Десять алгоритмов машинного обучения, которые вам нужно знать
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-08-12 19:18
машинное обучение python, искусственный интеллект, Основы нейронных сетей, Нейронные сети для начинающих

Мы живем в начале революционной эры аналитики данных, больших вычислительных мощностей и облачных вычислений. Машинное обучение играет в этом большую роль, а оно основано на алгоритмах. В этой статье собраны десять самых популярных алгоритмов машинного обучения.
Эти алгоритмы можно разделить на три основные категории.
- Контролируемые алгоритмы: набор обучающих данных имеет входные данные, а также желаемый результат. Во время обучения модель будет корректировать свои переменные для сопоставления входных данных с соответствующим выходом.
- Неконтролируемые алгоритмы: в этой категории нет желаемого результата. Алгоритмы будут группировать набор данных на разные группы.
- Алгоритмы с подкреплением: эти алгоритмы обучаются на готовых решениях. На основе этих решений алгоритм будет обучаться на основе успеха/ошибки результата. В конечном счете алгоритм сможет давать хорошие прогнозы.
Следующие алгоритмы будут описываться в этой статье.
- Линейная регрессия
- SVM (метод опорных векторов)
- KNN (метод k-ближайших соседей)
- Логистическая регрессия
- Дерево решений
- Метод k-средних
- Random Forest
- Наивный байесовский классификатор
- Алгоритмы сокращения размеров
- Алгоритмы усиления градиента
1. Линейная регрессия (linear regression)
Алгоритм линейной регрессии будет использовать точки данных для поиска оптимальной линии для создания модели. Линию можно представить уравнением y = m*x + c, где y – зависимая переменная, а x – независимая переменная. Базовые теории исчисления применяются для определения значений для m и c с использованием заданного набора данных.
Существует два типа линейной регрессии: простая линейная регрессия с одной независимой переменной и множественная линейная регрессия, где используется несколько независимых переменных.
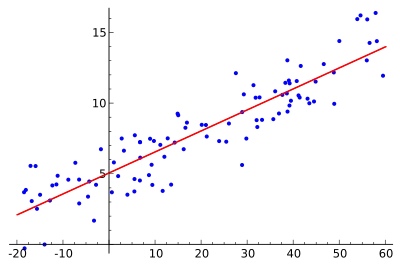
scikit-learn — это простой и эффективный инструмент для машинного обучения на Python. Ниже представлена реализация линейной регрессии при помощи scikit-learn.
from sklearn import linear_model, datasets #digit dataset from sklearn digits = datasets.load_digits() #create the LinearRegression model clf = linear_model.LinearRegression() #set training set x, y = digits.data[:-1], digits.target[:-1] #train model clf.fit(x, y) #predict y_pred = clf.predict([digits.data[-1]]) y_true = digits.target[-1] print(y_pred) print(y_true)
2. Метод опорных векторов (SVM — Support Vector Machine)
Он принадлежит к алгоритму классификационного типа. Алгоритм будет разделять точки данных, используя линию. Эта линия должна быть максимально удаленной от ближайших точек данных в каждой из двух категорий.
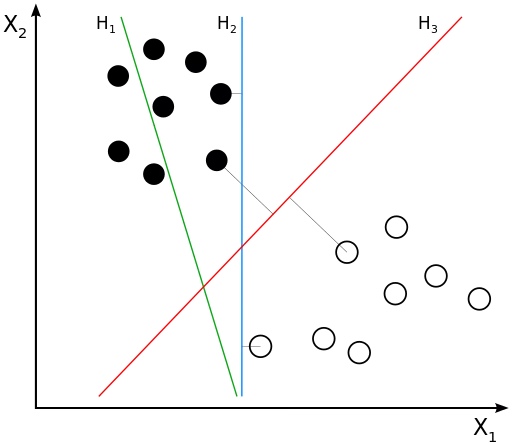
На диаграмме выше красная линия подходит лучше всего, так как она больше всего удалена от всех точек. На основе этой линии данные делятся на две группы.
from sklearn import svm, datasets #digit dataset from sklearn digits = datasets.load_digits() #create the Support Vector Classifier clf = svm.SVC(gamma = 0.001, C = 100) #set training set x, y = digits.data[:-1], digits.target[:-1] #train model clf.fit(x, y) #predict y_pred = clf.predict([digits.data[-1]]) y_true = digits.target[-1] print(y_pred) print(y_true)
3. Метод k-ближайших соседей (KNN — K-nearest neighbors)
Это простой алгоритм, который предсказывает неизвестную точку данных на основе её k ближайших соседей. Значение k здесь критически важный фактор, который определяет точность предсказания. Ближайшая точка определяется исходя из базовых функций расстояния, вроде Евклидовой.

