Как работает сверточная нейронная сеть: архитектура, примеры, особенности
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-07-25 17:27

Понимание устройства сверточной нейронной сети, особенно впервые, может быть затруднено из-за таких терминов, как ядра (kernels), фильтры (filters), каналы (channels) и множества других нагромождений. Сверточная нейронная сеть основана на удивительно мощной и универсальной математической операции. В этой статье мы шаг за шагом рассмотрим механизм их работы на примере стандартной полностью рабочей сети (network), изучим то, как они строят качественные визуальные иерархии (visual hierarchy), что делает их сильным инструментом для выделения образов (feature extraction) в изображениях.
Двумерная сверточная нейронная сеть
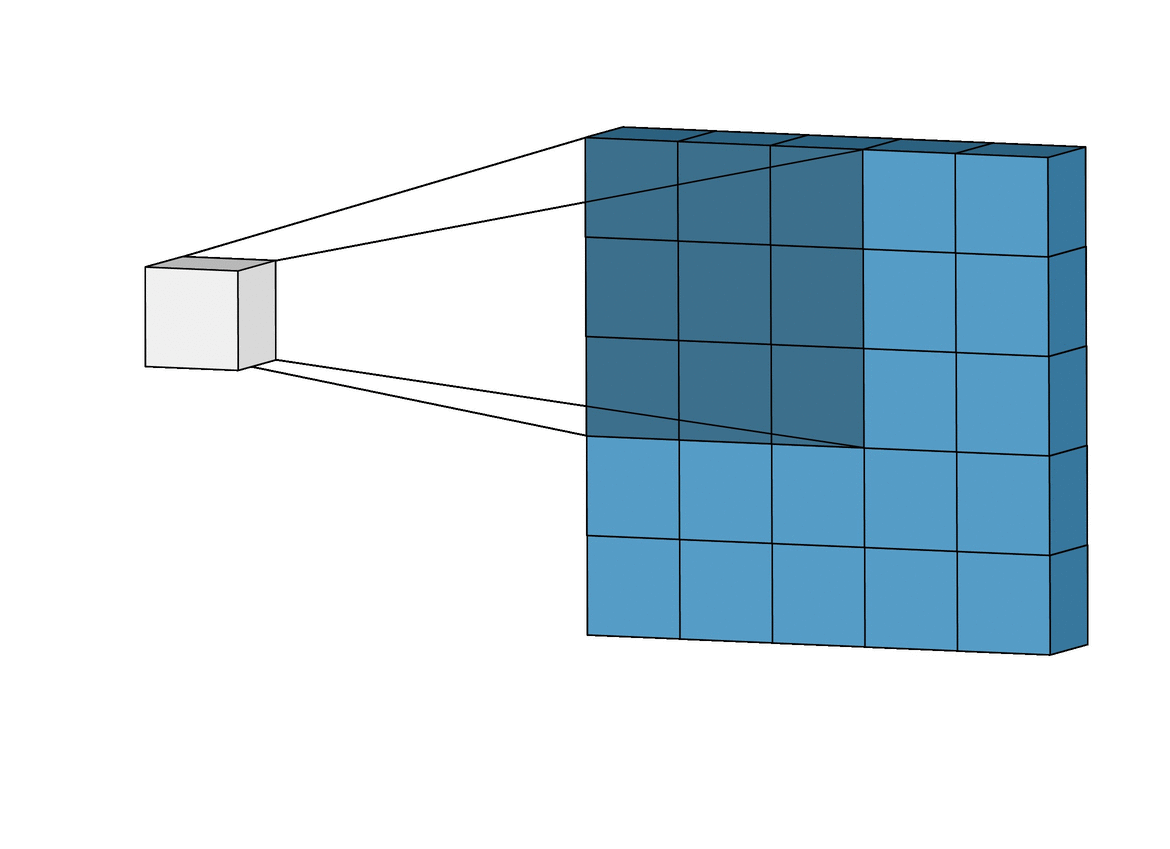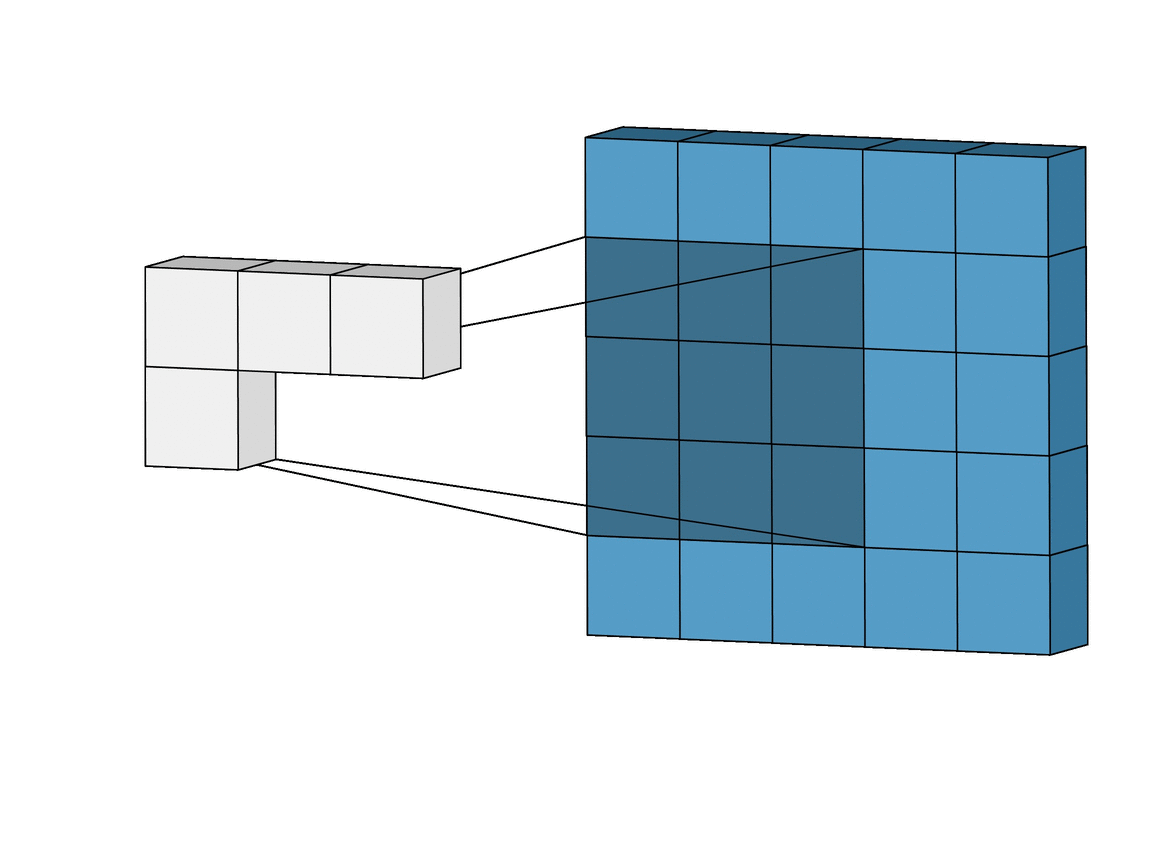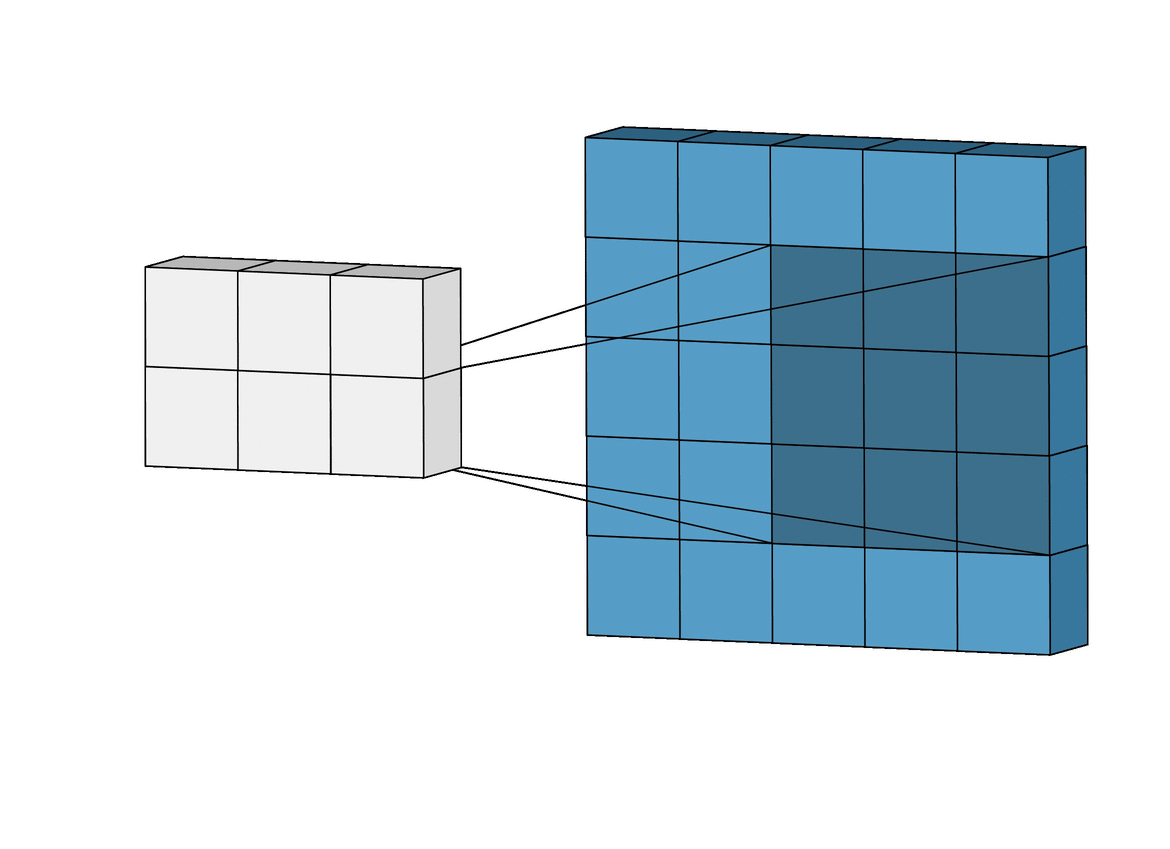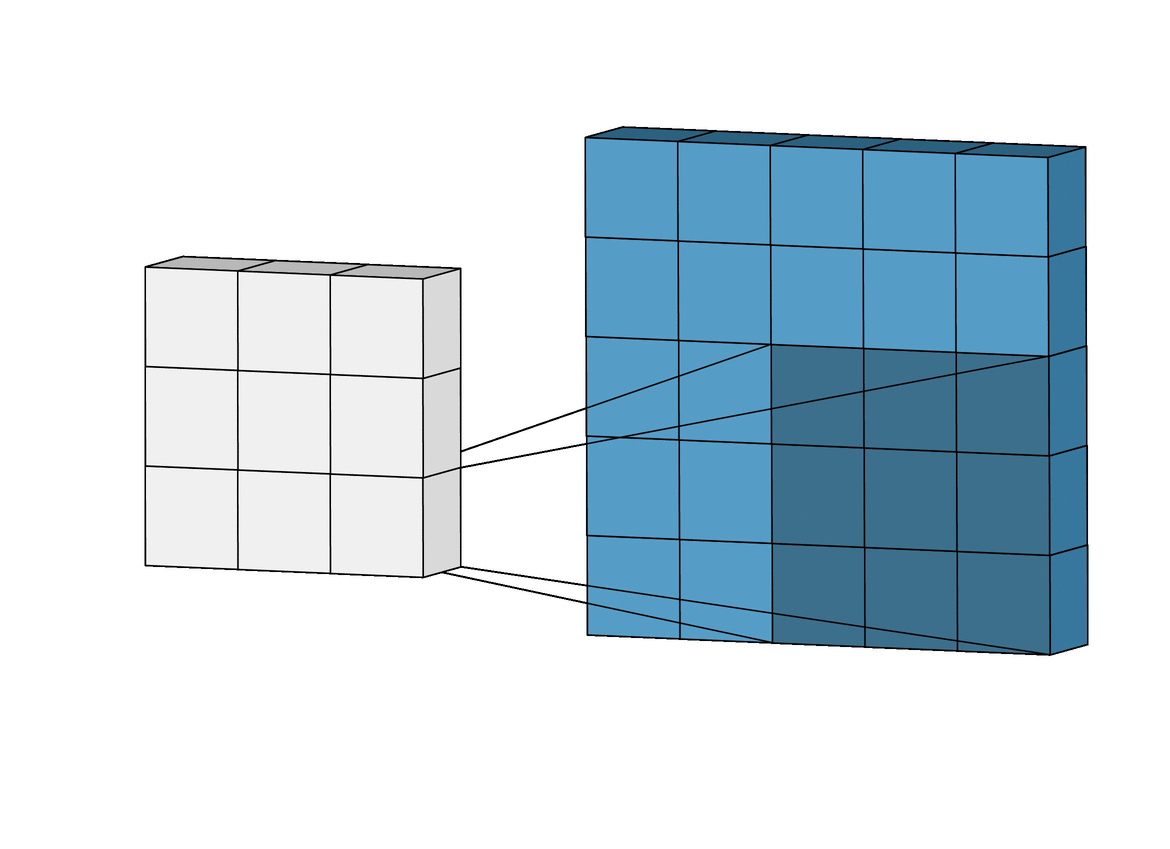
Двумерная свертка (2D convolution) — это по сути довольно простая операция: начинаем с ядра, представляющего из себя весовую матрицу (weight matrix). Это ядро “скользит” над двумерным изображением, поэлементно выполняя операцию умножения с той частью входных данных, над которой оно сейчас находится, и затем суммирует все полученные значения в один выходной пиксель.
