха сотрудничества будущего.
Поэтому построим граф связей датасаентистов из истории командных выступлений в соревнованиях на какой-нибудь площадке, вроде Kaggle или Hackerrank, которая позволяет участникам не только мериться математикой, но и общаться на форумах, ставить лайки кернелам и всё такое (предположим, что читатель уже сделал это).
Дадим определение:
Персонализированной выборкой по значению критерия , назовём подмножество вершин графа :
Остаётся построить персонализированную матрицу вероятности переходов:
И решить уравнение относительно , как мы это уже не раз делали. В векторе содержатся значения персонализированного PageRank по отношению к нашей выборке — наиболее относящиеся к ней вершины. Для решения вопроса с поиском потенциальных кандидатов, отсортируем содержимое по убыванию значений — нас интересует вершина списка.
Именно этот метод отвечает за подготовку 80% рекомендаций в Pinterest.
Частный случай, когда , называется Random Walks with Restarts — бродяги возвращаются и возвращаются в одну интересующую нас вершину. В результате мы получаем меру близости для каждой вершины графа по отношению к той единственной. И это решает задачу предсказания связей лучше, чем позволяет дистанция Адамик/Адар.
Добавим ещё улучшений:
Вспомним, что рёбра нашего графа имеют веса .
Это позволит задать взвешенную матрицу вероятности переходов:
Бродяга будет совершать переходы по-прежнему случайно, но уже не равновероятно!
Внимательный читатель уже задался вопросом о том, как же эти веса померять.
Этим же озадачились в Facebook в 2011. Нужно было построить систему рекомендации друзей из друзей друзей, да так, чтобы максимизировать создание новых связей. И первым шагом было создание взвешенного графа связей между пользователями из информации в их профилях и истории взаимодействия (лайки, сообщения, совместные фото и прочее). Как-то силу дружбы в интернете померять.
где — вектор свойств вершин и соединяющего их ребра, т.е. , а — вектор весов, которые предстоит выучить из данных.
Здесь подготовленный читатель узнает линейную модель, а неподготовленный — задумается о том, что стоит пройти открытый курс машинного обучения, чтобы разобраться с градиентным спуском, с помощью которого мы и выучим значения весов в векторе — они покажут, как влияют лайки и сообщения на дружбу в интернете.
Зачем нам это всё надо?
Кроме того, что рассматриваемый подход позволяет предсказывать связи ещё лучше, мы можем выучить правила успешного командообразования. И узнать, на что обращать внимание в будущем.
Напомним условия нашего упражнения. Мы наблюдаем за развитием сотрудничества (совместное участие в соревнованиях) в группе условных датасаентистов на интервале (например, один календарный месяц) и хотим предсказать командообразование в интервале (другой месяц). Кроме участия в соревнованиях, мы отслеживаем общение на форумах, лайки кернелов, и ещё чего заблагорассудится. Всю собранную информацию храним в матрице (её колонки — вектора , — размерности векторов свойств вершин и рёбер , соответственно) и графе для двух интервалов времени.
Подготовим данные для машинного обучения.
Для каждой вершины :
1) определим множество друзей друзей:
2) и построим суб-графы связей с друзьями и друзьями друзей,
3) выделим множество вершин, , с которыми образовались связи — это наши позитивные примеры для обучения,
4) все неслучившиеся связи из множества — это наши негативные примеры для обучения.
Наша задача — подобрать такой вектор весов , при котором позитивные примеры из множества получат более высокое значение Personalized PageRank относительно , чем негативные примеры.
Для этого зададим функцию потерь, которую будем минимизировать:
где — штраф за нарушение условия, — сила регуляризации весов , — вектор с решениями уравнения относительно для суб-графа друзей друзей отдельно взятой вершины .
Забавная деталь — градиент этой функции вычисляется так же, как и PageRank, степенным методом. Подробности — в 17-й лекции редакции 2014 года, слайды 9-27.
Вот так выглядело острие прогресса в момент моего первого знакомства с курсом cs224w.
Путь случайного бродяги и вершина в векторе
А потом наступило торжество лени!
