Deep Learning: Распознавание сцен и достопримечательностей на изображениях
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-08-22 10:16
теория распознавания образов, машинное обучение новости, свёрточные нейронные сети

Статья написана пользователем ValeriaKhokha для Хабрахабр
Время пополнять копилку хороших русскоязычных докладов по Machine Learning! Копилка сама не пополнится!
В этот раз мы познакомимся с увлекательным рассказом Андрея Боярова про распознавание сцен. Андрей — программист-исследователь, занимающийся машинным зрением в компании Mail.Ru Group.
Распознавание сцен — одна из активно применяемых областей машинного зрения. Задача эта посложнее, чем изученное распознавание объектов: сцена — более комплексное и менее формализованное понятие, выделить признаки труднее. Из распознавания сцен вытекает задача распознавания достопримечательностей: нужно выделить известные места на фото, обеспечив низкий уровень ложных срабатываний.
Это 30 минут видео с конференции Smart Data 2017. Видео удобно смотреть дома и в дороге. Для тех же, кто не готов столько сидеть у экрана, или кому удобней воспринимать информацию в текстовом виде, мы прикладываем полную текстовую расшифровку, оформленную в виде статьи.
Я занимаюсь машинным зрением в компании Mail.ru. Сегодня я расскажу про то, как мы используем deep learning для распознавания изображений сцен и достопримечательностей.
В компании возникла необходимость в тегировании и поиске по изображениям пользователей, и для этого мы решили сделать свой Computer Vision API, частью которого будет инструмент тегирования по сценам. В результате работы этого инструмента мы хотим получить нечто такое, как представлено на картинке ниже: пользователь делает запрос, например, «собор», и получает все свои фотографии с соборами.
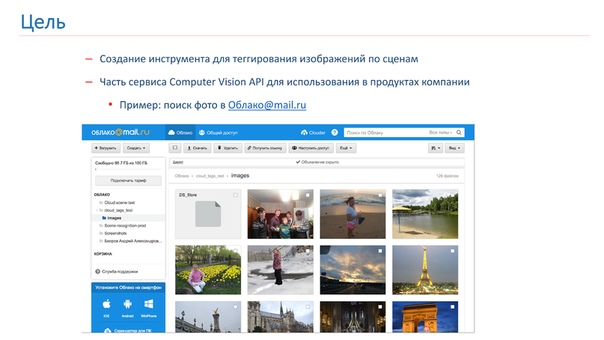
В Computer Vision-комьюнити достаточно неплохо изучена тема распознавания объектов на изображениях. Есть известный конкурс ImageNet, который проводится уже несколько лет и основной частью которого является распознавание объектов.
Нам в основном нужно локализовать некоторый объект и классифицировать его. Со сценами задача несколько сложнее, потому что сцена — это более комплексный объект, она состоит из большого числа других объектов и объединяющего их контекста, поэтому задачи отличаются.

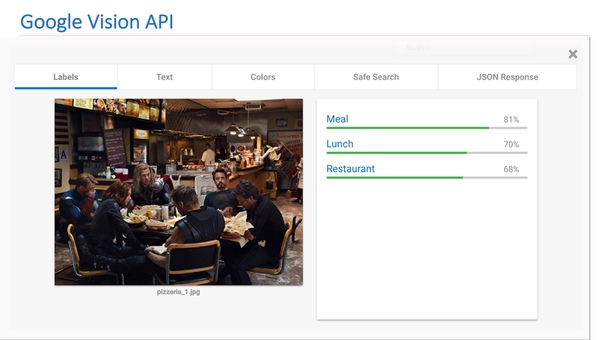
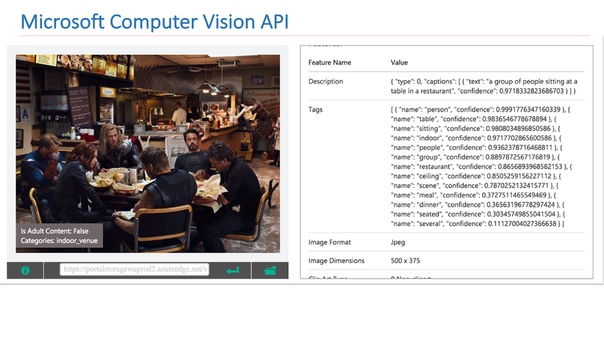
В интернете есть доступные сервисы от других компаний, которые реализуют такой функционал. В частности, это Google Vision API или Microsoft Computer Vision API, который умеет находить сцены на изображениях.
Мы решали эту задачу с помощью машинного обучения, поэтому для этого нам нужны данные. В открытом доступе сейчас есть две основные базы по распознаванию сцен. Первая из них появилась в 2013 году — это база SUN от Принстонского университета. Эта база состоит из сотни тысяч изображений и 397 классов.
Вторая база, на которой мы обучались, — это база Places2 от MIT. Она появилась в 2013 году в двух вариантах. Первый — Places2-Standart, более сбалансированная база с 1,8 млн. изображений и 365 классов. Второй вариант — Places2-Challenge, содержит восемь миллионов изображений и 365 классов, но количество изображений между классами не сбалансировано. В конкурс ImageNet 2016 года в раздел Scene Recognition входил Places2-Challenge, и победитель показал лучший результат Top-5 classification error около 9%.

