Давайте обрабатывать звук на Go
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-09-28 11:00
алгоритмы распознавания речи, распознавание образов, разработка по
Дисклеймер: Я не рассматриваю какие-либо алгоритмы и API для работы со звуком и распознаванием речи. Эта статья о проблемах при работе с аудио и об их решении с помощью Go.

phono — прикладной фреймворк для работы со звуком. Его основная функция — создать конвейер из разных технологий, который обработает звук за вас нужным вам образом.
При чём тут конвейер, к тому же из разных технологий и зачем ещё один фреймворк? Сейчас разберёмся.
Откуда звук?
К 2018 году звук стал стандартным способом взаимодействия человека с технологиями. Большинство IT-гигантов создали своего голосового помощника или делают это прямо сейчас. Голосовое управление уже есть в большинстве операционных систем, а голосовые сообщения — типичная функция любого мессенджера. В мире около тысячи стартапов работают над обработкой естественного языка и около двух сотен над распознаванием речи.
С музыкой похожая история. Она играет из любого устройства, а звукозапись доступна каждому, у кого есть компьютер. Музыкальный софт разрабатывают сотни компаний и тысячи энтузиастов по всему миру.
Общие задачи
Если вам приходилось работать со звуком, то следующие условия должны звучать знакомо:
- Аудио надо получить из файла, устройства, сети и т.д.
- Аудио надо обработать: добавить эффекты, перекодировать, проанализировать и т.п.
- Аудио надо передать в файл, устройство, сеть и т.д.
- Данные передаются небольшими буферами
Получается обычный конвейер — есть поток данных, который проходит несколько стадий обработки.
Решения
Для наглядности, возьмём задачу из реальной жизни. Например, нужно преобразовать голос в текст:
- Записываем аудио с устройства
- Удаляем шумы
- Эквализируем
- Передаём сигнал в API для распознавания речи
Как и любая другая задача, эта имеет несколько решений.
В лоб
Только для хардкорных велосипедистов программистов. Записываем звук непосредственно через драйвер звуковой карты, пишем умный шумодав и многополосный эквалайзер. Это очень интересно, но можно на несколько месяцев забыть о своей изначальной задаче.
Долго и очень сложно.
По-нормальному
Альтернатива — использовать существующие API. Записать аудио можно с помощью ASIO, CoreAudio, PortAudio, ALSA и прочих. Для обработки тоже есть несколько видов плагинов: AAX, VST2, VST3, AU.
Богатый выбор не означает, что можно использовать всё сразу. Обычно действуют следующие ограничения:
- Операционная система. Не все API доступны на всех операционных системах. Например, AU — нативная технология OS X и доступна только там.
- Язык программирования. Большинство аудио библиотек написаны на С или С++. В 1996 году компания Steinberg выпустила первую версию VST SDK, до сих пор самый популярный стандарт плагинов. Спустя 20 лет уже не обязательно писать на С/С++: для VST есть обёртки на Java, Python, C#, Rust и кто знает на чём еще. Хоть язык и остаётся ограничением, но теперь звук обрабатывают даже на JavaScript.
- Функционал. Если задача простая и понятная, не обязательно писать новое приложение. Тот же FFmpeg умеет очень многое.
В этой ситуации сложность зависит от вашего выбора. В худшем случае придётся иметь дело с несколькими библиотеками. И если совсем не повезёт, со сложными абстракциями и абсолютно разными интерфейсами.
Что в итоге?
Нужно выбирать между очень сложным и сложным:
- либо иметь дело с несколькими низкоуровневыми API, чтобы писать свои велосипеды
- либо иметь дело с несколькими API и пытаться их подружить
Неважно какой способ выбран, задача всегда сводится к конвейеру. Используемые технологии могут отличаться, но суть неизменна. Проблема в том, что опять вместо решения реальной задачи, приходиться писать велосипед конвейер.
Но есть выход.
phono

phono создан, чтобы решить общие задачи — "получить, обработать и передать" звук. Для этого он использует конвейер, как самую естественную абстракцию. В официальном блоге Go есть статья, которая описывает паттерн pipeline (англ. конвейер). Главная идея pipeline в том, что есть несколько стадий обработки данных, которые работают независимо друг от друга и обмениваются данными через каналы. То, что надо.
