FeatureSelector: отбор признаков для машинного обучения на Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-08-13 18:00
Поиск и отбор признаков в исходных данных является важнейшим этапом обучения. Рассмотрим 5 методов выборки и один удобный инструмент.

Ненужные признаки снижают скорость обучения модели, интерпретируемость и, главное, способность к обобщению. FeatureSelector – это специальный класс для отбора информативных признаков, написанный на языке Python, реализующий самые распространенные методы выборки. Его исходный код доступен на GitHub. Инструмент позволяет оценивать параметры по следующим характеристикам:
- высокий процент пропущенных значений;
- коллинеарность (сильная корреляция);
- нулевая важность в моделях, основанных на деревьях;
- низкая важность;
- единственное значение.
В статье мы рассмотрим пример использования FeatureSelector для машинного обучения на реальном наборе данных и убедимся, что он позволяет организовать работу быстро и эффективно.
На текущий момент инструмент находится в стадии разработки, так что вы можете внести собственный вклад в его развитие.
Исходный набор данных
Для примера мы будем использовать данные из Kaggle-соревнования по вычислению кредитных рисков. Загрузить полный датасет можно здесь. Его структура представлена на изображении:

Это задача контролируемой классификации. Набор данных замечательно подходит для примера. В нем много пропущенных значений, сильно коррелированных (коллинеарных) и нерелевантных признаков, которые мешают эффективному обучению модели.
Создание экземпляра
При создании экземпляра класса FeatureSelector ему необходимо передать структурированный набор данных с объектами наблюдения в строках и атрибутами в столбцах. Некоторые методы могут работать только с признаками, но методам, основанным на важности, нужны обучающие метки. Так как у нас задача контролируемой классификации, мы будем использовать набор функций и набор меток.
Убедитесь, что вы запускаете этот код в той же директории, что и feature_selector.py:
| 1 2 3 4 | fromfeature_selector importFeatureSelector # Признаки - в train, метки - в train_labels fs=FeatureSelector(data=train,labels=train_labels) |
Методы
FeatureSelector имеет 5 методов для отбора неподходящих для обучения признаков. Любой идентифицированный объект можно удалить из набора вручную или с помощью функции remove. Мы разберем каждый метод и даже запустим их вместе.
FeatureSelector также умеет строить графики, ведь визуальный контроль данных – это важный компонент машинного обучения.
Пропущенные значения
Первый метод осуществляет отбор признаков по очень простому алгоритму: подсчет количества пропущенных значений. Если оно превышает заданный порог, параметр рекомендуется удалить.
Этот код идентифицирует признаки, имеющие более 60% пропусков:
| 1 2 3 | fs.identify_missing(missing_threshold=0.6) ->17features withgreater than0.60missing values. |
В этом фрейме показаны доли незаполненных значений для каждого параметра:
| 1 | fs.missing_stats.head() |
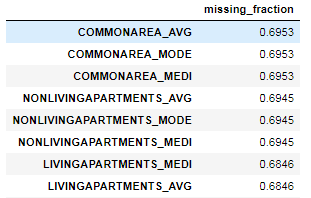
Чтобы увидеть удаляемые признаки, нужно обратиться к атрибуту ops класса FeatureSelector, который является словарем:
| 1 2 3 4 5 6 7 8 | missing_features=fs.ops['missing'] missing_features[:5] ['OWN_CAR_AGE', 'YEARS_BUILD_AVG', 'COMMONAREA_AVG', 'FLOORSMIN_AVG', 'LIVINGAPARTMENTS_AVG'] |
Построим график распределения пропущенных значений по всем атрибутам:
| 1 | fs.plot_missing() |
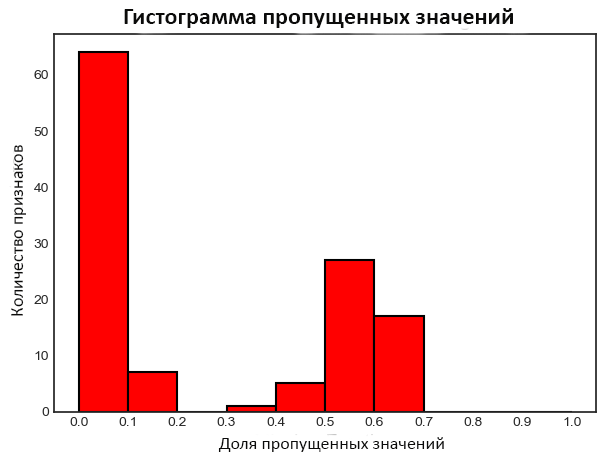
Коллинеарные признаки
Коллинеарными называются признаки, которые сильно коррелируют друг с другом. В машинном обучении это приводит к снижению производительности обобщения данных из-за высокой дисперсии и меньшей интерпретируемости модели.
