Глубокое обучение для обнаружения объектов: полный обзор
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-08-11 17:20
техническое зрение, Основы нейронных сетей, Нейронные сети для начинающих

С подъемом автономных кораблей, франтовское видео-наблюдение, лицевое обнаружение и различные люди подсчитывая применения, быстрые и точные системы обнаружения предмета поднимают в требовании. Эти системы предполагают не только признание и классификации каждый объект на изображении, но локализация каждого рисунка подходящую рамку вокруг него. Это делает обнаружение объекта значительно более трудной задачей чем своя традиционная предшественница компьютерного зрения, классификация изображения.
К счастью, однако, наиболее успешными подходами к обнаружению объектов в настоящее время являются расширения моделей классификации изображений. Несколько месяцев назад компания Google выпустила новый объект обнаружения по API для Tensorflow. С этим выпуском пришел встроенных архитектур и весов для нескольких конкретных моделей:
- Одиночный выстрел Мультибоксе детектор (SSD) с MobileNets
- SSD с начала П2
- Области на основе полностью Сверточных сетей (Р-ДТМ) с Resnet 101
- Быстрее РЕН с Resnet 101
- Быстрее РЕН с начала Resnet П2
В моем прошлом блоге, я прикрыл интуиция за три базовых сетевых архитектур, перечисленных выше: MobileNets, создания и ResNet. На этот раз я хочу сделать то же самое для моделей обнаружения объектов Tensorflow: Faster R-CNN, R-FCN и SSD. К концу этого поста мы, надеюсь, получили понимание того, как глубокое обучение применяется для обнаружения объектов, и как эти модели обнаружения объектов как вдохновляют, так и расходятся друг от друга.
Быстрее R-CNN
Faster R-CNN теперь является канонической моделью для обнаружения объектов на основе глубокого обучения. Это помогло вдохновить многих моделей обнаружения и сегментации, которые пришли после него, в том числе двух других, которые мы собираемся исследовать сегодня. К сожалению, мы не можем начать понимать быстрее R-CNN, не понимая своих предшественников, R-CNN и Fast R-CNN, так что давайте быстро погрузимся в его происхождение.
R-CNN
R-CNN-дедушка Faster R-CNN. Другими словами, R-Эн-Эн , правда, сбрасывал вещи с ноги.
Р-Эн-Эн, или Рэгион основе сonvolutional Неурал Нetwork он состоял из 3 простых шагов
- Сканирования входного изображения для возможных объектов с помощью алгоритма, называемого выборочного поиска, генерации ~2000 области предложения
- Запустить сверточная нейронная сеть (CNN с) на каждой из этих области предложения
- Возьмите на выходе каждого канала CNN и кормить его в а) СВМ классифицировать регионе и б) линейной регрессор затянуть ограничивающий прямоугольник объекта, если такой объект существует.