А почему Go?
Во-первых, большинство аудио программ и библиотек написаны на C, а Go часто упоминается в качестве его преемника. К тому же, есть cgo и довольно много биндингов для существующих аудио библиотек. Можно брать и пользоваться.
Во-вторых, по моему личному мнению, Go — хороший язык. Не буду углубляться, но отмечу его многопоточность. Каналы и горутины сильно упрощают реализацию конвейера.
Абстракции
Сердцем phono является тип pipe.Pipe (англ. труба). Именно он реализует pipeline. Как и в образце из блога, предусмотрено три вида стадий:
pipe.Pump(англ. насос) — получение звука, только выходные каналыpipe.Processor(англ. обработчик) — обработка звука, входные и выходные каналыpipe.Sink(англ. раковина) — передача звука, только входные каналы
Внутри pipe.Pipe данные передаются буферами. Правила, по которым можно строить pipeline:
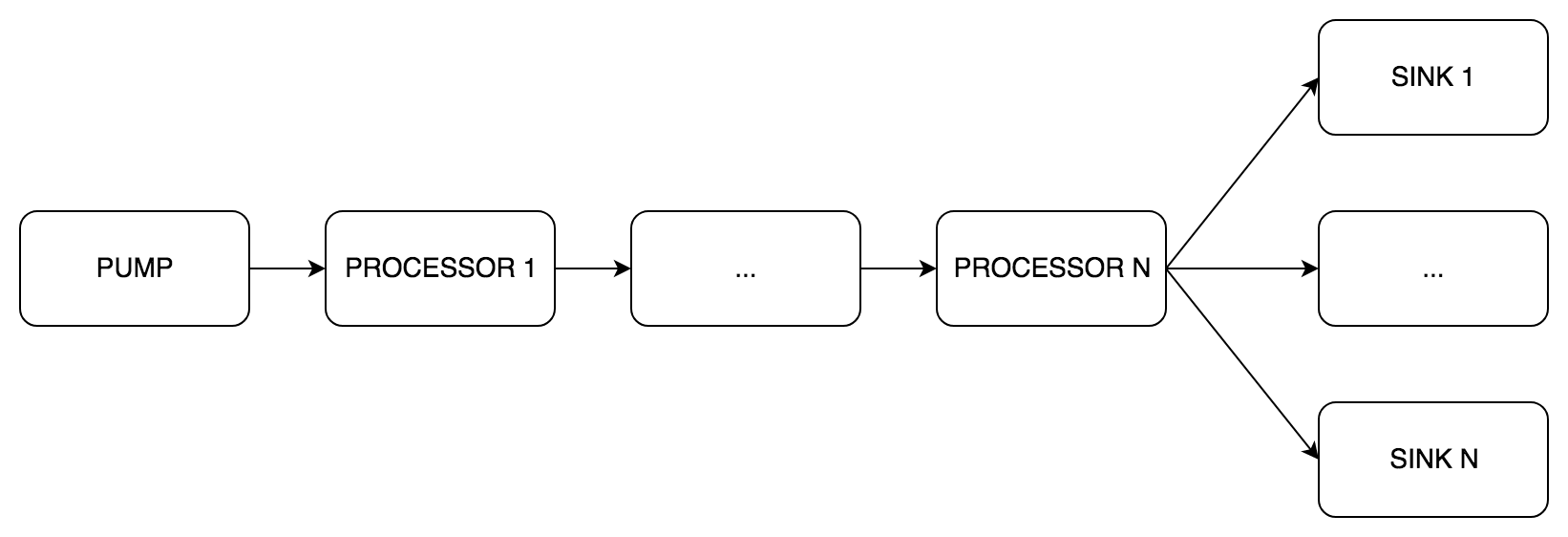
- Один
pipe.Pump - Несколько
pipe.Processor, размещённых последовательно друг за другом - Один или несколько
pipe.Sink, размещённых параллельно - Все компоненты
pipe.Pipeдолжны иметь одинаковые:
- Размер буфера (сообщения)
- Частоту дискретизации
- Число каналов
Минимальная конфигурация — Pump и один Sink, остальное опционально.
