Как Яндекс применил технологии искусственного интеллекта для перевода веб-страниц
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-07-03 09:53
Сегодня мы расскажем читателям Хабра о двух важных технологических изменениях в переводчике Яндекс.Браузера. Во-первых, перевод выделенных слов и фраз теперь использует гибридную модель, и мы напомним, чем этот подход отличается от применения исключительно нейросетей. Во-вторых, нейронные сети переводчика теперь учитывают структуру веб-страниц, об особенностях которой мы также расскажем под катом.
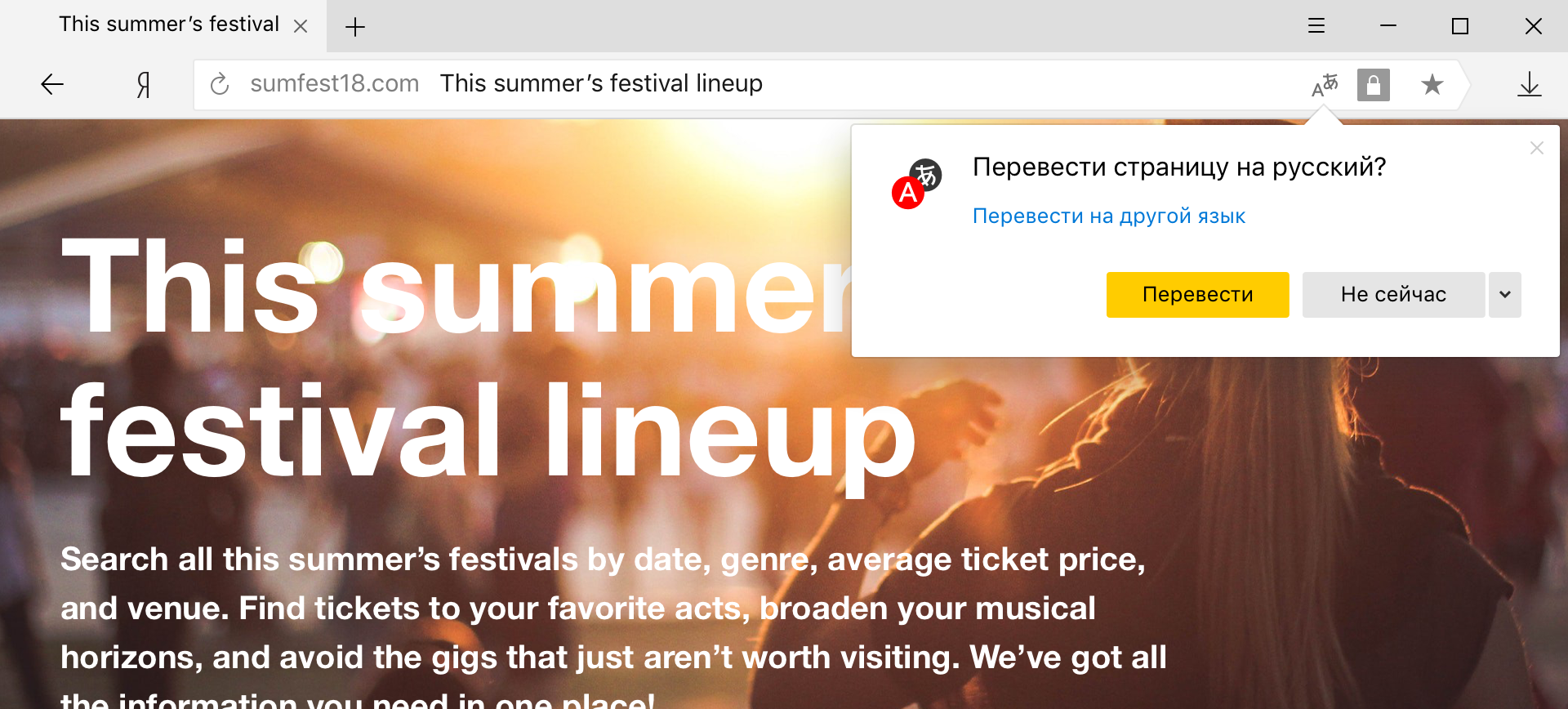
Гибридный переводчик слов и фраз
В основе первых систем машинного перевода лежали словари и правила (по сути, написанные вручную регулярки), которые и определяли качество перевода. Профессиональные лингвисты годами работали над тем, чтобы вывести всё более подробные ручные правила. Работа эта была столь трудоемкой, что серьезное внимание уделялось лишь наиболее популярным парам языков, но даже в рамках них машины справлялись плохо. Живой язык – очень сложная система, которая плохо подчиняется правилам. Ещё сложнее описать правилами соответствия двух языков.
