Эволюционные алгоритмы способны превзойти глубокое обучение в видеоиграх
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-07-19 12:49

Учёные использовали генетический алгоритм чтобы обучить компьютер играть в аркады Atari. Суть подхода в том, что для решения задачи изначально генерируется любой код, который затем изменяется с помощью случайных мутаций. Фрагменты кода, которые лучше решают задачу, воспроизводятся в коде нового поколения. Таким образом происходит развитие. Генетический алгоритм обучается быстрее, чем нейронная сеть. Кроме того, он содержит меньше данных, поэтому проще отследить процесс генерации решений.
Нейронные сети набрали все заголовки, но гораздо более мощный подход ждет в крыльях.
При всем волнении над нейронными сетями и методами глубокого обучения, легко представить, что мир компьютерных наук состоит из немного другого. Нейронные сети, в конце концов, начали опережать людей в таких задачах, как распознавание объектов и лиц, а также в таких играх, как шахматы, Go и различные аркадные видеоигры.
Эти сети основаны на том, как работает человеческий мозг. Ничто не может иметь больше потенциала, чем это, не так ли?
Не совсем. Совершенно другой тип вычислений может быть значительно более мощным, чем нейронные сети и глубокое обучение. Этот метод основан на процессе, который создал человеческий мозг-эволюцию. Другими словами, последовательность итеративных изменений и выбора, которая произвела самые сложные и способные машины, известные человечеству-глаз, крыло, мозг и так далее. Сила эволюции-это чудо созерцать.
Вот почему компьютерные ученые давно пытались использовать его возможности. Так называемые эволюционные вычисления достигли некоторых замечательных подвигов за 30 лет с тех пор, как они были впервые использованы для оптимизации заводских производственных линий для тракторов.
Но в последние несколько лет эта область компьютерных наук должна была играть вторую скрипку для машин глубокого обучения и их огромного успеха.
Сегодня, таблицы смотрят, что поворачивают спасибо работа Dennis Wilson и немного коллег на университете Тулузы в Франция. Эти ребята показали, как эволюционные вычисления могут соответствовать производительности глубинных обучения машин в символических задач, что питание их в известность в 2013 году—возможность превзойти человека в аркадных видео игр , таких как теннис, арканоид, и дрозды. Работа предполагает, что эволюционные вычисления должны быть настолько же интенсивны, как и их отношения, основанные на глубоком обучении.
Эволюционные вычисления работают совершенно иначе, чем нейронные сети. Цель состоит в том, чтобы создать компьютерный код, который решает конкретную проблему, используя подход, который несколько противоречит.
Обычный способ создания кода-писать его с первых принципов, имея в виду конкретную цель.
Эволюционные вычисления используют другой подход. Он начинается с кода, сгенерированного в случайном порядке. И не только одна его версия, но и множество версий, иногда сотни тысяч случайно собранных фрагментов кода.
Каждый из этих кодов тестируется, чтобы увидеть, достигает ли он требуемой цели. И конечно, весь код ужасен, потому что он генерируется случайным образом.
Но просто случайно, некоторые части кода немного лучше, чем другие. Эти части затем воспроизводятся в новом поколении кода, который включает в себя больше копий лучших кодов.
Однако следующее поколение не может быть идентичной копией первого. Вместо этого он должен как-то измениться. Эти изменения могут включать переключение двух терминов в коде - своего рода точечная мутация. Или они могут включать два кода, которые разрезаются пополам и пополам обмениваются-как половая рекомбинация.
Каждое новое поколение затем тестируется, чтобы увидеть, насколько хорошо он работает. Лучшие фрагменты кода преимущественно воспроизводятся в другом поколении и так далее.
Таким образом, код развивается. Со временем он становится лучше, и после многих поколений, если условия будут правильными, он может стать лучше, чем любой человеческий кодер может проектировать.
Компьютерные ученые успешно применяли эволюционные подходы к решению задач, начиная от проектирования роботов и заканчивая строительством частей самолета.
Но она выпала из-за огромного интереса к глубокому обучению. Таким образом, важный вопрос заключается в том, может ли он соответствовать производительности машин глубокого обучения. Чтобы узнать, Уилсон и co использовали подход для разработки кода, который может контролировать аркадные компьютерные игры, начиная с 1980-х и 1990-х годов.
Эти игры доступны в базе данных под названием Arcade Learning Environment, которая все чаще используется для проверки обучающего поведения алгоритмов различных видов. База данных состоит из 61 Atari игр, таких как Pong, Space Invaders, Breakout и Kung Fu Master.
