Доступность API: естественно-языковые интерфейсы
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-08-07 17:05

Перевод статьи, выполненный Александром Гуреевым для блога Microsoft на Хабрахабр
Программные интерфейсы приложения (API) играют все более важную роль как в виртуальном, так и в физическом мире благодаря развитию технологий, таких как сервис-ориентированная архитектура, облачные вычисления и Интернет вещей (IoT). Сегодня наши коллеги из подразделения Microsoft Research поделились своими наработками в сфере Natural Language Interfaces (естественно-языковые интерфейсы). Присоединяйтесь!
Размещенные в облаке веб-службы, посвященные погоде, спорту и финансам, через веб-API предоставляют данные и услуги конечным пользователям, а устройства из IoT дают возможность другим устройствам в сети использовать свою функциональность.
Обычно API-интерфейсы используются в различном программном обеспечении: в приложениях для рабочего стола, веб-сайтах и мобильных приложениях. Также они обслуживают пользователей с помощью графического пользовательского интерфейса (GUI). Графические интерфейсы внесли большой вклад в популяризацию компьютеров, но, по мере развития вычислительной техники, все больше проявляются их многочисленные ограничения. Поскольку устройства становятся все меньше размером, мобильнее и умнее, к графическому изображению на экране предъявляются все более высокие требования, например, в отношении переносных устройств или устройств, подключенных к IoT.
Пользователи также вынуждены привыкать к большому разнообразию графических интерфейсов при использовании различных сервисов и устройств. По мере увеличения числа доступных сервисов и устройств растут и расходы на обучение и адаптацию пользователей. Естественно-языковые интерфейсы (NLI) демонстрируют значительный потенциал в качестве единого интеллектуального инструмента для широкого спектра служб серверной части и устройств. NLI обладают невероятными возможностями по определению намерений пользователя и распознаванию контекстуальной информации, что делает приложения, такие как виртуальные помощники, значительно удобнее для пользователей.
Мы изучали естественно-языковые интерфейсы для API (NL2API). В отличие от NLI общего назначения, таких как виртуальные помощники, мы пытались понять, как создавать NLI для отдельных веб-API, например API для службы календаря. В перспективе такие NL2API смогут демократизировать API, помогая пользователям взаимодействовать с программными системами. Они также могут решить проблему масштабируемости виртуальных помощников общего назначения, предоставив возможность распределенной разработки. Полезность виртуального помощника во многом зависит от широты его возможностей, то есть от количества поддерживаемых им сервисов.
Однако интегрировать веб-сервисы в виртуального помощника по одному — невероятно кропотливая работа. Если бы у индивидуальных провайдеров веб-сервисов был простой способ создания NLI для своих API-интерфейсов, то затраты на интеграцию можно было бы значительно сократить. А виртуальному помощнику не нужно было бы обрабатывать разные интерфейсы для разных веб-сервисов. Ему достаточно было бы просто интегрировать отдельные NL2API, которые достигают единообразия благодаря естественному языку. NL2API также может облегчить разработку веб-сервисов, программирование систем рекомендаций и помощи для API. Тем самым не придется запоминать большое количество доступных веб-API и их синтаксис.
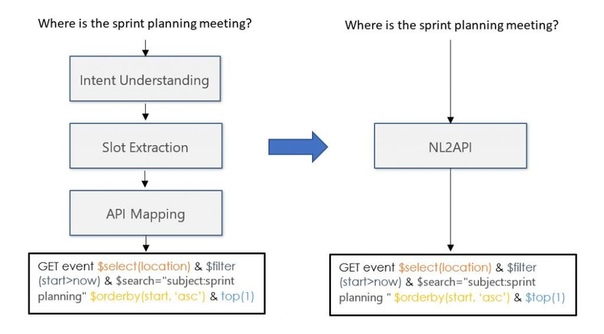
Основная задача NL2API состоит в том, чтобы распознавать выражения в естественном языке пользователя и переводить их в запрос к API. Если быть точнее, мы сосредоточились на веб-API, созданных по подобию архитектуры REST, то есть RESTful API. RESTful API широко используются в веб-сервисах, устройствах для IoT, а также в приложениях для смартфонов. Пример из Microsoft Graph API приведен на рисунке 1.
На левой стороне рисунка показан традиционный метод построения естественного языка, в котором мы обучаем модели восприятия языка распознавать намерения, а другие модели извлекать ячейки, связанные с каждым из намерений, и затем вручную сопоставлять их с запросами к API, прописывая код. Вместо этого (как показано на правой стороне рисунка), мы можем научиться переводить выражения из естественного языка напрямую в запросы к API. В рамках исследования мы применяем нашу систему для API-интерфейсов из пакета Microsoft Graph API. Веб-API Microsoft Graph позволяют разработчикам получать доступ к данным, обеспечивающим повышение производительности: почте, календарю, контактам, документам, каталогам, устройствам и многому другому.

