Serverless tensorflow на AWS Lambda
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-08-30 17:10

Машинное обучение и нейросети становятся все более незаменимыми для многих компаний. Одна из основных проблем, с которыми они сталкиваются — деплой такого рода приложений. Я хочу показать показать практичный и удобный способ подобного деплоя, для которого не требуется быть специалистом в облачных технологиях и кластерах. Для этого мы будем использовать serverless инфраструктуру.
Ввведение
В последнее время множество задач в продукте решается с применением моделей, созданных машинным обучением или нейросетями. Часто это задачи, которые много лет решались обычными детерменистскими методами теперь легче и дешевле решать через ML.
Имея современные фреймворки типа Keras или Tensorflow и каталоги готовых решений становится проще создавать модели, которые дают необходимую для продукта точность.
Мои коллеги называют это “коммодитизацией машинного обучения” и в чем-то они правы. Самое главное — что сегодня легко найти/скачать/натренировать модель и хочется иметь возможность также легко ее деплоить.
Опять же при работе в стартапе или маленькой компании часто нужно быстро проверять предположения, причем не только технические, но и рыночные. И для этого нужно быстро и несложно деплоить модель, ожидая не сильный, но все же трафик.
Для решения такой задачи деплоя мне понравилось работать с облачными микросервисами.