Ядро повторяет эту процедуру с каждой локацией, над которой оно “скользит”, преобразуя двумерную матрицу образов в другую все еще двумерную матрицу образов. Образы на выходе являются, по существу, взвешенными суммами (где веса являются значениями самого ядра) образов на входе, расположенных примерно в том же месте что и выходной пиксель на входном слое.

Независимо от того, попадает ли входной образ в “примерно то же место”, он определяется в зависимости от того, находится он в зоне ядра, создающего выходные данные, или нет. Это значит, что размер ядра сверточной нейронной сети определяет как много (или как мало) образов будут объединены для получения нового образа на выходе.
В примере, приведенном выше, мы имеем 5*5=25 образов на входе и 3*3=9 образов на выходе. Для стандартного слоя (standard fully connected layer) мы бы имели весовую матрицу 25*9 = 225 параметров, а каждый выходной образ являлся бы взвешенной суммой всех образов на входе. Свертка позволяет произвести такую операцию с всего 9-ю параметрами, ведь каждый образ на выходе получается анализом не каждого образа на входе, а только одного входного образа, находящегося в “примерно том же месте”. Обратите на это внимание, так как это будет иметь важное значение для дальнейшего обсуждения.
Часто используемые техники
Перед тем как мы двинемся дальше, безусловно стоит взглянуть на две техники, которые часто применяются в сверточных нейронных сетях: Padding и Strides.
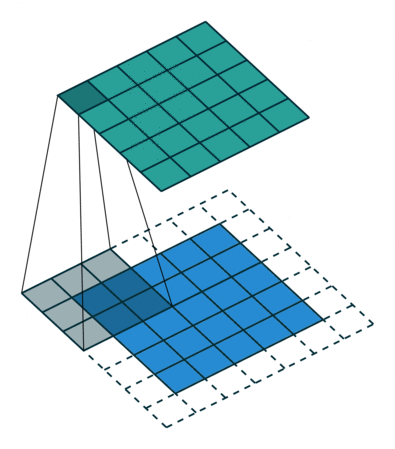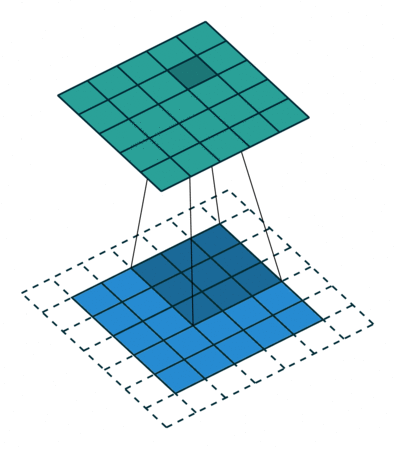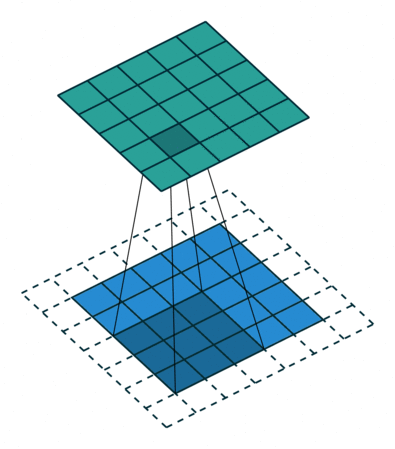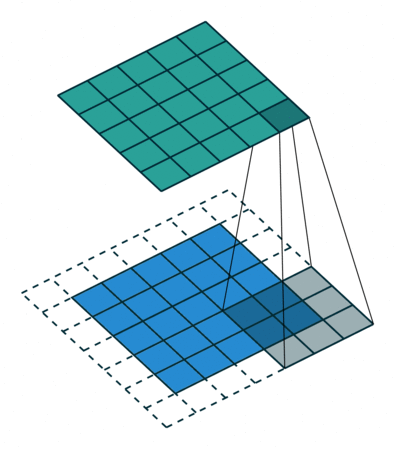
Padding. Если вы наблюдаете анимацию, обратите внимание на то, что в процессе скольжения края по существу обрезаются, преобразуя матрицу образов размером 5*5 в матрицу 3*3. Крайние пиксели никогда не оказываются в центре ядра, потому что тогда ядру не над чем будет скользить за краем. Это совсем не идеальный вариант, так как мы хотим чтобы чаще размер на выходе равнялся входному.
Padding делает кое-что довольно умное, чтобы решить эту проблему: добавляет к краям поддельные (fake) пиксели (обычно нулевого значения, вследствии этого к ним применяется термин “нулевое дополнение” — “zero padding”). Таким образом, ядро при проскальзывании позволяет неподдельным пикселям оказываться в своем центре, а затем распространяется на поддельные пиксели за пределами края, создавая выходную матрицу того же размера что и входная.
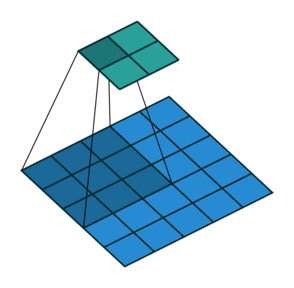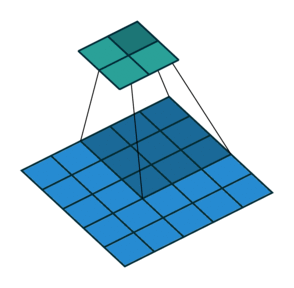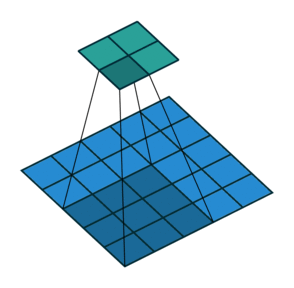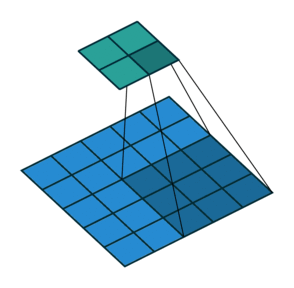
Striding. Часто бывает, что при работе со сверточным слоем, нужно получить выходные данные меньшего размера, чем входные. Это обычно необходимо в сверточных нейронных сетях, где размер пространственных размеров уменьшается при увеличении количества каналов. Один из способов достижения этого — использование субдискритизирующих слоев (pooling layer) (например, принимать среднее/максимальное значение каждой ветки размером 2*2, чтобы уменьшить все пространственные размеры в два раза). Еще один способ добиться этого — использовать stride (шаг).