Метод identify_collinear находит коллинеарные предикторы на основе заданного значения коэффициента корреляции. Для каждой пары коррелированных признаков он определяет один для удаления (так как нужно удалить только один):
| 1 2 | fs.identify_collinear(correlation_threshold=0.98) ->21features withacorrelation magnitude greater than0.98. |
Для визуализации можно построить тепловую карту. Она показывает все параметры, у которых есть хотя бы одна корреляция выше порогового значения:
| 1 | fs.plot_collinear() |
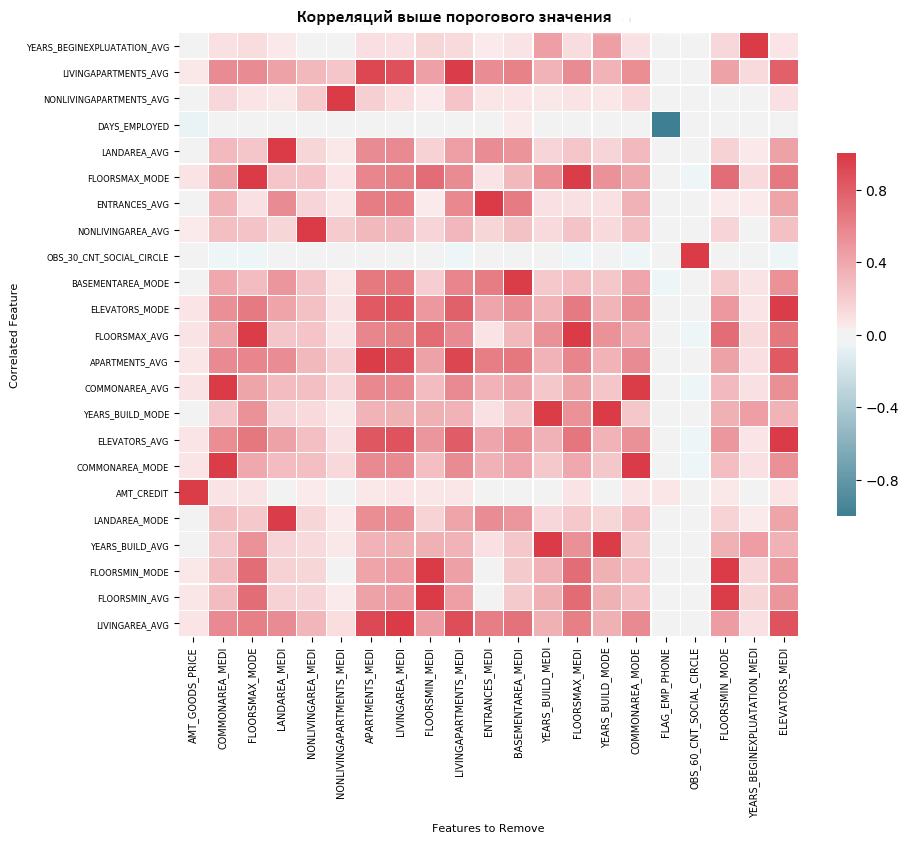
Как и раньше, можно получить доступ к полному списку удаляемых признаков или изучить сильно коррелированные пары параметров в датафрейме:
| 1 2 3 4 5 | # список признаков для удаления collinear_features=fs.ops['collinear'] # датафрейм коллинеарных признаков fs.record_collinear.head() |

Можно также построить график всех корреляций в наборе, передав вызову plot_all=True:
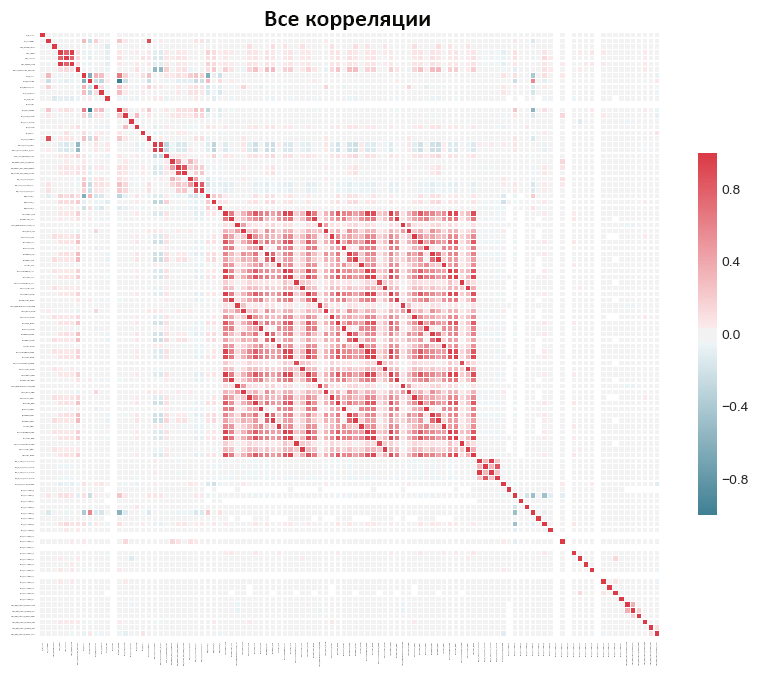
Признаки с нулевой важностью
Два перечисленных метода могут быть применены к любому структурированному набору данных. Они являются детерминированными, то есть результаты их работы не меняются в разных подходах.
Метод, который мы разберем сейчас, недетерминированный и предназначен только для задач контролируемого машинного обучения с обучающими метками. Функция identify_zero_importance находит признаки, которые имеют нулевую важность. В моделях на основе деревьев решений такие параметры не используются, поэтому мы можем смело удалить их, не влияя на производительность.
FeatureSelector устанавливает важность признаков с помощью алгоритма градиентного бустинга из библиотеки LightGBM. Показатель усредняется по 10 тренировочным прогонам GBM для уменьшения дисперсии. Кроме того, используется ранняя остановка с проверочным набором, чтобы предотвратить переобучение. Эту опцию можно отключить.
Приведенный ниже код производит отбор признаков с нулевой важностью:
| 1 2 3 4 5 6 7 8 | fs.identify_zero_importance(task='classification', eval_metric='auc', n_iterations=10, early_stopping=True) zero_importance_features=fs.ops['zero_importance'] ->63features with zero importance after one-hot encoding. |
Передаваемые параметры:
- task –
classificationилиregressionв зависимости от задачи; - eval_metric – метрика для ранней остановки (не требуется, если ранняя остановка отключена);
- n_iterations – количество прогонов обучения для усреднения важности;
- early_stopping – включение/отключение ранней остановки.