Разберём несколько примеров.
Простой
Задача: воспроизвести wav файл.
Приведём её к виду "получить, обработать, передать":
- Получаем аудио из wav файла
- Передаём аудио в portaudio устройство

Аудио считывается и сразу воспроизводится.
Код
package example import ( "github.com/dudk/phono" "github.com/dudk/phono/pipe" "github.com/dudk/phono/portaudio" "github.com/dudk/phono/wav" ) // Example: // Read .wav file // Play it with portaudio func easy() { wavPath := "_testdata/sample1.wav" bufferSize := phono.BufferSize(512) // wav pump wavPump, err := wav.NewPump( wavPath, bufferSize, ) check(err) // portaudio sink paSink := portaudio.NewSink( bufferSize, wavPump.WavSampleRate(), wavPump.WavNumChannels(), ) // build pipe p := pipe.New( pipe.WithPump(wavPump), pipe.WithSinks(paSink), ) defer p.Close() // run pipe err = p.Do(pipe.Run) check(err) } Сначала мы создаём элементы будущего конвейера: wav.Pump и portaudio.Sink и передаём их в конструктор pipe.New. Функция p.Do(pipe.actionFn) error запускает конвейер и ждёт окончания работы.
Сложнее
Задача: разбить wav файл на семплы, составить из них трек, результат сохранить и одновременно воспроизвести.
Трек — это последовательность семплов, а семпл — небольшой отрезок аудио. Чтобы аудио можно было резать, нужно сначала загрузить его в память. Для этого используем тип asset.Asset из пакета phono/asset. Разбиваем задачу на стандартные шаги:
- Получаем аудио из wav файла
- Передаём аудио в память
Теперь руками делаем семплы, добавляем их в трек и добиваем задачу:
- Получаем аудио из трека
- Передаём аудио в
- wav файл
- portaudio устройство
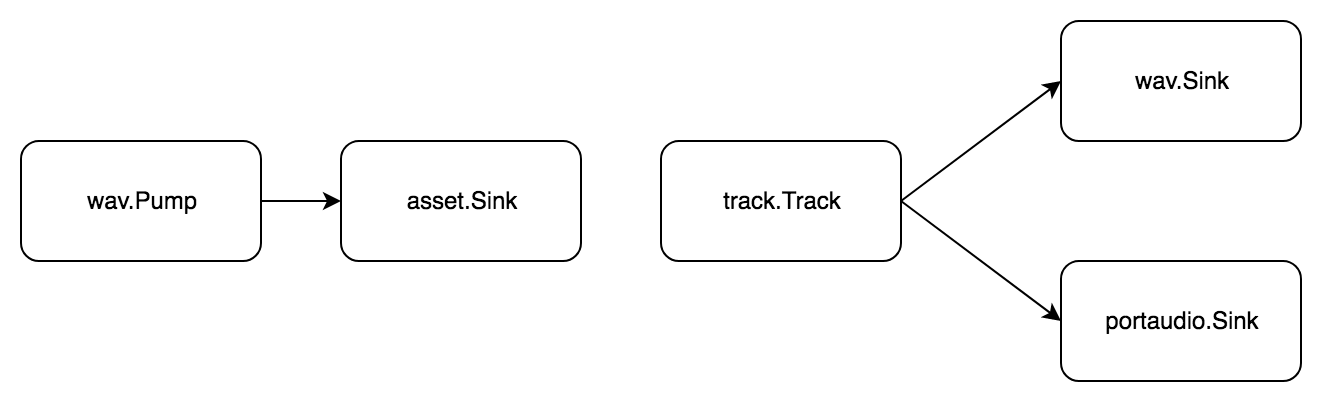
Снова, без стадии обработки, зато целых два pipeline!