Идея stride заключается в том, чтобы пропустить некоторые области над которыми скользит ядро. Шаг 1 означает, что берутся пролеты через пиксель, то есть по факту каждый пролет является стандартной сверткой. Шаг 2 означает, что пролеты совершаются через каждые два пикселя, пропуская все другие пролеты в процессе и уменьшая их количество примерно в 2 раза, шаг 3 означает пропуск 3-х пикселей, сокращая количество в 3 раза и т.д.
Более современные сети, такие как архитектуры ResNet, полностью отказываются от субдискритизирующих слоев во внутренних слоях, в пользу чередующихся сверток, когда необходимо уменьшить размер на выходе.
Многоканальная версия сверточной нейронной сети
Конечно, приведенные выше диаграммы касаются только случая, когда изображение имеет один входной канал. На практике большинство входных изображений имеют 3 канала, и чем глубже вы в сети, тем больше это число. Довольно просто думать о каналах, в общем, как о “взгляде” на изображение в целом, придавая большее значение одним аспектам и меньшее другим.

Вот где ключевые различия между терминами становятся нужными: тогда как в случае с 1 каналом, где термины фильтр и ядро взаимозаменяемы, в общем случае они разные.
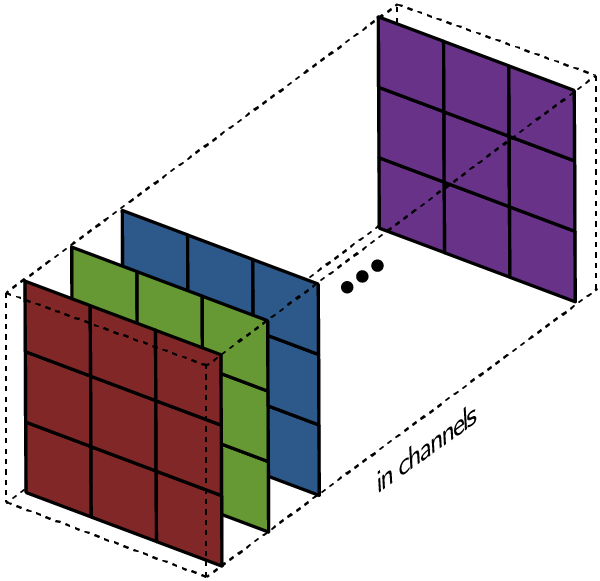
Каждый фильтр на самом деле представляет собой коллекцию ядер, причем для каждого отдельного входного канала для этого слоя есть одно ядро, где каждое ядро уникально.
Каждый фильтр в сверточном слое создает только один выходной канал и делают они это так: каждое из ядер фильтра «скользит» по их соответствующим входным каналам, создавая обработанную версию каждого из них. Некоторые ядра могут иметь больший вес, чем другие, для того чтобы уделять больше внимания определенным входным каналам (например, фильтр может иметь красный канал ядра с большим весом, чем другие каналы, и, следовательно, больше реагировать на различия в образах из красного канала).
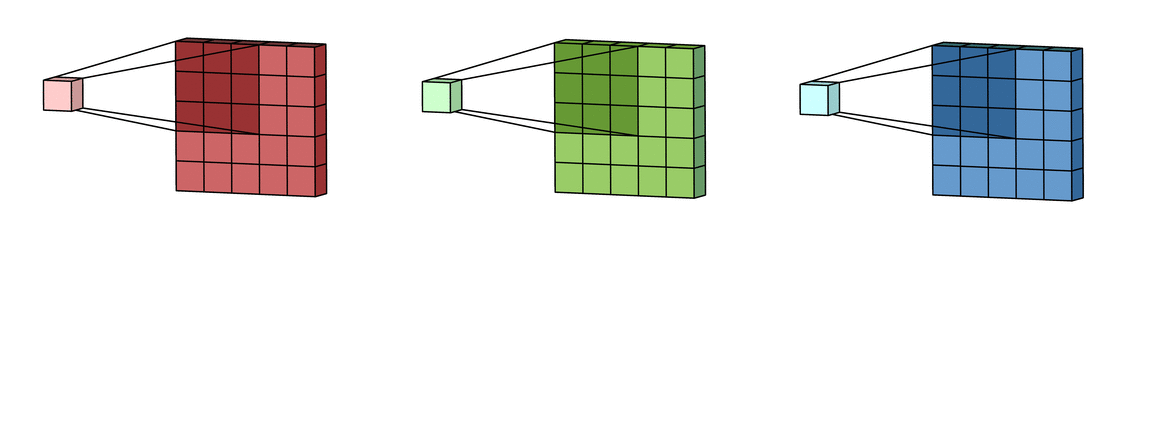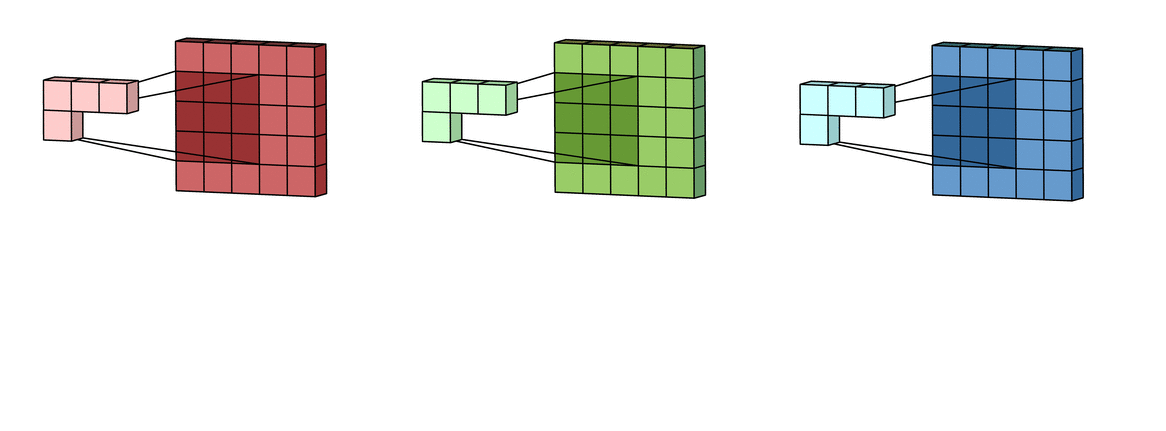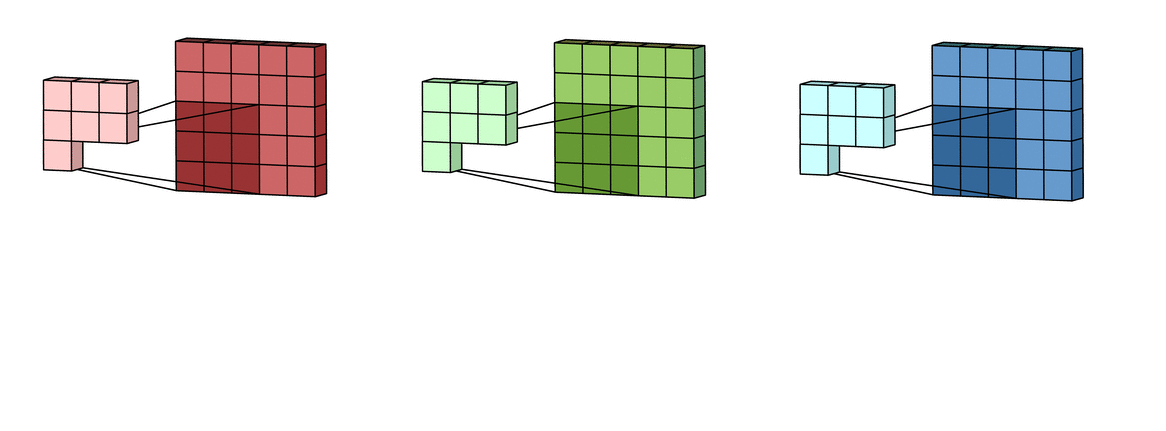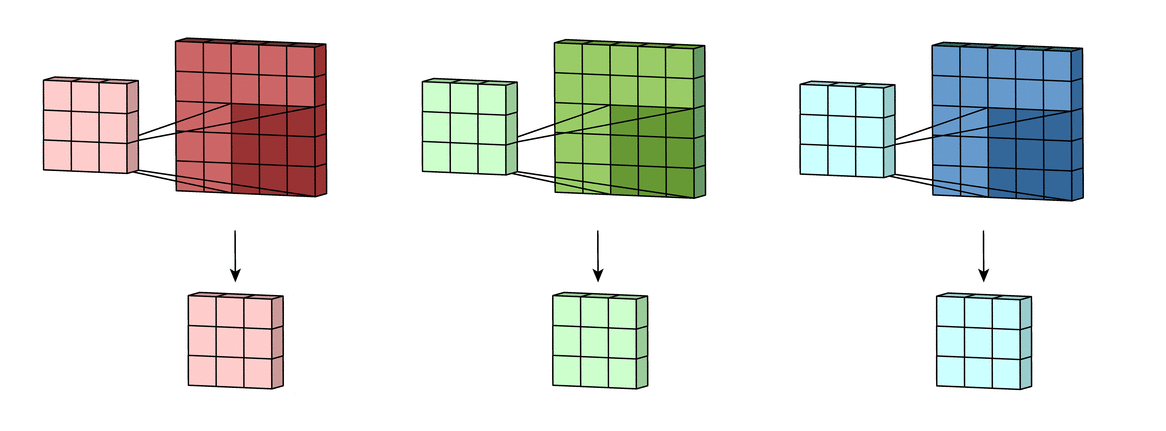
Затем каждая из обработанных в канале версий суммируется вместе для формирования одного канала. Ядра каждого фильтра генерируют одну версию каждого канала, а фильтр в целом создает один общий выходной канал:
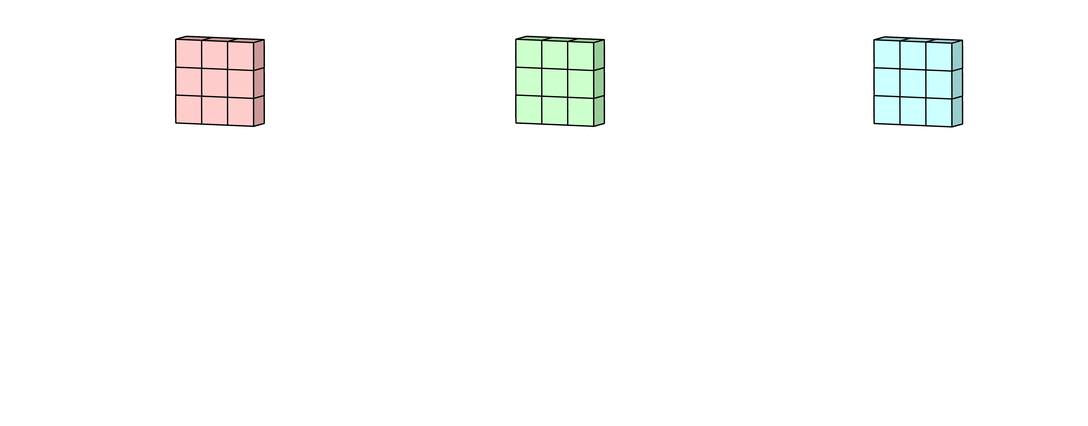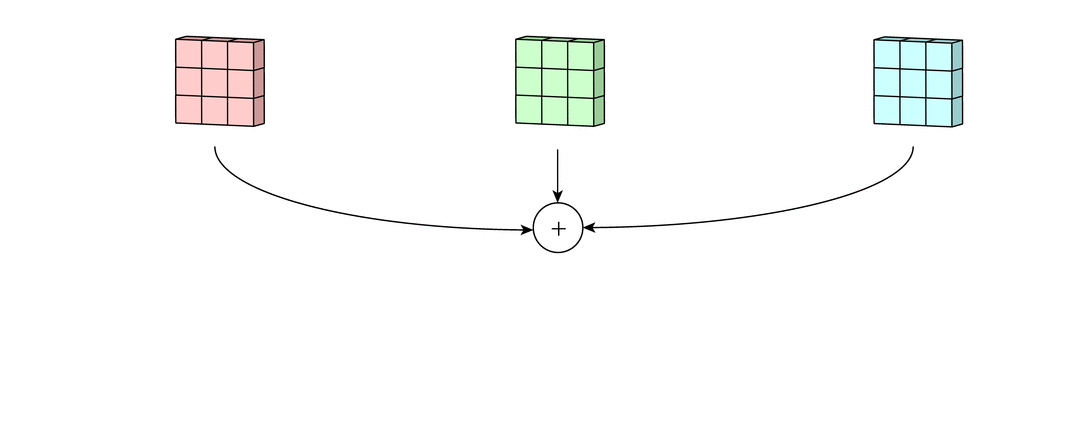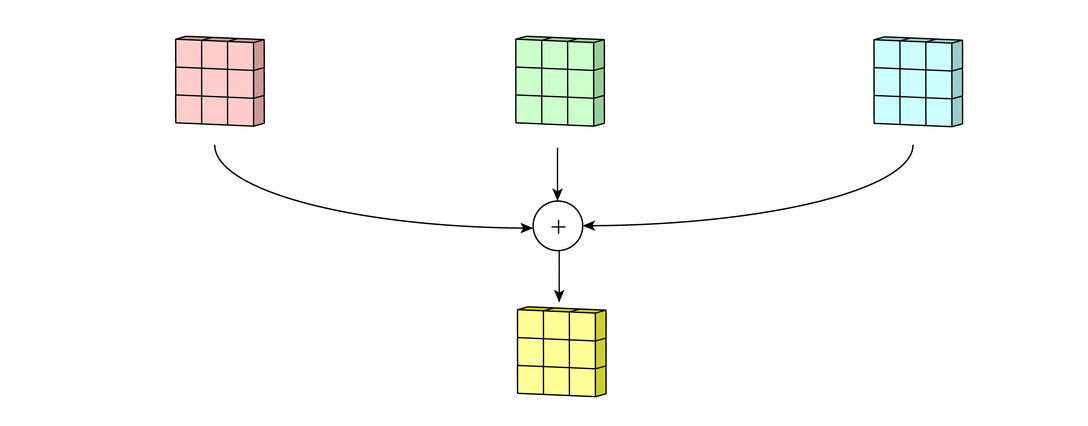
