AI, практический курс. Настройка модели и гиперпараметров для распознавания эмоций на изображениях
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-09-15 08:52
распознавание образов, искусственный интеллект, реализация нейронной сети

В предыдущих статьях данной обучающей серии были описаны возможные варианты подготовки данных Предобработка и дополнение данных с изображениями, также в этих статьях была построена Базовая модель распознавания эмоций на основе изображений сверточной нейросети.
В данной статье мы построим улучшенную модель сверточной нейросети для распознавания эмоций на изображениях с помощью техники, называемой индуктивным обучением.
Сначала вам необходимо ознакомиться со статьей о Базовой модели распознавания эмоций на изображениях, также вы можете обращаться к ней во время чтения, поскольку некоторые разделы, включая изучение исходных данных и описание показателей сети, не будут приведены здесь в подробном виде.
Данные
Набор данных содержит 1630 изображений с эмоциями двух классов: Негативные (класс 0) и Позитивные (класс 1). Несколько примеров таких изображений приведены ниже.
Отрицательные



Положительные



Некоторые из примеров содержат очевидную позитивную или негативную эмоцию, в то время как другие могут не поддаваться классификации — даже с участием человека. На основании визуальной проверки таких случаев мы оцениваем, что максимальная возможная точность при этом должна составлять около 80 процентов. Обратите внимание на то, что случайный классификатор обеспечивает точность примерно в 53 процента вследствие небольшой несбалансированности классов.
Для обучения модели мы используем технику удерживания части образцов и разобьем исходный набор данных на две части, одна из которых (20 процентов от исходного набора) будет использоваться нами для проверки. Разбиение выполняется с применением стратификации: это означает, что баланс между классами сохраняется в обучающем и проверочном наборах.
Решение проблемы недостаточности данных
Базовая модель продемонстрировала результаты, лишь немногим лучшие случайного предсказания класса изображений. У такого поведения может быть множество возможных причин. Мы полагаем, что основная причина заключается в том, что имеющегося объема данных решительно недостаточно для такого обучения сверточной части сети, которое позволило бы получать характерные признаки на основе входного изображения.
Существует множество различных способов решения проблемы недостаточности данных. Вот несколько из них:
- Повторная выборка. Идея метода заключается в оценке распределения данных и выборке новых примеров из этого распределения.
- Обучение без учителя. Каждый может найти большие объемы данных такого же характера, как помеченные примеры в заданном наборе данных. Например, это могут быть фильмы для распознавания видео или аудиокниги для распознавания речи. Следующим этапом на этом пути является использование этих данных для предварительного обучения модели (например, с помощью автокодировщиков).
- Аугментация данных. В ходе этого процесса примеры данных модифицируются случайным образом с помощью заданного набора преобразований.
- Индуктивное обучение. Данная тема представляет для нас большой интерес, поэтому давайте ознакомимся с ней более подробно.
Индуктивное обучение
Термин индуктивное обучение обозначает набор техник, использующих модели (зачастую очень крупные), обученные на различных наборах данных примерно одинакового характера.