Мы обучались на базе Places2. Вот пример изображения оттуда: это каньон, взлетно-посадочная полоса, кухня, футбольное поле. Это абсолютно разные сложные объекты, на которых нам нужно научиться распознавать.
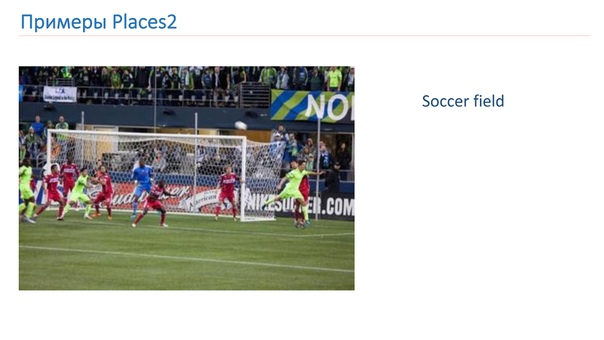

Перед тем как обучаться, мы адаптировали базы, которые у нас есть, под свои нужды. Для Object Recognition есть такой прием, когда с моделями проводят эксперименты на небольших базах CIFAR-10 и CIFAR-100 вместо ImageNet, а уже потом лучшие обучают на ImageNet.
Мы решили пойти по тому же пути, взяли базу SUN, уменьшили ее, получили 89 классов, 50 тысяч изображений на train и 10 тысяч изображений на validation. В итоге перед тем, как обучать на Places2, мы ставили эксперименты и проверяли наши модели на базе SUN. Обучение на ней занимает всего 6-10 часов, в отличие от нескольких суток на Places2, что позволяло провести гораздо больше экспериментов и сделать это эффективнее.
Мы также просмотрели саму базу Places2 и поняли, что некоторые классы нам не нужны. Или из соображений продакшна, или из-за того, что на них есть слишком мало данных, мы вырезали такие классы, как, например, акведук, дом на дереве, дверь сарая.