Наконец, есть срок смещение. Принцип работы смещения состоит в том, что каждый выходной файл имеет свой срок смещения. Смещение добавляется к выходному каналу для создания конечного выходного канала:
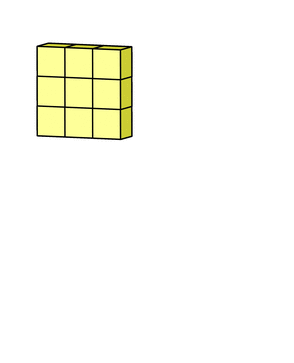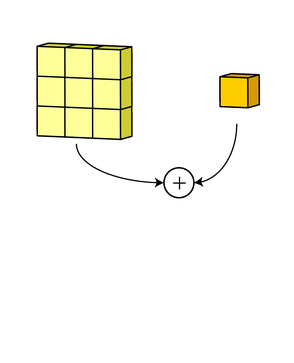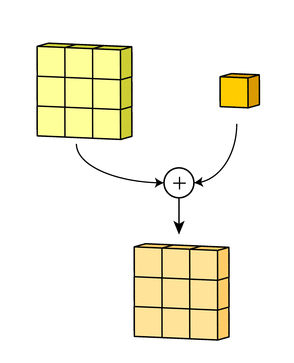
Результат для любого количества фильтров идентичен: каждый фильтр обрабатывает вход со своим отличающимся от других набором ядер и скалярным смещением по описанному выше процессу, создавая один выходной канал. Затем они объединяются вместе для получения общего выхода, причем количество выходных каналов равно числу фильтров. При этом обычно применяется нелинейность перед передачей входа другому слою свертки, который затем повторяет этот процесс.
Параметры в сверточной нейронной сети
Свертка — это по-прежнему линейное преобразование
Даже с уже описанной механикой работы сверточного слоя, все еще сложно связать это с нейронной сетью прямого распространения (feed-forward network), и это все еще не объясняет, почему свертки масштабируются и работают намного лучше с изображениями.
Предположим, что у нас есть вход 4*4, и мы хотим преобразовать его в сетку 2*2. Если бы мы использовали feed-forward network, мы бы переделали вход 4*4 в вектор длиной 16 и передали его через плотно связанный слой с 16 входами и 4 выходами. Можно было бы визуализировать весовую матрицу W для слоя по типу:
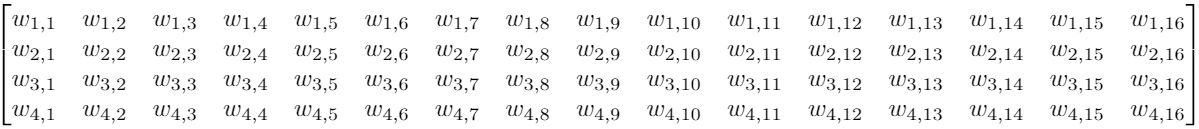
И хотя сверточные операции с ядрами могут вначале показаться немного странными, это по-прежнему линейные преобразования с эквивалентной матрицей перехода.
Если бы мы использовали ядро K размера 3 на видоизмененным входом размера 4*4, чтобы получить выход 2*2, эквивалентная матрица перехода будет выглядеть так:
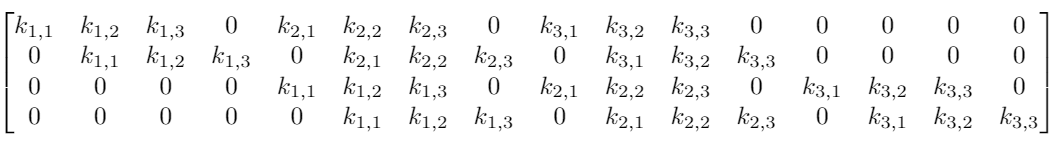
Свертка, в целом, все еще является линейным преобразованием, но в то же время она также представляет собой совершенно иной вид преобразования. Для матрицы с 64 элементами существует всего 9 параметров, которые повторно используются несколько раз. Каждый выходной узел получает только определенное количество входов (те, что находятся внутри ядра). Нет никакого взаимодействия с другими входами, так как вес для них равен 0.