Единственный способ машине постоянно адаптироваться к изменяющимся условиям – это учиться самостоятельно на большом количестве параллельных текстов (одинаковые по смыслу, но написаны на разных языках). В этом заключается статистический подход к машинному переводу. Компьютер сравнивает параллельные тексты и самостоятельно выявляет закономерности.
У статистического переводчика есть как достоинства, так и недостатки. С одной стороны, он хорошо запоминает редкие и сложные слова и фразы. Если они встречались в параллельных текстах, переводчик запомнит их и впредь будет переводить правильно. С другой стороны, результат перевода бывает похож на собранный пазл: общая картина вроде бы понятна, но если присмотреться, то видно, что она составлена из отдельных кусочков. Причина в том, что переводчик представляет отдельные слова в виде идентификаторов, которые никак не отражают взаимосвязи между ними. Это не соответствует тому, как люди воспринимают язык, когда слова определяются тем, как они используются, как соотносятся с другими словами и чем отличаются от них.
Решить эту проблему помогает нейронные сети. Векторное представление слов (word embedding), применяемое в нейронном машинном переводе, как правило, сопоставляет каждому слову вектор длиной в несколько сотен чисел. Векторы, в отличие от простых идентификаторов из статистического подхода, формируются при обучении нейронной сети и учитывают взаимосвязи между словами. Например, модель может распознать, что, поскольку «чай» и «кофе» часто появляются в сходных контекстах, оба эти слова должны быть возможны в контексте нового слова «разлив», с которым, допустим, в обучающих данных встретилось лишь одно из них.
Однако процесс обучения векторным представлениям явно более статистически требователен, чем механическое запоминание примеров. Кроме того, непонятно, что делать с теми редкими входными словами, которые недостаточно часто встречались, чтобы сеть могла построить для них приемлемое векторное представление. В этой ситуации логично совместить оба метода.
С прошлого года Яндекс.Переводчик использует гибридную модель. Когда Переводчик получает от пользователя текст, он отдаёт его на перевод обеим системам — и нейронной сети, и статистическому переводчику. Затем алгоритм, основанный на методе обучения CatBoost, оценивает, какой перевод лучше. При выставлении оценки учитываются десятки факторов — от длины предложения (короткие фразы лучше переводит статистическая модель) до синтаксиса. Перевод, признанный лучшим, показывается пользователю. Именно гибридная модель теперь используется в Яндекс.Браузере, когда пользователь выделяет для перевода конкретные слова и фразы на странице.