Сравнение методов традиционного машинного обучения и индуктивного обучения. Изображение взято из записи блога С. Рудера «Что такое индуктивное обучение?».
Существует три основных сценария использования индуктивного обучения:
- Предварительно обученные модели. Любой пользователь может просто взять модель, обученную кем-то еще, и использовать ее для своих задач. Такой сценарий возможен в том случае, если задачи являются очень похожими.
- Блок выделения признаков. К этому моменту мы знаем, что архитектуру модели можно разделить на две основные части: Блок выделения признаков, который отвечает за выделение признаков из входных данных, и модуль классификации, выполняющий классификацию примеров на основе полученных признаков. Обычно блок выделения признаков составляет основную часть модели. Идея метода заключается в том, чтобы взять блок выделения признаков у модели, обученной на другой задаче, зафиксировать его весовые коэффициенты (сделать их необучаемыми), после чего построить на его основе новые модули классификации для рассматриваемой задачи. Модуль классификации обычно не является очень глубоким и состоит из нескольких полносвязных слоев, поэтому такую модель гораздо легче обучить.
- Точная и глубокая настройка. Данный метод походит на сценарий с использованием блока выделения признаков. Выполняются те же самые действия за исключением «замораживания» блока выделения признаков. Например, можно взять сеть VGG в качестве блока выделения признаков и «заморозить» в нем только первые три (из четырех) сверточных блока. В этом случае блок выделения признаков может лучше приспособиться к текущей задаче. Для получения дополнительной информации см. запись в блоге Ф. Чоллета (F. Chollet) Построение мощных моделей классификации изображений с использованием очень малого объема данных.
Подробное описание сценариев использования индуктивного обучения можно найти в курсе Стэнфордского университета Сверточные нейронные сети CS231n для визуального распознавания за авторством Фей-Фей Ли (Fei-Fei Li) и записи в блоге С. Рудера (S. Ruder) Индуктивное обучение — следующий рубеж в развитии машинного обучения (тематика рассмотрена более комплексно).
У вас могут возникнуть вопросы: зачем нужны все эти методы и почему они могут работать? Попытаемся ответить на них.
- Преимущества от использования больших наборов данных. Например, мы можем взять блок выделения признаков у модели, обученной на 14 миллионах изображений, содержащихся в наборе данных конкурса ImageNet. Эти модели являются достаточно сложными, чтобы обеспечить выделение очень качественных признаков из входных данных.
- Соображения, связанные со временем. Обучение больших моделей может занимать недели и даже месяцы. В этом случае каждый может сэкономить огромное количество времени и вычислительных ресурсов.
- Веское предположение, лежащее в основе того, почему все это может работать, заключается в следующем: Признаки, полученные в результате обучения по одной задаче, могут быть полезными и подходящими для другой задачи. Иными словами, признаки обладают свойством инвариантности относительно задачи. Обратите внимание, что домен новой задачи должен быть сходен с доменом исходной задачи. В противном случае блок выделения признаков может даже ухудшить полученные результаты.
Архитектура улучшенной модели
Теперь мы знакомы с концепцией индуктивного обучения. Также мы знаем о том, что ImageNet является крупным мероприятием, в рамках которого были протестированы почти все современные передовые архитектуры сверточных нейросетей. Попробуем взять блок выделения признаков из одной из этих сетей.
К счастью, библиотека Keras предоставляет нам несколько предварительно обученных (в рамках ImageNet) моделей, которые были созданы внутри этой платформы. Импортируем и используем одну из этих моделей.
В данном случае мы будем использовать сеть с архитектурой VGG. Чтобы выделить только блок выделения признаков, удалим модуль классификации (три верхних полносвязных слоя) сети, установив для параметра include_top значение False. Также мы хотим инициализировать нашу сеть с помощью весовых коэффициентов сети, обученной в рамках ImageNet. Последним параметром является размер входных данных.
Обратите внимание, что размер исходных изображений в конкурсе ImageNet составляет (224, 224, 3), в то время как наши изображения имеют размер (400, 500, 3). Однако мы используем сверточные слои — это означает, что весовые коэффициенты сети являются весами скользящих ядер в операции свертки. Вкупе со свойством разделения параметров (обсуждение этого находится в нашей теоретической статье Обзор сверточных нейронных сетей для классификации изображений) — это приводит к тому факту, что размер входных данных может быть практически произвольным, поскольку свертка выполняется посредством скользящего окна, и данное окно может скользить по изображению произвольного размера. Единственное ограничение заключается в том, что размер входных данных должен быть достаточно большим, чтобы не произошло его свертывание в одну точку (пространственные измерения) в каком-нибудь промежуточном слое, поскольку в противном случае будет невозможно производить дальнейшие вычисления.
Еще одним приемом, который мы используем, является кэширование. VGG является очень крупной сетью. Один прямой проход для всех изображений (1630 примеров) через блок извлечения признаков занимает примерно 50 секунд. Однако следует помнить о том, что весовые коэффициенты блока извлечения признаков зафиксированы, и прямой проход всегда дает один и тот же результат для одинакового изображения. Мы можем использовать этот факт для того, чтобы выполнять прямой проход через блок извлечения признаков только один раз и затем кэшировать полученные результаты в промежуточном массиве. Для реализации данного сценария сначала создадим экземпляр класса ImageDataGenerator для загрузки файлов с жесткого диска напрямую (дополнительную информацию см. в базовой статье Базовая модель распознавания эмоций на изображениях).
На следующем этапе используем в режиме предсказания ранее созданный блок выделения признаков в составе модели для получения признаков изображений.