Полезно представлять сверточные операции как hard prior для весовых матриц. В данном контексте, под prior я подразумеваю предопределенные сетевые параметры. Например, когда вы используете предварительно обработанную модель для классификации изображений, вы используете предварительные параметры сети как prior, как экстрактор образов для вашего окончательного плотно связанного слоя.
В этом плане, существует прямая причина тому, почему оба они настолько эффективны (по сравнению с их альтернативами). Transfer learning эффективнее на порядок по сравнению со случайной инициализацией, потому что вам только нужно оптимизировать параметры конечного полностью связанного слоя, а это означает, что вы можете иметь фантастическую производительность всего лишь с несколькими десятками изображений в классе.
Вам не нужно оптимизировать все 64 параметра, потому большинство из них установлено на ноль (и они останутся такими), а остальные мы преобразуем в общие параметры и в результате получим только 9 параметров для оптимизации. Эта эффективность имеет значение, потому что, когда вы переходите от 784 входов MNIST к реальным изображениям 224*224*3, это более 150 000 входов. Плотный слой, пытающийся вдвое уменьшить вход до 75 000 входных значений, по-прежнему потребует более 10 миллиардов параметров. Для сравнения, в целом ResNet-50 имеет около 25 миллионов параметров.
Таким образом, фиксирование некоторых параметров к нулю и их связывание повышает эффективность, но в отличие от случая с transfer learning, где мы знаем, что prior работает грамотно, потому что он работает с большим общим набором изображений, откуда мы знаем, что это будет работать хоть сколько-то хорошо?
Ответ заключается в комбинациях образов, изучаемых параметрами за счет prior.
Локальные особенности
Итак:
- Ядра объединяют пиксели только из небольшой локальной области для формирования выхода. То есть выходные образы видят только входные образы из небольшой локальной области;
- Ядро применяется глобально по всему изображению для создания матрицы выходных значений.
Таким образом, с backpropagation (метод обратного распространения ошибки), идущим во всех направлениях от узлов классификации сети, ядра имеют интересную задачу изучения весов для создания образов только из локального набора входов. Кроме того, поскольку само ядро применяется по всему изображению, образы, которые изучает ядро, должны быть достаточно общими, чтобы поступать из любой части изображения.