Эти 3 шага проиллюстрированы на рисунке ниже
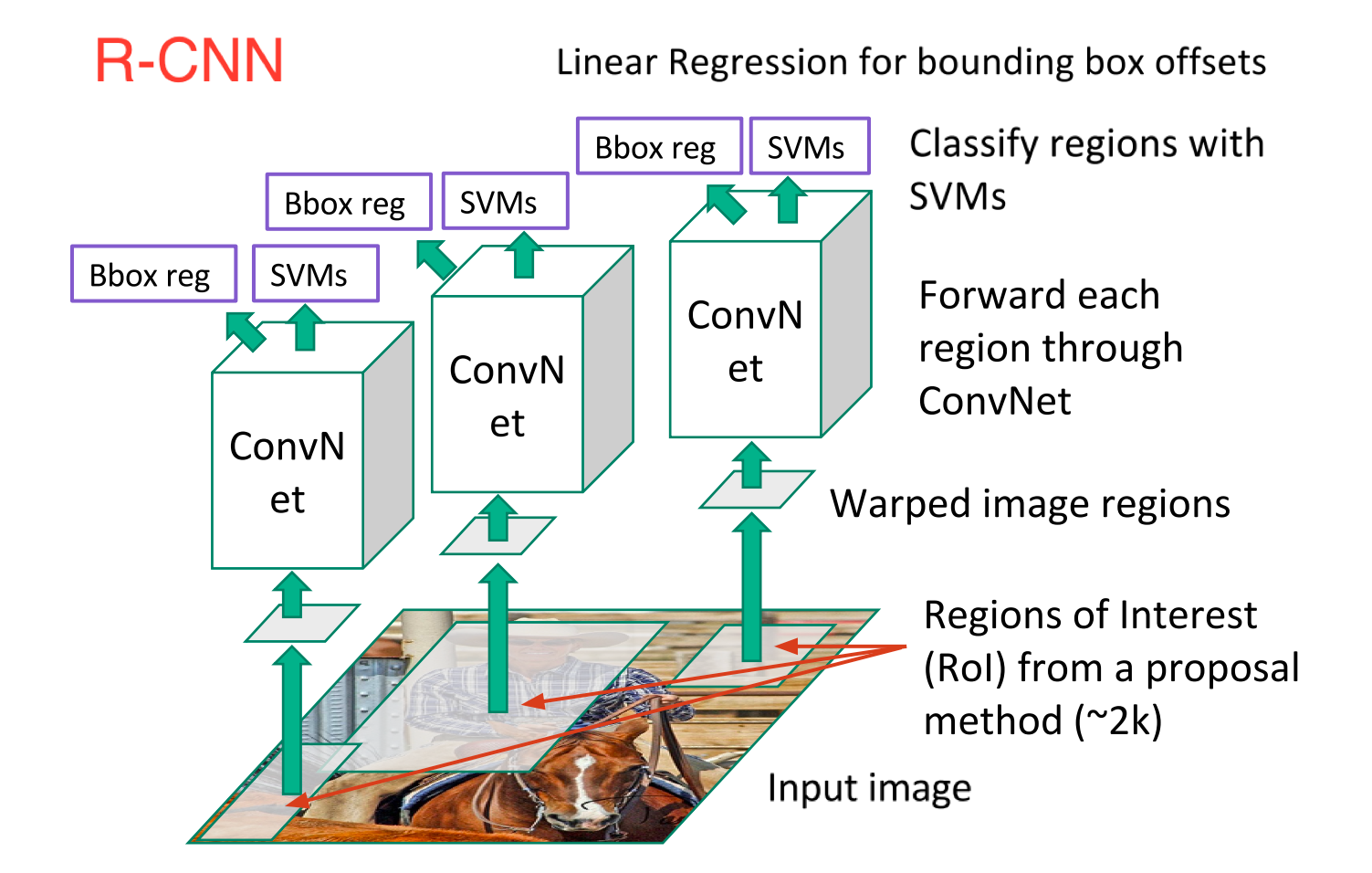
Другими словами, сначала мы предлагаем регионы, затем извлекаем объекты, а затем классифицируем эти регионы на основе их особенностей. В сущности, мы превратили обнаружение объектов в проблему классификации изображений. R-CNN был очень интуитивным, но очень медленным.