Известно, что теорию графов придумал Леонард Эйлер, когда ему наскучило решать нерешаемую задачу про те мосты, что стоят сейчас в Калининграде. Вместо того, чтобы голову сушить почём зря, он изобрёл математический аппарат, позволяющий доказать принципиальную невозможность решения головоломки.
В лучших традициях вычислительных наук, мы тоже будем лениться и зададимся задачей поиска функции, которая бы позволила отойти от одномерных представлений узлов и перейти к многомерным векторам свойств.
Здесь мы знакомимся с графовыми эмбеддингами в современном понимании этого термина.
Формально, мы хотим:
1) Определить энкодер (функцию соответствия ENC, которая задаёт преобразование узла в вектор ); 2) Определить функцию подобия узлов (меру близости в графе, который мы будем подавать на вход энкодера); 3) Оптимизировать параметры энкодера таким образом, что:
Мы стремимся к тому, чтобы вершины, близко расположенные в графе, получали близкое представление в векторном отображении. Другими словами, чтобы угол между двумя полученными векторами был минимален.
Здорово, а как её определить, эту близость в графе?
Например, будем считать, что вес ребра — хорошая мера близости и её можно приближенно считать равной скалярному произведению для эмбеддингов двух узлов. Функция потерь для такого случая примет вид:
остаётся найти (например, градиентным спуском) матрицу , которая минимизирует .
Альтернативный подход — определить окружение для вершины шире, чем множество соседей.
В этом нам помогут блуждания по графу. Первый проект, использовавший этот подход — DeepWalk. Суть метода заключается в том, что мы будем запускать бродягу гулять по графу случайным образом из каждой вершины , и скармливать короткие последовательности фиксированной длины посещённых за время его прогулки вершин в word2vec.
Здесь интуиция состоит в том, что распределение вероятности посещения вершин графа — степенной закон — очень похож на распределение вероятности появления слов в человеческих языках. И раз word2vec работает для слов, то и для графов может. Попробовали — получилось!
В DeepWalk бродяга реализует марковский процесс первого порядка — из каждой вершины мы переходим в соседние, согласно вероятностям из взвешенной матрицы смежности (либо её производных, вроде ). То, откуда мы пришли в вершину — никак не влияет на выбор следующего шага.
«Всякий, кто соглашается с арифметическими методами генерации, разумеется, грешен. Как было неоднократно показано, нет такой вещи, как случайное число — есть лишь методы создания таких чисел, и жесткая арифметическая процедура, разумеется, не является таким методом… Мы лишь имеем дело с рецептами приготовления для создания чисел...»
— Джон фон Нейман
Здесь остаётся посоветовать стремящимся к праведной жизни найти в продаже альбом «Black and White Noise» — в 1995 Джордж Марсаглия записал на компакт-диск массив байтов, полученных оцифровкой шума с усилителя во время проигрывания рэпчика и назвал его соответственно.
Развитием метода является node2vec, в котором реализован марковский процесс второго порядка — мы смотрим, откуда пришли, и это влияет на вероятности выбора направления следующего шага. Рассмотрим, как это работает.
Допустим, мы запускаем бродягу гулять по графу из вершины , ей смежна вершина , вершины и — в двух шагах, а — в трёх. После каждого шага, мы можем выполнить одно из трёх возможных действий: 1) вернуться ближе к ; 2) исследовать вершины на той же дистанции от , что и та, в которой сейчас находимся; 3) удалиться от .
Реализуется эта стратегия с помощью двух параметров: — задаёт вероятность вернуться в предыдущую вершину; — задаёт баланс между поиском вширь и поиском вглубь.
Эти параметры определяют ненормированные вероятности перехода следующим образом:
Допустим, мы находимся в вершине и пришли в неё из вершины . Для ребра мы назначим вес (ненормированную вероятность) . Для ребра — (как и для всех прочих рёбер, ведущих в вершины, равноудалённые от ). Для уводящего вдаль от ребра — .
Затем — нормируем вероятности (чтобы сумма была равна 1), и совершим следующий шаг.
Нас интересует последовательность посещённых вершин — её мы и будем отправлять в word2vec (разобраться с ним поможет вот эта статья, либо лекция 8 из курс о Deep Learning на пальцах). Подбор стратегий для бродяги, оптимальных для решения конкретных задач — область активного исследования. Например, node2vec, с которым мы ознакомились, — чемпион в классификации вершин (например — определении токсичности препаратов, или пола/возраста/расы участника социальной сети).