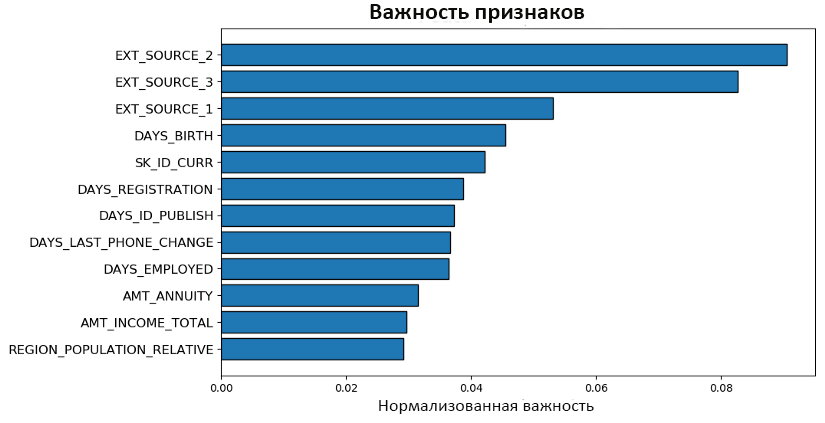
Построим с помощью plot_feature_importance два графика:
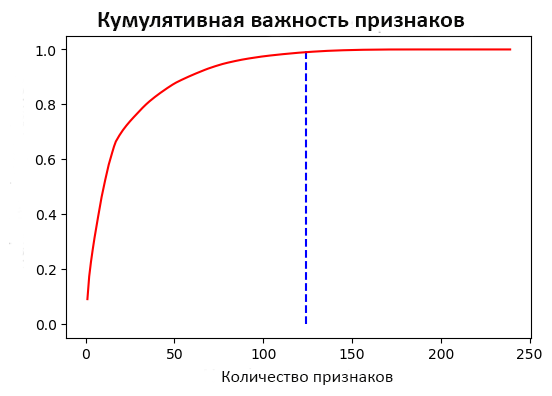
| 1 2 3 | fs.plot_feature_importances(threshold=0.99,plot_n=12) ->124features required for0.99of cumulative importance |
Здесь мы видим нормализованные показатели важности plot_n самых значимых признаков:
На этом графике отражено изменение кумулятивной важности в зависимости от общего количества признаков. Вертикальная линия отмечает пороговое значение, в данном случае 99%.
Две важные вещи, которые нужно помнить, производя отбор признаков по важности:
- Алгоритм градиентного бустинга является стохастическим. Это означает, что важность параметров будет меняться при каждом запуске модели. Отличия обычно некритичны, самые важные атрибуты не опустятся на последние места. Однако их порядок вполне может измениться, не удивляйтесь.
- Среди удаляемых могут оказаться признаки, закодированные с помощью алгоритма one-hot encoding, которые могут потребоваться для дальнейшего обучения.
Признаки с низкой важностью
Этот метод основан на предыдущем. Функция identify_low_importance находит параметры с наименьшей значимостью, которые не влияют на указанный общий уровень. Например, этот вызов отберет признаки, которые не вносят вклад в 99% общего значения:
| 1 2 3 4 | fs.identify_low_importance(cumulative_importance=0.99) ->123features required forcumulative importance of0.99after one hot encoding. ->116features do notcontribute to cumulative importance of0.99. |
Основываясь на графике кумулятивной важности, градиентный бустинг считает многие аргументы неактуальными. Опять же, результаты этого метода будут меняться при каждом обучении.
Можно просмотреть все удаляемые объекты в датафрейме:
| 1 | fs.feature_importances.head(10) |
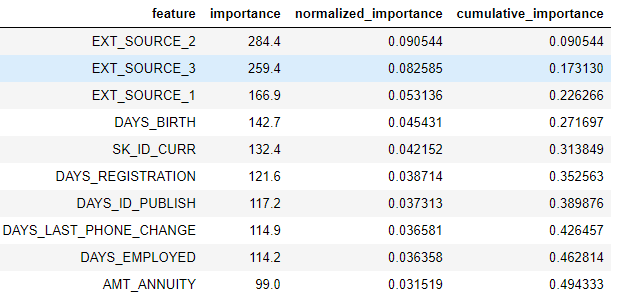
Функция low_importance основывается на том же подходе, что и метод главных компонент (PCA).
Отбор признаков по их важности применим только в случае использования решающего дерева для создания прогнозов. Помимо того, что эти методы являются стохастическими, они представляют собой черный ящик, поскольку мы не знаем, почему модель считает признаки неактуальными. Запустите их несколько раз, чтобы увидеть, как изменяются результаты, и создайте при необходимости несколько наборов данных с разными параметрами для тестирования!