Fast R-CNN
Непосредственным потомком R-CNN был Fast-R-CNN. Fast R-CNN во многих отношениях напоминал оригинал, но улучшил скорость его обнаружения через два основных увеличения
- Выполняя функцию извлечения на изображение, прежде чем предлагать регионам, таким образом, только работает один телеканал CNN на всем изображении, а не 2000 на CNN за 2000 перекрывающихся областей
- Замена SVM на слой softmax, тем самым расширяя нейронную сеть для предсказаний вместо создания новой модели
Новая модель выглядела примерно так
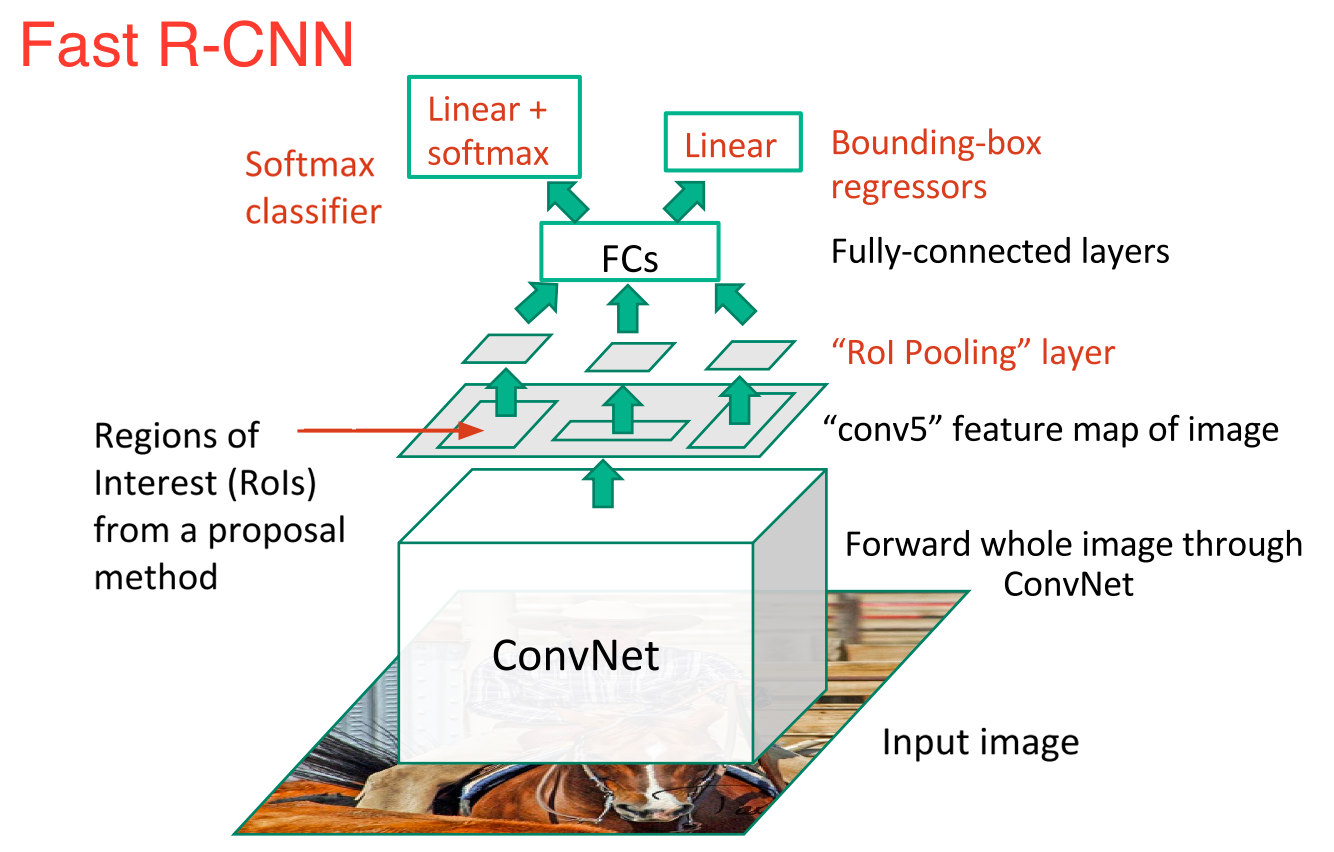
Как мы можем видеть из изображения, теперь мы генерируем региональные предложения на основе последней карты объектов сети, а не из самого исходного изображения. В результате, мы можем обучать только одна КНС для всего изображения.
Кроме того, вместо обучения многих различных SVM для классификации каждого класса объектов существует один слой softmax, который выводит вероятности классов напрямую. Теперь у нас есть только одна нейронная сеть для обучения, в отличие от одной нейронной сети и многих SVM.
Fast R-CNN показал себя намного лучше с точки зрения скорости. Осталось только одно большое узкое место: алгоритм выборочного поиска для генерации региональных предложений.