В итоге после всех манипуляций мы получили базу Places2, которая содержит 314 классов и полтора миллиона изображений (в своей стандартной версии), в Challenge-версии около 7,5 миллионов изображений. На этих базах мы и строили обучение.
Кроме того, при просмотре оставшихся классов мы выяснили, что их слишком много для продакшна, они слишком подробны. И для этого мы применили механизм Scene mapping, когда некоторые классы объединяются в один общий. Например, всё, что связано с лесами, мы объединили в лес, всё, что связано с госпиталями — в госпиталь, с отелями — в отель.
Scene mapping мы используем только для тестирования и для конечного пользователя, потому что это удобнее. На обучении же мы используем все стандартные 314 классов. Полученную базу мы назвали Places Sift.
П Подходы, решения
Теперь рассмотрим подходы, которые мы использовали для решения этой задачи. Собственно, такие задачи связаны с классическим подходом — глубокими сверточными нейронными сетями.
На изображении внизу представлена одна из первых классических сетей, но она уже содержит основные строительные блоки, которые используются в современных сетях.
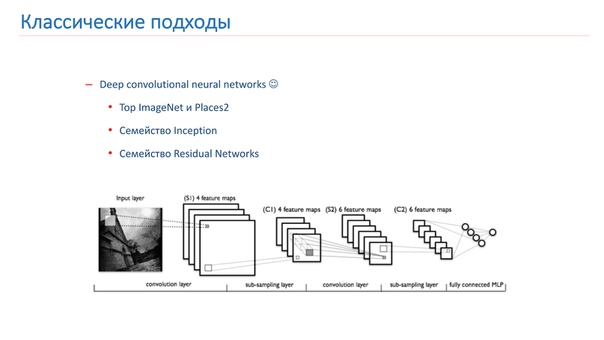
Это сверточные слои, это pulling-слои, полносвязные слои. Для того, чтобы определиться с архитектурой, мы проверяли топы соревнований ImageNet и Places2.
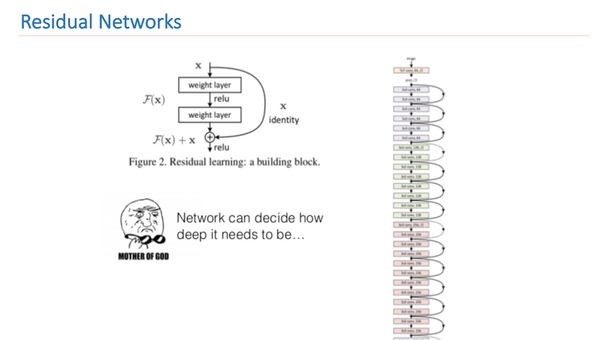
Можно сказать, что основные ведущие архитектуры можно разделить на два семейства: Inception и семейство ResNet (residual network). В ходе экспериментов мы выяснили, что для нашей задачи лучше подходит семейство ResNet, и дальнейший эксперимент исследования мы проводили именно над этим семейством.
ResNet — это глубокая сеть, которая состоит из большого количества residual-блоков. Это ее основной строительный блок, который состоит из нескольких слоев с весами и shortcut connection. В результате такой конструкции этот блок обучается, насколько входной сигнал x отличается от выхода f (x). В результате мы можем строить сети из таких блоков, а при обучении сеть может на последних слоях делать веса близкими к нулю.
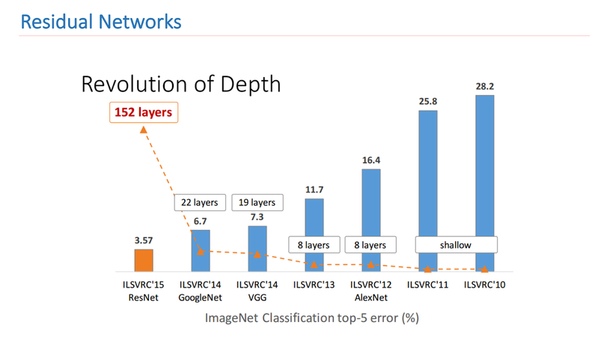
Таким образом можно сказать, что сеть сама решает, насколько ей нужно быть глубокой для решения некоторых поставленных задач. Благодаря такой архитектуры можно строить сети очень большой глубины с очень большим количеством слоев. Победитель ImageNet 2014 года содержал всего 22 слоя, ResNet превзошел этот результат и содержал уже 152 слоя.
Основные исследования ResNet заключаются в том, чтобы улучшить и правильно построить residual-блок. На картинке ниже представлен эмпирически и математически обоснованный вариант, который дает лучший результат. Такое построение блока позволяет бороться с одной из фундаментальных проблем глубокого обучения — затухающим градиентом.

Для обучения наших сетей мы использовали написанный на языке Lua фреймворк Torch из-за его гибкости и скорости работы, а для ResNet сделали форк реализации ResNet от Facebook. Для валидации качества работы сети мы использовали три теста.
Первый тест Places val – валидация множества Places Sift. Второй тест – Places Sift с использованием Scene Mapping, а третий – наиболее приближенный к боевой ситуации, Cloud-тест. Изображения сотрудников взяты из облака и размечены вручную. На картинке ниже есть два примера таких изображений.