Признаки с единственным значением
Последний метод просто отбирает все столбцы, которые содержат только одно значение. Такие признаки не могут быть полезны для машинного обучения, так как имеют нулевую дисперсию. Например, деревья решений не могут их разделить.
Этот метод не принимает никаких параметров для настройки:
| 1 2 3 | fs.identify_single_unique() ->4features withasingle unique value. |
Построим гистограмму количества уникальных значений для каждого признака:
| 1 | fs.plot_unique() |
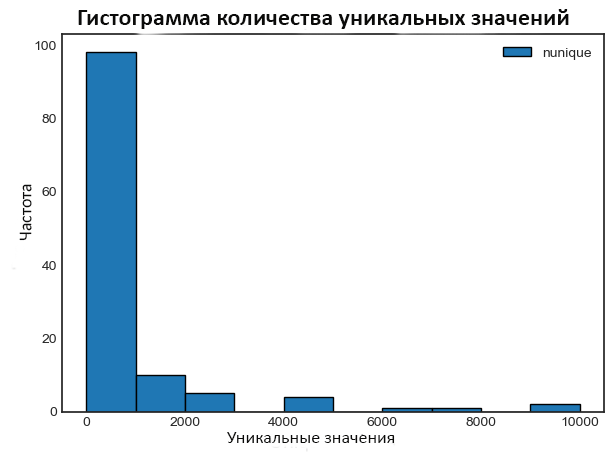
Помните, что Pandas отбрасывает значения NaN перед вычислением.
Удаление признаков
После того как отбор признаков осуществлен, их можно удалить двумя способами. Все параметры хранятся в словаре ops класса FeatureSelector, и их можно использовать для ручного удаления. Кроме того, существует встроенная функция remove, которая сделает все за вас.
В параметр methods нужно передать функции отбора или ключевое слово all, чтобы задействовать все реализованные методы.
| 1 2 3 4 5 | train_removed=fs.remove(methods='all') ->['missing','single_unique','collinear','zero_importance','low_importance']methods have been run ->Removed140features. |
Метод возвращает фрейм данных с удаленными параметрами. Можно также удалить one-hot признаки, созданные во время обучения:
| 1 2 3 | train_removed_all=fs.remove(methods='all',keep_one_hot=False) ->Removed187features including one-hot features. |
Исходный набор данных всегда хранится в виде резервной копии в атрибуте data.
Отбор признаков всеми методами
Вместо отдельного использования разных методов, можно запустить их одновременно с помощью identify_all. Эта функция принимает словарь параметров:
| 1 2 3 4 5 6 7 | fs.identify_all(selection_params={'missing_threshold':0.6, 'correlation_threshold':0.98, 'task':'classification', 'eval_metric':'auc', 'cumulative_importance':0.99}) ->151total features out of255identified forremoval after one-hot encoding. |
Обратите внимание, что общее количество признаков изменилось, так как мы повторно запустили модель. Затем можно вызвать функцию remove, чтобы удалить отобранные параметры.
Выводы
Класс FeatureSelector реализует несколько распространенных операций удаления признаков перед обучением модели. Их можно запускать по отдельности и одновременно. Кроме идентификации параметров, инструмент способен строить графики и гистограммы для визуализации.
Отбор признаков по пропущенным значениям, коллинеарности и малой дисперсии детерминирован, а методы основанные на важности, напротив, при каждом запуске выдают другие результаты. Выбор функции для отбора, как и вся сфера машинного обучения, является эмпирическим и требует тестирования нескольких комбинация для поиска оптимального варианта. FeatureSelector позволяет делать это быстро и эффективно.
Помните, что вы можете внести свой вклад в развитие проекта FeatureSelector.
Перевод статьи William Koehrsen: A Feature Selection Tool for Machine Learning in Python
Другие интересные статьи по Data Science
Телеграм: t.me/ainewsline
Источник: proglib.io