Задача состоит в том, чтобы создать алгоритм, который может играть в игру, как понг, глядя только на выход с экрана, так же, как люди играют. Таким образом, алгоритм должен проанализировать каждую игровую позицию, а затем решить, как двигаться, чтобы максимизировать свой счет.
Элементы управления для всех игр одинаковы. Эти соответствуют 8 направлениям регулятор можно двинуть (вверх, вниз, налево, и справедливо плюс 4 раскосных направления), давление кнопки, такие же 8 движений совмещенных с давлением кнопки, и делать ничего на всех. Не все игры используют все 18 возможных комбинаций, а некоторые используют всего лишь четыре.
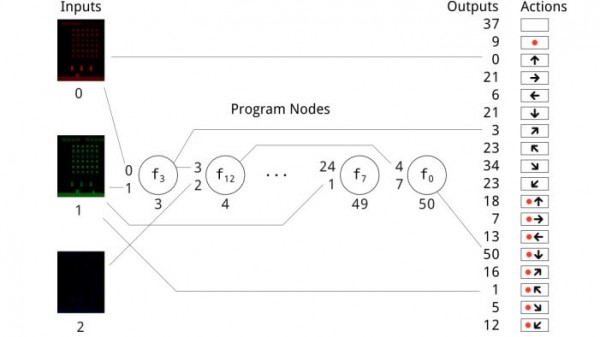
Сначала необходимо создать код. Эволюционный подход требует словаря терминов, которые могут быть объединены в компьютерный код. Термины варьируются от простых действий, таких как ADD (x+y)/2, до более сложных, таких как “возвращает 1-элемент x-vector, если x является скалярным.
Выбор терминов, которые составляют этот словарный запас, важен, и Уилсон и со используют множество, уже определенное для Декартово-генетического программирования (как их техника называется).
Процесс начинается с случайного создания кода, содержащего 40 терминов. Это и есть "геном" программы. Этот геном затем тестируется, чтобы увидеть, насколько хорошо он играет в игру, как судить по счету. В зависимости от того, насколько хорошо он работает, геном затем воспроизводится с мутациями и снова тестируется и так далее. В общей сложности, команда проверила 10,000 геномов таким образом.
Результаты делают для интересного чтения. Во-первых, геномы ужасны в игре. Но со временем они становятся лучше. И после многих поколений, они играют хорошо, иногда лучше, чем люди.
Многие геномы в конечном итоге играют совершенно новые игровые стратегии, часто сложные. Но они иногда находили простые, которые люди упускали из виду.
Например, играя в Kung Fu Master, эволюционный алгоритм обнаружил, что наиболее ценной атакой был удар приседания. Крадущийся безопаснее, потому что он уклоняется от половины пуль, направленных на игрока, а также атакует что-либо поблизости. Стратегия алгоритма состояла в том, чтобы многократно использовать этот маневр без каких-либо других действий. Оглядываясь назад, использование crouch-punch исключительно имеет смысл.
Это удивило людей, участвующих в исследовании. "Использование этой стратегии вручную достигло лучшего результата, чем играть в игру обычно, и автор теперь использует крадущиеся удары исключительно при атаке в этой игре”, - говорят Уилсон и co.
В целом, эволюционировал код играл многие игры хорошо, даже превосходя людей в таких играх, как Kung Fu Master. Так же важно, что разработанный код так же хорош, как и многие подходы к глубокому обучению, и превосходит их в таких играх, как Asteroids, Defender и Kung Fu Master.
Это также дает результат быстрее. ” В то время как программы относительно малы, многие контроллеры конкурентоспособны с современными методами для эталонного набора Atari и требуют меньше времени на обучение",-говорят Уилсон и co.
У разработанного кода есть еще одно преимущество. Потому что она мала, легко увидеть как она работает. В отличие от этого, хорошо известная проблема с методами глубокого обучения заключается в том, что иногда невозможно знать, почему они приняли конкретные решения, и это может иметь практические и правовые последствия.
В целом, это интересная работа, которая должна предложить компьютерным ученым, которые сосредотачиваются исключительно на глубоком обучении, что они могут пропустить трюк. Эволюционный подход является мощной альтернативой, которая может быть применена в широком спектре ситуаций.
Действительно, некоторые исследователи начали использовать его, чтобы развивать лучшие машины для глубокого обучения. Что может пойти не так?
Реф: https://arxiv.org/abs/1806.05695: развитие простой программы для игры на Atari игры
Телеграм: t.me/ainewsline
Источник: www.technologyreview.com