Amazon, Google и Microsoft недавно предоставили FaaS — function as a service. Они относительно дешевые, их легко деплоить (не требуется Docker) и можно параллельно запускать практически неограниченное количество сущностей.
Сейчас я расскажу, как можно задеплоить модели TensorFlow/Keras на AWS Lambda — FaaS от Amazon. Как итог — API для распознавания содержания на изображениях стоимостью 1$ за 20000 распознаваний. Можно дешевле? Возможно. Можно проще? Вряд ли.
Function-as-a-service
Рассмотрим диаграмму различных видов деплоя приложений:
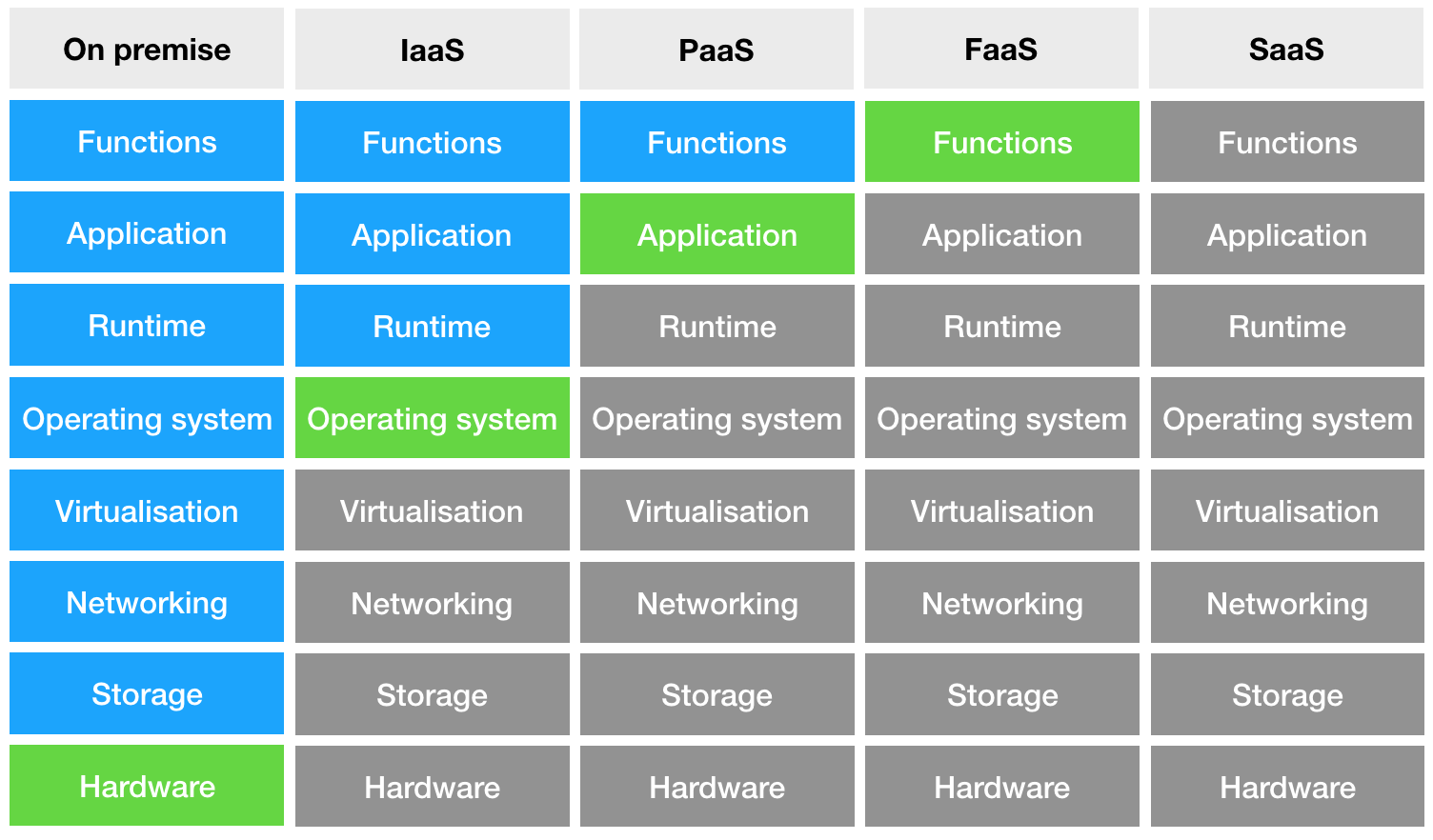
Слева мы видим on premise — когда мы владеем сервером. Далее мы видим Infrastructure-as-a-Service — здесь мы уже работаем с виртуальной машиной — сервером, расположенным в датацентре. Следующий шаг — Platform-as-a-Service, когда у нас уже нет доступа к самой машине, но мы управляем контейнером в котором будет исполняться приложение. И наконец-то Function-as-a-Service, когда мы контролируем только код, а все остальное спрятано от нас. Это хорошие новости, так как мы увидим позже, что дает нам очень крутую функциональность.
AWS Lambda — это имплементация FAAS на платформе AWS. Кратко про имплементацию. Контейнером для него является zip архив [код + библиотеки]. Код такой же как на локальной машине. AWS разворачивает этот код на контейнерах в зависимости от количества внешних запросов (триггеров). Границы сверху по сути нет — текущее ограничения — 1000 одновременно работающих контейнеров, но его легко можно поднять до 10000 и выше через саппорт.
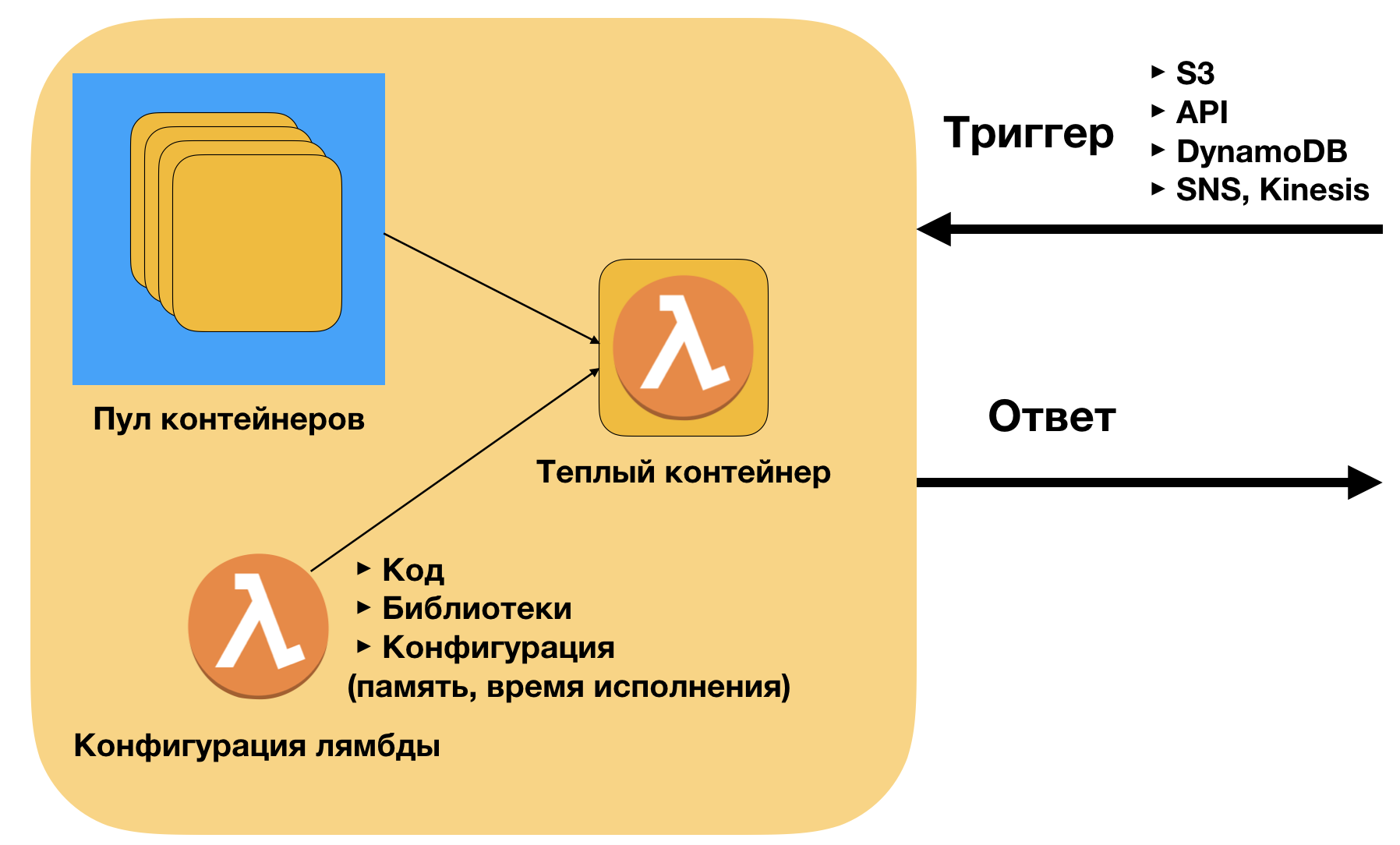