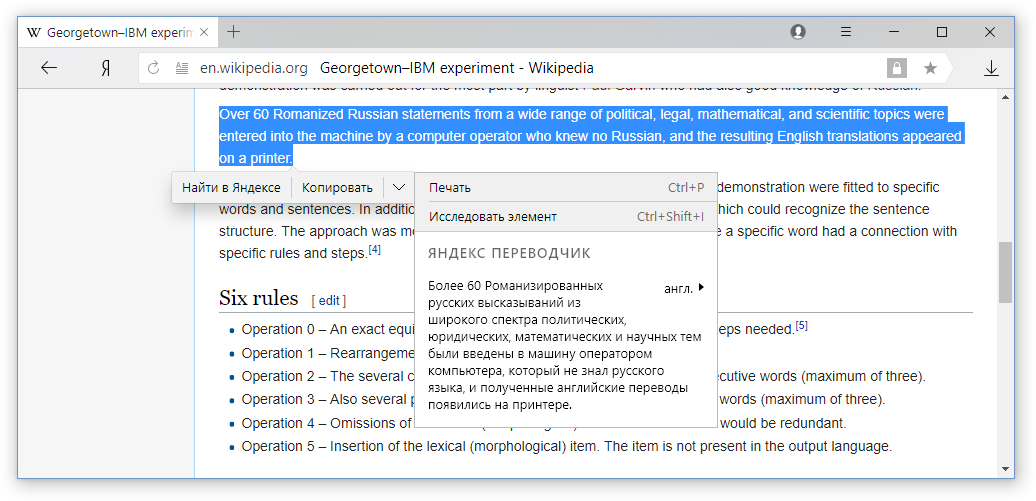
Нейросетевой переводчик веб-страниц
Со времён Джорджтаунского эксперимента и практически до наших дней все системы машинного перевода обучались переводить каждое предложение исходного текста по отдельности. В то время как веб-страница – это не просто набор предложений, а структурированный текст, в котором есть принципиально разные элементы. Рассмотрим основные элементы большинства страниц. Заголовок. Обычно яркий и крупный текст, который мы видим сразу при заходе на страницу. Заголовок часто содержит суть новости, поэтому важно перевести его правильно. Но сделать это сложно, потому что текста в заголовке мало и без понимания контекста можно допустить ошибку. В случае с английским языком всё ещё сложнее, потому что англоязычные заголовки часто содержат фразы с нетрадиционной грамматикой, инфинитивы или даже пропускают глаголы. Например, Game of Thrones prequel announced.
Навигация. Слова и фразы, которые помогают нам ориентироваться на сайте. Например, Home, Back и My account вряд ли стоит переводить как «Дом», «Спина» и «Мой счёт», если они расположены в меню сайта, а не в тексте публикации.
Основной текст. С ним всё проще, он мало отличается от обычных текстов и предложений, которые мы можем найти в книгах. Но даже здесь важно обеспечивать консистентность переводов, то есть добиваться того, чтобы в рамках одной веб-страницы одни и те же термины и понятия переводились одинаково.
Для качественного перевода веб-страниц недостаточно использовать нейросетевую или гибридную модель – необходимо учитывать ещё и структуру страниц. А для этого нам нужно было разобраться со множеством технологических трудностей.
Классификация сегментов текста. Для этого мы опять же используем CatBoost и факторы, основанные как на самом тексте, так и на HTML-разметке документов (тэг , размер текста, числа ссылок на единицу текста, ...). Факторы достаточно разнородные, поэтому именно CatBoost (основанный на градиентном бустинге) показывает лучшие результаты (точность классификации выше 95%). Но одной классификации сегментов недостаточно.
Перекос в данных. Традиционно алгоритмы Яндекс.Переводчика обучаются на текстах из интернета. Казалось бы, это идеальное решение для обучения переводчика веб-страниц (иными словами, сеть учится на текстах той же природы, что и у тех текстов, на которых мы собираемся её применять). Но как только мы научились отделять друг от друга различные сегменты, мы обнаружили интересную особенность. В среднем на сайтах контент занимает примерно 85% всего текста, а на заголовки и навигацию приходится всего по 7.5%. Вспомним также, что сами заголовки и элементы навигации по стилю и грамматике заметно отличаются от остального текста. Эти два фактора в совокупности приводят к проблеме перекоса данных. Нейронной сети выгоднее просто игнорировать особенности этих весьма бедно представленных в обучающей выборке сегментов. Сеть обучается хорошо переводить только основной текст, из-за чего страдает качество перевода заголовков и навигации. Чтобы нивелировать этот неприятный эффект, мы сделали две вещи: к каждой паре параллельных предложений мы приписали в качестве метаинформации один из трёх типов сегментов (контент, заголовок или навигация) и искусственно подняли концентрацию двух последних в тренировочном корпусе до 33% за счёт того, что стали чаще показывать обучающейся нейросети подобные примеры.