Мы стали измерять и обучать сети, сравнивать их между собой. Первая – ResNet-152 benchmark, которая поставляется с Places2, вторая — ResNet-50, которую обучили на ImageNet и дообучили его на нашу базу, результат оказался уже лучше. Потом взяли ResNet-200, тоже обучили на ImageNet, и она показала в итоге лучший результат.
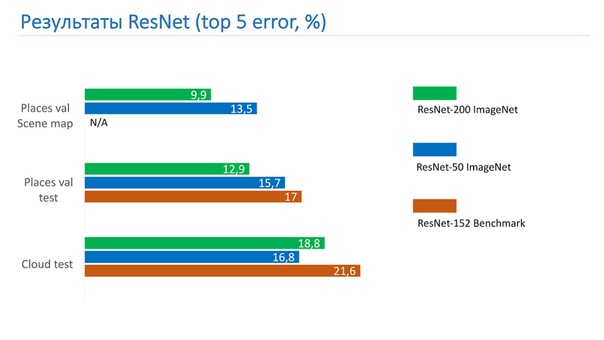
Ниже — примеры работы. Это ResNet-152 benchmark. Predicted — это те оригинальные лейблы, которые выдает сеть. Mapped lables — это лейблы, которые получились после Scene Mapping. Видно, что результат не очень хороший. То есть она вроде дает что-то по делу, но не очень хорошо.

Следующий пример – работа ResNet-200. Уже очень даже адекватно.

У Улучшение ResNet
Мы решили попробовать улучшить нашу сеть, и сначала пытались просто увеличить глубину сети, но после этого ее стало гораздо сложнее обучать. Это известная проблема, в прошлом году вышло несколько статей по этому поводу, которые говорят, что ResNet, по сути, представляет из себя ансамбль из большого количества обычных сетей различной глубины.

Res-блоки, которые находятся в конце сетки, вносят маленький вклад в формирование окончательного результата. Более перспективным представляется увеличивать не глубину сети, а ее ширину, то есть количество фильтров внутри Res-блока.
Эту идею и реализует появившийся в 2016 году Wide Residual Network. Мы в конечном итоге использовали WRN-50-2, которая является обычным ResNet-50 с увеличенным в два раза количеством фильтров во внутренней bottleneck 3x3 свертке.

Сеть показывает на ImageNet схожие результаты с ResNet-200, которую мы уже использовали, но, что немаловажно, она почти в два раза быстрее. Вот две реализации Residual-блока на Torch, ярким выделен тот параметр, который увеличивается в два раза. Речь идет о количестве фильтров во внутренней свертке.

Это замеры на тестах ResNet-200 ImageNet. Сначала мы взяли WRN-22-6, он показал результат хуже. Потом взяли WRN-50-2-ImageNet, обучили его, взяли WRN-50-2, обученный на ImageNet, и дообучили на Places2-challenge, он и показал лучший результат.
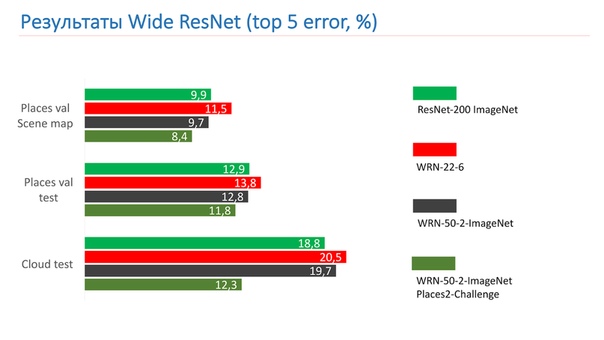
Вот пример работы WRN-50-2 — вполне адекватный результат на наших картинках, которые вы уже видели.

А это пример работы на боевых фотографиях, тоже успешно.

Есть, конечно, и не очень удачные работы. Мост Александра III в Париже не распознался как мост.