Одним из требований к разрабатываемой нами модели является возможность создавать детальный пользовательский интерфейс. Большинство существующих NLI мало чем могут помочь пользователям в том случае, когда команда была неправильно распознана. Мы предполагаем, что более детальное взаимодействие с пользователем может сделать NLI значительно более удобными.
Мы разработали модульную модель, работающую по принципу «от последовательности к последовательности» (см. рис. 3), чтобы обеспечить детальное взаимодействие с NLI. Для этого мы используем архитектуру, работающую по принципу «от последовательности к последовательности», но при этом разбиваем результат дешифровки на несколько интерпретируемых единиц, называемых модулями.
Каждый модуль пытается спрогнозировать заранее определенный результат, например, задействуя определенный параметр на основе поступающего в NL2API высказывания. После простого сопоставления пользователи смогут легко понять результат прогноза любого модуля и взаимодействовать с системой на модульном уровне. Каждый модуль в нашей модели генерирует последовательные результаты, а не непрерывное состояние.

Модули: сначала мы определим, что такое модуль. Модуль представляет собой специализированную нейронную сеть, предназначенную для выполнения конкретной задачи по прогнозированию последовательности. В NL2API разные модули соответствуют различным параметрам. Например, в GET-Messages API модулями будут являться FILTER (sender), FILTER (isRead), SELECT (attachments), ORDERBY (receivedDateTime), SEARCH и т. д. Задача модуля — в случае активации распознать входящее высказывание и создать полный параметр. Для этого модуль должен определить значения своего параметра на основании входящего высказывания.
Например, если входящее высказывание звучит как «непрочитанные письма по поводу докторской диссертации», модуль SEARCH должен предсказать, что значение параметра SEARCH — «докторская диссертация», и сгенерировать полный параметр «SEARCH докторская диссертация» в качестве последовательности на выходе. По аналогии модуль FILTER (isRead) должен запомнить, что такие фразы, как «непрочитанные электронные письма», «электронные письма, которые не были прочитаны» и «еще непрочитанные электронные письма» указывают на то, что значение его параметра должно быть «False».
Вполне естественно, что следующим шагом было создание модулей-декодеров, определяющих, на чем стоит сосредоточить внимание, как и в обычной модели «от последовательности к последовательности». Однако вместо одного декодера, который используется для всего, у нас теперь есть несколько декодеров, каждый из которых специализируется на прогнозировании конкретных параметров. Более того, поскольку каждый модуль имеет четко определенную терминологию, становится гораздо проще настроить взаимодействие с пользователем на модульном уровне.
Регулятор: для каждой вводной фразы будут использоваться только несколько модулей. Задача регулятора — определить, какие модули он будет запускать. Таким образом, регулятор также является декодером, определяющим, на чем стоит сосредоточить внимание. Кодируя высказывание и превращая его во входные данные, он создает последовательность модулей, называемую схемой. Затем модули создают соответствующие им параметры, и, наконец, параметры объединяются для формирования окончательного запроса к API.
Разбив сложный процесс прогнозирования в стандартной модели «от последовательности к последовательности» на небольшие узкоспециализированные единицы прогнозирования, называемые модулями, прогнозную модель будет легко объяснить пользователям. Затем, с помощью обратной связи от пользователей, можно будет исправить возможные ошибки прогнозирования на самом низком уровне. В нашем исследовании мы проверяем нашу гипотезу, сравнивая интерактивный NLI с его неинтерактивной версией как с помощью симуляции, так и с помощью экспериментов с участием людей, использующих реально работающие API. Мы можем продемонстрировать, что с помощью интерактивных NLI пользователи достигают успеха чаще и быстрее, что приводит к более высокому уровню удовлетворенности пользователей.
Телеграм: t.me/ainewsline
Источник: m.vk.com