Однако этот алгоритм требует высокой вычислительной мощности, и нам необходимо сначала нормализовать данные, чтобы каждая точка данных была в том же диапазоне.
from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier #digit dataset from sklearn digits = datasets.load_digits() #create the KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=6) #set training set x, y = digits.data[:-1], digits.target[:-1] #train model clf.fit(x, y) #predict y_pred = clf.predict([digits.data[-1]]) y_true = digits.target[-1] print(y_pred) print(y_true)
4. Логистическая регрессия (logistic regression)
Логистическая регрессия используется, когда ожидается дискретный результат, например, возникновение какого-либо события (пойдет дождь или нет). Обычно логистическая регрессия использует функцию, чтобы поместить значения в определенный диапазон.

“Сигмоид” — это одна из таких функций в форме буквы S, которая используется для бинарной классификации. Она конвертирует значения в диапазон от 0 до 1, что является вероятностью возникновения события.
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
Выше находится простое уравнение логистической регрессии, где b0 и b1 — это постоянные.Во время обучения значения для них будут вычисляться таким образом, чтобы ошибка между предсказанием и фактическим значением становилась минимальной.
5. Дерево решений (decision tree)
Этот алгоритм распределяет данные на несколько наборов на основе каких-либо свойств (независимых переменных). Обычно этот алгоритм используется для решения проблем классификации. Категоризация используется на основе методов вроде Джини, Хи-квадрат, энтропия и так далее.
Возьмем группу людей и используем алгоритм дерева решений, чтобы понять, кто из них имеет кредитную карту. Например, возьмем возраст и семейное положение в качестве свойств. Если человеку больше 30 лет и он/она замужем или женат, то вероятность того, что у них есть кредитная карта, выше.

Дерево решений можно расширить и добавить подходящие свойства и категории. Например, если человек женат и ему больше 30 лет, то он, вероятно, имеет кредитную карту. Данные тестирования будут использоваться для создания этого дерева решений.
6. Метод k-средних (k-means)
Это алгоритм, работающий без присмотра, который предоставляет решение проблемы группировки. Алгоритм формирует кластеры, которые содержат гомогенные точки данных.
Входные данные алгоритма — это значение k. На основе этого алгоритм выбирает k центроидов. Затем центроид и его соседние точки данных формируют кластер, а внутри каждого кластера создается новый центроид. Потом точки данных, близкие к новому центроиду снова комбинируются для расширения кластера. Процесс продолжается до тех пор, пока центроиды не перестанут изменяться.

7. Случайный лес (Random Forest)
Random Forest — это коллекция деревьев решений. Каждое дерево пытается оценить данные, и это называется голосом. В идеале мы рассматриваем каждый голос от каждого дерева и выбираем классификацию с большим количеством голосов.

8. Наивный байесовский классификатор (Naive Bayes)
Этот алгоритм основан на теореме Байеса. Благодаря этому наивный байесовский классификатор можно применить, только если функции независимы друг от друга. Если мы попытаемся предсказать вид цветка на основе длины и ширины его лепестка, мы сможем использовать этот алгоритм, так как функции не зависят друг от друга.
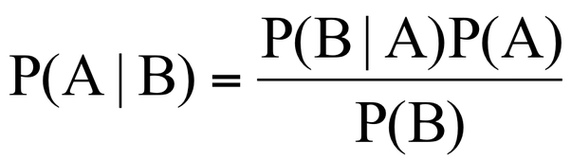
Наивный байесовский алгоритм также является классификационным. Он используется, когда проблема содержит несколько классов.
9. Алгоритмы сокращения размеров (dimensional reduction algorithms)
Некоторые наборы данных содержат много переменных, которыми сложно управлять. Особенно сейчас, когда системы собирают большое количество детализированных данных из разных источников. В таких случаях данные могут содержать тысячи переменных, многие из которых будут не нужны.
В таком случае почти невозможно определить переменные, которые будут иметь наибольшее влияние на наше предсказание. в таких ситуациях используются алгоритмы сокращения размеров. Они применяют алгоритмы вроде случайного леса или дерева решений, чтобы определить самые важные переменные.
10. Алгоритмы усиления градиента (gradient boosting algorithms)
Алгоритм усиления градиента использует множество слабых алгоритмов, чтобы создать более точный, стабильный и надежный алгоритм.
Существует несколько алгоритмов усиления градиента:
- XGBoost — использует линейные алгоритмы и дерево решений
- LightGBM — использует только алгоритмы, основанные на деревьях
Особенность алгоритмов усиления градиента — это их высокая точность. Более того, алгоритмы вроде LightGBM имеют и высокую производительность.
Телеграм: t.me/ainewsline
Источник: m.vk.com