У Улучшение модели
Мы задумались, как можно улучшить эту модель. Семейство ResNet продолжает улучшаться, выходят новые статьи. В частности, в 2016 году вышла интересная статья PyramidNet, которая показала многообещающие результаты на CIFAR-10/100 и ImageNet.

Идея заключается в том, чтобы не резко увеличивать ширину Residual-блока, а делать это постепенно. Мы обучили несколько вариантов этой сети, но, к сожалению, она показала результаты чуть хуже, чем наша боевая модель.
Весной 2018 года вышла модель ResNext, тоже перспективная идея: разделить Residual-блок на несколько параллельных блоков меньшего размера, меньшей ширины. Это похоже на идею Inception, мы с ней тоже экспериментировали. Но, к сожалению, она показала результаты хуже, чем наша модель.

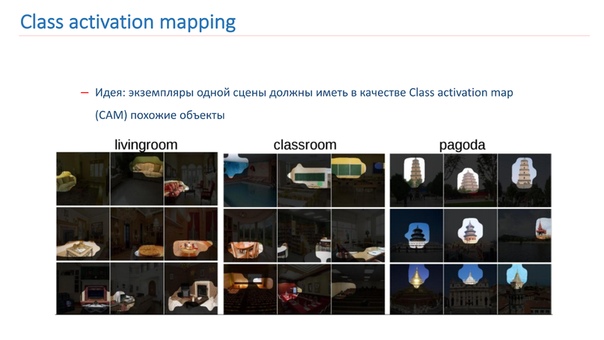
Также мы экспериментировали с различными «креативными» подходами по улучшению наших моделей. В частности, мы пытались использовать Class activation mapping (CAM), то есть это объекты, на которые смотрит сеть, когда она классифицирует изображение.

Наша идея заключалась в том, что экземпляры одной и той же сцены должны иметь в качестве класса CAM одни и те же или похожие объекты. Мы попробовали использовать этот подход. Сначала взяли две сети. Одна — обученная на ImageNet, вторая — наша модель, которую мы хотим улучшить.
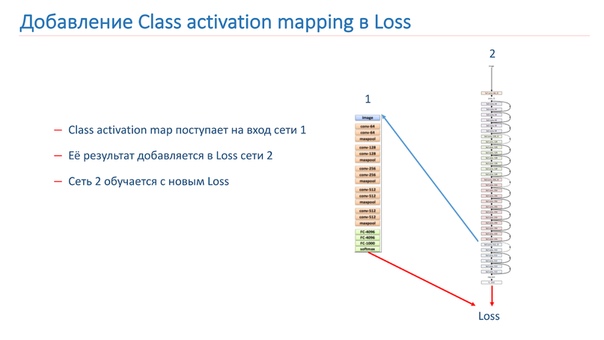
Мы берем изображение, прогоняем через сеть 2, добавляем CAM для слоя, потом подаем его на вход сети 1. Прогоняем через сеть 1, результаты добавляем в функцию потери сети 2, продолжаем это на новых функциях потери.
Второй вариант заключается в том, что мы прогоняем изображение через сеть 2, берем CAM, подаем на вход сети 1, а дальше на этих данных просто обучаем сеть 1 и используем ансамбль из результатов сети 1 и сети 2.
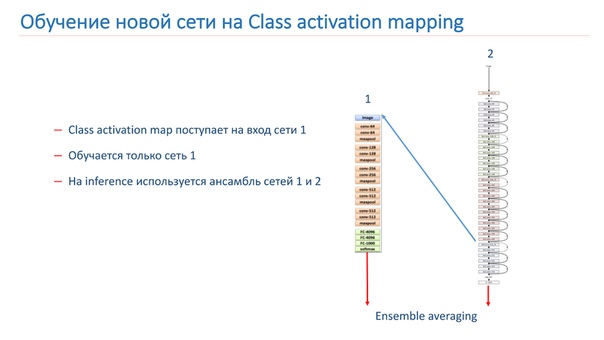
Мы дообучали нашу модель на WRN-50-2, в качестве сети 1 использовалась ResNet-50 ImageNet, но не получилось как-то существенно увеличить качество нашей модели.
Но продолжаем исследования по тому, как можно улучшить наши результаты: обучаем новые архитектуры CNN, в частности семейства ResNet. Мы пробуем экспериментировать и c CAM и рассматриваем различные подходы с более умными обработками патчей изображений – нам кажется, что этот подход достаточно перспективен.
Р Распознавание достопримечательностей