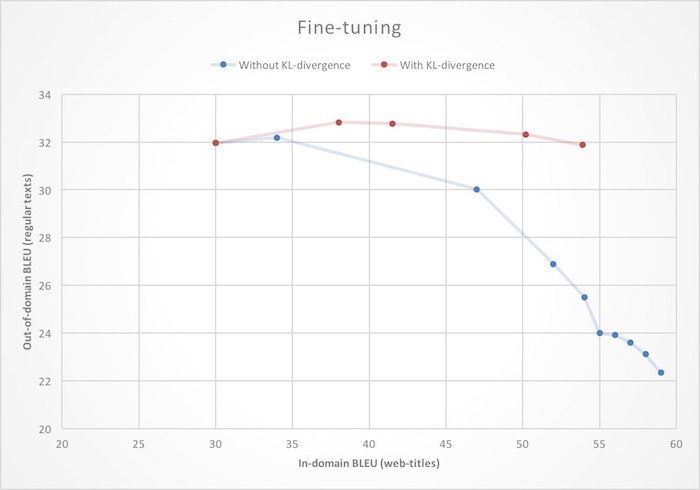
Multi-task learning. Поскольку теперь мы умеем разделять тексты на веб-страницах на три класса сегментов, может показаться естественной идеей обучать три отдельные модели, каждая из которых будет справляться с переводом своего типа текстов – заголовков, навигации или контента. Это действительно работает неплохо, однако ещё лучше работает схема, при которой мы обучаем одну нейросеть переводить сразу все типы текстов. Ключ к пониманию лежит в идее mutli-task learning (MTL): если между несколькими задачами машинного обучения имеется внутренняя связь, то модель, которая учится решать эти задачи одновременно, может научиться решать каждую из задач лучше, чем узкопрофильная специализированная модель! Fine-tuning. У нас уже был весьма неплохой машинный перевод, поэтому было бы неразумно обучать новый переводчик для Яндекс.Браузера с нуля. Логичнее взять базовую систему для перевода обычных текстов и дообучить её для работы с веб-страницами. В контексте нейросетей это часто называют термином fine-tuning. Но если подойти к этой задаче в лоб, т.е. просто инициализировать веса нейронной сети значениями из готовой модели и начать учить на новых данных, то можно столкнуться с эффектом доменного сдвига: по мере обучения качество перевода веб-страниц (in-domain) будет расти, но качество перевода обычных (out-of-domain) текстов будет падать. Чтобы избавиться от этой неприятной особенности, при дообучении мы накладываем на нейросеть дополнительное ограничение, запрещая ей слишком сильно менять веса по сравнению с начальным состоянием.
Математически это выражается добавлением слагаемого к функции потерь (loss function), представляющего из себя расстояние Кульбака—Лейблера (KL-divergence) между распределениями вероятностей порождения очередного слова, выдаваемыми исходной и дообучаемой сетями. Как можно видеть на иллюстрации, это приводит к тому, что рост качества перевода веб-страниц больше не приводит к деградации перевода обычного текста.
- Подчёркнутый фрагмент в переводе должен соответствовать именно подчёркнутому фрагменту в исходном тексте.
- Согласованность перевода на границах подчёркнутого фрагмента не должна нарушаться.
Для того чтобы обеспечить такое поведение, мы сначала переводим текст как обычно, а затем с помощью статистических моделей пословного выравнивания определяем соответствия между фрагментами исходного и переведённого текстов. Это помогает понять, что именно нужно подчеркнуть (выделить курсивом, оформить как гиперссылку, ...). Intersection observer. Мощные нейросетевые модели перевода, которые мы натренировали, требуют заметно больше вычислительных ресурсов на наших серверах (как CPU, так и GPU), чем статистические модели предыдущих поколений. При этом пользователи далеко не всегда дочитывают страницы до конца, поэтому отправка всего текста веб-страниц в облако выглядит излишней. Чтобы сэкономить серверные ресурсы и пользовательский трафик мы научили Переводчик использовать Intersection Observer API, чтобы отправлять на перевод только тот текст, который отображается на экране. За счёт этого нам удалось снизить расход трафика на перевод более чем в 3 раза. Несколько слов об итогах внедрения нейросетевого переводчика с учётом структуры веб-страниц в Яндекс.Браузер. Для оценки качества переводов мы используем метрику BLEU*, которая сравнивает переводы, выполненные машиной и профессиональным переводчиком, и оценивает качество машинного перевода по шкале от 0 до 100%. Чем ближе машинный перевод к человеческому, тем выше процент. Обычно пользователи замечают изменение качества при росте метрики BLEU хотя бы на 3%. Новый переводчик Яндекс.Браузера показал рост почти на 18%.

Телеграм: t.me/ainewsline
Источник: habr.com