Главные плюсы AWS Lambda:
- Легко деплоить (без docker) — только код и библиотеки
- Легко подключать к триггерам (API, S3, SNS, DynamoDB)
- Хорошее масштабирование — в продакшене мы запускали более 40 тысяч инвокаций одновременно. Можно и больше.
- Низкая цена вызова. Для моих коллег из BD направления также важно, что микросервисы поддерживают pay-as-you-go модель для использования сервиса. Это делает понятной юнит-экономику использования модели при масштабировании.
Зачем портировать нейросети на serverless
Прежде всего хочу уточнить, что для своих примеров я использую Tensorflow — открытый фреймфорк, который позволяет разработчикам создавать, тренировать и деплоить модели машинного обучения. На данный момент это самая популярная библиотека для глубокого обучения и ее используют как эксперты, так и новички.
На данным момент основным способом деплоя моделей машинного обучения является кластер. Если мы хотим сделать REST API для глубокого обучения, он будет выглядеть следующий образом:
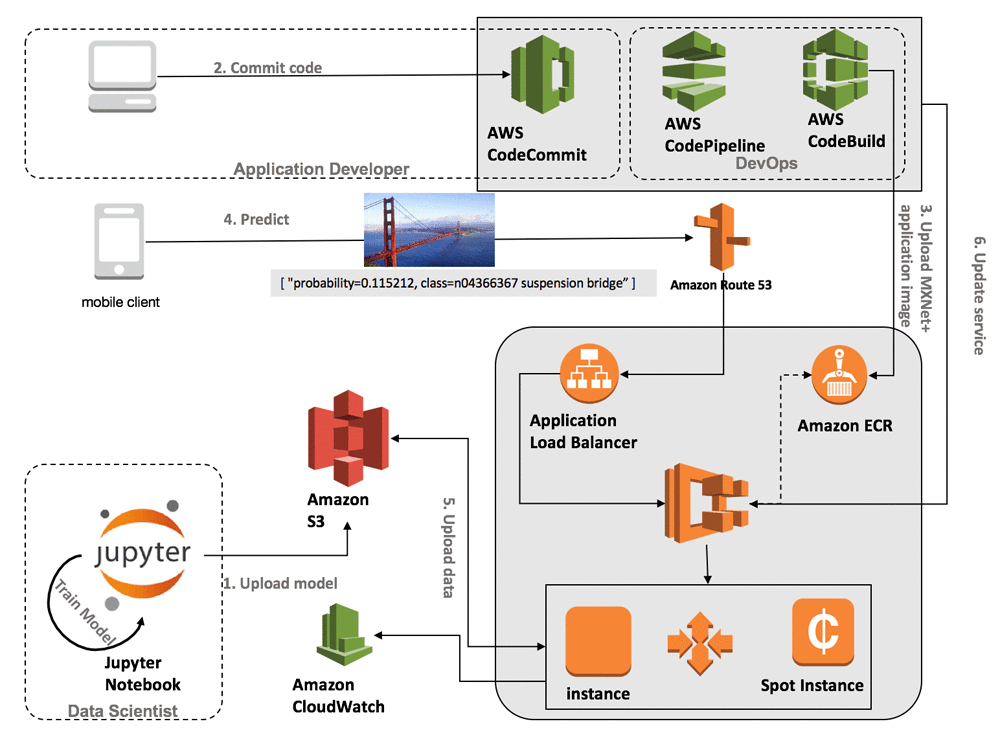
(Изображение из блога AWS)
Кажется громоздким? В то же время вам придется позаботиться о следующих вещах:
- прописать логику распределения трафика на машины кластера
- прописать логику масштабирования, постараясь найти золотую середину между простоем и торможением
- прописать логику поведения контейнера — логирование, управление входящими запросами
На AWS Lambda архитектура будет выглядеть заметно проще:
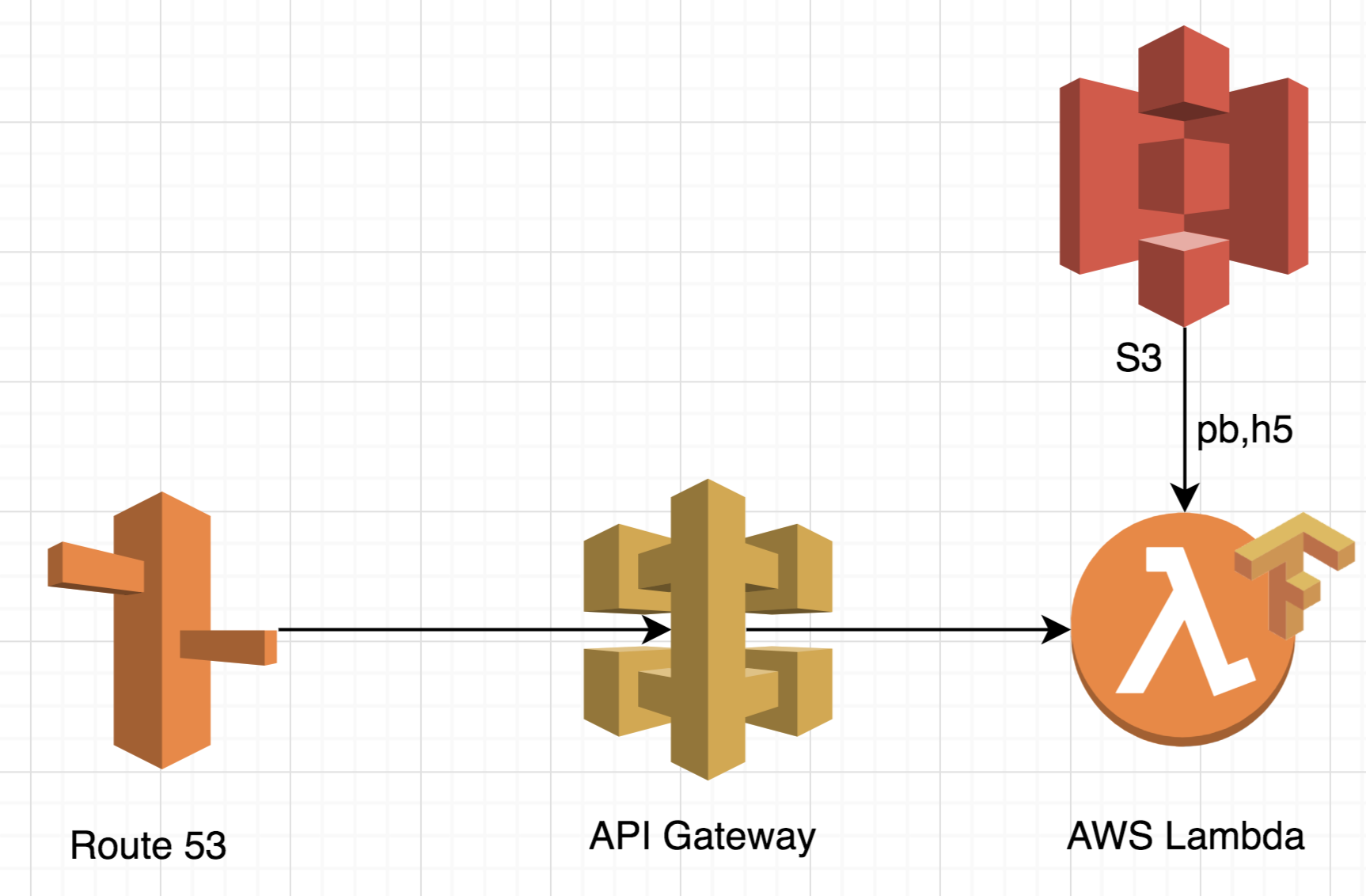