У нас есть неплохая модель по распознаванию сцен, но теперь нам хочется узнавать некоторые знаковые места, то есть достопримечательности. К тому же, пользователи часто фотографируют их или фотографируются на их фоне.
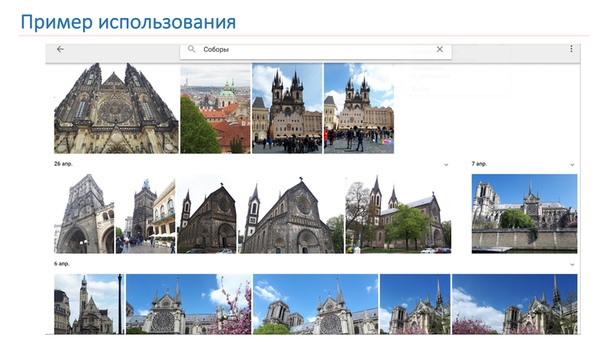
Нам хочется, чтобы в результате нам выдавались не просто соборы, как на изображении на слайде, а чтобы система сказала: «Здесь есть Нотр-Дам де Пари и соборы в Праге».
Когда мы решали эту задачу, мы столкнулись с некоторыми сложностями.
- Практически нет исследований на эту тему и нет готовых данных в открытом доступе.
- Малое количество «чистых» изображений в открытом доступе для каждой достопримечательности.
- Не совсем понятно, что из зданий достопримечательность. К примеру, дом с башнями на пл. Льва Толстого в Петербурге TripAdvisor не считает достопримечательностями, а Google считает.
Мы начали со сбора базы, составили список из 100 городов, а затем использовали Google Places API для скачивания JSON-данных по достопримечательностям из этих городов.
Данные фильтровали и парсили, а по полученному списку скачивали по 20 изображений с Google Search по каждой достопримечательности. Число 20 взято из эмпирических соображений. В итоге мы получили базу из 2827 достопримечательностей и около 56 тысяч изображений. Это та база, на которой мы обучали нашу модель. Для валидации нашей модели мы использовали два теста.
Cloud test — это изображения от наших сотрудников, размеченные вручную. Он содержит 200 картинок на 15 городов и 10 тысяч изображений не достопримечательностей. Второй — это Search test. Он был построен с помощью поиска Mail.ru, который содержит от 3 до 10 изображений на каждую достопримечательность, но, к сожалению, этот тест грязноват.
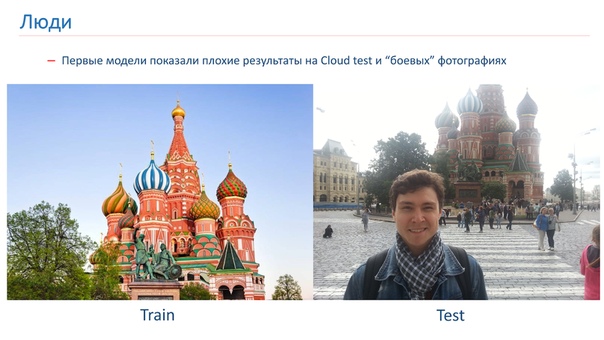
Мы обучили первые модели, но они показали плохие результаты на Cloud test на боевых фотографиях.
Вот пример изображения, на котором мы обучались, и пример боевой фотографии. Проблема в людях, в том, что они очень часто фотографируются на фоне достопримечательности. На те изображениях, которые мы доставали из поиска, людей не было.
Чтобы бороться с этим, мы добавили при обучении «людскую» аугментацию. То есть мы использовали стандартные подходы: случайные повороты, случайное вырезание части изображения и так далее. Но также в процессе обучения в некоторые изображения мы случайным образом добавляли людей.