Быстрее R-CNN
На этом этапе мы возвращаемся к нашей первоначальной цели: Faster R-CNN. Основная идея Faster R-CNN заключалась в замене медленного селективного алгоритма поиска на быструю нейронную сеть. В частности, он представил регион предложение сети (РПН).
Вот как работал RPN
- На последнем слое исходного CNN скользящее окно 3x3 перемещается по карте объектов и сопоставляет его с более низким измерением (например, 256-d
- Для каждого скользящего окна расположение, он генерирует несколько возможных регионов на основе к фиксированной соотношение якорных ящиков (по умолчанию рамки
- Каждое предложение по региону состоит из a) балла” objectness " для этого региона и B) 4 координат, представляющих ограничивающий прямоугольник региона
Другими словами, мы смотрим на каждое место в нашей последней карте и рассмотреть к различным ящики вокруг нее: высокая коробка, большой коробка, большой коробка, etc. Для каждой из этих коробок мы выводим, независимо от того, содержит ли она объект или нет, и какие координаты для этой коробки. Это то, как он выглядит в одном месте раздвижного окна
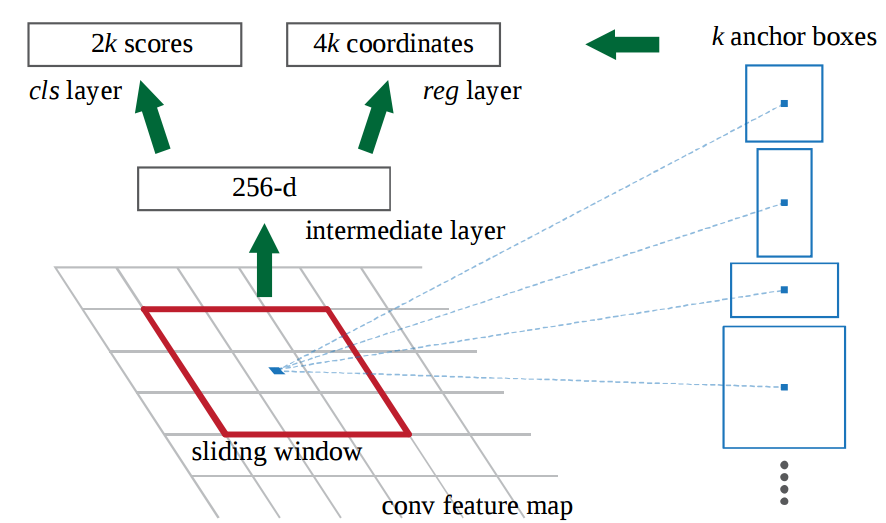
В 2к баллов соответствует softmax вероятность каждого из к ограничивающим рамкам на “объект."Заметьте, что, хотя RPN выводит координаты ограничивающего прямоугольника, он не пытается классифицировать любые потенциальные объекты: его единственная задача по-прежнему предлагает области объектов. Если поле привязки имеет оценку “objectness” выше определенного порога, координаты этого поля передаются вперед как предложение региона.
После того, как у нас есть предложения по нашему региону, мы кормим их прямо в то, что по существу является быстрым R-CNN. Мы добавляем слой объединения, некоторые полностью связанные слои, и, наконец, классификационный слой softmax и регрессор граничной рамки. В некотором смысле, быстрее R-Эн-Эн = РПН + быстрая Р-Эн-Эн.