Оптимизировать будем вероятность появления вершин на пути бродяги, функция потерь:
в её явной форме — достаточно дорогое по вычислительной нагрузке удовольствие
Итак, мы разобрались с тем, как получить векторное представление вершин. Дело в шляпе!
Как готовить эмбеддинги для рёбер:
Нам нужно определить оператор, позволяющий для любой пары вершин и построить векторное представление , независимо от того, связаны ли они на графе. Таким оператором может выступать:
a) среднее арифметическое: ; b) произведение Адамара: ; c) взвешенная L1 норма: ; d) взвешенная L2 норма: .
В экспериментах наиболее устойчиво себя ведёт произведение Адамара.
На всякий случай, вспомним Free Lunch Theorem:
Ни один алгоритм не является универсальным — стоит проверить несколько методов.
Развитием node2vec является проект OhmNet, который позволяет объединить несколько графов в иерархию и построить эмбеддинги вершин для разных уровней иерархии. Изначально был разработан для моделирования связей между белками в разных органах (а они ведут себя по-разному в зависимости от местоположения).
Проницательный читатель здесь увидит сходство с организационной структурой и бизнес-процессами.
А мы же — вернёмся к примеру из области IT-рекрутинга — подбору канидатов, наиболее подходящих уже сложившемуся коллективу. Ранее мы рассматривали одномодальные графы связей условных датасаентистов, полученные из истории взаимодействия (в одномодальном графе вершины и связи — одного типа). В реальности же количество социальных кругов, в которые может быть включен индивидуум — более одного.
Допустим, кроме истории совместных участий в соревнованиях, мы собрали ещё и информацию о том, как датасаентисты общались в нашем уютном чате. Теперь у нас уже два графа связей, и OhmNet отлично подходит для решения задачи создания эмбеддингов из нескольких структур.
Теперь — о недостатках методов, построенных на неглубоких энкодерах — внутри word2vec всего один скрытый слой, веса которого и кодируют эмбеддинги. На выходе мы получаем таблицу соответствия вершина-вектор. Всем подобным подходам свойственны следующие ограничения:
Каждая вершина кодируется уникальным вектором и модель не предполагает совместного использования параметров;
Мы можем кодировать только те вершины, которые модель видела во время обучения — для новых вершин ничего сделать не сможем (кроме как переобучить энкодер заново);
Никак не учитываются вектора свойств вершин.
От обозначенных недостатков свободны графовые свёрточные сети. Мы подобрались к Decagon!
Наши дни — случайный бродяга для всех и каждого
Про бродяг мне ещё повезло написать первый магистерский диплом и защитить его в далёком 2003, а вот с глубоким обучением пришлось пройти классическим путём, чтобы разобраться с тем, что там под капотом. А там забавно.
Для начала посмотрим, почему стандартные методы глубокого обучения — не подходят графам.
Графы — это вам не котики!
Современный набор инструментов глубокого обучения (многослойные, свёрточные, и рекуррентные сети) оптимизирован для решения задач на достаточно простых данных — последовательностях и решётках. Граф — структура посложнее. Одна из проблем, которая помешает нам взять матрицу смежности и отправить её в нейронную сеть — изоморфизм. В нашем игрушечном графе , состоящем из вершин , для построения матрицы смежности , мы предположили сквозную нумерацию . Нетрудно видеть, что мы можем пронумеровать вершины иначе, например , или — всякий раз получая новую матрицу смежности одного и того же графа.
В случае с котиками, нашей сети пришлось бы обучиться их распознавать при всех возможных перестановках строк и столбцов — та ещё задачка. В качестве упражнения попробуйте изменить нумерацию точек на картинке ниже таким образом, чтобы при последовательном их соединении получился котик.
Следующая незадача у графов с обычными нейронными сетями — стандартная размерность входа. Когда мы работаем с изображениями, то всегда нормируем размер картинки для того, чтобы подать её на вход сети — он фиксированного размера. С графами такой фокус не пройдёт — количество вершин может быть произвольным — ужимать матрицу связности до заданной размерности без потери информации — тот ещё вызов.