Такой подход помог нам решить проблему с людьми и получить приемлемое качество работы модели.
F Fine tunning scene-модели
Как мы обучали модель: есть некоторая база обучения, но она достаточно маленькая. Но мы знаем, что достопримечательность – частный случай сцены. А у нас есть довольно хорошая Scene-модель. Мы решили дообучить ее на достопримечательности. Для этого добавили сверху сети несколько полносвязных и BN-слоев, обучали их и верхние три Residual-блока. Остальная часть сети была заморожена.

К тому же для обучения мы использования нестандартную функцию потери center loss. Center loss старается при обучении «растащить» представителей разных классов по разным кластерам, как показано на картинке.

При обучении мы добавили еще один класс «не достопримечательность». И к этому классу не применяли center loss. На такой смешанной функции потери проводилось обучение.
После того, как мы обучили сеть, мы отрезаем от нее последний классифицирующий слой, и, когда изображение проходит через сеть, оно превращается в числовой вектор, который называется embedding.

Для дальнейшего построения системы распознавания достопримечательности мы построили опорные вектора для каждого класса. Мы взяли каждый класс достопримечательности из множества и прогнали изображения через сеть. Получили embedding-и и взяли их средний вектор, который назвали опорным вектором класса.
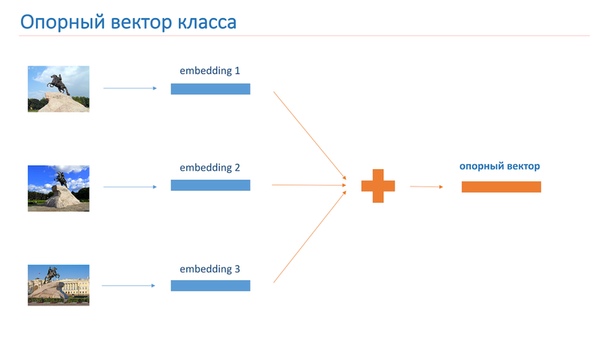
Для определения достопримечательностей на фото мы прогоняем входное изображение через сеть, и его embedding сравнивается с опорным вектором каждого класса. Если результат сравнения меньше порога, то считаем, что на изображении нет достопримечательности. Иначе берем класс с наибольшим значением сравнения.
Р Результаты на тестах
- На cloud test получили точность достопримечательности 0.616, не достопримечательности – 0,981
- На search test получили среднюю точность 0,669, среднюю полноту – 0,576.
На Search получили не очень большие результаты, но это объясняется тем, что первое достаточно «грязное», а у второго есть особенности – среди достопримечательностей есть разные ботанические сады, которые похожи во всех городах.
Была идея для распознавания сцен сначала натренировать сеть, которая будет определять маску сцены, то есть убирать с нее объекты на переднем фоне, а потом подавать в саму модель, которая распознает сцены изображения без этих участков, где фон загорожен. Но не очень понятно, что именно нужно убирать с переднего слоя, какая маска нужна.
Это будет довольно сложная и умная вещь, потому что не всем понятно, какие объекты принадлежат сцене, а какие лишние. К примеру, люди в ресторане могут быть нужны. Это нетривиальное решение, мы пытались сделать что-то похожее, но это не дало хороших результатов.
Вот пример работы на боевых фотографиях.
Примеры успешной работы:


А вот неудачная работа: достопримечательности не нашлось. Основная проблема нашей модели на данный момент не в том, что сеть путает между собой достопримечательности, а в том, что не находит их на фото.

В дальнейшем планируем собрать базу по еще большему количеству городов, найти новые методы обучения сети для этой задачи и определить возможности увеличения числа классов без переобучения сети.
В Выводы
Сегодня мы:
- Рассмотрели, какие есть наборы данных для Scene recognition;
- Увидели, что Wide Residual Network – лучшая модель;
- Обсудили дальнейшие возможности для увеличения качества этой модели;
- Посмотрели задачу распознавания достопримечательностей, какие возникают сложности;
- Описали алгоритм сбора базы и методы обучения модели для распознавания достопримечательностей.
Могу сказать, что задачи интересные, но малоизученные в сообществе. Ими интересно заниматься, потому что можно применить нестандартные подходы, которые не применяются в обычном распознавании объектов.
Телеграм: t.me/ainewsline
Источник: m.vk.com