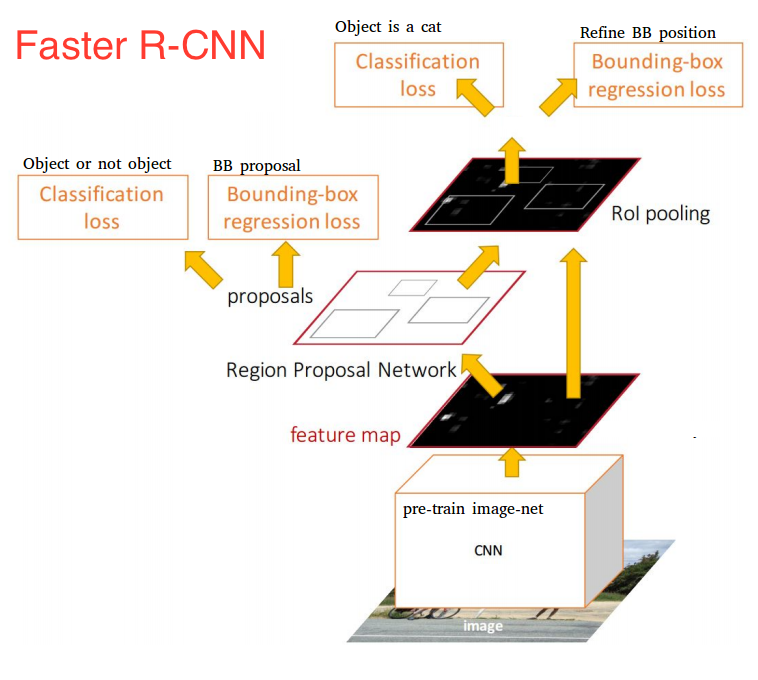
В целом, более быстрый R-CNN достиг гораздо лучших скоростей и современной точности. Стоит отметить, что, хотя будущие модели сделали много для увеличения скорости обнаружения, несколько моделей удалось опередить быстрее R-CNN со значительным отрывом. Другими словами, более быстрый R-CNN не может быть самым простым или самым быстрым методом обнаружения объекта, но он по-прежнему является одним из лучших. Дело в точку, Tensorflow быстрее Р-Эн-Эн с начала ResNet является их медленный, но наиболее точная модель.
В конце дня, быстрее R-Эн-Эн может выглядеть сложным, но его основной дизайн такой же, как и оригинал R-Эн-Эн: выдвигать гипотезу, объект регионах, а затем классифицировать их. В настоящее время это преобладающий конвейер для многих моделей обнаружения объектов, включая нашу следующую.
R-FCN
Помните, как быстро R-CNN улучшился на скорости обнаружения оригинала путем совместного использования одного вычисления CNN во всех предложениях региона? Такой тип мышления был также мотивация Р-ДТС: увеличение скорости путем увеличения общего расчета.
Р-ДТС, или Рэгион на основе Фулы сonvolutional НЭ, акций 100% расчетов через каждый выход. Будучи полностью сверточные, он столкнулся с уникальной проблемой в дизайн модели.
С одной стороны, при выполнении классификации объекта, мы хотим узнать местоположение инвариантности в модели: независимо от того, где кот предстает в образе, мы хотим, чтобы классифицировать его как кошка. С другой стороны, при обнаружении объекта, мы хотим узнать местоположение дисперсии: если кошка находится в левом верхнем углу, мы хотим нарисовать прямоугольник в верхнем левом углу. Поэтому, если мы пытаемся разделить сверточные вычисления по 100% сети, как мы можем скомпрометировать инвариантность местоположения и дисперсию местоположения?
Р-ДТС решение: позиционно-чувствительных счет карты.
Каждый позиционно-чувствительный результат карта представляет одно относительное положение из одного объекта класса. Например, один счет карты может активировать везде, где он обнаруживает на верхнем правом из кот. Еще один счет карты может активировать, где он видит снизу-слева от автомобиля. Ты понимаешь, в чем дело. По сути, эти счет карты сверточных характеристика карт, которые были обучены распознавать определенные части каждого объекта.
Теперь R-FCN работает следующим образом
- Запустите CNN (в данном случае ResNet) над входным изображением
- Добавить полностью сверточного слоя, чтобы создать счет банка из вышеупомянутых “позиционно-чувствительных счет карты."Должны быть карты очков k2(C+1), с K2, представляющим количество относительных позиций, чтобы разделить объект (например, 32 для сетки 3 на 3) и C+1, представляющий количество классов плюс фон.