Решение — будем строить новые архитектуры, вдохновляясь структурой графов.
Для этого воспользуемся простой двухшаговой стратегией:
Для каждой вершины построим вычислительный граф с помощью бродяги;
Соберём и трансформируем информацию о соседях.
Напомним, что свойства вершин мы храним в векторах — столбцах матрицы и наша задача — для каждой вершины собрать свойства соседних вершин , чтобы получить вектора эмбеддингов . Вычислительный граф может быть произвольной глубины. Рассмотрим вариант с двумя слоями.
Нулевой слой — это свойства вершин, первый — промежуточная аггрегация с помощью некой функции (обозначена вопросительным знаком), второй — окончательная аггрегация, которая и производит интересующие нас вектора эмбеддингов.
где и — веса модели, которые мы выучим градиентным спуском, применяя одну из рассмотренных функций потерь, а — нелинейность, например RELU: .
И здесь мы оказываемся на перепутье — в зависимости от стоящей задачи, можем:
заняться обучением без учителя и воспользоваться любой из рассмотренных ранее функций потерь — бродяги, либо веса рёбер. Полученные веса будут оптимизированы для того, чтобы вектора похожих вершин размещались компактно;
начать обучение с учителем, например — решать задачу классификации, задавшись вопросом будет ли препарат токсичен.
Для задачи бинарной классификации функция потерь примет вид:
где — класс вершины , — вектор весов, а — нелинейность, например сигмоида: .
А мы двинемся дальше и рассмотрим принцип работы GraphSAGE — предвестника Decagon.
Для каждой вершины мы будем аггрегировать информацию от соседей , и её самой.
где — обобщённое обозначение функции аггрегации — главное — дифферинцируемой.
Усреднение: возьмём взвешенное среднее от соседей
Пулинг: поэлементное среднее/максимальное значение
LSTM: взболтать окружение (не смешивать!) и запустить в LSTM
В Pinterest, например, напихали туда многослойных перцептронов и выкатили в прод PinSAGE.
В решении задачи предсказания функций белков в органах особо отличились аггрегаторы пулинг и LSTM (которые навсегда). Рассмотрим её детальнее и приведём аналогии с процессами командообразования и IT-рекрутинга.
Проведём очевидные параллели:
Вводные: орган и белок, цель — определить функцию, выполняемую этим белком в данном органе.
В мире командообразования, вводные: проект/подразделение и специалист, цель — определить роль в команде.
С развитием технологий и роста количества данных о взаимодействиях между веществами, размечать их с помощью людей — задача за гранью выполнимого. Похоже, технологическая сингулярность уже наступила в отдельных областях знания. Например, во время одного из моих первых пресейлов, когда мы продавали систему построения графиков смен для нескольких тысяч работников центра поддержки, в голову запала оценка сложности. Один руководитель может выровнять загрузку с учётом типов найма (постоянные/временные) сотрудников, выслуги лет, необходимых навыков, и прочего — вручную — не более, чем для 30 человек.
В похожих органах белки выполняют биологически близкие функции.
Задача — определить вероятность выполнения одной из множества функций (multi-label node classification task) — один белок может выполнять несколько ролей в разных органах. Решение — используем графы взаимодействий между белками в разных органах. Свойствами вершин (белков) будут их генетические структуры и иммунологические сигнатуры (эти данные — достаточно фрагментарные — недоступны для 42% белков). Тренируем графовую свёрточную сеть GraphSAGE, и выучиваем веса, общие для всех вершин — теперь мы знаем обобщённые правила аггрегации информации о соседях.
Полученные веса позволяют генерировать эмбеддинги для ранее не встречавшихся графов!
И это позволяет определять функции белков в ранее не исследованных органах, что для медицины — прорыв, так как не всякое исследование можно провести, оставив объект в живых. Такого рода информация помогает разрабатывать новые препараты направленного действия, что безусловно здорово.
