Школа медицины при Нью-Йоркском университете планирует ускорить МРТ-сканирование как минимум в 10 раз. Поможет им в этом группа исследователей искусственного интеллекта из Facebook (FAIR) с помощью технологий машинного обучения. Проект называется fastMRI. Медики предоставят для него датасет из 3 миллионов снимков мозга, коленей и печени, собранные с 10 тысяч пациентов, а Facebook — свои наработки по машинному обучению для тренировки алгоритма. Согласно задумке, аппарат МРТ будет собирать только часть информации, а пробелы заполнит обученная нейросеть. Приемлемые для реального использования результаты исследователи планируют опубликовать в течении года под свободной лицензией. Аппарат для МРТ воздействует на ткань электромагнитным излучением и фиксирует выделение энергии в виде цифровых данных, из которых потом формируют снимки — «двумерные срезы». Процесс может длиться от 15 минут до часа. Чем больше данных необходимо собрать, тем дольше требуется воздействие.
Человеку в это время надо лежать и не двигаться. Для некоторых пациентов — например, маленьких детей, людей, страдающих клаустрофобией или испытывающих боли в лежачем положении — это может быть проблемой.
Первые попытки ускорить получение снимка исследователи при Школе медицины предприняли в 2015 году. Ученые предположили, что время в аппарате можно сократить, собрав только часть данных, а оставшиеся пробелы заполнить с помощью обученного ИИ на нейросетевых алгоритмах.
Аппараты МРТ в целом довольно гибкие в плане количества данных, необходимых для получения результата. Но после первых попыток, исследователи пришли к выводу, что для воссоздания качественных снимков необходимо даже меньше данных, чем они предполагали.
Сложность в том, что когда при обработке фото и видео нейросетевые алгоритмы заполняют похожим образом пробелы, дорисовывая пиксели на основе полученных данных, допущения и отклонения не критичны, по крайней мере в вопросах жизни и смерти. Но в анализе снимков МРТ на диагноз может повлиять каждый миллиметр.
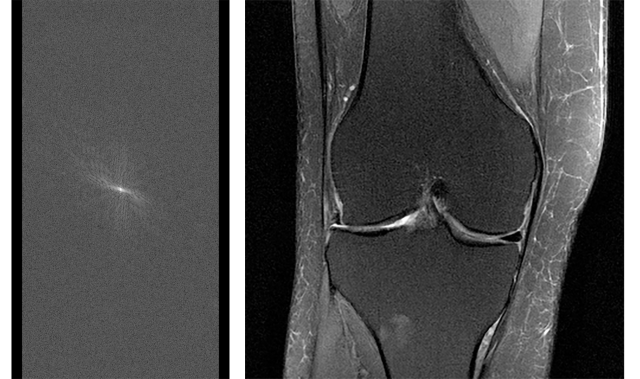
Слева на этом изображении полный набор исходных данных, собранных МРТ. А справа снимок колена, который из них получен.
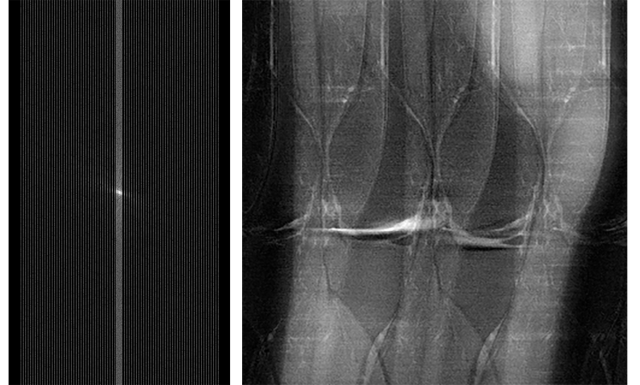
А на этом — частичный набор данных и снимок колена, полученный с помощью нейросетевых алгоритмов на данном этапе.
Помимо вопросов с точностью воссоздания, проект поднимает некоторые этические проблемы.
Решением похожих задач с компьютерным зрением — только в других сферах — занимались инженеры Facebook. Они говорят, что участие в этом проекте — хороший способ для них применить технологии на практике. Но сбор персональных данных компаниями, которые зарабатывают на их монетизации — в последнее время особо чувствительный вопрос. Тем более, если речь идет о медицинских данных.
Исследователи заявляют, что в датасетах нет информации о личностях пациентов, имен и медицинских сведений — только сами снимки и исходные данные, из которых эти снимки получены. Представители Facebook также утверждают, что в проекте не использованы данные, которые собирает компания сама.
Как сообщил изданию VentureBeat представитель Facebook, результатов стоит ждать в течении года. Как только будет проделан необходимый прогресс, исследователи выложат в общий доступ все модели, метрики и датасеты, на которых обучали ИИ для того, чтобы их могли использовать другие клиники.