- Запустите полностью сверточную сеть предложений по регионам (RPN) для создания интересующих регионов (RoI
- Для каждого RoI разделите его на те же K2” bins " или субрегионы, что и оценочные карты
- Для каждой ячейки проверьте, соответствует ли эта ячейка соответствующей позиции какого-либо объекта. Например, если я нахожусь в” верхнем левом "Бине, я возьму карты баллов, которые соответствуют” верхнему левому" углу объекта и усредняют эти значения в регионе RoI. Этот процесс повторяется для каждого класса.
- После того, как каждая из ячеек K2 имеет значение “соответствие объекта” для каждого класса, усредните ячейки, чтобы получить один балл за класс.
- Классифицировать RoI с softmax над оставшимся C + 1 мерным вектором
В целом, R-FCN выглядит примерно так, с RPN, генерирующим RoI
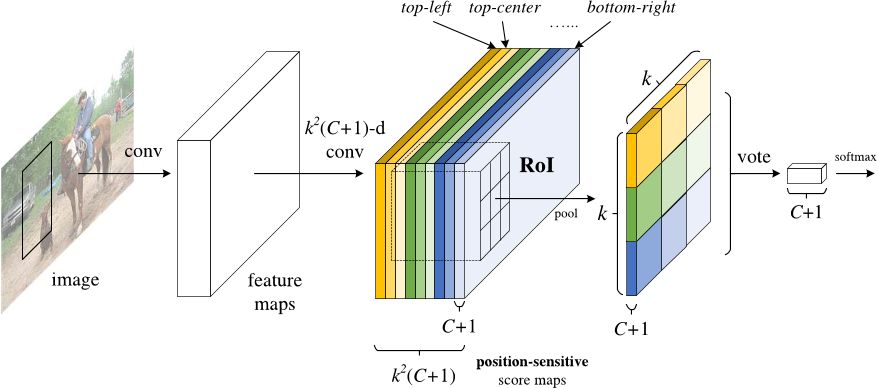
Даже с объяснением и изображением, вы все еще можете быть немного смущены тем, как работает эта модель. Честно говоря, R-FCN гораздо легче понять, когда вы можете визуализировать, что он делает. Вот один из таких примеров R-FCN на практике, обнаруживая ребенка

Проще говоря, R-FCN рассматривает каждое предложение по региону, делит его на подгруппы и перебирает подгруппы, спрашивая: "это похоже на верхний левый ребенка?", "это похоже на верхний центр ребенка?"это похоже на верхнюю правую часть ребенка?”, п. Он повторяет это для всех возможных классов. Если достаточное количество регионов скажут: "да, я совпаду с той частью ребенка!"RoI классифицируется как ребенок после softmax по всем классам.
С помощью этой установки, Р-ДТС способен одновременно решать расположении отклонений , предложив различный объект регионах, и место инвариантность , что каждый регион предложение обратиться в тот же банк на счет карты. Эти карты должны научиться классифицировать кошку как кошку, независимо от того, где появляется кошка. Лучше всего, это полностью свернуто, что означает, что все вычисления распределены по всей сети.
В результате R-FCN в несколько раз быстрее, чем R-CNN, и достигает сопоставимой точности.
ТВЕРДОТЕЛЬНЫЙ ДИСК
Наша окончательная модель SSD, который расшифровывается сингл-сгорячей дetector. Как и R-FCN, он обеспечивает огромные увеличения скорости по сравнению с более быстрым R-CNN, но делает это заметно по-другому.
Наши первые две модели выполняли региональные предложения и классификации регионов в два отдельных этапа. Во-первых, они использовали сеть региональных предложений для создания интересующих регионов; затем они использовали либо полностью связанные слои, либо чувствительные к Положению сверточные слои для классификации этих регионов. SSD делает два в “одном кадре”, одновременно предсказывая ограничивающую рамку и класс, как он обрабатывает изображение.
Конкретно, учитывая входное изображение и набор меток "правда земли", SSD делает следующее
- Передайте изображение через серию сверточных слоев, производя несколько наборов векторных карт в разных масштабах (например, 10x10, затем 6x6, затем 3x3 и т. д.