Если это были какие-то другие данные, например, данные о установках приложений по категориям, то это стало бы катастрофой, потому что количество столбцов установки приложений и типов приложений рядом друг с другом не означает, что у них есть «локальные общие образы», общие с датами установки приложений и временем использования. Конечно, у четырех могут быть основные образы более высокого уровня (например, какие приложения люди хотят больше всего), которые могут быть найдены, но это не дает нам никаких оснований полагать, что параметры для первых двух точно такие же, как параметры для последних двух. Эти четверо могли быть в любом (последовательном) порядке и по-прежнему быть подходящими!
Пиксели, однако, всегда отображаются в последовательном порядке, а соседние пиксели влияют на пиксель рядом, например, если все соседние пиксели красные, довольно вероятно, что пиксель рядом также краснеет. Если есть отклонения, это интересная аномалия, которая может быть преобразована в образ, и все это можно обнаружить при сравнении пикселя со своими соседями, с другими пикселями в своей местности.
Эта идея — то, на чем были основаны более ранние методы извлечения образов компьютерным зрением. Например, для обнаружения граней можно использовать фильтр обнаружения граней Sobel — ядро с фиксированными параметрами, действующее точно так же, как стандартная одноканальная свертка:

Для сетки, не содержащей граней (например,неба на заднем фоне), большинство пикселей имеют одинаковое значение, поэтому общий вывод ядра в этой точке равен 0. Для сетки с вертикальными гранями существует разница между пикселями слева и справа от грани, и ядро вычисляет эту ненулевую разницу, выявляя ребра. Ядро за раз работает только с сетками 3*3, обнаруживая аномалии в определенных местах, но применения по всему изображению достаточно для обнаружения определенного образа в любом месте на изображении!
Но могут ли полезные ядра быть изучены? Для ранних слоев, работающих с необработанными пикселями, мы могли бы ожидать детекторы образов низкого уровня, такие как ребра, линии и т.д.
Существует целая отрасль исследований глубокого обучения, ориентированная на то, чтобы сделать модели нейронных сетей интерпретируемыми. Один из самых мощных инструментов для этого — визуализация образов с помощью оптимизации. Идея в корне проста: оптимизируйте изображение (обычно инициализированное случайным шумом), чтобы активировать фильтр как можно сильнее. Такой способ интуитивно понятен: если оптимизированное изображение полностью заполнено гранями, то это убедительное доказательство того, что фильтр активирован и занят поиском. Используя это, мы можем заглянуть в изученные фильтры, и результаты будут ошеломляющими:


Важно обратить внимание на то, что конвертированные изображения остаются изображениями. Выход, получаемый от небольшой сетки пикселей в верхнем левом углу, будет тоже расположен в верхнем левом углу. Таким образом, можно применять один слой поверх другого (как два слева на картинке) для извлечения более грубоких образов, которые мы визуализируем.
Тем не менее, как бы глубоки ни заходили наши детекторы образов, без каких-либо дальнейших изменений они все равно будут работать на очень маленьких участках изображения. Независимо от того, насколько глубоки ваши детекторы, вы не сможете обнаружить лица в сетке 3*3. И вот здесь возникает идея рецептивного поля (receptive field).
Рецептивные поля
Существенной особенностью дизайна CNN архитектур является то, что размеры ввода становятся все меньше и меньше от начала до конца сети, а количество каналов становится больше. Это, как упоминалось ранее, часто делается с помощью strides или pooling layers. Местность определяет, какие входные данные из предыдущего уровня будут на выходе следующего. Receptive field определяет, какую область исходного входа получает выход.
Идея strided convolution состоит в том, что мы обрабатываем пролеты только на фиксированном расстоянии друг от друга и пропускаем те что посередине. С другой точки зрения, мы оставляем только выходы на определенном расстоянии друг от друга, удаляя остальные.
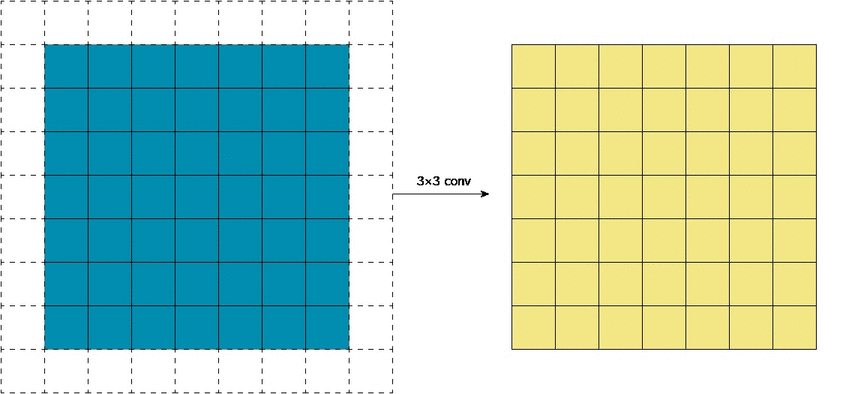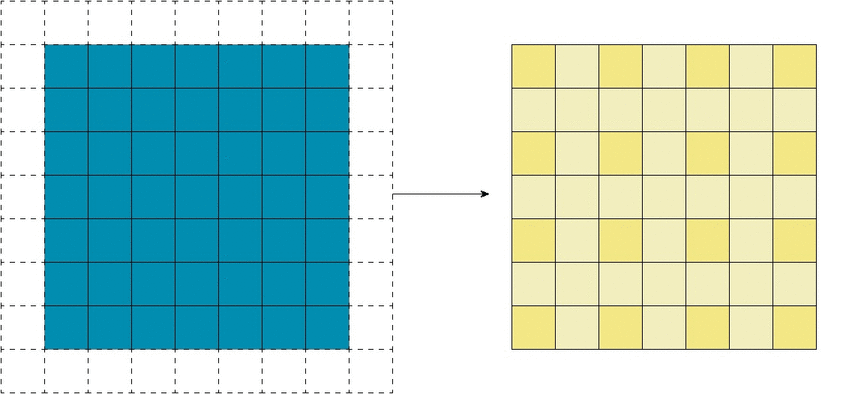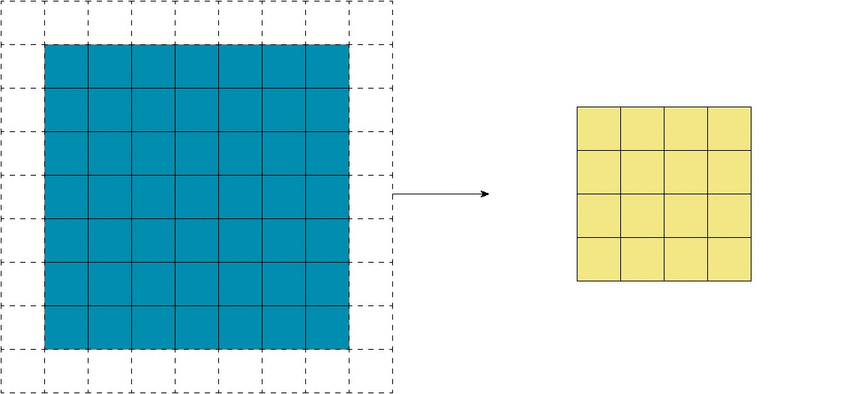
Затем мы применяем нелинейность к выходном данным, затем накладываем еще один новый слой свертки сверху. Здесь все становится интересным. Даже если бы мы применили ядро того же размера (3*3), имеющее одну и ту же локальную область, к выходу strided convolution, ядро имело бы более эффективное receptive field.