Во-первых такой подход очень масштабируемый. Он может обработать до 10 тысяч одновременных запросов без прописывания какой-либо дополнительной логики. Такая особенность делает архитектуру идеальной для обработки пиковой нагрузки, так как ей не требуется дополнительное время на обработку.
Во-вторых вам не придется платить за простой сервера. В Serverless архитектуре оплата идет за один реквест. Это означает, что если у вас будет 25 тысяч реквестов, вы заплатите только за 25 тысяч реквестов, в независимости каким потоком они пришли. Таким образом не только стоимость становится более прозрачной, но и стоимость сама по себе очень низкая. Для примера на Tensorflow, который я покажу позднее стоимость составляет 20-25 тысяч запросов за 1 доллар. Кластер с аналогичным функционалом стоит гораздо больше, а выгоднее он становиться только на очень большом количестве реквестом (>1 миллиона).
В-третьих инфраструктура становится гораздо больше. Не нужно работать с докером, прописывать логику масштабирования и распредления нагрузки. Если коротко — в компанию не придется нанимать дополнительного человека на поддержку инфраструктуры, а если вы датасаентист, то вы сможете сделать все своими руками.
Как вы увидите ниже, деплой всей инфраструктуры для вышеупомянутого приложения требуется не более 4 строк кода.
Было бы некорректно не сказать о недостатках serverless инфраструктуры и о тех случаях, когда она работать не будет. У AWS Lambda есть жесткие ограничения на время обработки и на доступную память, которые надо иметь в виду.