Код
package example import ( "github.com/dudk/phono" "github.com/dudk/phono/asset" "github.com/dudk/phono/pipe" "github.com/dudk/phono/portaudio" "github.com/dudk/phono/track" "github.com/dudk/phono/wav" ) // Example: // Read .wav file // Split it to samples // Put samples to track // Save track into .wav and play it with portaudio func normal() { bufferSize := phono.BufferSize(512) inPath := "_testdata/sample1.wav" outPath := "_testdata/example4_out.wav" // wav pump wavPump, err := wav.NewPump(inPath, bufferSize) check(err) // asset sink asset := &asset.Asset{ SampleRate: wavPump.WavSampleRate(), } // import pipe importAsset := pipe.New( pipe.WithPump(wavPump), pipe.WithSinks(asset), ) defer importAsset.Close() err = importAsset.Do(pipe.Run) check(err) // track pump track := track.New(bufferSize, asset.NumChannels()) // add samples to track track.AddFrame(198450, asset.Frame(0, 44100)) track.AddFrame(66150, asset.Frame(44100, 44100)) track.AddFrame(132300, asset.Frame(0, 44100)) // wav sink wavSink, err := wav.NewSink( outPath, wavPump.WavSampleRate(), wavPump.WavNumChannels(), wavPump.WavBitDepth(), wavPump.WavAudioFormat(), ) // portaudio sink paSink := portaudio.NewSink( bufferSize, wavPump.WavSampleRate(), wavPump.WavNumChannels(), ) // final pipe p := pipe.New( pipe.WithPump(track), pipe.WithSinks(wavSink, paSink), ) err = p.Do(pipe.Run) } По сравнению с прошлым примером, есть два pipe.Pipe. Первый передаёт данные в память, чтобы можно было нарезать семплы. Второй имеет сразу два получателя в конце: wav.Sink и portaudio.Sink. При такой схеме звук одновременно записывается в wav файл и воспроизводится.
Еще сложнее
Задача: прочитать два wav файла, смешать, обработать vst2 плагином и сохранить в новый wav файл.
В пакете phono/mixer есть простой миксер mixer.Mixer. В него можно передать сигналы из нескольких источников и получить один смиксованный. Для этого он одновременно реализует pipe.Pump и pipe.Sink.
Опять задача состоит из двух подзадач. Первая выглядит так:
- Получаем аудио wav файла
- Передаём аудио в миксер
Вторая:
- Получаем аудио из миксера
- Обрабатываем аудио плагином
- Передаём аудио в wav файл
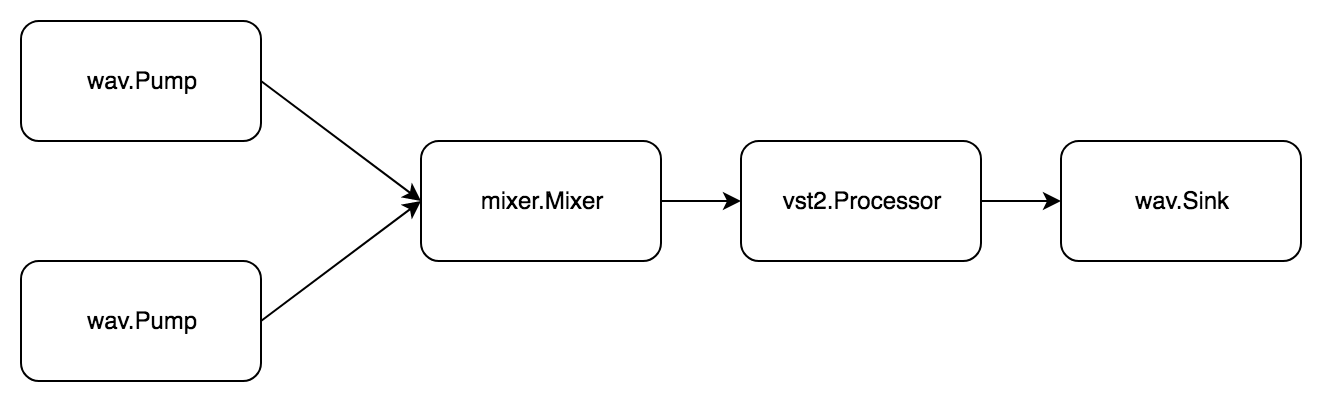
Код
package example import ( "github.com/dudk/phono" "github.com/dudk/phono/mixer" "github.com/dudk/phono/pipe" "github.com/dudk/phono/vst2" "github.com/dudk/phono/wav" vst2sdk "github.com/dudk/vst2" ) // Example: // Read two .wav files // Mix them // Process with vst2 // Save result into new .wav file // // NOTE: For example both wav files have same characteristics i.e: sample rate, bit depth and number of channels. // In real life implicit conversion will be needed. func hard() { bs := phono.BufferSize(512) inPath1 := "../_testdata/sample1.wav" inPath2 := "../_testdata/sample2.wav" outPath := "../_testdata/out/example5.wav" // wav pump 1 wavPump1, err := wav.NewPump(inPath1, bs) check(err) // wav