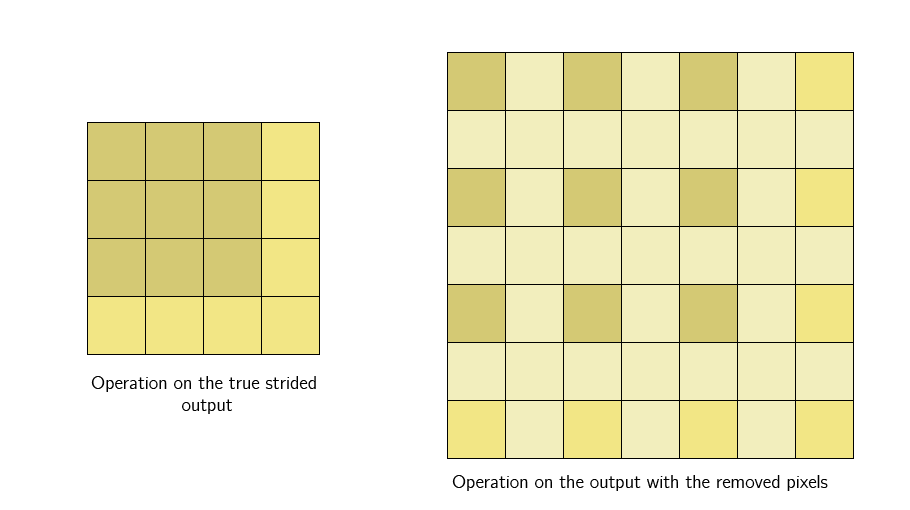
Это связано с тем, что выход strided слоя по-прежнему представляет из себя одно и то же изображение. Это не столько обрезка, сколько изменение размера, только теперь каждый отдельный пиксель в выходе является «представителем» большей площади (другие пиксели которой были отброшены) из того же местоположения исходного ввода. Поэтому, когда ядро следующего слоя применяется к выходу, оно работает с пикселями, собранными из большей области.
Примечание: если вы знакомы с расширенными свертками, обратите внимание, что вышеупомянутое ею не является. Оба являются методами увеличения receptive field, но расширенные свертки представляют собой один слой, тогда как у нас все происходит на регулярной свертке совместно с пошаговой сверткой и нелинейностью между.

Такое расширение восприимчивого поля позволяет слоям свертки сочетать образы низкого уровня (линии, ребра) с образами более высокого уровня (кривые, текстуры), как мы видим в слое mixed3a.
Вслед за слоем pooling/strided сеть продолжает создавать детекторы для еще более высокоуровневых образов (частей, шаблонов), как мы видим на mixed4a.
Повторное уменьшение размера изображения к 5-му блоку сверток дает размеры ввода всего 7*7, по сравнению с входами 224*224. В этот момент каждый отдельный пиксель представляет собой огромную сетку размером 32*32 пикселя.
Если на более ранних слоях активация обнаруживала грани, то здесь активация на сетке 7*7 нужна для выявления более сложных образов, например, птиц.
Сеть в целом развивается из небольшого количества фильтров (64 в случае GoogLeNet), обнаруживая функции низкого уровня, до очень большого количества фильтров (1024 в окончательной свертке), каждый из которых ищет чрезвычайно специфические образы высокого уровня. И далее применяется окончательный слой — pooling layer, который сворачивает каждую сетку 7*7 в один пиксель, каждый канал является детектором образов с receptive field, эквивалентным всему изображению.
По сравнению с тем, что сделала бы стандартная feedforward сеть, вывод здесь не впечатляет. Стандартная feedforward сеть создала бы абстрактные векторы образов из комбинации всех пикселей в изображении, требуя труднообучаемых объемов данных.
Сверточная нейронная сеть с наложенными на нее priors, начинает обучение с изучения детекторов образов низкого уровня, и когда слой за слоем ее receptive field становится все больше, учится комбинировать эти низкоуровневые образы в образы более высокого уровня; не абстрактное сочетание каждого пикселя, а сильная визуальная иерархия.
Обнаруживая низкоуровневые образы и используя их для обнаружения образов более высокого уровня по мере улучшения своей визуальной иерархии, она в конечном итоге может обнаруживать целые визуальные концепции, такие как лица, птицы, деревья и т.д, именно это делает их такими мощными и эффективными для изображений.
Проблема adversarial attacks
С созданием визуальной иерархии CNN вполне разумно предположить, что их системы видения похожи на такую у людей. И они действительно великолепно справляются с изображениями реального мира, но они также терпят неудачу там, где их система не совсем такая как у человека. Самая главная проблема: Adversarial Examples, примеры, которые были специально изменены, чтобы обмануть модель.
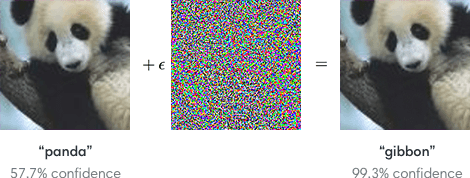
Приведенные примеры были бы нецелесообразными, если бы только подделки, вызвавшие неудачу моделей, были теми, которые заметят люди. Проблема в том, что модели восприимчивы к образцам, которые были только слегка подделаны, и явно не обманут любого человека. Это открывает двери для отказов у моделей, что может быть довольно опасно для широкого спектра приложений: от самоуправляемых автомобилей до задач здравоохранения.
Задача защиты от таких отказов сейчас является активной областью исследования, предметом статей и различных конкурсов, решение которой несомненно улучшит архитектуру сверточной нейронной сети, сделает их надежнее и безопаснее.
CNN были моделями, которые позволяли компьютерному зрению работать как с простыми задачами, так и применяться к сложным продуктам и услугам, начиная от распознавания лиц в вашей фотогалерее и заканчивая улучшением медицинских диагнозов. Они могут быть ключевым методом в компьютерном зрении в будущем, хотя новый прорыв может быть уже за углом. Одно можно сказать наверняка: сверточные нейросети — удивительная основа многих современных инновационных приложений, и, безусловно, заслуживают глубокого изучения.
Телеграм: t.me/ainewsline
Источник: neurohive.io