Во-первых, как я и упоминал ранее кластеры становятся более выгодными после определенного числа реквестов. В случаях когда у вас нет пиковой нагрузки и много реквестов, кластер будет более выгоден.
Во-вторых, у AWS Lambda есть небольшое, но определенное время старта (100-200мс). Для приложений глубокого обучения требуется еще некоторое время на скачивание модели с S3. Для примера, который я буду показывать ниже, холодный запуск будет составлять 4.5 секунды, а теплый — 3 секунды. Для некоторых приложений это может быть не критично, но если ваше приложение сфокусировано на максимально быстрой обработке одиночного реквеста, кластер будет более хорошим вариантом.
Приложение
Теперь перейдем к практической части.
Для этого примера я использую достаточно популярное применение нейронных сетей — распознавание изображений. Наше приложение берет картинку на вход и возвращает описание объекта на ней. Такого рода приложения широко используются для фильтрации изображений и классификации множества изображений на группы. Наше приложение будет пытаться распознать фотографию панды.
 Памятка: Модель и оригинальный код доступны здесь
Памятка: Модель и оригинальный код доступны здесь
Мы будем использовать следующий стек:
- API Gateway для управления запросами
- AWS Lambda для процессинга
- Serverless фреймворк для деплоя
“Hello world” код
Для начала вам нужно установиться и настроить Serverless фреймворк, который мы будет использовать для оркестрации и деплоя приложения. Ссылка на гайд.