Вот теперь-то мы разобрались с деталями, необходимыми для понимания функционирования Decagon. Напомним, метод состоит в построении мультимодального графа взаимодействий белок-белок, препарат-белок, и побочных эффектов от комбинации препаратов, которые представляются связями препарат-препарат, где каждый из побочных эффектов — ребро определённого типа ri. Каждый из побочных эффектов моделируется изолированно. Для каждой вершины-препарата мы строим 964 (по количеству побочных эффектов) вычислительных графа.
Затем — для каждого препарата нелинейно строится вычислительный граф, объединяющий полученные на предыдущем шаге графы с графами взаимодействия препарат-белок, и белок-белок.
Формально, для каждого слоя мы вычисляем
где — нелинейность, например RELU. Как видим, в Decagon использован простейший вариант графовой свёрточной сети — взвешенная сумма. Очевидно, что ничто не мешает усложнить модель, аналогично GraphSAGE. Полученные на финальном слое эмбеддинги вершин подаём на вход декодера, который возвращает вероятности возникновения каждого из побочных эффектов при совместном приёме препаратов.
Разберёмся с тем, как этот декодер функционирует.
Его задача — реконструировать маркированные рёбра в графе, полагаясь на выученные эмбеддинги. Каждый тип ребра обрабатывается по-своему. Для каждой тройки параметров , декодер вычисляет функцию:
и подаёт результат в сигмоиду, чтобы определить вероятность появления ребра заданного типа:
Итого, у нас есть сквозная (end-to-end) модель энкодер-декодер, в которой четыре типа параметров: (i) — веса нейронных сетей для аггрегации каждого типа отношений в графе, (ii) — матрицы параметров отношений препарат-белок и белок-белок, (iii) — общая матрица параметров побочных эффектов, и (iv) — матрицы параметров каждого побочного эффекта.
Все эти параметры — выучиваются градиентным спуском с использованием функции потерь кросс-энтропии и негативного семплинга для выбора несуществующих рёбер.
Здесь можно выдохнуть — следующее обновление острия прогресса ожидается через полгода.
Подытоживая всё сказанное выше — в сложных системах с кучей взаимосвязей, которые мы моделируем с помощью графов, отчётливо проявляются характерные черты: 1) гомофилия — подобное — притягивается; и 2) старое правило "Скажи мне, кто твой друг, и я скажу тебе, кто ты" — по-прежнему актуально. Здорово, что для того, чтобы обуздать всё это буйство связей теперь уже не нужно жечь нервные клетки, а можно просто взять и посчитать.
Как и где такие данные хранить и откуда брать
Кратко — в ОЗУ — так быстрее.
Моя личная позиция по поводу обработки графов в оперативной памяти на одной машине связана с тем, что размер структурированных данных (а именно из них мы и строим графы) растёт медленнее, чем объемы доступной за вменяемые деньги ОЗУ. Например, все исследования генома, проведённые человечеством из базы GenBank уместятся в 1 Тб, и машина с таким объемом памяти сейчас стоит примерно столько же, сколько автомобиль гольф-класса — рабочий инструмент торгового представителя, ездящего по аптекам. Кластерные вычисления — это здорово, но распределённый подсчёт триад для большого графа из-за необходимости координировать и собирать результаты вычислений занимает в разы (если не на порядок) больше времени, чем та же операция в SNAP при соразмерных вычислительных мощностях.
Рассмотрим несколько доступных на сегодняшний день инструментов и способов работы.
Достаточно подробное описание возможных конструкций из точек и линий в одноимённой работе дают причастные к созданию первой графовой базы данных Neo4j, в которой реализована модель графа со свойствами (property graph).
Такой подход позволяет построить мультимодальный граф, в котором много разных сущностей можно связать различными типами связей. Рабочая задача, с которой сразу обратился к преподавателю, — связать вместе (i) бизнес-процессы, (ii) отношения между сотрудниками, и (iii) план проекта, в котором куски работы — отдельные задачи — так или иначе влияют на первые два. Ответ довелось искать самостоятельно.