Это занимает около 50 секунд. Теперь мы можем использовать полученные результаты для очень быстрого обучения верхней классификационной части модели — одна эпоха длится у нас примерно 1 секунду. Представьте теперь, что каждая эпоха длится на 50 секунд больше. Таким образом, этот простой кэширующий прием позволил ускорить процесс обучения сети в 50 раз! В данном сценарии мы сохраняем все признаки для всех примеров в оперативной памяти, так как ее объема достаточно для этого. При использовании более крупного набора данных можно выполнить вычисление свойств, записать их на жесткий диск, после чего считать их с использованием такого же подхода, связанного с классом генератора.
Наконец, рассмотрим архитектуру классификационной части модели:
Вспомните о том, что на выходе блока извлечения признаков сверточной нейросети выдается четырехмерный тензор (примеры, высота, ширина и каналы), а полносвязный слой для классификации принимает двухмерный тензор (примеры, признаки). Одним из способов преобразования четырехмерного тензора с признаками является просто его выравнивание вокруг трех последних осей (подобная техника использовалась нами в базовой модели). В данном сценарии мы используем другой подход, называемый глобальной субдискретизацией на основе среднего значения (GAP). Вместо выравнивания четырехмерных векторов мы будем брать среднее значение на основе двух пространственных измерений. В действительности мы берем карту признаков и просто усредняем все значения в ней. Метод GAP был впервые представлен в превосходной работе Мин Лина (Min Lin) Сеть в сети (эта книга действительно стоит ознакомления с ней, поскольку в ней рассмотрены некоторые важные понятия — например свертки размером 1 ? 1). Одним из очевидных преимуществ подхода GAP является значительное сокращение числа параметров. При использовании GAP мы получаем лишь 512 признаков для каждого примера, в то время как выравнивании сырых данных число признаков составит 15 ? 12 ? 512 = 92 160. Это может привести к серьезным накладным расходам, поскольку в этом случае классификационная часть модели будет иметь около 50 миллионов параметров! Другие элементы классификационной части модели, такие как полносвязные слои и слои, реализующие метод исключения, подробно рассмотрены в статье Базовая модель распознавания эмоций на изображениях.
Настройки и параметры обучения
После того, как мы подготовили архитектуру нашей модели с помощью Keras, необходимо настроить всю модель для обучения с использованием метода компиляции.
При этом мы используем настройки, практически аналогичные настройкам базовой модели за исключением выбора оптимизатора. Для оптимизации обучения в качестве функции потери будет использоваться двоичная перекрестная энтропия, дополнительно будет отслеживаться метрика точности. В качестве оптимизатора используем метод Adam. Adam представляет собой вид алгоритма стохастического градиентного спуска с моментом и адаптивной скоростью обучения (для получения дополнительной информации см. запись в блоге С. Рудера Обзор алгоритмов оптимизации градиентного спуска).
Скорость обучения является гиперпараметром оптимизатора, который необходимо настроить для обеспечения работоспособности модели. Вспомните, как выглядит формула для «ванильного» градиентного спуска, не содержащего дополнительного функционала:
представляет собой вектор параметров модели (в нашем случае это весовые коэффициенты нейронной сети), ? — целевая функция, ? — оператор градиента (вычисляемый с помощью алгоритма обратного распространения ошибки), ? — скорость обучения. Таким образом градиент целевой функции представляет собой направление шага оптимизации в пространстве параметров, а скорость обучения — его размер. При использовании необоснованно высокой скорости обучения существует вероятность постоянного проскакивания оптимальной точки из-за слишком большого размера шага. С другой стороны, если скорость обучения слишком мала, то оптимизация займет слишком много времени и может обеспечить сходимость только в некачественные локальные минимумы вместо глобального экстремума. Поэтому в каждой конкретной ситуации необходимо искать соответствующий компромисс. Использование настроек по умолчанию для алгоритма Adam — хорошая отправная точка для начала работы.Однако в этой задаче настройки Adam по умолчанию демонстрируют плохие результаты. Нам необходимо снизить исходную скорость обучения до значения 0,0001. В противном случае, обучение не сможет обеспечить сходимость.
В конечном счете мы можем начать обучение в течение 100 эпох и сохранить после этого саму модель и историю обучения. Команда %time — это магическая команда Ipython*, позволяющая измерить время выполнения кода.
Оценка
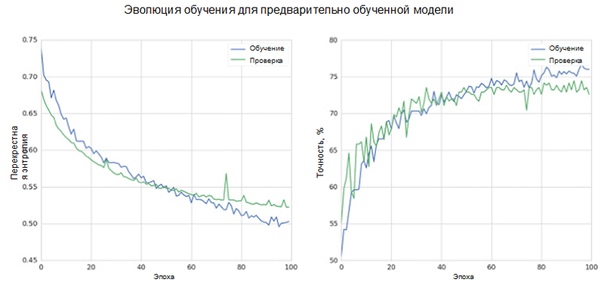
Давайте оценим эффективность модели во время обучения. В нашем случае точность проверки составляет 73 процента (по сравнению с 55 процентами при использовании базовой модели). Этот результат гораздо лучше результата базовой модели.
Давайте также рассмотрим распределение ошибок с помощью матрицы неточностей. Ошибки распределены практически равномерно между классами с небольшим смещением в сторону неправильно классифицированных негативных примеров (верхняя левая ячейка матрицы неточностей). Это можно объяснить небольшим дисбалансом в наборе данных в сторону позитивного класса.
Еще одной отслеживаемой нами метрикой является кривая рабочей характеристики приемника (ROC-кривая) и площадь под этой кривой (AUC). Подробное описание этих метрик см. в статье Базовая модель распознавания эмоций на изображениях.

Чем ближе ROC-кривая к левой верхней точке графика и больше площадь под ней (метрика AUC), тем лучше работает классификатор. На данном рисунке четко видно, что улучшенная и предварительно обученная модель демонстрирует лучшие результаты по сравнению с базовой моделью, созданной с нуля. Значение AUC для предварительно обученной модели равно 0,82, что является хорошим результатом.

Заключение
В данной статье мы познакомились с мощной техникой — индуктивным обучением. Мы также построили классификатор сверточной нейронной сети с помощью предварительно обученного блока выделения признаков на базе архитектуры VGG. Данный классификатор превзошел по своим рабочим характеристикам базовую сверточную модель, обученную с нуля. Прирост в точности составил 18 процентов, а прирост в метрике AUC — 0,25, что демонстрирует весьма значительное повышение качества системы.
Телеграм: t.me/ainewsline
Источник: m.vk.com