Сделайте пустую папку и запустить следующую команду:
serverless install -u https://github.com/ryfeus/lambda-packs/tree/master/tensorflow/source -n tensorflow cd tensorflow serverless deploy serverless invoke --function main --logВы получите следующих ответ:
/tmp/imagenet/imagenet_synset_to_human_label_map.txt /tmp/imagenet/imagenet_2012_challenge_label_map_proto.pbtxt /tmp/imagenet/classify_image_graph_def.pb /tmp/imagenet/inputimage.jpg giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89107) indri, indris, Indri indri, Indri brevicaudatus (score = 0.00779) lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens (score = 0.00296) custard apple (score = 0.00147) earthstar (score = 0.00117)Как вы видите, наше приложение успешно распознало картинку с пандой (0,89).
Вуаля. Мы успешно задеплоили нейронную сеть для распознавания изображений на Tensorflow на AWS Lambda.
Рассмотрим код поподробнее
Начнем с конфигурационного файла. Ничего нестандартного — мы используем базовую конфигурацию AWS Lambda.
service: tensorflow frameworkVersion: ">=1.2.0 <2.0.0" provider: name: aws runtime: python2.7 memorySize: 1536 timeout: 300 functions: main: handler: index.handlerЕсли мы посмотрим на сам файл 'index.py', то мы увидим, что сначала мы скачиваем модель ('.pb' файл) в папку '/tmp/' на AWS Lambda, а потом импортируем ее стандартным образом через Tensorflow.
Ниже ссылки на части кода в Github, которые вы должны иметь в виду если вы хотите вставить свою собственную модель:
strBucket = 'ryfeuslambda' strKey = 'tensorflow/imagenet/classify_image_graph_def.pb' strFile = '/tmp/imagenet/classify_image_graph_def.pb' downloadFromS3(strBucket,strKey,strFile) print(strFile)def create_graph(): with tf.gfile.FastGFile(os.path.join('/tmp/imagenet/', 'classify_image_graph_def.pb'), 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def, name='') strFile = '/tmp/imagenet/inputimage.jpg' if ('imagelink' in event): urllib.urlretrieve(event['imagelink'], strFile) else: strBucket = 'ryfeuslambda' strKey = 'tensorflow/imagenet/cropped_panda.jpg' downloadFromS3(strBucket,strKey,strFile) print(strFile)Получение предсказаний из модели:
softmax_tensor = sess.graph.get_tensor_by_name('softmax:0') predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data}) predictions = np.squeeze(predictions)Теперь давайте добавим API к лямбде.
Пример с API
Самый простой способ добавить API это модифицировать конфигурационный YAML файл.
service: tensorflow frameworkVersion: ">=1.2.0 <2.0.0" provider: name: aws runtime: python2.7 memorySize: 1536 timeout: 300 functions: main: handler: index.handler events: - http: GET handlerТеперь давайте передеплоим стек:
serverless deployПолучаем следующее.
Service Information service: tensorflow stage: dev region: us-east-1 stack: tensorflow-dev api keys: None endpoints: GET - https://<urlkey>.execute-api.us-east-1.amazonaws.com/dev/handler functions: main: tensorflow-dev-mainЧтобы протестировать API можно просто открыть качестве ссылки:
https://<urlkey>.execute-api.us-east-1.amazonaws.com/dev/handlerИли использовать curl:
curl https://<urlkey>.execute-api.us-east-1.amazonaws.com/dev/handlerМы получим:
{"return": "giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89107)"}Заключение
Мы создали API для модели на Tensorflow на основе AWS Lambda с помощью Serverless фреймворка. Все удалось сделать достаточно просто и такой подход сэкономил нам много времени по сравнению с традиционным подходом.
Модифицируя конфигурационный файл, можно подключить множество других AWS сервисов, например SQS для потоковой обработки задач или сделать чатбота, использую AWS Lex.
В качестве моего хобби я портирую множество библиотек, чтобы сделать serverless более дружелюбным. Вы можете найти их здесь. У проекта MIT лицензия, поэтому можете спокойно модифицировать и использовать его для своих задач.
Библиотеки включают в себя следующие примеры:
- Машинное обучение (Scikit, LightGBM)
- Компьютерное зрение (Skimage, OpenCV, PIL)
- Распознавание текста (Tesseract)
- Анализ текста (Spacy)
- Веб скрейпинг (Selenium, PhantomJS, lxml)
- Тестирование API (WRK, pyrestest)
Я очень рад видеть, как другие используют serverless для своих проектов. Обязательно скажите обратную связь в комментариях и удачной вам разработки.
Телеграм: t.me/ainewsline
Источник: habr.com