Альтернативный пример таких данных — сама статья и все к ней причастные:
Кроме того, вклад Neo4j в индустрию заключается в создании декларативного языка Cypher, реализующего модель графа со свойствами и оперирующего в форме, подобной SQL, следующими типами данных: вершины, отношения, словари, списки, целые, с плавающей точкой, и бинарные числа, и строки. Пример запроса, возвращающего список фильмов с участием Николь Кидман:
MATCH (nicole:Actor {name: 'Nicole Kidman'})-[:ACTED_IN]->(movie:Movie) WHERE movie.year < $yearParameter RETURN movie
Neo4j с помощью костылей можно заставить работать в памяти.
Стоит также упомянуть Gephi — удобное средство визуализации и раскладки графов на плоскости — первый инструмент анализа сетей, из опробованных лично. С натяжкой можно считать, что в Gephi возможно реализовать граф со свойствами вершин и рёбер, правда работать с ним будет не очень удобно, да и набор алгоритмов для анализа ограничен. Это нисколько не умаляет достоинств пакета — для меня он на первом месте в ряду средств визуализации. Освоив внутренний формат хранения данных GEXF, вы сможете создавать впечатляющие изображения. Привлекает возможность лёгкого экспорта в веб, а также — возможность задавать для вершин и рёбер свойства во времени и получать в результате затейливые анимации — строил так маршруты движения коммивояжеров из данных продаж. Всё благодаря раскладке графов на карте по координатам вершин — стандартной части пакета.
Сейчас большую часть исследований провожу аналитически, картинки рисую на финише.
Мой поиск инструментов и способов обработки данных в сложно связанных системах продолжается. Три года назад нашёл решение для работы с мультимодальными графами. Библиотека SNAP Юре Лесковека — инструмент, который он разработал для себя и померял им уже много чего. Использую Snap.py — версию для Python (прокси к функциям SNAP, реализованным на C++) и набора из около трёх сотен доступных операций мне хватает в большинстве случаев.
Недавно Маринка Житник выпустила MAMBO — набор инструментов (внутри — SNAP) для работы с мультимодальными сетями и туториал в виде серии блокнотов Jupyter с образцово-показательным анализом генетических мутаций.
Наконец, есть SAP HANA Graph — там внутри ML, SQL, OpenCypher — всё, чего душе угодно.
В пользу SAP HANA тот факт, что копать скорее всего доведётся хорошо структурированные данные транзакций из ERP, а чистые данные — многого стоят. Ещё один плюс — мощные инструменты поиска суб-графов по заданным шаблонам — полезная и непростая задача, реализации которой в других пакетах не встречал и использовал специализированные программы. Бесплатная лицензия для разработчика предоставляет базу размером 1 Гб — как раз хватит, чтобы поиграться с достаточно большими сетями. Забавный вызов — набор аналитических алгоритмов из коробки — мал, PageRank нужно будет реализовать самостоятельно. Для этого потребуется освоить GraphScript — новый язык программирования, но это уже мелочи. Как говорил мой тренер по гребному слалому, для мастера — это пыль!
Теперь о том, где взять данных для того, чтобы построить из них графов. Несколько идей:
Можно сказать, здесь будет последнее предупреждение о рисках, связанных с этой вечеринкой.
Как вы понимаете, дамы и господа, задача программы — отражать состояние дел на острие прогресса очень продуктивной и щедро профинансированной исследовательской группировки. Это как Ленинград, только про современную математику. Возможны побочные эффекты:
Даннинга-Крюгера, модифицированный, без эйфории новичка и плато совершенства. Лесковека попробуй догони.
Скука в провинции у моря. Из 400 человек на курсе, которым дали матаппарат, заставили написать проект, и сдать экзамен в первую же сессию во время моей второй магистратуры, графы зашли полутора. Преподаватели в их исследовательской деятельности — так и остались на уровне модулярности и мер центральности. На митапах про питон и данные тоже грустно. В общем, если не умеете развлечь себя самостоятельно — я предупреждал.
Гордость за славянский акцент в английской речи.
Памятка воспроизводителю
Привет, воспроизводитель!
В приключении, которое нам подарил Юре Лесковек, тебе потребуется свободное время. Курс состоит из 20 лекций, четырёх домашек, на каждую из которых рекомендуется выделить около 20 часов, рекомендованной литературы, а также — обширного списка дополнительных материалов, которые позволят составить первое впечатление о состоянии дел на острие прогресса в любой из рассмотренных тем.