- Для каждого места в каждый из этих объектов карты, использовать 3х3 сверточного фильтра, чтобы оценить небольшой набор по умолчанию рамки. Эти ограничивающие рамки по умолчанию по существу эквивалентны более быстрым полям привязки R-CNN.
- Для каждого блока одновременно предсказать а) граничное смещение и б) вероятности классов
- Во время обучения, соответствуют земле, правды коробка с этими предсказал поля, основываясь на вексель. Лучший прогнозируемый ящик будет помечен как "положительный", наряду со всеми другими ящиками, которые имеют IoU с правдой >0,5.
SSD звучит просто, но обучение имеет уникальный вызов. С предыдущими двумя моделями сеть региональных предложений гарантировала, что все, что мы пытались классифицировать, имело некоторую минимальную вероятность быть “объектом"."Однако с SSD мы пропускаем этот шаг фильтрации. Мы классифицируем и нарисовать рамки, у каждой позиции в изображения, используя несколько различных форм, в различных масштабах. В результате мы создаем гораздо большее количество ограничителей, чем другие модели, и почти все они являются отрицательными примерами.
Чтобы исправить этот дисбаланс, SSD делает две вещи. Во-первых, он использует не-максимального подавления , чтобы сгруппировать высоко-перекрытие коробки в одной коробке. Другими словами, если 4 коробки подобных форм, размеров, etc. содержите одну и ту же собаку, NMS сохранит ту, у которой самая высокая уверенность, и отбросит остальных. Во-вторых, модель использует технику, называемую негатив горнодобывающей сбалансировать занятия во время тренировки. В тяжелом отрицательном майнинге на каждой итерации обучения используется только подмножество отрицательных примеров с наибольшей тренировочной потерей (т. е. ложными срабатываниями). SSD сохраняет соотношение 3: 1 негативов к положительным.