pump 2 wavPump2, err := wav.NewPump(inPath2, bs) check(err) // mixer mixer := mixer.New(bs, wavPump1.WavNumChannels()) // track 1 track1 := pipe.New( pipe.WithPump(wavPump1), pipe.WithSinks(mixer), ) defer track1.Close() // track 2 track2 := pipe.New( pipe.WithPump(wavPump2), pipe.WithSinks(mixer), ) defer track2.Close() // vst2 processor vst2path := "../_testdata/Krush.vst" vst2lib, err := vst2sdk.Open(vst2path) check(err) defer vst2lib.Close() vst2plugin, err := vst2lib.Open() check(err) defer vst2plugin.Close() vst2processor := vst2.NewProcessor( vst2plugin, bs, wavPump1.WavSampleRate(), wavPump1.WavNumChannels(), ) // wav sink wavSink, err := wav.NewSink( outPath, wavPump1.WavSampleRate(), wavPump1.WavNumChannels(), wavPump1.WavBitDepth(), wavPump1.WavAudioFormat(), ) check(err) // out pipe out := pipe.New( pipe.WithPump(mixer), pipe.WithProcessors(vst2processor), pipe.WithSinks(wavSink), ) defer out.Close() // run all track1Done, err := track1.Begin(pipe.Run) check(err) track2Done, err := track2.Begin(pipe.Run) check(err) outDone, err := out.Begin(pipe.Run) check(err) // wait results err = track1.Wait(track1Done) check(err) err = track2.Wait(track2Done) check(err) err = out.Wait(outDone) check(err) } Здесь уже три pipe.Pipe, все связанные между собой через миксер. Для запуска используется функция p.Begin(pipe.actionFn) (pipe.State, error). В отличии от p.Do(pipe.actionFn) error, она не блокирует вызов, а просто возвращает состояние, которое потом можно дождаться с помощью p.Wait(pipe.State) error.
Что дальше?
Я хочу, чтобы phono стал максимально удобным прикладным фреймворком. Если есть задача со звуком, не нужно разбираться в сложных API и тратить время на изучение стандартов. Всё, что надо — построить конвейер из подходящих элементов и запустить его.
За пол года запилены следующие пакеты:
phono/wav— читать/писать wav файлыphono/vst2— неполные биндинги VST2 SDK, пока можно только открывать плагин и вызывать его методы, но нет всех структурphono/mixer— миксер, складывает N сигналов, без баланса и громкостиphono/asset— семплирование буферовphono/track— последовательное считывание семплов (разрулены наслоения)phono/portaudio— воспроизведение сигнала, пока эксперименты
Кроме этого списка, есть постоянно толстеющий бэклог из новых идей и задумок, среди которых:
- Отсчёт времени
- Изменяемый на лету pipeline
- HTTP pump/sink
- Автоматизация параметров
- Ресемплинг-процессор
- Баланс и громкость в миксере
- Real-time pump
- Синхронизированный pump для нескольких треков
- Полноценный vst2
В следующих статьях я разберу:
- жизненный цикл
pipe.Pipe— из-за сложной структуры его состояние управляется конечным атоматом - как писать свои стадии конвейера
Это мой первый open-source проект, так что я буду благодарен любой помощи и рекомендациям. Добро пожаловать.
Ссылки
Телеграм: t.me/ainewsline
Источник: habr.com