Для выполнения заданий настоятельно рекомендуется использовать библиотеку SNAP (в каком-то смысле, весь курс можно рассматривать как обзор её возможностей).
Кроме того, можно попробовать реализовать собственный проект или написать туториал по понравившейся теме.
Краткое содержание лекций 2017 года:
1. Вступление и структура графов Анализ сетей — это универсальный язык описания сложных систем и сейчас — самое время с ним разобраться. Курс акцентируется на трёх направлениях: свойства сетей, модели, и алгоритмы. Начнём со способов представления объектов: узлы, рёбра, и способы их организации.
2. Всемирная паутина и модель случайного графа Мы узнаем, почему интернет похож на бабочку, и познакомимся с понятием сильно связанных компонентов. Как измерять сети — основные свойства: распределение степеней узлов, длина пути, и коэффициент кластеризации. И познакомимся с моделью случайного графа Эрдоша-Рейни.
3. Феномен малого мира Замеряем основные свойства случайного графа. Сравним его с реальными сетями. Поговорим о числе Эрдоша и том, как тесен мир. Вспомним Стенли Милграма и про шесть рукопожатий. Наконец, опишем всё происходящее математически (модель Ваттса-Строгатца).
4. Децентрализованный поиск в малом мире и пирнинговые сети Как ориентироваться в распределённой сети. И как работают торренты. Собираем всё в кучу — свойства, модели, и алгоритмы.
5. Приложения анализа социальных сетей Меры центральности. Люди в интернете — как кто кого оценивает. Эффект подобия. Статус. Теория структурного баланса.
6. Сети с разнозначными рёбрами Баланс в сетях. Взаимные лайки и статус. Как кормить троллей.
7. Каскады: модели, основанные на решениях Распространение в сетях: диффузия инноваций, сетевые эффекты, эпидемии. Модель коллективного действия. Решения и теория игр в сетях.
8. Каскады: вероятностные модели распространения информации Модели распространения эпидемий, основанные на случайных деревьях. Распространение болячек. Независимые каскады. Механика вирусного маркетинга. Смоделируем взаимодействия между заражениями.
9. Максимизация влияния Как создавать большие каскады. А вообще, насколько задача сложна? Итоги экспериментов.
10. Выявление заражения Что общего у заразы и новостей. Как быть в курсе самого интересного. И где размещать сенсоры в водопроводе.
11. Степенной закон и предпочтительное присоединение Процесс роста сети. Масштабно-инвариантные сети. Математика степенной функции распределения. Следствия: устойчивость сети. Модель предпочтительного присоединения — богатые богатеют.
12. Модели растущих сетей Меряем хвосты: экспотенциальный против степенного. Эволюция социальных сетей. Вид на всё это с высоты птичьего полёта.
13. Графы Кронекера Продолжаем полёт. Модель лесного пожара. Рекурсивная генерация графов. Стохастические графы Кронекера. Эксперименты с реальными сетями.
14. Анализ связей: HITS и PageRank Как упорядочить интернет? Хабы и Авторитеты. Находка Сергея Брина и Ларри Пейджа. Пьяный бродяга с телепортом. Как делать рекомендации — опыт Pinterest.
15. Сила слабых связей и структура сообществ в сетях Триады и потоки информации. Как выделить сообщества? Метод Гирвана-Ньюмана. Модулярность.
17. Биологические сети Взаимодействия белков. Выявление цепочек болезненных реакций. Определение молекулярных аттрибутов, например функций белков в клетках. Что делают гены? Навешиваем ярлыки.
18. Пересекающиеся сообщества в сетях Различные социальные круги. От кластеров к пересекающимся сообществам.
19. Изучение представлений на графах Автоматическое формирование фичей — просто праздник для ленивых. Графовые эмбеддинги. Node2vec. От отдельных графов — к сложным иерархическим структурам — OhmNet.
20. Сети: пара забавностей Жизненный цикл участника абстрактного сообщества. И как управлять поведением сообществ с помощью бейджей.
Думаю, после погружения в теорию графов, вопросы про деревья будут уже не страшны. Впрочем, это — всего лишь мнение любителя, ни разу в жизни на позицию разработчика не собеседовавшегося.