Его архитектура выглядит так
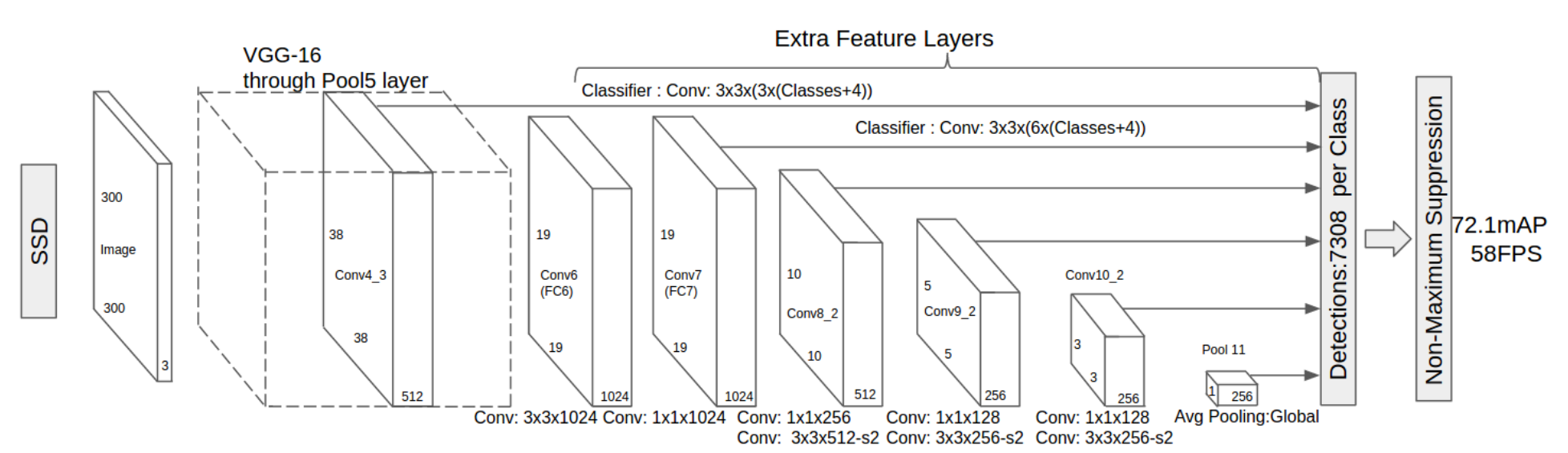
Как я уже упоминал выше, в конце есть” дополнительные векторные слои", которые уменьшают Размер. Эти карты объектов разного размера помогают захватывать объекты разных размеров. Например, вот SSD в действии
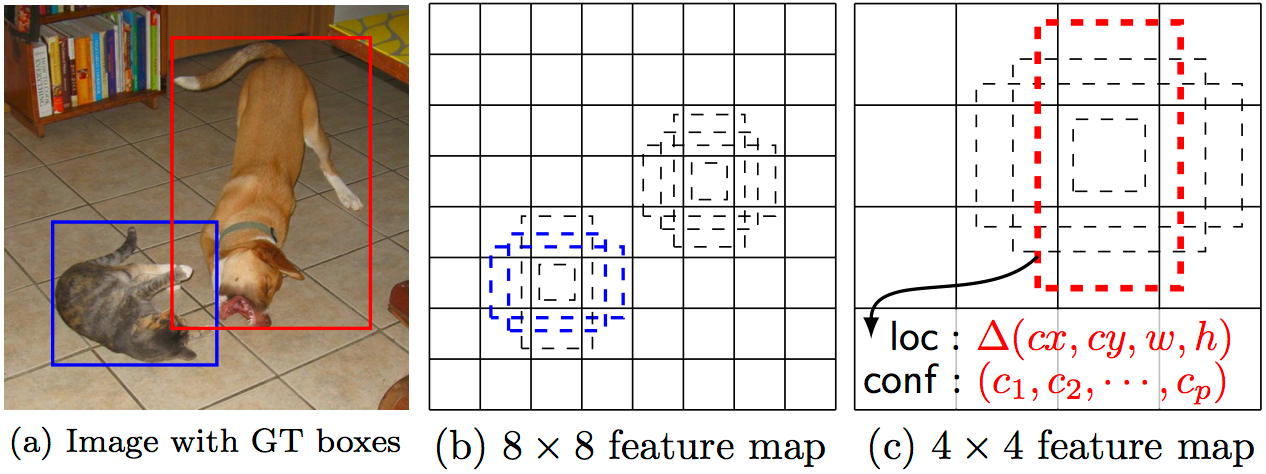
На картах объектов меньшего размера (например, 4x4) каждая ячейка охватывает большую область изображения, позволяя обнаруживать объекты большего размера. Области предложение и классификации выполняются одновременно: дали п предмет классы, в каждом ограничивающего прямоугольника связан с (4+р)-мерный вектор, который выводит 4 коробка смещение координат и п класс вероятностей. На последнем шаге softmax снова используется для классификации объекта.
В конечном счете, SSD не так сильно отличается от первых двух моделей. Он просто пропускает шаг “предложение по региону", вместо этого рассматривая каждую ограничивающую рамку в каждом месте изображения одновременно с его классификацией. Потому, что SSD делает все в одном кадре, это самый быстрый из трех моделей, и по-прежнему выполняет вполне сопоставимо.
Вывод
Faster R-CNN, R-FCN и SSD являются тремя из лучших и наиболее широко используемых моделей обнаружения объектов там прямо сейчас. Другие популярные модели, как правило, довольно похожи на эти три, все полагаются на глубокие CNN (читай: ResNet, Inception и т. д.) сделать первоначальный тяжелый подъем и в основном следовать тому же предложению / классификационному трубопроводу.
На данный момент, использование этих моделей требует знания API Tensorflow. Tensorflow имеет стартера руководство по использованию этих моделей здесь. Дайте ему попробовать, и счастливый взлом!
Телеграм: t.me/ainewsline
Источник: towardsdatascience.com